基于多模型迁移和BMA理论的复杂工业过程低成本建模方法与流程
本发明提出一种基于多模型迁移和贝叶斯模型平均理论的复杂工业过程低成本建模方法,属于工业生产过程构建性能预测模型技术领域。
背景技术:
随着市场竞争的日益激烈,以低成本快速准确地建立工业过程的性能预测模型已经是工业生产领域中的一种趋势。然而由于工业过程运行数据不足,传统的建模方法在有限的预算和时间难以快速准确的建立过程性能预测模型,而设计实验采集数据耗时费力,又增加过程建模成本。为了解决此问题,基于多模型方法建立新工业过程预测模型的方法应运而生。chenglin等人对电动车电池建立了thevenin模型,双极化模型,3阶rc模型评估其充电状态;nandola等人对非线性混合模型分别建立多个线性子模型对其进行优化控制。
然而这两种方式实质上都只关注于一个过程而不是多个相似的过程,因此忽略了多个相似工业过程之间有用的信息。
技术实现要素:
为了实现上述目的,本发明提供了一种基于多模型迁移和bma理论的复杂工业过程低成本建模方法,此处bma理论指贝叶斯模型平均理论(bayesianmodelaveraging)。工业生产中存在大量相似的过程并且它们之间是相互关联的,尽管它们在尺寸、结构等方面存在差异,但是它们的内在机理是相似的,它们包含的信息可以指导新工业过程的建模。本发明在对新工业过程进行建模时,充分利用相似工业过程的有用信息,减少新工业过程建模阶段中对其运行数据的依赖,有效解决了新工业过程建模成本高、建模周期长的问题,从而加快新工业过程的建模速度,同时将新工业过程建模所需要的数据量尽可能降至最低。
本发明是通过如下技术方案实现的:一种基于多模型迁移和bma理论的复杂工业过程低成本建模方法,其具体步骤如下:
a、选取已有相似旧工业过程模型mi(x),i=1,…,n;
b、利用拉丁超立方采样方法,采集新工业过程建模初始数据集,同时映射新工业过程数据至旧工业过程模型的可行区间;
c、用贝叶斯模型平均理论评估旧工业过程模型对新工业过程建模的权重,获得旧工业过程模型融合输出为
d、多模型迁移策略,训练新工业过程模型。将旧工业过程模型融合输出y1和新工业过程输入数据x作为多模型迁移策略的输入数据,利用取最小二乘支持向量机(leastsquaressupportvectormachine,lssvm)算法训练新工业过程模型,获得新工业过程模型输出y2,完成新工业过程建模;
e、模型验证,若步骤d所得模型满足实验停止条件,则模型迁移训练结束,否则,利用嵌套拉丁超立方设计来采集新工业过程样本,继续训练新工业过程模型,直至满足实验停止条件;
所述步骤a包含:根据“25%规则”(g.e.box,j.s.hunterandw.g.hunter,statisticsforexperimenters:design,innovation,anddiscovery,vol.2,newyork,ny,usa:wiley,2005.)确定初始数据集大小n0,即n0≤0.25*t,t为实验预算;利用拉丁超立方采样方法采集n0组新工业过程数据,并将新工业过程数据映射到旧工业过程模型所对应的区间内,公式如下:
其中xo和xn分别对应旧工业过程和新工业过程的输入,xo,min和xo,max是旧工业过程运行区间下限和上限,xn,min和xn,max是新工业过程运行区间的下限和上限。
所述步骤c包含:对于选定的n个相似旧工业过程模型m1,m2,...,mn和训练数据集d={(y1,x1),(y2,x2),…,(yn,xn)},输出值y的概率分布函数可以被描述为:
其中pi(y|mi,d)是在给定第i个旧工业过程模型mi和训练数据集d下y的后验分布,p(mi|d)是旧工业过程模型mi的权重,即wi=p(mi|d)且
利用期望最大化(expectation-maximization,em)算法估计wi的值,步骤如下:
1)设置t=0,计算初始值:
2)计算初始似然函数值:
其中gp(x)是高斯函数;
3)设置t=t+1,计算
4)计算权值:
更新似然函数值;
5)计算δ=l(w,σ)t-l(w,σ)t-1,如果δ≤δ0就结束算法。否则,返回第3)步。
根据获得的wi值,可得到旧工业过程模型融合输出为
所述步骤e中嵌套拉丁超立方设计为:假设初始实验中通过lhd运行n0次采集的数据序列为
1)计算
2)从
3)通过
4)运行n1次逐行相加a和c得到b;
所述步骤e中实验停止条件为:选取交叉验证误差(meancrossvalidationerror,mean_cve)作为阈值来判断数据采集循环继续与否,具体过程如下:
1)通过lhd采集初始的n0个实验数据;
2)设置t=0;
3)使用nt个新工业过程数据训练迁移模型;
4)计算mean_cve,
其中yi是新工业过程的真值,yi'是由数据点(xi,yi)以外的数据建立的迁移模型的预测值;
5)如果mean_cve小于设定值则停止迁移模型训练,否则,令t=t+1,通过嵌套拉丁超立方方法采集(nt+1-nt)组新工业过程数据,扩大训练数据集
所述步骤e中模型验证为:利用均方根误差(rootmeansquareerror,rmse)和平均相对误差(meanrelativeerror,mre)来评估迁移模型的有效性,公式如下:
其中,n是测试数据的数量,yi是预测模型的输出,yi是新工业过程的真实输出。
本发明的有益效果是:
本发明通过采用了一种多模型融合迁移策略来为新工业过程建立性能预测模型,充分利用了工业中现有的相似旧工业过程的性能预测模型,利用贝叶斯模型平均理论得到最优的旧工业过程模型融合权值,并在尽可能少的运行数据支持下,利用最小二乘支持向量机对相似旧工业过程中的公共部分进行模型迁移训练,从而加快新工业过程的建模速度,降低了建模成本,获得符合精度要求的预测模型。同时该方法比单模型迁移和纯lssvm建模方法需要的实验数据信息更少,预测精度更高,几乎接近实际输出,为复杂工业过程建模降低了大量成本。
附图说明
下面结合附图和具体实例对本发明做进一步描述:
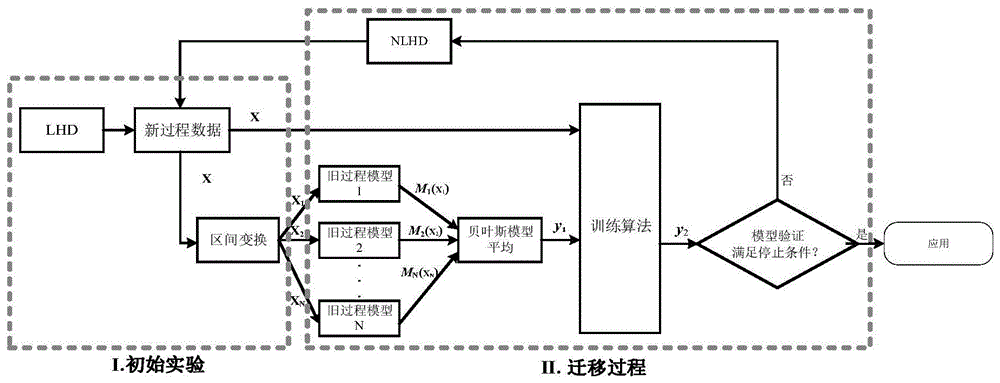
图1是多模型迁移策略示意图;
图2是多模型迁移方法中旧压缩机b,c和d的融合权重;
图3是多模型迁移模型,单模型迁移模型和纯lssvm模型的压力比的预测结果;
图4是多模型迁移模型,单模型迁移模型和纯lssvm模型的压力比的rmse。
具体实施办法
下面结合附图及具体实施例对本发明进行详细说明。
如图1所示,一种基于多模型迁移和bma理论的复杂工业过程低成本建模方法,在对新工业过程进行建模时,充分利用了已有相似工业过程的有用信息,同时将新工业过程建模所需要的数据量降至最低,其具体步骤如下:
a、选取已有相似旧工业过程模型mi(x),i=1,…,n;
b、利用拉丁超立方(latinhypercubedesign,lhd)采样方法,采集新工业过程建模初始数据集,同时映射新工业过程数据至旧工业过程模型的可行区间;
c、用贝叶斯模型平均理论评估旧工业过程模型对新工业过程建模的权重,获得旧工业过程模型融合输出为
d、多模型迁移策略,训练新工业过程模型。将旧工业过程模型融合输出y1和新工业过程输入数据x作为多模型迁移策略的输入数据,利用取最小二乘支持向量机(leastsquaressupportvectormachine,lssvm)算法训练新工业过程模型,获得新工业过程模型输出y2,完成新工业过程建模;
e、模型验证,若步骤d所得模型满足实验停止条件,则模型迁移训练结束,否则,利用嵌套拉丁超立方设计(nestedlatinhypercubedesign,nlhd)来采集新工业过程样本,继续训练新工业过程模型,直至满足实验停止条件。
所述步骤a包含:根据“25%规则”(g.e.box,j.s.hunterandw.g.hunter,statisticsforexperimenters:design,innovation,anddiscovery,vol.2,newyork,ny,usa:wiley,2005.)确定初始数据集大小n0,即n0≤0.25*t,t为实验预算;利用拉丁超立方采样方法采集n0组新工业过程数据,并将新工业过程数据映射到旧工业过程模型所对应的区间内,公式如下:
其中xo和xn分别对应旧工业过程和新工业过程的输入,xo,min和xo,max是旧工业过程运行区间下限和上限,xn,min和xn,max是新工业过程运行区间的下限和上限。具体实施例中的新旧压缩机稳定运行区间如表1所示(a是新压缩机,b、c、d是旧压缩机),
表1.新旧压缩机稳定运行区间
所述步骤c包含:对于选定的n个相似旧工业过程模型m1,m2,...,mn和训练数据集d={(y1,x1),(y2,x2),…,(yn,xn)},输出值y的概率分布函数可以被描述为:
其中pi(y|mi,d)是在给定第i个旧工业过程模型mi和训练数据集d下y的后验分布,p(mi|d)是旧工业过程模型mi的权重,即wi=p(mi|d)且
利用期望最大化(expectation-maximization,em)算法估计wi的值,步骤如下:
1)设置t=0,计算初始值:
2)计算初始似然函数值:
其中gp(x)是高斯函数;
3)设置t=t+1,计算
4)计算权值:
更新似然函数值;
5)计算δ=l(w,σ)t-l(w,σ)t-1,如果δ≤δ0就结束算法。否则,返回第3)步。
根据获得的wi值,可得到旧工业过程模型融合输出为
所述步骤e中嵌套拉丁超立方设计为:假设初始实验中通过lhd运行n0次采集的数据序列为
1)计算
2)从
3)通过
4)运行n1次逐行相加a和c得到b;
所述步骤e中实验停止条件为:选取交叉验证误差(meancrossvalidationerror,mean_cve)作为阈值来判断数据采集循环继续与否,具体过程如下:
1)通过lhd采集初始的n0个实验数据;
2)设置t=0;
3)使用nt个新工业过程数据训练迁移模型;
4)计算mean_cve,
其中yi是新工业过程的真值,yi'是由数据点(xi,yi)以外的数据建立的迁移模型的预测值;
5)如果mean_cve小于设定值则停止迁移模型训练,否则,令t=t+1,通过嵌套拉丁超立方方法采集(nt+1-nt)组新工业过程数据,扩大训练数据集
所述步骤e中模型验证为:利用均方根误差(rootmeansquareerror,rmse)和平均相对误差(meanrelativeerror,mre)来评估迁移模型的有效性,公式如下:
其中,n是测试数据的数量,yi是预测模型的输出,yi是新工业过程的真实输出。
为了验证该方法的效果,利用所采集的实验数据样本分别建立基于多模型迁移的新压缩机性能预测模型、基于单模型迁移的新压缩机性能预测模型以及基于纯lssvm方法的新压缩机性能预测模型,并将三个模型的预测压比与实际输出进行对比,结果如图3可见,基于多模型迁移的建模方法预测精度要比其他两种建模方法预测精度高很多,具体数值的mean_cve如表2可见:随着新压缩机运行数据点的增加,三种模型的mean_cve都在逐渐的减少,所提方法在运行次数为20时满足实验停止的条件,其mean_cve=0.041<0.05,而其他两种方法的mean_cve都达不到实验停止要求。
表2.纯lssvm、单目标迁移和多目标迁移模型的输出值的mean_cve
表3列出了多模型迁移模型,单模型迁移模型和lssvm模型的压力比的rmse和mre,图4为三种模型的压力比的rmse曲线,从图表中可以看出,多模型方法的rmse和mre分别为0.0274和0.16%,均小于其他两种方法。
表3.三种建模方法预测的压力比的rmse和mre
由上述分析可知,本发明通过采用了一种多模型融合迁移策略来为新工业过程建立性能预测模型,充分利用了工业中现有的相似旧工业过程的性能预测模型,利用贝叶斯模型平均理论得到最优的旧工业过程模型融合权值,并在尽可能少的新压缩机运行数据支持下,利用最小二乘支持向量机对相似旧工业过程中的公共部分进行模型迁移训练,从而加快新工业过程的建模速度,降低了建模成本,获得符合精度要求的预测模型。同时该方法比单模型迁移和纯lssvm建模方法需要的实验数据信息更少,预测精度更高,几乎接近实际输出,为工业过程建模降低了大量成本。
- 还没有人留言评论。精彩留言会获得点赞!