一种样本数据的动态平衡方法及系统与流程
本发明属于数据处理技术领域,特别涉及一种样本数据的动态平衡方法及系统。
背景技术:
随着计算机科学与技术的发展,机器学习算法越来越广泛地应用于数据的分类中。一个分类神经网络模型上线使用后,在用户的不断使用过程中能够产生更多的标注数据。这些数据将会用于后续优化模型的训练中。随着新标注数据不断地产生,不同类别的数据量的差异也会越来越大。比如,一个判断是否为菜品的二分类模型,在上线之后,随着新标注数据量的增大,导致负样本的数量可能大于正样本的数量。如果把产生的所有新样本数据去做优化模型的训练,会造成分类数据的不平衡,从而导致有的类别学习速度会很慢。
现有技术中,在进行分类神经网络优化模型训练时,需要获取大量的样本数据。如果每一次等到优化模型需要样本数据时,再从数据库中读取和处理样本数据的话,就会大大降低优化模型的训练效率。另外,将样本数据从数据库中选定后,由选定的样本数据组成的训练集就不能改变了,也就是说不能使用数据库中所有的样本数据来训练优化模型。如果将整个数据库作为训练集,有不能平衡不同类别之间的样本数据的数据量。
因此,为解决上述技术问题,本发明提出一种对样本数据进行动态平衡的方法,使数据库中的所有样本数据都有机会用于模型训练,并且自动平衡不同类别之间的样本数据的数据量,并且随时动态加入新的样本数据而不用停止模型训练。
技术实现要素:
鉴于此,本发明的目的在于提供一种样本数据的动态平衡方法及系统,可以自动平衡不同类别的样本数据,使所有的样本数据均有机会被作为模型训练。
根据上述发明目的,本发明提供一种样本数据的动态平衡方法,所述方法包括:
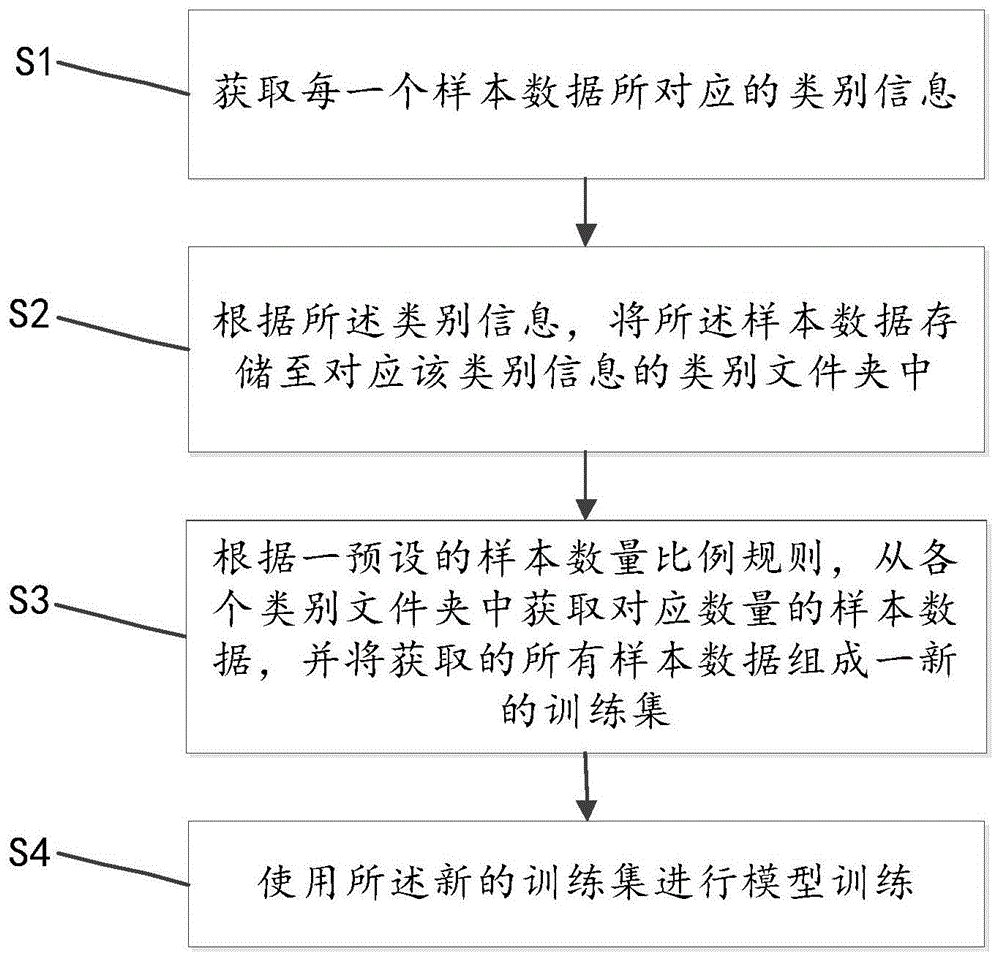
s1、获取每一个样本数据所对应的类别信息;
s2、根据所述类别信息,将所述样本数据存储至对应该类别信息的类别文件夹中;
s3、根据一预设的样本数量比例规则,从各个类别文件夹中获取对应数量的样本数据,并将获取的所有样本数据组成一新的训练集;
s4、使用所述新的训练集进行模型训练。
优选地,所述步骤s1包括:
采集样本数据;
根据构建的菜品分类模型,对每一个样本数据进行识别分类,获取每一个样本数据所对应的类别信息。
优选地,所述步骤s2还包括:
在样本数据库中建立多个类别文件夹,每一个类别文件夹的文件夹名称与所述类别信息相对应;
根据所述类别信息,将所述样本数据存储至对应该类别信息的类别文件夹中。
优选地,所述步骤s2还包括:
建立多个分类队列,每一个分类队列的队列名称与所述类别信息相对应;
在所述每一个分类队列中,存储一预设数量的样本数据,所述样本数据的分类信息与所述分类队列的队列名称相对应。
优选地,所述步骤s2还包括:
当所述分类队列为空时,获取所述分类队列的队列名称;
根据所述分类队列的队列名称,获取对应的类别信息;
根据所述类别信息对应的文件夹的名称,从对应的类别文件夹中读取样本数据,并存储至所述分类队列中。
优选地,所述步骤s3包括:
根据一预设的样本数量比例规则,从各个分类队列中获取对应数量的样本数据,并将获取的所有样本数据组成一新的训练集。
优选地,所述样本数量比例规则包括:
根据样本数据的样本特征显著性和分类模型设置比例值的大小。
根据上述发明目的,本发明提供一种样本数据的动态平衡系统,所述系统包括:
获取模块,用于获取每一个样本数据所对应的类别信息;
存储模块,用于根据所述类别信息,将所述样本数据存储至对应该类别信息的类别文件夹中;
训练集模块,用于根据一预设的样本数量比例规则,从各个类别文件夹中获取对应数量的样本数据,并将获取的所有样本数据组成一新的训练集;
训练模块,用于使用所述新的训练集进行模型训练。
优选地,所述存储模块包括:
类别文件夹单元,用于在样本数据库中建立多个类别文件夹,每一个类别文件夹的文件夹名称与所述类别信息相对应;
存储单元,用于根据所述类别信息,将所述样本数据存储至对应该类别信息的类别文件夹中。
优选地,所述存储模块还包括:
分类队列单元,用于建立多个分类队列,每一个分类队列的队列名称与所述类别信息相对应;
缓存单元,用于在所述每一个分类队列中,存储一预设数量的样本数据,所述样本数据的分类信息与所述分类队列的队列名称相对应。
与现有技术相比,本发明提供的样本数据的动态平衡方法及系统,具有以下有益效果:使数据库中的所有样本数据都有机会用于模型训练,并且自动平衡不同类别之间的样本数据的数据量;解决现有技术中模型训练从数据库中读取样本数据而导致训练效率降低的问题,通过使用分类队列来获取样本数据,动态获取训练集样本数据,可以使样本数据获取和模型训练同步进行,提高模型训练的效率,并且随时动态加入新的样本数据而不用停止模型训练。
附图说明
下面将以明确易懂的方式,结合附图说明优选实施方式,对一种样本数据的动态平衡方法及系统的上述特性、技术特征、优点及其实现方式予以进一步说明。
图1是本发明一种样本数据的动态平衡方法的流程图;
图2是本发明一种样本数据的动态平衡系统的组成结构图。
具体实施方式
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对照附图说明本发明的具体实施方式。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。
为使图面简洁,各图中只示意性地表示出了与本发明相关的部分,它们并不代表其作为产品的实际结构。另外,以使图面简洁便于理解,在有些图中具有相同结构或功能的部件,仅示意性地绘示了其中的一个,或仅标出了其中的一个。在本文中,“一个”不仅表示“仅此一个”,也可以表示“多于一个”的情形。
如图1所示,本发明的一个实施例,一种样本数据的动态平衡方法,所述方法包括:
s1、获取每一个样本数据所对应的类别信息;
s2、根据所述类别信息,将所述样本数据存储至对应该类别信息的类别文件夹中;
s3、根据一预设的样本数量比例规则,从各个类别文件夹中获取对应数量的样本数据,并将获取的所有样本数据组成一新的训练集;
s4、使用所述新的训练集进行模型训练。
一个分类神经网络模型上线使用后,在用户的不断使用过程中能够产生更多的标注数据。这些数据将会用于后续该模型的优化训练。具体地,采集样本数据,比如,对于菜品分类模型训练中,需要收集大量的菜品图像,通过网络爬虫,获取大量的菜品图像作为样本数据。通过构建的菜品分类模型,对每一个样本数据进行识别分类,获取每一个样本数据所对应的类别信息。该菜品分类模型对菜品图片进行识别,识别出该菜品的类别。如上述例子,对于菜品图像为西红柿炒鸡蛋来说,通过菜品识别模型识别该样本数据的类别信息为西红柿炒鸡蛋,对于菜品图像为青椒炒肉的图片来说,通过菜品识别模型识别该样本数据的类别信息为青椒炒肉。
根据所述类别信息,将所述样本数据存储至对应该类别信息的类别文件夹中。获取每一个样本数据的类别信息,根据该样本数据的类别信息,将该样本数据存储对应该类别信息的类别文件夹中。本发明的一具体实施例,在样本数据库中建立多个类别文件夹,每一个类别文件夹的文件夹名称与所述类别信息相对应;根据所述类别信息,将所述样本数据存储至对应该类别信息的类别文件夹中。比如,在样本数据库中建立文件夹名称为西红柿炒鸡蛋的类别文件夹,该文件夹的名称与类别信息为西红柿炒鸡蛋相对应。将类别信息为西红柿炒鸡蛋的所有样本数据都存储至该类别文件中。不同类别信息的样本数据存储至不同的类别文件中。将不同类别的样本数据进行区分。
本发明的一具体实施例,建立多个分类队列,每一个分类队列的队列名称与所述类别信息相对应。比如,建立队列名称为西红柿炒鸡蛋的分类队列,该分类队列的队列名称与类别信息为西红柿炒鸡蛋相对应。在该分类队列中,存储一预设数量的样本数据。在各个分类队列中,存储对应类型信息的样本数据。若分类队列为空时,获取所述分类队列的队列名称;根据所述分类队列的队列名称,获取对应的类别信息;根据所述类别信息对应的文件夹名称,从对应的类别文件中读取样本数据,存储至所述分类队列中。当菜品分类模型进行模型训练时,从该分类队列中直接获取样本数据,解决现有技术中模型训练从数据库中读取样本数据而导致训练效率降低的问题,通过使用分类队列来获取样本数据,可以使样本数据获取和模型训练同步进行。具体来说,在类别文件中存储大量的样本数据,在分类队列中存储一定数量的样本数据。将样本数据的存储和读取分开,在菜品分类模型进行模型训练时,从分列队列中取走需要的样本数据,分类队列中样本数据都已经被加载到内存并已经预处理好,所以可以很快地送入至模型中进行训练。并且只要当任何一个分列队列为空时,就从对应分类文件夹中读取样本数据,加载到该分类队列中,可使样本数据获取和模型训练同步进行,提供了模型训练的速度。
根据一预设的样本数量比例规则,从各个类别文件夹中获取对应数量的样本数据,并将获取的所有样本数据组成一新的训练集。本发明的一具体实施例,根据一预设的样本数量比例规则,从各个分类队列中获取对应数量的样本数据,并将获取的所有样本数据组成一新的训练集。设置样本数量比例规则,是将数据库的所有样本数据都有机会被用于训练,平衡不同类别之间的样本数据量。所述样本数量比例规则,根据样本数据的样本特征显著性和分类模型来设置比例值的大小。根据不同的二分类模型,选取的比例值不同。比如,样本特征显著性强的比例值可以大些,样本特征显著性弱的,比例可以值小些。本发明的一具体实施例,对于一个二分类模型,需要负样本数量是正样本数量的3倍。正样本是指要分类的类别信息所对应的样本数据,相反地,不是该类别信息的样本数据为负样本。比如,以菜品为例,对西红柿炒鸡蛋的类别信息进行模型训练,因此,类别信息为西红柿炒鸡蛋的样本数据是正样本,类别信息不是西红柿炒鸡蛋的样本数据为负样本。假设,本次训练需要32个样本数据,那么需要获取8个正样本数据,24个负样本数据。将这32个样本数据组成一个新的训练集。
使用所述新的训练集进行模型训练。使用新的训练集进行优化模型的训练。当这一个新的训练集训练完成后,再从分类队列中获取新的样本数据,形成下一次的新的训练集,进行模型训练。
通过该技术方案,使数据库中的所有样本数据都有机会用于模型训练,并且自动平衡不同类别之间的样本数据的数据量;解决现有技术中模型训练从数据库中读取样本数据而导致训练效率降低的问题,通过使用分类队列来获取样本数据,可以使样本数据获取和模型训练同步进行,提高模型训练的效率,并且随时动态加入新的样本数据而不用停止模型训练。
如图2所述,本发明的一实施例,本发明提供一种样本数据的动态平衡系统,所述系统包括:
获取模块20,用于获取每一个样本数据所对应的类别信息;
存储模块21,用于根据所述类别信息,将所述样本数据存储至对应该类别信息的类别文件夹中;
训练集模块22,用于根据一预设的样本数量比例规则,从各个类别文件夹中获取对应数量的样本数据,并将获取的所有样本数据组成一新的训练集;
训练模块23,用于使用所述新的训练集进行模型训练。
所述获取模块获取每一个样本数据所对应的类别信息。具体地,所述存储模块采集样本数据,比如通过网络爬虫,获取大量的菜品图像作为样本数据。存储模块通过构建的菜品分类模型,对每一个样本数据进行识别分类,获取每一个样本数据所对应的类别信息。比如,对于菜品图像为西红柿炒鸡蛋来说,通过菜品分类模型识别该样本数据的类别信息为西红柿炒鸡蛋。
所述存储模块根据所述类别信息,将所述样本数据存储至对应该类别信息的类别文件夹中。所述存储模块具体包括类别文件夹单元和存储单元。所述类别文件夹单元在样本数据库中建立多个类别文件夹,每一个类别文件夹的文件夹名称与所述类别信息相对应。所述存储单元根据所述类别信息,将所述样本数据存储至对应该类别信息的类别文件夹中。比如,在样本数据库中建立文件夹名称为西红柿炒鸡蛋的类别文件夹,该文件夹的名称与类别信息为西红柿炒鸡蛋相对应。将类别信息为西红柿炒鸡蛋的所有样本数据都存储至该类别文件中。不同类别信息的样本数据存储至不同的类别文件中。
本发明的一具体实施例,所述存储模块还包括分类队列单元和缓存单元。所述分类队列单元建立多个分类队列,每一个分类队列的队列名称与所述类别信息相对应。所述缓存单元在所述每一个分类队列中,存储一预设数量的样本数据,所述样本数据的分类信息与所述分类队列的队列名称相对应。若分类队列为空时,获取所述分类队列的队列名称;根据所述分类队列的队列名称,获取对应的类别信息;根据所述类别信息对应的类别文件夹,从所述对应的类别文件中读取样本数据,存储至所述分类队列中。通过使用分类队列来获取样本数据,可以使样本数据获取和模型训练同步进行。将样本数据的存储和读取分开,在菜品分类模型进行模型训练时,从分列队列中不同取走需要的样本数据,分类队列中样本数据都已经被加载到内存并已经预处理好,所以可以很快地送入至模型中进行训练。
所述训练集模块根据一预设的样本数量比例规则,从各个类别文件夹中获取对应数量的样本数据,并将获取的所有样本数据组成一新的训练集。具体地,根据一预设的样本数量比例规则,从各个分类队列中获取对应数量的样本数据,并将获取的所有样本数据组成一新的训练集。所述样本数量比例规则,根据样本数据的样本特征显著性和分类模型来设置比例值的大小。根据不同的二分类模型,选取的比例值不同。比如,样本特征显著性强的比例值可以大些,样本特征显著性弱的,比例可以值小些。
所述训练模块使用所述新的训练集进行模型训练。使用新的训练集进行优化模型的训练。当这一个新的训练集训练完成后,再从分类队列中获取新的样本数据,形成下一次的新的训练集,进行模型训练。
通过该技术方案,使数据库中的所有样本数据都有机会用于模型训练,并且自动平衡不同类别之间的样本数据的数据量;解决现有技术中模型训练从数据库中读取样本数据而导致训练效率降低的问题,通过使用分类队列来获取样本数据,可以使样本数据获取和模型训练同步进行,提高模型训练的效率。
综上所述,本发明能够自动平衡不同类别的样本数据,使所有的样本数据均有机会被作为模型训练,并且动态获取训练集样本数据。
应当说明的是,上述实施例均可根据需要自由组合。以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!