一种基于差分矩阵的标签向量序列异常检测方法与流程
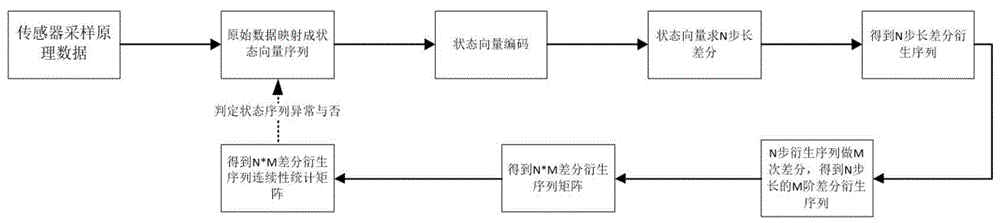
本发明涉及数据挖掘技术领域。提供了一种基于差分矩阵的标签向量序列异常检测方法。
技术背景
时间序列是按时间先后顺序收集的数值型数据序列,它广泛存在于金融、工业、商业、医疗、气象等领域中。股票交易所中随时间变化的股票价格、工厂中各种传感器采集的数据、商店每个月的商品销售量、患者的心电图、某地区的降水量等数据都是时间序列。
传统的数据挖掘中,异常值可能会被当作噪声剔除掉,以免影响数据挖掘的结果。然而在某些情形中,异常值包含了重要的信息,挖掘和分析异常值,能得到很多有用的知识。如地震数据中,异常值可能是一次地震的前兆;工厂中传感器数据的异常,可能表示着系统中某个部分出现了故障,及时发现异常并对系统故障进行维修,减少损失;生产线中零件进行一系列加工步骤时的检测值构成时间序列,检测其中的异常,可以判断每个步骤是否合格、最终加工的零件是否合格,进而指导生产,提高合格率。因此,时间序列中的异常检测具有重要的研究意义。
通过手机内置的传感器可获知手机的坐标及加速度等多维度数据,可以用整体法认为手机的状态即是手机使用者的状态。准确获取手机使用者状态可以作为重要的人群类别识别和分类,对于大数据人群画像具有重要意义。
对比文件cn201810575076.5,公开了一种时间序列异常点检测方法及装置,其主要构思是通过回归模型及输入的当前时刻前一段的时间序列预测当前时刻序列值,并根据预测得到的当前时刻序列值。其检测方式为对序列逐点检测异常点,检测效率不高。
技术实现要素:
对于单个状态标签,观测可能具有合理解释性,但是,当标签构成标签序列时,需要进一步对标签序列进行异常检验。本发明意在量化状态标签序列(在不产生歧义的前提下,可称该序列为原始标签序列)的连续性(在不产生歧义的前提下,本文中所提及“连续性”等价于“光滑性”),衍生出一簇衍生状态序列,量化这一簇状态序列的特性,特别是统计特性,反向对原始序列进行异常检测。
本发明为解决上述问题采用以下技术方案:
一种基于差分矩阵的标签向量序列异常检测方法,包括以下步骤:
步骤1:对标签向量进行编码,把已经标签化的序列(通常是时间序列)映射成线性空间中的高维向量;
步骤2:对标签向量序列做n步长*m阶的差分序列矩阵;
步骤3:对差分矩阵做统计性分析,得到差分序列矩阵对应的差分序列统计矩阵;
步骤4:通过差分序列统计矩阵对标签向量序列进行正常/异常识别。
上述技术方案中,步长差分定义:
定义有k维状态标签的状态标签向量为状态序列向量为
v=[a1,a2,a3,...,ak]
第i时刻的状态向量为
vi=[a1i,a2i,a3i,...,aki]
那么在i时刻的n步长差分向量定义为:
din=
[min(max(abs(a1i-a1i-1),abs(a1i-a1i-2),...,abs(a1i-a1i-n),0),1),
...,
min(max(abs(aki-aki-1),abs(aki-aki-2),...,abs(aki-aki-n),0),1)]
解释:
abs(aki-aki-1):第状态码ak第i个序列值与第i-1个序列值的差值绝对值,因为在后续的运算中需要取最大值,所以为了避免负数造成的影响,对差值结果取绝对值,保证了状态只要有不同,则状态差值绝对值肯定大于等于1;
max(abs(a1i-a1i-1),abs(a1i-a1i-2),...,abs(a1i-a1i-n),0),
若a1i与a1i-1,a1i-2,...,a1i-n中任意一个状态不同,则其
max(abs(a1i-a1i-1),abs(a1i-a1i-2),...,abs(a1i-a1i-n),0)>0
可以做的推断有:
max(abs(a1i-a1i-1),abs(a1i-a1i-2),...,abs(a1i-a1i-n),0)=0当且仅当
a1i=a1i-1=a1i-2=...=a1i-n,即在n步内,
a1的状态没有发生变化;
min(max(abs(a1i-a1i-1),abs(a1i-a1i-2),...,abs(a1i-a1i-n),0),1)把状态差分映射到[0,1]二元状态集,
即当min(max(abs(a1i-a1i-1),abs(a1i-a1i-2),...,abs(a1i-a1i-n),0),1)=0,则意味着在n步内,
a1的状态没有发生变化;
当min(max(abs(a1i-a1i-1),abs(a1i-a1i-2),…,abs(a1i-a1i-n),0),1)=1,在n步内,
a1的状态有发生变化。
可以做的推断:
当n=1时,是特殊的一步步长状态差分,差分向量用于刻画当前时刻标签与前一时刻标签是否有变化。
m阶差分定义:
对标签序列做一次n步长的差分叫做n步的一阶差分;
对一阶差分继续做n步长的差分叫做n步的二阶差分;
以此类推,即m阶差分序列的阶数等价于做差分的次数。
上述技术方案中,步骤3包括,对n*m的差分矩阵的各个状态标签按某种或者某几种统计量进行统计,得到该统计量统计矩阵,即得到n*m差分衍生序列连续性统计矩阵。
上述技术方案中,对n*m的差分矩阵的各个状态标签进行统计,统计各个状态标签值为1的百分比,得到n*m的统计矩阵。
上述技术方案中,步骤4包括,步骤4.1:构造差分序列矩阵的断点率矩阵作为差分序列统计矩阵;
步骤4.2:设定1步长1阶及2步长1阶差分序列的断点率其中之一超过30%,即判定原始序列为异常。
本发明因为采用了上述技术方案因此具备以下有益效果:
1:本发明不是逐点检测异常点,而是对整个序列的异常与否做整体性检测;
2:本发明不修改序列值,只对序列做检测,不用改变序列值本身,保持序列原始信息;
3:本发明使用的算法消耗存储空间较小,存储量是原始标签序列的m*n倍,没有中间过渡数据集的存储;计算量较小,不会涉及复杂的数学运算,无迭代运算结构,对计算性能消耗较小。
附图说明
图1为本发明流程示意图;
图2为时序序列表;
图3为状态编码向量表;
图4为状态标签表;
图5为状态向量序列表;
图6为序列矩阵表
图7为断点率统计表。
具体实施方法
为了是本发明的目的看技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,所描述的具体实例仅用以解释本发明,并不限定于本发明。
一种基于差分矩阵的标签向量序列异常检测方法,包括以下步骤:
步骤1:对标签向量进行编码,把已经标签化的序列(通常是时间序列)映射成线性空间中的高维向量;
步骤2:对标签向量序列做n步长*m阶的差分序列矩阵;
步骤3:对差分矩阵做统计性分析,得到差分序列矩阵对应的差分序列统计矩阵;
步骤4:通过差分序列统计矩阵对标签向量序列进行正常/异常识别。
上述技术方案中,步长差分定义:
定义有k维状态标签的状态标签向量为状态序列向量为
v=[a1,a2,a3,...,ak]
第i时刻的状态向量为
vi=[a1i,a2i,a3i,...,aki]
那么在i时刻的n步长差分向量定义为:
din=
[min(max(abs(a1i-a1i-1),abs(a1i-a1i-2),...,abs(a1i-a1i-n),0),1),
...,
min(max(abs(aki-aki-1),abs(aki-aki-2),...,abs(aki-aki-n),0),1)]
解释:
abs(aki-aki-1):第状态码ak第i个序列值与第i-1个序列值的差值绝对值,因为在后续的运算中需要取最大值,所以为了避免负数造成的影响,对差值结果取绝对值,保证了状态只要有不同,则状态差值绝对值肯定大于等于1;
max(abs(a1i-a1i-1),abs(a1i-a1i-2),...,abs(a1i-a1i-n),0),
若a1i与a1i-1,a1i-2,...,a1i-n中任意一个状态不同,则其
max(abs(a1i-a1i-1),abs(a1i-a1i-2),...,abs(a1i-a1i-n),0)>0
可以做的推断有:
max(abs(a1i-a1i-1),abs(a1i-a1i-2),...,abs(a1i-a1i-n),0)=0当且仅当
a1i=a1i-1=a1i-2=...=a1i-n,即在n步内,
a1的状态没有发生变化;
min(max(abs(a1i-a1i-1),abs(a1i-a1i-2),...,abs(a1i-a1i-n),0),1)把状态差分映射到[0,1]二元状态集,
即当min(max(abs(a1i-a1i-1),abs(a1i-a1i-2),...,abs(a1i-a1i-n),0),1)=0,则意味着在n步内,
a1的状态没有发生变化;
当min(max(abs(a1i-a1i-1),abs(a1i-a1i-2),...,abs(a1i-a1i-n),0),1)=1,在n步内,
a1的状态有发生变化。
可以做的推断:
当n=1时,是特殊的一步步长状态差分,差分向量用于刻画当前时刻标签与前一时刻标签是否有变化。
m阶差分定义:
对标签序列做一次n步长的差分叫做n步的一阶差分;
对一阶差分继续做n步长的差分叫做n步的二阶差分;
以此类推,即m阶差分序列的阶数等价于做差分的次数。
上述技术方案中,步骤3包括,对n*m的差分矩阵的各个状态标签按某种或者某几种统计量进行统计,得到该统计量统计矩阵。
上述技术方案中,对n*m的差分矩阵的各个状态标签进行统计,统计各个状态标签值为1的百分比,得到n*m的统计矩阵。
上述技术方案中,步骤4包括,步骤4.1:构造差分序列矩阵的断点率矩阵作为差分序列统计矩阵;
对n*m的差分矩阵的各个状态标签按某种或者某几种统计量进行统计,得到该统计量的统计矩阵。需要说明的是,断点率统计只是其中最自然最直接的统计量,若对断点率做统计,则统计各个状态标签值为1的百分比,得到n*m的断点率统计矩阵,则可以使用断点率统计矩阵作为n*m差分矩阵对应的统计矩阵。
步骤4.2:设定1步长1阶及2步长1阶差分序列的断点率其中之一超过30%,即判定原始序列为异常。
例如,步骤4.2设定“手机使用者处于行走状态序列,一阶的断点率大于30%则判定为异常,小于等于30%则为正常”为博蒙的判别规则;
则在4.1中计算“手机使用者处于行走状态”断点率,算出来的值去匹配4.2的规则即可。
实施例:
步骤一:通过phyphoxapp手机传感器数据采集工具采集手机状态信息,实验设计的参数为:
传感器类型:accelerometer以及gyroscope两个传感器,
采样频率:50hz
采样时长:>=50秒
得到如下的时间序列(aceelerometer,时间长度=1秒),如图2所示,
步骤二:
对感兴趣的状态变量进行编码,本例中主要关心
用户在6种行为(走路1,静止2,上楼3,下楼4,私家车5,公交车6,地铁7),2种动作(打字1,不打字2),以及2种姿势(站1,坐2)一共20种用户交互额合理场景下的状态标签,状态标签构成三维向量。
下面是各种情况的标注情况,对状态进行编码,形成状态编码向量,如图3所示:
步骤三,在利用第二步的状态编码,对第一步得到的数据进行状态识别,每0.5秒得到一个状态标签,如图4所示;
步骤四:
前面三个步骤展示了如何将传感器的数据映射成状态标签,状态标签码,以及状态标签码组成的向量,在步骤三中,我们得到两个状态向量序列,即[[7,1,1],[7,1,1]]
现假定我们得到了一组状态向量序列,如图5所示,
显然,在行为码中,0.5s之内反复切换打字和不打字的状态,这在真实环境中极大概率是不成立的,所以,本发明的目的就在于引入类似于刻画函数曲线连续性(光滑性)的方法,排除这类异常的状态序列。
我们通过图5的原始标签序列,通过定义得到以下2步长*2阶的序列矩阵,如图6所示:
步骤五:
对n*m的序列矩阵做各个状态标签上的统计,例如,对a1统计关于1出现(即状态发生变化)的频数统计,得到n*m的矩阵,对于该矩阵,我们可以设置判定规则,满足n*m的矩阵的设定的判定规则,则判定该状态为正常状态,否则判定其为非正常状态,图7简单统计得到2步长*2阶的序列矩阵间断点率,姿势码的1步长1阶及2步长1阶差分序列间断点率均为100%,1步长2阶差分序列间断点率及2步长2阶差分序列间断点率均为0。姿势码的差分序列间断点率已于其他状态码断点率,与原始标签序列观测到的异常情况一致。
- 还没有人留言评论。精彩留言会获得点赞!