一种结合知识转移的强化学习方法及其应用于无人车自主技能的学习方法与流程
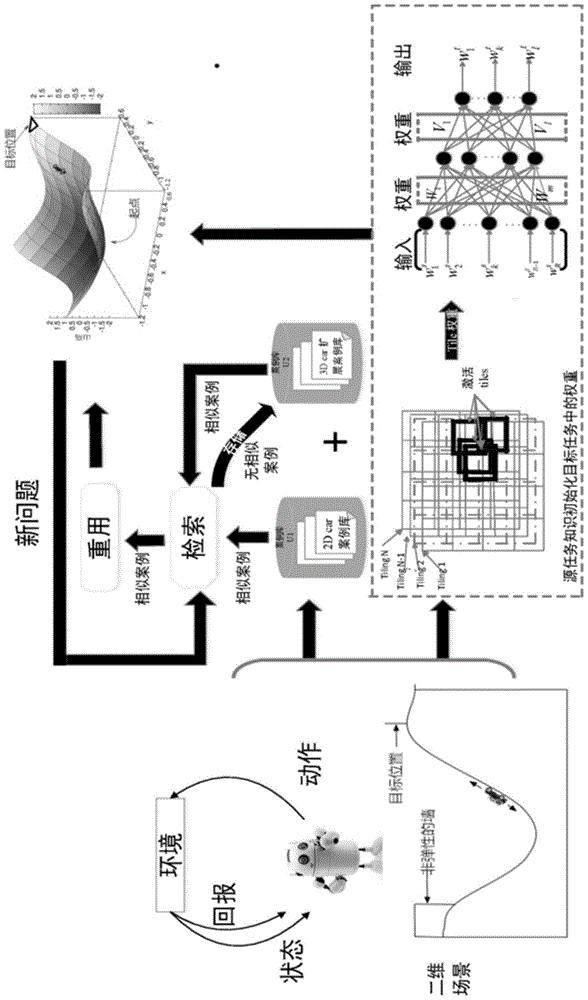
本发明是涉及一种结合知识转移的强化学习方法及其应用于无人车自主技能的学习方法,属于人工智能
技术领域:
。
背景技术:
:随着人工智能时代来袭,大数据、云计算以及物联网的快速发展,社会变得越来越智能化,而研究更加智能的机器人成为了世界各个国家主要的战略发展方向。美国提出的再工业战略,日本提出的机器人新战略以及德国的工业4.0,还有我国提出的互联网+战略,这都体现了人工智能已经成为各国发展战略中的必要一环。现如今,无人工厂、语音识别、计算机视觉、无人驾驶等诸多领域的发展,大量的解决了人们的单调、重复的体力劳动,提高了生产质量。同时,也让人们生活充满着更加丰富的生活体验。现在电脑会玩游戏早已不奇怪,特别是一些策略或棋类游戏,甚至人早己不是电脑的对手。但如果事先不告诉电脑该怎么玩,而只让电脑通过自己观看显示器的显示控制器如何操作,然后让它尽可能的去获得高分,此时大部分传统的人工智能就一筹莫展了。而强化学习便是一种人工智能获得该技能的非常有前途的方法,其中agent通过与环境交互学习最优策略。其在人工智能领域成功运用的经典案例有:例如2013年deepmind团队向人们首次展现他们那个agent靠观察游戏视频,通过强化学习不断试错学习最后击败好多人类专业玩家的游戏高手。在2016年的人机大战,google的alphago大战李世石,并且以4:1成绩取得胜利等等。人类能够通过不断地探索环境了解环境的变化以此获得对环境的认知,主要是因为人类能够在环境中不断的学习积累经验,总结规律,以增长知识和才能,从而使自己能够做出更好的行为决策。强化学习作为一种目的使计算机具有学习的能力,能够模拟或实现人类生活中的学一些活动的学习方法,逐渐成为人工智能的一个重要的研究领域。强化学习的研究和发展对人工智能的研究起着相当重要的作用。强化学习与人类学习方法相比有很多优点,学习速度和人相比更加快速、只要一个agent学会,其它可直接通过复制它的程序实现该功能,而人类则需要经过漫长的后天学习才能达到同样效果。强化学习不会因为人生命终结而终止,对知识的积累能够达到一个非常高的高度。强化学习算法作为一种重要的机器学习方法,agent能够通过不断与环境的交互来不断地完善自己对环境的认知能力,而不需要各种指导信息,且可以和各种计算方法相结合,如遗传算法、神经网络、案例推理、迁移学习。因此在求解复杂问题中强化学习算法有着广泛的应用前景。而对于迁移学习,它是通过重用先前任务中积累的经验以更好地学习新颖但相关的目标任务,并且可以被描述为通过利用相关且研究良好的问题领域中有价值的知识来增强目标领域中的问题解决的方法。例如,1)在学习演奏小提琴时获得的知识可用于加速学习演奏大提琴的过程,使大提琴的学习过程变得更加容易。2)飞行员在学飞机之前都是通过模拟飞行驾驶来学习,最终将学习到的经验用于真实的飞机驾驶。另外,对于迁移学习,给出的两个主要定义,一是域,二是任务。域即为数据集,在迁移学习中分为源域和目标域,源域可以理解为之前例子中有足够训练数据的数据集,而目标域则是我们感兴趣的但可能缺乏足够训练数据的数据集。任务则是分为源任务和目标任务。迁移方法的各不相同主要是因为域和任务之间的差异。当源域和目标域一样,源任务和目标任务一样时,是传统的机器学习;当源域和目标域不同但任务相同,被称为转换迁移学习;当源域和目标域相同但任务不同时,被称为引导迁移学习;当域和任务都不相同时,被称为无监督迁移学习。因此,本领域亟需设计了一种结合知识转移的强化学习方法,结合强化学习与迁移学习的优势,以便实现机器人从简单领域或源域获得的经验通过迁移加速应用到复杂领域或目标域中的学习过程。技术实现要素:针对现有技术存在的上述问题和需求,本发明的目的是提供一种结合知识转移的强化学习方法及其应用于无人车自主技能的学习方法,能够有效克服机器人自主技能学习时速度慢的问题,避免因高维和复杂问题规模的增加、复杂度呈指数増长,而遇上"维数灾难"的问题。为实现上述目的,本发明采用的技术方案如下:一种结合知识转移的强化学习方法,其特征在于,具体包括以下步骤:s1、设计bp神经网络自主任务间映射关系,通过对源任务中的学习经验进行映射来初始化目标任务,为目标任务设置先验;s2、对源任务学习经验进行案例存储,并构建线性感知器来学习源域和目标域之间的动作映射关系;s3、运用基于案例推理机理,在目标任务进行学习时对其在线学习经验进行存储来扩充案例库,并提出渐进遗忘准则对案例库所存储经验中长期不被利用的信息进行清除,以减少匹配检索时间;s4、进行相似度计算与案例检索,并运用所学到的案例库中的经验作为启发式来加速相关但不同任务的学习。作为优选方案,在步骤s1中所述目标任务设置先验时,运用一维tiling来通过tilecoding线性函数逼近器逼近状态-行为值函数并构建神经网络学习源任务的函数逼近器结构与目标任务的函数逼近器结构之间的映射,以实现通过源任务中学习经验来初始化目标任务,网络训练过程中源任务和目标任务tilecoding中激活的tile权重分别作为网络输入和输出。作为优选方案,所述函数公式为:其中,j=1,......,n.,n为tilings总数,θj(st)为给定状态st的第j个激活tile的二值特征(1或0),wj为给定状态st的第j个激活tile的权重;假设φ是由状态st=[ω1,...,ωk,...ωt]激活的块的集合,其中ωk表示第k个状态变量,那么φ可以被划分为t个子集φ={φ1,...,φk,...φt},其中φk是由状态变量ωk激活的tile的集合,则进一步计算函数公式为:通过源任务tilecoding线性函数逼近器权重来初始化目标任务中的tilecoding线性函数逼近器权重,实现源任务学习经验,为目标任务设置先验。作为优选方案,所述步骤s2具体包括以下步骤:s2.1:在案例库构建过程中,用q(λ)算法对源任务进行训练,并通过其所学策略建立一定数量的案例库,案例库中每个案例用一个三元组表示:case=(p,a,q)其中:p为问题描述-属性,a为解决方案-动作,q为执行解决方案的预期回报,用于反应所采取的解决方案的质量;s2.2:在动作映射过程中,运用线性、单层、前馈的线性感知器网络将源任务和目标任务之间的动作建立联系,在所述线性感知器网络中,输入节点对应于目标任务中一组可能动作,输出节点对应于源任务中一组可能动作;通过在源域和目标域中执行一组随机动作来更新网络权重方法,如果两个动作的观察结果相似,那么连接这一对动作的权重就会增加;反之,连接的权重会降低。作为优选方案,所述步骤s3具体包括以下步骤:s3.1:案例库扩充,对目标域中的在线学习经验进行存储和利用,以实时扩充案例库;s3.2:定义案例u在时间t的记忆值为:其中,ut为新案例与案例库进行检索所匹配到案例,h为取值范围在0~1的遗忘因子,rt(u)为案例库中每一个案例随时间的变化而变化的记忆值。作为进一步优选方案,所述渐进遗忘准则公式为:其中,rf为给定阈值。作为优选方案,步骤s4所述相似度通过下述公式计算:其中,是新问题m中所描述的第i个属性值,是案例库中案例sk所描述的第i个属性值,表示属性和属性之间的距离;之后,将基于距离方法的相似性度量技术用于案例研究,对全部案例u即源任务案例库和目标任务经验库进行检索,计算其相似度。本发明还提供一种应用于无人车自主技能的学习方法,采用上述方法进行学习,其特征在于:在无人车模拟器上进行无人车自主技能学习,且源任务和目标任务不同时,对案例库中的案例进行分布式检索处理;无人车模拟器的源任务经验存储的案例库u1中,案例都是拥有两个属性的状态变量(x,x’),而目标任务经验存储的案例库u2中案例拥有四个属性状态变量(x,x’,y,y’),为了实现案例的检索,将相似度计算分如下步骤进行分布式检索:(1)当前案例与案例库u1进行匹配计算相似度:(2)如果案例库u1中匹配到满足相似度阈值的案例,则不进行案例库u2匹配,如何没有匹配到满足相似度阈值的案例,则将当前案例与案例库u2进行匹配计算相似度:其中:dist(m,n)为属性m和属性n之间的距离;如果计算的相似度高于给定阈值,表明案例库有相似案例,然后选择和执行案例所建议的动作计算启发式h(st,at);如果计算的相似度都低于给定阈值,表示案例库无相似案例,则将rl与知识转移相结合框架下的强化学习算法表现为传统强化算法进行学习。与现有技术相比,本发明具有如下有益效果:本发明所述结合知识转移的强化学习方法及其应用于无人车自主技能的学习方法,结合强化学习与迁移学习的优势,可实现机器人从简单领域或源域获得的经验通过迁移加速应用到复杂领域或目标域中的学习过程;能够有效克服机器人自主技能学习时速度慢的问题,避免因高维和复杂问题规模的增加、复杂度呈指数増长,而遇上"维数灾难"的问题;显著的提高了无人车自主技能学习速度和效率,相对于现有技术具有突出的实质性特点和显著的进步。附图说明图1为本发明提供的一种结合知识转移的强化学习方法的示意图;图2为本发明提供的一种结合知识转移的强化学习方法的流程图;图3(a)为本发明提供的使用n层tiling的tilecoding逼近器示意图,较粗的线表示对于给定状态st激活的tile;图3(b)为本发明提供的三层人工神经网络结构示意图;图4为本发明提供的源任务tilecoding函数逼近器的tile权重初始化目标任务tilecoding函数逼近器的tile权重过程框架图;图5(a)为本发明提供的q(λ)算法的流程图;图5(b)为本发明提供的启发式加速q(λ)算法的流程图;图6(a)为本发明提供的二维场景模拟图;图6(b)为本发明提供的三维场景模拟图;图7为本发明提供的在3d模拟器中10次实验所求得的达到目标时的每集的平均步数曲线图;图8为本发明提供的三种算法每一集的学习时间曲线图;图9(a)为本发明提供的启发式加速q(λ)算法vsq(λ)算法;图9(b)为本发明提供的启发式加速q(λ)算法vs启发式加速q(λ)算法。具体实施方式以下结合附图和实施例对本发明的技术方案做进一步详细描述。实施例1结合图1至图5(b)所示,本实施例提供的一种结合知识转移的强化学习方法,其特征在于,具体包括以下步骤:s1、设计bp神经网络自主任务间映射关系,通过对源任务中的学习经验进行映射来初始化目标任务,为目标任务设置良好的先验;s2、对源任务学习经验进行案例存储,并构建线性感知器来学习源域和目标域之间的动作映射关系;s3、运用基于案例推理机理,在目标任务进行学习时对其在线学习经验进行存储来扩充案例库,并提出渐进遗忘准则对案例库所存储经验中长期不被利用的信息进行清除,以减少匹配检索时间;s4、进行相似度计算与案例检索,并运用所学到的案例库中的经验作为启发式来加速相关但不同任务的学习。在本实施例中,步骤s1中所述目标任务设置先验时,运用一维tiling来通过tilecoding线性函数逼近器逼近状态-行为值函数并构建神经网络学习源任务的函数逼近器结构与目标任务的函数逼近器结构之间的映射,以实现通过源任务中学习经验来初始化目标任务,网络训练过程中源任务和目标任务tilecoding中激活的tile权重分别作为网络输入和输出;所述步骤s1具体包括以下步骤:s1.1、建立tilecoding线性函数逼近器逼近状态-行为值函数并运用一维tiling,即每个tiling中的tile当且仅由一个状态变量所激活来通过tilecoding线性逼近状态-行为值函数tilecoding线性逼近状态-行为值函数是通过将状态空间划分为多个称为tiling的层来实现的,如图3(a)所示,较粗的线表示对于给定状态st激活哪些tile,其中tiling中每个划分区块称为tile;当且仅当给定状态落在由该tiling描绘的tile中时,此时该tiling中的tile被激活;所述函数公式为:其中,j=1,......,n.,n为tilings总数,θj(st)为给定状态st的第j个激活tile的1或0的二值特征,wj为给定状态st的第j个激活tile的权重;在利用tilecoding线性逼近状态-行为值函数时,agent存在多个状态变量,所以本发明使用一维tiling,即每个tiling中的tile当且仅由一个状态变量所激活。现在假设φ是由状态st=[ω1,...,ωk,...ωt]激活的块的集合,其中ωk表示第k个状态变量,那么φ可以被划分为t个子集φ={φ1,...,φk,...φt},其中φk是由状态变量ωk激活的tile的集合。则计算函数公式为:s1.2、通过源任务tilecoding线性函数逼近器权重来初始化目标任务中的tilecoding线性函数逼近器权重,实现源任务学习经验,为目标任务设置先验,即通过建立bp神经网络来构建源任务的函数逼近器结构与目标任务的函数逼近器结构之间的映射。迁移学习在强化学习中有着广泛的运用,但是这些应用都没有考虑在目标任务中agent学习开始时运用tilecoding线性函数逼近器计算状态行为值函数时所有参数权值初始化为零所带来的弊端。所以在代理开始学习时,如果对计算状态行为值函数时的tilecoding线性函数逼近器的所有参数权值初始化为零,即此时状态行为值函数都为0。这时每个状态对动作的选取具有相同的影响,并且当代理选择执行哪个动作时,每个动作都具有相同的优先级。这样将导致agent需要花费大量的时间进行开始时的探索。因此,我们通过源任务学习知识来初始化目标任务中的tilecoding线性函数逼近器权重,源任务学习知识即源任务tilecoding线性函数逼近器权重,从而为agent设置良好的先验,以减少agent开始时的探索时间。而在实际应用中,目标任务与源任务之间通常存在着一定的差异,而tilecoding是一种比较简单的特征抽取方法,而这些提取的特征又形成了将其用作函数逼近器的潜在动机。所以,为了让源任务与目标任务之间建立联系,本发明通过建立源任务的函数逼近器结构与目标任务的函数逼近器结构之间的映射,即tile权重之间映射,从而达到运用源任务学习知识来初始化目标任务中的函数逼近器权重的目的,源任务学习知识即源任务tilecoding线性函数逼近器权重,进而为agent设置良好先验。在实施例中,使用bp神经网络来学习源任务tile权重与目标任务tile权重之间的映射关系,所述bp神经网络如图3(b)所示,其中输入向量为源任务训练所学到的tile权重表示为输出向量为目标任务训练所学到的tile权重表示为输入层与隐含层之间的bp神经网络权重矩阵分别为w1,...,wm,隐含层与输出层之间的bp神经网络权重矩阵分别为v1,...vl。为了对bp神经网络进行训练,假设源任务中状态变量数为ms,即状态st可表示为动作数为as;在目标任务中,假设状态变量数为mt,动作数为at;同时bp神经网络的输入节点个数设置为ni=ms×as,输出节点个数设置为no=mt*at,隐含层节点个数设置为其中,网络输入为源任务tilecoding线性函数逼近器中状态变量所激活的tile权重,而输出为目标任务tilecoding线性函数逼近器中状态变量所激活的tile权重,激活函数采用修正线性单元relu激活函数:f(z)=max(0,z)其中,z是该神经元输入;可进一步计算神经元节点的输出以及该神经网络的网络误差如下:隐含层节点输出为yj=f(wj·wsτ),输出层节点输出为其中,yj和oj分别表示隐藏层第j个神经元节点输出和输出层第j个神经元节点输出;可进一步计算bp神经网络误差:其中,tpj为第j个神经元节点的期望输出值;opj为第j个神经元节点计算输出值;然后通过计算得到的bp神经网络误差方向传播来更新神经网络权重来学习该网络;最后对完成训练的bp神经网络,运用源任务tilecoding线性函数逼近器权重作为完成训练的bp神经网络的输入,并用完成训练的bp神经网络输出对目标任务中的函数逼近器中tile权值进行初始化,从而得出具有先验的初始值即为agent建立了学习起点,具体过程如图4所示。在本实施例中,所述步骤s2具体包括以下步骤:s2.1、在案例库构建过程中,如图5(a)所示,用q(λ)算法对源任务进行训练,并通过其所学策略建立一定数量的案例库,案例库中每个案例用一个三元组表示:case=(p,a,q)其中,p为问题描述-属性,a为解决方案-动作,q为执行解决方案的预期回报,用于反应所采取的解决方案的质量;s2.2、在动作映射过程中,运用线性、单层、前馈的线性感知器网络将源任务和目标任务之间的动作建立联系,在所述线性感知器网络中,输入节点对应于目标任务中一组可能动作,输出节点对应于源任务中一组可能动作。为更好获得线性感知器网络权重,运用以下方法更新线性感知器网络权重,即在源域和目标域中执行一组随机动作。如果两个动作的观察结果相似,例如两个动作都会导致agent加速,那么连接这一对动作的权重就会增加;反之,连接的权重会降低。这里神经网络输入我们通过对目标域动作进行处理得到双极形式,如该动作能使agent速度增加则为1,反之为-1,网络输出通过二进制heaviside激活函数也得到双极形式。更新所述线性感知器网络权重通过下述公式计算:△wi,j=μtisjwi,j=wi,j+△wi,j其中,μ为学习率,wi,j为线性感知器网络权重,ti为第i个输入神经元所输入的目标域动作对agent速度改变的差值,sj为第j个输出神经元所输出的源域动作对agent速度改变的差值即velocity-old_velocity;故如果一组动作使ti,sj同号,表明这组动作作用于agent的观察结果相似,△wi,j>0连接这组动作的线性感知器网络权重wi,j加大;反之,△wi,j<0,连接这组动作的线性感知器网络权重wi,j减小。在学习过程中,由于神经网络是线性、单层、前馈的线性感知器网络,所以一个神经元的输出取决于输入神经元的加权和:其中,b0是偏置;则二进制heaviside激活函数可表示如下:之后,对此线性感知器网络权重进行训练,最终得出源域和目标域的动作之间的映射关系。在本实施例中,所述步骤s3具体包括以下步骤:s3.1、案例库扩充,为了避免目标任务学习经验的浪费,对目标域中的在线学习经验进行存储和利用,使案例库得到实时扩充,在本实施例中,案例库只含源域案例库u1,实时扩充的案例库为目标任务在线经验存储案例库u2;s3.2、定义案例u在时间t的记忆值为:其中,ut为新案例与案例库进行检索所匹配到案例,h为取值范围在0~1的遗忘因子,rt(u)为案例库中每一个案例随时间的变化而变化的记忆值;如果案例库案例长期不被利用,那么其记忆值会逐渐减小,如果被利用该案例记忆值立马恢复为1;所述渐进遗忘准则公式为:其中,rf为给定阈值;在案例库中所有的案例,如果在某个时刻其记忆值小于给定阈值rf,那么该案例的所有信息在这个案例库中被遗忘从而清除。在本实施例中,步骤s4所述相似度通过下述公式计算:其中,是新问题m中所描述的第i个属性值,是案例库中案例sk所描述的第i个属性值,表示属性和属性之间的距离;之后,将基于距离方法的相似性度量技术用于案例研究,对全部案例u即源任务案例库和目标任务经验库进行检索,计算其相似度。实施例2结合图6(a)至图9(b)所示,本实施例还提供一种应用于无人车自主技能的学习方法,采用实施例1所示方法进行学习,在无人车模拟器上进行无人车自主技能学习,且源任务和目标任务不同时,对案例库中的案例进行分布式检索处理;考虑驱动一辆动力不足的汽车冲上陡峭的山路,如图6(a)所示。但是由于重力大于车引擎所能产生的动力,即使使用最大的油门也难以冲上斜坡。解决方法为先向相反方向的斜坡前进,然后依靠惯性和大油门冲上目标斜坡。这个任务每一步的奖赏值为-1。可选动作有3个:大油门(+1),反向大油门(-1),空油门(0)。状态由2个变量组成,分别为车的位置xt和速度这两个变量按下式进行更新:其中,bound函数用来修正这两个值使其分别保持在范围[-1.2,0.6]和[-0.07,0.07]中;当xt+1为左边界时,将xt+1置零;当到达右边界0.5时,目标达到,集数结束。三维空间的无人车爬坡(如图6(b))与二维平面情况相识,状态由4个变量组成:分别为xt,yt,位置和速度取值范围也为[-1.2,0.6]和[-0.07,0.07]。不过在这种场景中,无人车共有5个动作选择,分别为:向东,向南,向西,向北,不动。在本实施例中,使用q(λ)算法分别对2d模拟器和3d模拟器进行200集训练,并用获得的tile权重来训练ann映射,从而为3d模拟器无人车学习提供良好的起点。又由于在2d模拟器中,训练200集可使趋向于0,因此在该学习完成后,可以进行案例获取。为了在目标域中使用案例,对2个域之间的动作进行映射。设置神经网络的输入层有5个神经元即输入目标域中的五个动作,输出层有3个神经元即输出源域中的三个动作,学习率α=0.95,偏置b=0.01,并使用500000次迭代。由于3d模拟器中无人车的动作仅在一维中应用,如无人车进行向东操作只改变x方向上速度,所以在实验中,将每个动作的结果作为无人车速度在每个维度上的变化,然后使用动作的结果来训练神经网络;如表1,给出了所得到的2个域之间的动作映射关系。表1:无人车爬坡实验中的动作映射关系在案例库扩充与渐进遗忘准则阶段,为了避免3d模拟器中无人车的学习经验的浪费,对目标域中的在线学习经验进行存储和利用,使案例库得到实时扩充,在本实施例中,案例库只含源域案例库u1,实时扩充的案例库为目标任务在线经验存储案例库u2;同时引入了渐进遗忘准则以清除长期不被利用的信息,其中遗忘因子h=0.99,遗忘阈值rf=10-8。最后在相似度计算与案例检索阶段,运用全部案例u来加速目标域的学习,在本实施例中,全部案例u=源域案例库u1+目标任务在线经验存储案例库u2,由于案例库u中有两个属性的状态变量(x,x’),可能也有四个属性状态变量(x,x’,y,y’)。所以,为了实现案例的检索,将相似度计算分如下步骤进行分布式检索:(1)当前案例与案例库u1进行匹配计算相似度:(2)如果案例库u1中匹配到满足相似度阈值的案例,则不进行案例库u2匹配,如何没有匹配到满足相似度阈值的案例,则将当前案例与案例库u2进行匹配计算相似度:其中:dist(m,n)为属性m和属性n之间的距离;如果计算的相似度高于给定阈值,表明案例库有相似案例,然后选择和执行案例所建议的动作计算启发式h(st,at),如图2中圈出部分所示,启发式加速q(λ)算法如图5(b)所示;如果计算的相似度都低于给定阈值,表示案例库无相似案例,则将rl与知识转移相结合框架下的强化学习算法表现为传统强化算法进行学习。为了评估本发明所述学习方法的性能,分别用q(λ)算法,启发式加速q(λ)算法以及基于本发明框架下的启发式加速q(λ)算法在3d无人车爬坡模拟器上执行10次训练,每一次训练包含1000集;并且在所有试验中,使用相同的参数:学习率α=0.2,探索率ε=0.0,λ=0.95,γ=1.0;其中,基于本发明所述启发式加速q(λ)算法中启发系数η=1;用于衡量启发函数重要性参数ξ=1,β=1,每集结束时衰减10-4;遗忘因子h=0.99;遗忘阈值rf=10-8;2d模拟器中案例库u1中案例个数n=500。如图7所示,启发式加速q(λ)算法以及基于本发明所述学习方法的启发式加速q(λ)算法在3d无人车模拟器上的学习曲线,可以注意到基于本发明所述学习方法的启发式加速q(λ)算法在前550集明显优于启发式加速q(λ)算法和q(λ)算法,最终三种算法都收敛且性能几乎趋于一致。如图8所示,三种算法在每一集中学习所花费的时间学习曲线可看出,在学习开始时基于本发明框架下的启发式加速q(λ)算法学习所用的时间明显优于其它两种算法。在学习过程中,随着经验的积累,q(λ)算法,启发式加速q(λ)算法每一集学习时间逐渐减少,学习速度加快,但最后三种算法在每一集的学习时间都趋于一致。为了更好的验证本发明所述学习方法的性能,用图9中的数据为每一集计算了t-test的t值;图9中的结果显示基于本发明框架下的启发式加速q(λ)算法在650集之前表现明显优于q(λ)算法,在前550集表现明显优于启发式加速q(λ)算法,置信水平大于95%。与此同时,我们还运用其它几种学习指标,对这些算法的性能进行比较,其中:1、渐近性能:测量在目标域中收敛时的所需步数;2、总报酬:测量目标域中学习总奖励;3、转移比:测量目标域中进行转移和非转移学习之间的奖励面积;4、阈值时间:测量在目标域中学习到达规定性能阈值所用的时间。如表2和表3所示,上述指标比较的结果都验证了基于本发明所述学习方法的启发式加速q(λ)算法优于q(λ)算法和启发式加速q(λ)算法。算法渐近性能总报酬(×103)转移比q(λ)算法289±45-13290启发式加速q(λ)算法276±36-11441.16本发明框架下启发式加速q(λ)算法250±6-4043.29表2三种算法的渐近性能,总报酬,转移比性能指标表3三种算法的阈值时间性能指标如表4所示,给出了基于这三种算法对3d模拟器进行学习10次,每一次实验的平均时间。从表中可以看出基于本发明所述学习方法的启发式加速q(λ)算法显著的提高了无人车自主技能学习速度和效率。算法学习时间q(λ)算法14.011946启发式加速q(λ)算法11.214722本发明框架下启发式加速q(λ)算法6.136719表4三种算法进行试验的学习时间综上所诉可见:本发明所述结合知识转移的强化学习方法及其应用于无人车自主技能的学习方法,结合强化学习与迁移学习的优势,可实现机器人从简单领域或源域获得的经验通过迁移加速应用到复杂领域或目标域中的学习过程;能够有效克服机器人自主技能学习时速度慢的问题,避免因高维和复杂问题规模的增加、复杂度呈指数増长,而遇上"维数灾难"的问题;显著的提高了无人车自主技能学习速度和效率,相对于现有技术具有突出的实质性特点和显著的进步。最后有必要在此指出的是:以上所述仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1