一种基于改进WMD算法的实体对齐方法与流程
本发明属于自然语言处理技术领域,涉及的实体对齐方法,具体来讲是一种基于改进wmd算法的实体对齐方法。
背景技术:
为促进数据的语义化,国内外的研究机构和企业已经构建了丰富多样的知识库。这些知识库在数据挖掘,语义分析,智能问答系统等应用中发挥了重要的作用。但仅仅使用单一知识库会导致信息覆盖面低,描述不完整的问题。在构建中文知识库中,可以通过多个知识库的融合,有效解决信息缺失的问题,而有效的实体对齐技术正是数据融合的关键所在。实体对齐的目的是判别来自不同数据源中的实体是否指向现实世界的同一对象。通过有效的实体对齐技术,我们可以从网络百科实体页面中抽取实体,进而构建一个高质量的中文百科知识库。
实体对齐实质上是要解决多源知识库之间异构问题,目前知识库的异构问题主要体现在两个方面(1)体系结构差异,不同知识库的结构存在较大差异;(2)内容差异,即不同知识库中所填充的实体不同,相同的实体名可能指代多个对象。但中文知识库资源缺乏完整的体系结构,不适用应用以上方法。在内容差异方面的对齐工作较少,多为基于实体的属性信息。但由于百科数据属于用户原创,数据质量参差不齐,仅通过属性信息难以判定是否为同一实体。
技术实现要素:
本发明对传统实习对齐方法在中文百科实体上正确率不高的问题,公开一种基于改进wmd算法的实体对齐方法,一种通过计算编辑距离和改进的wmd距离进而完成中文百科实体对齐方法。
一种基于改进wmd算法的实体对齐方法,按照如下步骤进行:
步骤(1)计算百科实体之间的属性相似度。
步骤(2)计算百科实体间的摘要文本相似度。
步骤(3)通过属性相似度和摘要文本相似度综合判断实体是否能够消岐。
步骤1所述的计算百科实体之间的属性相似度,过程如下:
1.1首先统一属性的名称,采用人工构建属性映射规则的方法,通过人工对比校验,构建了多个类别的属性名映射表,进而规范属性名称不一致的情况。
1.2其次统一属性的属性值,通过统计分析,建立属性值归一化规则,对属性值进行归一化。
1.3对于实体ea,eb,其属性名称集合分别为:propertya={pa1,pa2,...,pam},propertyb={pb1,pb2,...,pbn}。属性值集合分别为valuea={va1,va2,...,vam},vaiueb={vb1,vb2,...,vbn}。
1.4对于公有属性pi∈commonpropertty(ea,eb),对应着相同属性名称的pam∈propertya,pbn∈propertyb。其中pam的属性值为vam,pbn的属性值为vbn,则百科实体的属性相似度计算公式为:
其中:
t=|propretya∩propretyb|
t为公共属性交集中的元素个数,ed(vax,vby)为实体属性值的编辑距离,max{len(vax),len(vby)}为属性值的最大字符长度。
进一步的,步骤2所述的计算百科实体之间摘要文本相似度的步骤如下:
2.1采用textrank算法对百科实体的摘要文本计算词权重,其单个词权重ws(vi)计算公式为:
其中,in(vi)代表指向该词vi的集合,out(vj)代表vi指向的词集合,d为阻尼系数,一般设置为0.85。sij为词vi到vj边的权重,sjk为词vj到vk边的权重。
2.2通过预训练好的word2vec模型,将分词后的百科实体的摘要文本转化为词的分布式低维实数向量表示,将一个词的语义转化为另外一个词的语义的代价定义为wordtravelcost,词vi,vj之间的wordtravelcost定义为:
c(i,j)=||xi-xj||2
其中,xi,xj分别对应词vi,vj所对应的word2vec词向量。
2.3在计算文档d0,d1的距离时,wmd会尝试寻找最小的代价将d0中的所有单词转化为d1中的单词。d0中的词vi的权重为ws(vi),d1中的词vj的权重为ws(vj),且vi,vj∈{v0,v1…vn}。设t∈rn×n为低维系数矩阵,其中tij为词语vi到词语vj的转移量,则wmd的优化表达式为:
其中:
2.4通过以上计算,百科实体的摘要文本相似度计算公式为:
进一步的,步骤3通过属性相似度和摘要文本相似度综合判断的步骤如下包括:
3.1将计算得出的属性相似度和预设定的实体属性相似度上限阈值ν和下限阈值ω进行比较,如大于等于上限阈值v,则对齐实体,输出新的实体。若相似度在在上限阈值v和下限阈值ω之间或等于下限阈值ω,则转向步骤3.2。否则认为该实体对之间不需要对齐工作;
3.2将摘要文本相似度和预设定的摘要文本相似度阈值λ进行比较,若大于等于阈值λ,则对齐实体,输出新的实体。否则判定这两个实体无关。
本发明的优点及有益效果如下:
本发明由于采取以上技术方案,具有如下优点:本发明通过改进的wmd算法对百科实体的摘要文本进行相似度计算,同时考虑百科实体的属性相似度,综合判断是否可以进行百科实体对的消岐工作。在引入对百科实体摘要文本的语义信息的考量的同时,有效降低了单纯依赖属性相似度来进行实体消岐工作带来的误差。
附图说明
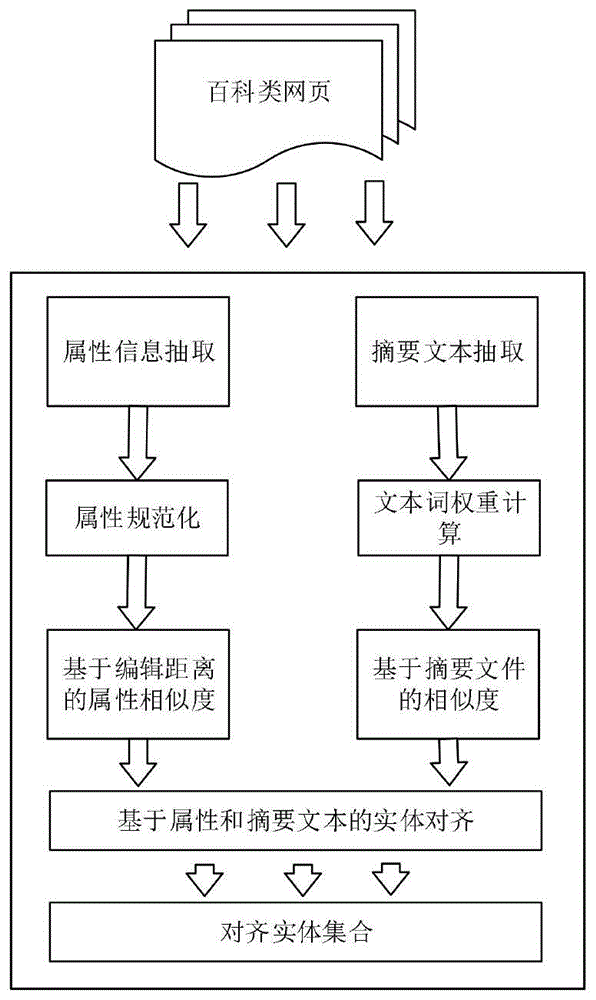
图1是本发明所述方法的流程框图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1,一种基于改进的wmd算法的实体对齐方法包括以下步骤:
1)步骤(1)计算百科实体之间的属性相似度。
1.1)首先统一属性的名称,采用人工构建属性映射规则的方法,通过人工对比校验,构建了多个类别的属性名映射表,进而规范属性名不一致的情况。
1.2)其次统一属性的属性值,通过统计分析,建立属性值归一化规则,对属性值进行归一化。
1.3)对于实体ea,eb,其属性名集合其属性名集合propertya={pa1,pa2,...,pam},propertyb={pb1,pb2,...,pbn}。属性值集合为valuea={va1,va2,...,vam},vaiueb={vb1,vb2,...,vbn}。
1.4)对于公有属性pi∈commonpropertty(ea,eb),对应着相同属性名称的pam∈propertya,pbn∈propertyb。其中pam的属性值为vam,pbn的属性值为vbn,则百科实体的属性相似度计算公式为:
其中:
t=|propretya∩propretyb|
t为公共属性交集中的元素个数,ed(vax,vby)为实体属性值的编辑距离,max{len(vax),len(vby)}为属性值的最大字符长度。
2)步骤(2)计算实体间的摘要文本相似度。
2.1)采用textrank算法对百科实体的摘要文本计算词权重,其单个词权重ws(vi)计算公式为:
2.2)通过预训练好的word2vec模型,将分词后的百科实体的摘要文本转化为词的分布式低维实数向量表示,将一个词的语义转化为另外一个词的语义的代价定义为wordtravelcost,词vi,vj之间的wordtravelcost定义为:
c(i,j)=||xi-xj||2
其中,xi,xj分别对应词vi,vj所对应的word2vec词向量。
2.3)在计算文档d0,d1的距离时,wmd会尝试寻找最小的代价将d0中的所有单词转化为d1中的单词。d0中的词vi的权重为ws(vi),d1中的词vj的权重为ws(vj),且vi,vj∈{v0,v1…vn}。设t∈rn×n为低维系数矩阵,其中tij为词语vi到词语vj的转移量,则wmd的优化表达式为:
其中:
2.4)通过以上计算,百科实体的摘要文本相似度计算公式为:
3)步骤(3)通过属性相似度和摘要文本相似度综合判断实体是否可以消岐。
3.1)将计算得出的属性相似度和预设定的实体属性相似度上限阈值ν和下限阈值ω进行比较,如大于等于上限阈值v,则对齐实体,输出新的实体。若相似度在上限阈值ν和下限阈值ω之间或等于下限阈值ω,则转向下一步。否则认为该实体对之间不需要对齐工作
3.2)将摘要文本相似度和预设定的摘要文本相似度阈值λ进行比较,若大于等于阈值λ,则对齐实体,输出新的实体。否则判定这两个实体无关。
3.3)根据以上的定义和公式,综合判断中文百科实体对齐的算法如下:
- 还没有人留言评论。精彩留言会获得点赞!