一种基于变分推理贝叶斯神经网络的洪水集合预报方法与流程
本发明属于水文水资源领域,更具体地,涉及一种基于变分推理贝叶斯神经网络的洪水集合预报方法。
背景技术:
准确可靠的洪水预报,能为流域梯级水库防洪调度决策提供科学依据,对流域防洪安全和洪水资源合理利用具有重大意义。滑动平均自回归、支持向量机回归以及深度学习方法在水文预报中展现了其优秀的性能。预报的不确定性在防洪调度中同样十分重要,然而这类确定性预报方法只能预报一个值,无法量化预报中的不确定性。因此,构建考虑预报不确定性的集合预报模型是亟需解决的理论和实际工程问题。
为了定量估计预报的不确定性,krzysztofwicz等人提出一种基于贝叶斯概率的水文预报方法,其通过贝叶斯理论来预测模型的不确定性。虽然该方法能够定量估计预报的不确定性,但是其后验参数的推导过程需要大量的计算成本。yaringal等人提出一种变分贝叶斯网络结构,其利用dropout方法来估计预报的不确定性。然而,该方法采用伯努利分布作为变分分布,具有多个超参数,需要大量的重复试验才能得到最优的超参数。
技术实现要素:
针对现有技术的缺陷,本发明的目的在于解决现有技术洪水集合预报计算成本高、超参数多导致优化复杂的技术问题。
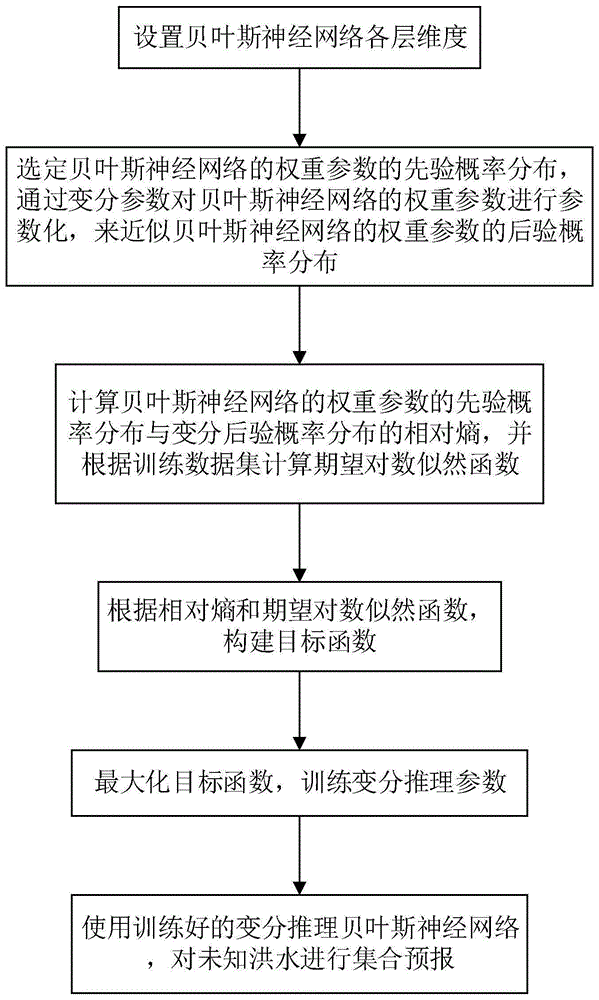
为实现上述目的,第一方面,本发明实施例提供了一种基于变分推理贝叶斯神经网络的洪水集合预报方法,所述方法包括以下步骤:
步骤s1.设置贝叶斯神经网络各层维度;
步骤s2.选定贝叶斯神经网络的权重参数的先验概率分布,通过变分参数对贝叶斯神经网络的权重参数进行参数化,来近似贝叶斯神经网络的权重参数的后验概率分布;
步骤s3.计算贝叶斯神经网络的权重参数的先验概率分布与变分后验概率分布的相对熵,并根据训练数据集计算期望对数似然函数;
步骤s4.根据相对熵和期望对数似然函数,构建目标函数;
步骤s5.最大化目标函数,训练变分推理参数;
步骤s6.使用训练好的变分推理贝叶斯神经网络,对未知洪水进行集合预报。
具体地,步骤s2中选定bnn权重参数w的先验概率分布为标准正态分布p(wij)~n(0,1),其中,wij为bnn第i层第j个维度的权重参数。
具体地,步骤s2中采用以θij为均值、以σij为标准差的高斯分布,作为变分后验分布
其中,θij为bnn第i层第j个维度的权重参数wij的均值,σij为bnn第i层第j个维度的权重参数wij的方差。
具体地,贝叶斯神经网络的权重参数的先验概率分布p(w)与变分后验概率分布
其中,θij为bnn第i层第j个维度的权重参数wij的均值;σij为bnn第i层第j个维度的权重参数wij的方差。
具体地,期望对数似然
其中,x表示预报因子x的集合,y表示预报对象y的集合,(xm,ym)表示从所有数据集(x,y)中随机选取的第m个不同的数据点,m=1,2,…m,m为随机选取的数据点总个数,n为训练集的数据个数,
具体地,目标函数
具体地,步骤s5具体为:采用前向传播算法得到目标函数
具体地,步骤s6具体为:采用蒙特卡罗采样bnn权重参数w,生成s个预报值,作为集合预报:
[y1,y2,...,ys]=bnn(x*,[w1,w2,...,ws])
∈~n(0,1)
其中,s为蒙特卡罗采样的个数,bnn(x,w)表示根据给定的预报因子x以及bnn的参数w通过前向传播算法得到预报值y=[y1,y2,...,ys]。
具体地,对于数据点x*,其预报值y*的概率分布可按下式得到:
其中,
第二方面,本发明实施例提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器执行时实现上述第一方面所述的洪水集合预报方法。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有以下有益效果:
1.本发明通过变分贝叶斯神经网络模型进行洪水集合预报,将变分推理的理论与贝叶斯神经网络模型结合,通过变分分布近似贝叶斯网络模型权重的后验参数,有效地简化了传统贝叶斯网络模型集合预报复杂的计算过程,并能够定量描述洪水预报的不确定性,从而为防洪调度提供来水不确定性的信息,减少防洪调度风险。
2.本发明通过高斯分布的参数化方法,对变分分布进行参数化,用变分参数代替贝叶斯神经网络的权重参数,在模型训练的过程中动态优化变分参数,其方法利用蒙特卡罗模拟对变分参数进行随机参数化,与以伯努利分布作为变分分布的dropout方法相比,避免了预先设定大量的超参数,减少了模型优化选择的复杂问题。
附图说明
图1为本发明实施例提供的一种基于变分推理贝叶斯神经网络的洪水集合预报方法流程图;
图2为本发明实施例提供的宜昌站汛期洪水集合预报概率积分转换(pit)统计图;
图3为本发明实施例提供的宜昌站汛期洪水集合预报“径流大于历史同期中位数值”事件的预报概率和观测概率图;
图4为本发明实施例提供的宜昌站汛期洪水集合预报不确定性分析图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图1所示,一种基于变分推理贝叶斯神经网络的洪水集合预报方法,所述方法包括以下步骤:
步骤s1.设置贝叶斯神经网络各层维度;
步骤s2.选定贝叶斯神经网络的权重参数的先验概率分布,通过变分参数对贝叶斯神经网络的权重参数进行参数化,来近似贝叶斯神经网络的权重参数的后验概率分布;
步骤s3.计算贝叶斯神经网络的权重参数的先验概率分布与变分后验概率分布的相对熵,并根据训练数据集计算期望对数似然函数;
步骤s4.根据相对熵和期望对数似然函数,构建目标函数;
步骤s5.最大化目标函数,训练变分推理参数;
步骤s6.使用训练好的变分推理贝叶斯神经网络,对未知洪水进行集合预报。
步骤s1.设置贝叶斯神经网络各层维度。
本发明实施例中构建的贝叶斯神经网络(bayesianneuralnetwork,bnn)结构如下:输入层维度为7,三层隐含层每层维度为40,输出层维度为1。
步骤s2.选定贝叶斯神经网络的权重参数的先验概率分布,通过变分参数对贝叶斯神经网络的权重参数进行参数化,来近似贝叶斯神经网络的权重参数的后验概率分布。
bnn的权重参数w首先按照先验概率分布p(w)设置。本发明实施例选定bnn权重参数w的先验概率分布为标准正态分布p(wij)~n(0,1),其中,wij为bnn第i层第j个维度的权重参数。
本发明采用变分推理来近似bnn权重参数w的后验概率分布p(w|x,y),x表示预报因子(前期来水)x的集合,y表示预报对象(实测来水)y的集合。其核心思想是通过一个变分分布
其中,θij为bnn第i层第j个维度的权重参数wij的均值;σij为bnn第i层第j个维度的权重参数wij的方差。
步骤s3.计算贝叶斯神经网络的权重参数的先验概率分布与变分后验概率分布的相对熵,并根据训练数据集计算期望对数似然函数。
贝叶斯神经网络的权重参数的先验概率分布p(w)与变分后验概率分布
本发明使用随机梯度变分贝叶斯,计算期望对数似然函数
本发明实施例以长江上游水文站点为研究对象,数据采用1952年到2008年宜昌站的汛期(6月~9月)实测来水为预报对象y,以宜昌站、屏山站、高场站、李家湾站和北碚站的前期来水为预报因子x,其中1952年到1990年数据作为训练集,1991年到2008年数据作为测试集。
期望对数似然
其中,n为训练集的数据个数。
通过蒙特卡罗采样得到:
其中,
期望对数似然
其中,(xm,ym)表示从所有数据集(x,y)中随机选取的第m个不同的数据点,m=1,2,…m。
步骤s4.根据相对熵和期望对数似然函数,构建目标函数。
目标函数
步骤s5.最大化目标函数,训练变分推理参数。
采用前向传播算法得到目标函数
步骤s6.使用训练好的变分推理贝叶斯神经网络,对未知洪水进行集合预报。
给定一个新的数据点x*,其预报值y*的概率分布可按下式得到:
为了得到集合预报,采用蒙特卡罗采样bnn权重参数w,生成s个预报值,作为集合预报:
[y1,y2,...,ys]=bnn(x*,[w1,w2,...,ws])
∈~n(0,1)
其中,s为蒙特卡罗采样的个数,bnn(x,w)表示根据给定的预报因子x以及bnn的参数w通过前向传播算法得到预报值y。多个不同的参数由蒙特卡罗采样得到,从而得到多个不同预报值[y1,y2,...,ys]。
从预报精度及其预报可靠性两个方面评估集合预报方法的性能,并分析洪水集合预报的不确定性。
表1给出提出的变分贝叶斯神经网络vbnn以及基于dropout方法的贝叶斯神经网络(bdo-0.1、bdo-0.05)模型在测试集的洪水集合预报的评价指标值。其中,表1中crps表示连续分级概率评分,rmse表示均方根误差,nse表示纳什系数。crps同时考虑了预报的偏差以及概率预报的范围,是一种集合预报常用的评价指标,指标值越小越好。rmse通常为点预报的预报评价指标,这里采用集合预报均值作为点预报值来计算rmse指标,指标值越小越好。nse是一个相对值,其范围在负无穷到1之间,越接近于1,代表预报值与实测径流值越接近。从表1可以看出,采用vbnn的集合预报的方法能够得到较高的预报精度。
表1洪水集合预报的评价指标值表
在预报精度评价的基础上,进一步对预报可靠性进行分析。本发明选用预报概率积分转换(pit)值和可靠性图来分析可靠性,其中,当pit值整体成均匀分布时以及可靠性图中预报概率和观测概率相似度高时,认为预报的可靠性高。
如图2所示,概率积分转换pit整体上呈现均匀分布的特征。这一结果说明:观测值基本上可以看作来自对应概率预报的随机采样,代表此预报具有较高的可靠性。
如图3所示,“径流大于历史同期中位数值”事件的预报概率和观测概率三点基本分布在一比一线附近,说明预报概率和观测概率温和较好,预报可靠性较高。
图4以集合预报均值为横轴,给出了集合预报80%和95%的置信区间。如图4所示,置信区间随着预报均值的增加变得更宽,这说明变分贝叶斯神经网络集合预报方法较好地描述了预报不确定性异方差的特性。图4中的点表示预报均值对应的观测值,整体上,观测值与集合预报的均值以及置信区间有良好的对应关系,其大都分布在置信区间以内,少数点分布在置信区间边界附近。
以上,仅为本申请较佳的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!