一种用自适应控制学习改进生成对抗网络方法与流程
本发明属于对抗网络技术领域,尤其涉及一种用自适应控制学习改进生成对抗网络方法。
背景技术:
生成对抗网络(gan)可有效地合成各种应用的样本,如图像生成、工业设计、语音合成和自然语言处理。gan的目标是交替地训练生成器模型g和判别器模型d。gan的g和d通常选择使用多层感知机(mlp)或卷积神经网络(cnn)。生成器接受一组噪声先验来模拟真实的的数据分布,模拟出的分布叫做生成数据分布,而判别器被训练以提取真实数据的区别特征。更具体地,判别器判断一个数据是来自真实数据分布的概率;,输出概率和真实标签的误差用于指导判别器和生成器网络的参数更新。该过程交替进行,直到d不能区分真实和合成数据。
在实践中,gan以其不稳定行为(不稳定性)和模式崩溃问题而闻名,特别是在对包含各种视觉对象的数据集合进行训练时。使问题复杂化的两个主要问题是:1)在训练过程中生成器和判别器模型能力的不均衡,这阻碍生成器有效学习真实数据分布;2)缺乏可计算、可解释的收敛标准。
最近,一些国内外研究或发明集中在如何提高原始gan的稳定性,它们采取的策略主要是采用启发式方法,通过简化训练前期真实数据分布,逐步指导g的训练,例如在图像生成领域,让gan先试着训练不清晰的图像,或者较小的图像,随后渐渐清晰化或者扩大图像的尺寸。这种启发式学习方法可以一定程度上稳定训练。但这种由模糊渐渐变清晰或由小渐渐变大的过程不依赖g和d能力的均衡成长(竞争),而是依赖于一个预先定义好的渐近函数。这种方法对不同的数据集和gan模型变体极其敏感,难以应用于真实应用场景。与现有的研究或发明不同,本发明提出了一种基于对数据集自适应,动态地调整超参数来引导生成器和判别器学习进程的方法来解决gan训练不稳定性问题。
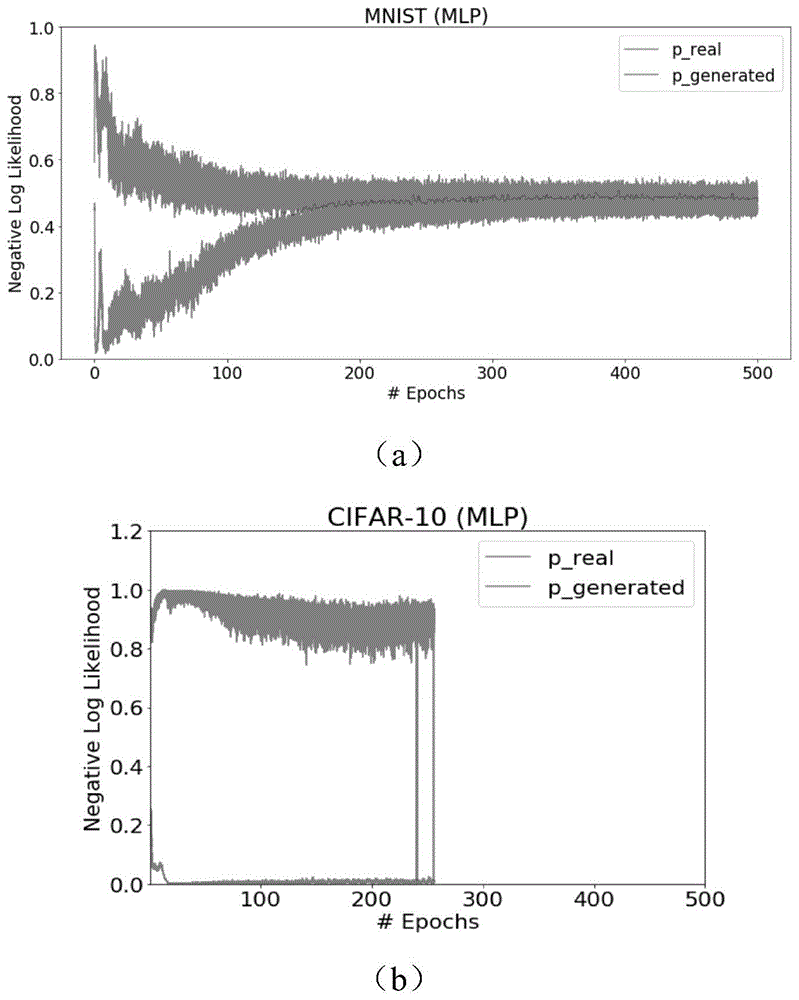
gan在简单数据集上容易训练成功,即g和d的能力能均衡的增长或降低,最终g达到了生成逼真图像的目的,而d最终不能准确区别真实图像和生成图像的差异。本项目提出的基于基准值自适应调参的方法建立在这样一个观察:简单数据集上训练正常的gan之中d的两个概率输出值(pr和pg)呈现与图6(a)相似的趋势与走向,同时g和d的损失函数输出值(lg和ld)呈现与图6(b)相似的趋势与走向。而图6(c)展示了一个失败的gan训练走向图。
基于这个观察,本项目拟使用gan在mnist上训练并获取的两组曲线做为基准线:一组展示d的两个概率输出值(pmr和pmg);另一组展示g和d的损失函数值(lmg和lmd)。这两组基准值曲线通过结合控制算法来指导gan在复杂图像上的训练进程。
综上所述,现有技术存在的问题如下:
传统gan不稳定和模式崩溃,特别是在对包含多种复杂视觉对象的数据集合进行训练时;
现有技术中,使问题复杂化的两个主要问题是:在训练过程中生成器和判别器的模型能力不均衡增长,这阻碍了发电机的有效学习;缺乏可计算、可解释的收敛标准。
本发明的实际意义:
自适应的gan训练方法能拓展gan的应用领域并推进gan应用落地的进程。具体表现在以下几个方面:1)模型性能的提升,模型能更好地学习到真实数据分布,内容创作时更加逼真;2)自适应、可解释的人工智能技术,今日的深度神经网络为代表的人工智能技术缺少通用性和对数据及环境的自适应性,本项目关注的对不同数据集的自适应gan训练方法可一定范围内提升对数据的适应并为通用人工智能技术提供理论支撑。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种用自适应控制学习改进生成对抗网络方法。
本发明是这样实现的,一种用自适应控制学习改进生成对抗网络方法,所述用自适应控制学习改进生成对抗网络方法包括以下步骤:
步骤一、使用任意gan模型在相对简单的数据集上训练,直至收敛。记录收敛时的批次数(如500次)
步骤二、导出第一批次数至收敛批次数区间所有产生的损失值或判定概率值,并通过曲线拟合方法对这些值进行拟合,拟合后的值做为基准损失值(lmg和lmd)或基准概率值(pmr和pmg)
步骤三、在相对复杂数据集上训练gan。训练过程中在每c个批次数(迭代系数)之后比较并计算当前的输出值(lg、ld、pr和pg四者之一)与基准值的差异,如果该差异超过预先设置的阈值(α),则视情况对k值进行调整后训练g和d;如果该差值在阈值内,则不对k值做任何改动,训练g和d。
步骤四、反复运行步骤三,直至与所有的基准值比较完毕。
进一步,使用d和g的训练次数的比率k作为控制变量;动态调整k值满足不同数据集训练期间的约束;使用以下两个不等式约束来控制k;
其中pg是d将生成数据分类为真实数据的概率;pmg是在mnist上训练的得到的概率,指导pg值的基准值;ld是当前训练数据中d的损失值;lmd是在mnist上训练的基准损失值;α是预先定义的阈值。
符号定义
进一步,基于概率/损失值的自适应控制方法包括:
本发明的另一目的在于提供一种实施所述用自适应控制学习改进生成对抗网络方法的自适应控制学习改进生成对抗网络控制系统。
本发明的另一目的在于提供一种用自适应控制学习改进生成对抗网络计算机程序,所述用自适应控制学习改进生成对抗网络计算机程序实施权利要求1-3任意一项所述的用自适应控制学习改进生成对抗网络方法。
本发明的另一目的在于提供一种终端,所述终端搭载所述的用自适应控制学习改进生成对抗网络方法的控制器。
本发明的另一目的在于提供一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行所述的用自适应控制学习改进生成对抗网络方法。
由于pg或ld的标准学习曲线在训练过程中表现出相同的趋势,可使用上述基于pg的自适应控制方法来处理它们。在所提出的算法1中,当k大于1时,这意味着d被训练k步而g被训练一步。如果当前pg或ld超过阈值α定义的允许偏差,基于以下之一将d步(由k表示)增加或减少1。结果案例:正偏差
本发明的优点及积极效果为:
本发明提出了一种适用于gan的自适应超参数学习过程,以提高不同数据集的训练稳定性,从而保证生成图像的质量。这是通过使用在在相对简单、单一的数据集下获取的训练有素的学习曲线(基准线)来指导不同复杂度场景数据集上的训练过程来实现的。本发明还提出了具有mlp和dcgan架构的自适应gan模型,并进行了多种验证实验,结果表明,该方法确实可以提高原始gan训练的稳定性,并可以很好地推广到各种gan变种模型和不同场景的数据集。对于未来的工作,计划分析更好的生成样本度量,这可能会鼓励gan的收敛。此外,希望分析所提出的自适应控制机制在gan多模态学习中的作用,以扩展其可用范围。
本发明对传统gan进行了以下具体改进:
由于训练过程中d和g能力的增长不均衡,传统gan训练难以收敛到合适的数据生成能力,导致在某些数据集(尤其是应用场景较复杂的数据集)上数据生成效果不佳,本发明证明通过自适应地调整d和g的训练步骤或强度可以提高性能;
基于这一观察,提出了一种用于gan模型的自适应控制学习算法(所产生的新模型叫做ak-gan),其动态调整生成器和判别器的训练步骤的比率(k值);
提供了ak-gan与传统gan之间的性能比较,表明了该算法在生成图像质量方面的优越性。
符号定义
对比实验数据如下:
生成数据分布与真实数据分布间的相似度使用了业界常用的指标inceptionscore,其计算公式如下:
x是生成器生成数据分布(pg)的采样数据,p(y|x)是给定一个采样数据的条件下类别分布,p(y)是类别y的数据分布。dkl(p(y|x)||p(y))测量p(y|x)和p(y)之间的kl距离(kl-divergence)。inceptionscore可以定量地测量生成器的两个性能指标:生成的图像必须含有清晰可辨的物体,即p(y|x)的熵要低;同时生成器生成的图像必须满足多样性,即p(y)的熵要高。当一张图像的上述两个指标值越大,它所获得的inceptionscore越大,即p(y|x)和p(y)的kl距离越大。
下表比较了本发明与传统gan方法的性能评测,每个评测分数都是5万张图像所得分数的平均。数据集使用了anime和celeba,生成器和判别器均使用mlp架构。本发明提出的方法在两个数据集上都超越了传统方法。
表1.基于mlp架构的传统gan和本发明提出的模型(ak-gan)性能(inceptionscores)评测
表2.基于cnn架构的传统gan和本发明提出的模型(ak-gan)性能(inceptionscores)评测
附图说明
图1是本发明实施提供的用自适应控制学习改进生成对抗网络方法流程图。
图2是本发明实施提供的原始gan对具有不同多样性水平的数据收集的影响图。
图3是本发明实施提供的传统gan模型的学习曲线图。
图4是本发明实施提供的原始gan(mlp)和ak-gan(mlp)在动画数据集上的比较(从动画壁纸的图像板网站衍生出动漫面部,并裁剪图像仅包含面部。这些图像大小为96x这个数据集由51,223个彩色图像组成图)。
图5是本发明实施提供的动画数据集上原始gan(dcgan)和ak-gan(dcgan)的比较图。
图6是本发明实施提供的gan训练曲线图;
(a)、训练成功的gan概率值曲线图:p_real是d对真实图像输出的概率,p_generated是d对生成图像输出的概率图;(b)、训练成功的gan损失值曲线图:d_loss是d的损失值,g_loss是g的损失值图;(c)、训练失败的gan概率曲线图。
图7是本发明实施提供的表1分数所对应的生成图像;
图8是本发明实施提供的表2分数所对应的生成图像。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
传统gan不稳定和模式崩溃,特别是在对包含各种视觉对象的数据集合进行训练时;
现有技术中,使问题复杂化的两个主要问题是:在训练过程中生成器和判别器的模型容量不均衡增长,这阻碍了生成器的有效学习;缺乏可计算、可解释的收敛标准。
为解决现有技术的问题,下面结合具体方案对本发明的应用原理作详细描述。
如图1所示,本发明实施例提供的用自适应控制学习改进生成对抗网络方法包括以下步骤:
s101,使用任意gan模型在相对简单的数据集上训练,直至收敛。记录收敛时的批次数(如500次)
s102,导出第一批次数至收敛批次数区间所有产生的损失值或判定概率值,并通过曲线拟合方法对这些值进行拟合,拟合后的值做为基准损失值(lmg和lmd)或基准概率值(pmr和pmg)
s103,在相对复杂数据集上训练gan。训练过程中在每c个批次数(迭代系数)之后比较并计算当前的输出值(lg、ld、pr和pg四者之一)与基准值的差异,如果该差异超过预先设置的阈值(α),则视情况对k值进行调整后训练g和d;如果该差值在阈值内,则不对k值做任何改动,训练g和d。
s104,反复运行s103,直至与所有的基准值比较完毕。
作为本发明的优选实施例,本发明提供的基于pg或ld的自适应控制方法如下:
由于pg或ld的标准学习曲线在训练过程中表现出相同的趋势,使用相同的方法来控制它们。在所提出的算法1中,当k大于1时,这意味着d被训练k步而g被训练一步。如果当前pg或ld超过阈值α定义的允许偏差,基于以下之一将d步(由k表示)增加或减少1结果案例:正偏差
为进一步描述本发明具体方案的应用原理,下面结合实施例对本发明作进一步描述。
实施例:
1)、对抗生成网络
gan通过对抗过程来估计生成模型,其中生成器g与判别器d进行对弈。d的输入来自两个数据分布:真实数据和合成数据,后者由g生成。d被训练以最大化其能够将样本完全分类为真实或合成,而g则经过培训,可以最大限度地降低d分辨出合成数据的能力。在原始框架中,训练目标定义为极大极小化问题:
其中g是将输入噪声变量pz(z)映射到生成的数据分布pg的函数,而d是一个将数据空间映射到标量值的函数,其中每个值表示特定样本来自实际数据分布的概率。函数g和d构成gan网络,它们通常是的神经网络模型,并且在其目标函数上同时被训练。g和d的损失函数lg和ld被定义如下:
其中θd和θg是d和g的参数集。x(i)表示实际数据。g(z(i))是由g接受随机噪声z(i)后生成的合成数据。那么p(x(i);θd)是d将真实数据x分类为真实数据的概率。p(g(z(i));θd)是d将生成的数据g(z(i))分类为真实数据的概率。以下称为pr和pg。
2)、gan在图像合成方面,对包含相对单一类别的图像集合进行训练。这些包括mnist手写数字,卧室场景和简单动画人物,如图2(a)和图2(b)所示。然而,对于相对复杂类别的图像集合,gan通常不能产生令人满意的生成效果。例如,在cifar-10数据集上训练时,生成的物体可识别性差,如图2(c)和图2(d)所示。
平衡d和g的收敛是一个相当大的挑战。如果其中一个训练得过好,gan的训练就会变得不稳定。在实践中,d通常受到过度训练,因为在复杂数据集条件下,d在开始时太容易获胜。
跟踪并记录了mnist和cifar-10的训练曲线,如图3所示。该图描绘了在训练过程中由d估计的真实和合成数据来自真实数据分布的概率(分别为pr和pg)曲线。图3(a)显示了gan在mnist数据集上训练达到收敛的曲线图。观察可知,在开始时,pr和pg之间存在很大的差距,随着训练的进行,该差距逐渐变小,最终收敛于约概率值0.5。mnist的良好稳定性也反映在合成图像的相当高质量上,如图2(a)所示。然而,cifar-10的不良视觉效果可以通过不稳定的训练曲线来解释,如图3(b)所示。
3)、对gan的适应性训练算法
a.基本思路
提出方法的目标是通过使用训练有素的学习曲线指导各种数据集上的训练进程,以实现令人信服的表现。首先描述获得训练有素的学习曲线的方式,然后提出一种算法,该算法约束控制变量的当前值(例如,后验概率pr和pg,或损失值ld和lg)与基准值(训练有素的学习曲线的概率或损失值)之间的差异。
因为原始gan训练目标函数(objectivefunction)被定义为极大极小化双人游戏问题,所以确定g和d的收敛是非常困难的,因为d和g最小化各自的损失值,这样的对弈过程不能保证最终达到收敛。比起某一时刻的数值,完整的学习曲线通常是标识培训过程是否良性的有效手段。因此,使用上述学习曲线作为收敛的基准度量。
为pg和ld提出以下不等式约束,并且使用d和g之间的训练次数的比率(k)作为唯一控制变量。传统的gan实现将k设置为1,本发明采取动态调整k值的方法来满足不同数据集训练期间的稳定性控制。约束不等式公式如下。
其中pg是生成器在当前合成的数据逼真度量(概率);pmg是在mnist数据集上训练得到的标准概率;ld是当前训练数据中d的损失值;lmd是在mnist数据集上训练时d的标准损失值;α是限定当前值与标准值偏离程度的阈值。注意,α可以手动设置。大量实验结果显示将α设为0.2是比较合理的。
b.基于pg或ld的自适应控制
由于pg或ld的标准学习曲线在训练过程中表现出相同的趋势,使用相同的方法来控制它们。在所提出的算法1中,当k大于1时,这意味着d被训练k步而g被训练一步。如果当前pg或ld超过阈值α定义的允许偏差,基于以下之一将d步(由k表示)增加或减少1结果案例:正偏差
通过将其应用于具有mlp和cnn两种不同架构的gan模型来评估本发明(ak-gan)。
在图4中,显示了在不同数据集上使用基于mlp架构的ak-gan的实验结果。与传统gan模型生成的样本相比,自适应控制技术使gan能够捕获面部的可识别特征,例如面部轮廓和眼睛。但是,这些样品也经常产生噪音。此外,图像锐度仍有改善的空间。因此,还将所提出的自适应控制程序应用于dcgan架构,以进一步提高视觉质量,然后将动漫和celeba数据集的结果与传统的dcgan进行比较。图5显示,与传统dcgan相比,ak-gan模型生成具有更高质量的图像并减缓了模式崩溃现象。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!