一种基于BP神经网络的燃气机组碳排放量的核算方法与流程
本发明涉及碳排放检测技术领域,更为具体来说,本发明为一种基于bp神经网络的燃气机组碳排放量的核算方法。
背景技术:
随着人们对环境问题的日益重视,许多国家提出了严格的碳减排目标,比如,在2017年,中国全面启动了全国碳排放交易市场,电力行业作为最大的二氧化碳排放源,被纳入碳排放交易体系,而且在第一阶段以电力行业为全国碳排放交易体系的突破口,以希望使碳排放总量能够得到有效控制。
目前,碳排放量的核算往往依赖于排放因子进行计算,但火电企业的实际情况千差万别,现有基于排放因子的碳排放量核算方法往往难以准确核算不同火电企业的碳排放量,比如,对不同企业的燃气机组采用相同的排放因子和参数进行碳排放量核算,核算结果的准确性较差、可信度较差,不准确、不公平、可信度较差的核算结果会影响碳交易的鼓励机制和惩罚机制,进而会导致对积极参与碳减排的企业激励不够、对不履行碳减排的企业约束力小等问题,所以现有的碳排量的核算方法阻碍了碳市场交易的活跃度。另外,由于现有核算方法只能在排放之后进行核算,所以现有的核算方法的实时性也比较差,无法实现对碳排量进行及时核算、无法及时报送碳排量核算结果。
因此,如何能够实现对燃气机组碳排量的准确且及时核算,成为了本领域技术人员亟待解决的技术问题和始终研究的重点。
技术实现要素:
为解决现有基于排放因子的燃气机组碳排放量核算方法存在的准确性差、无法及时报送等问题,本发明创新提供了一种基于bp神经网络的燃气机组碳排放量的核算方法,具体为一种基于bp神经网络的燃气机组碳排放异常数据筛查机制,对燃气机组可能产生的碳排放异常数据监测值进行筛查,保证碳排放量核算结果的真实有效性;而且,本发明将有助于准确且完整地获取火电行业碳排放实时数据,为火电行业参与碳排放交易提供了坚实的数据支持。
为实现上述技术目的,本发明公开了一种基于bp神经网络的燃气机组碳排放量的核算方法,该核算方法包括如下步骤;
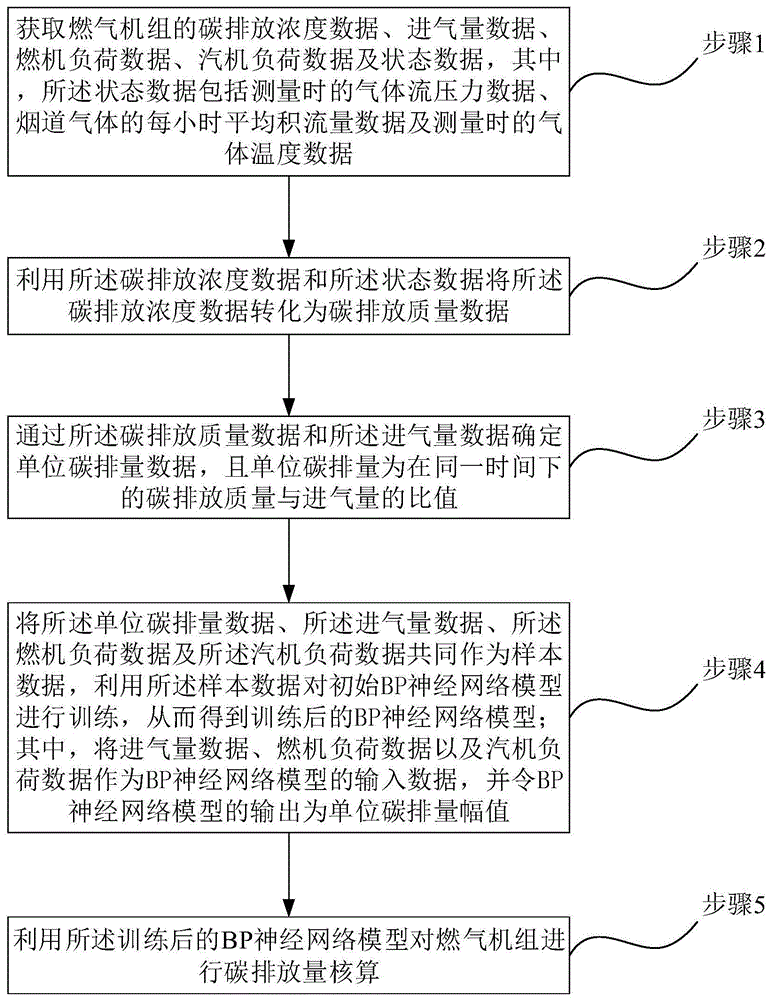
步骤1,获取燃气机组的碳排放浓度数据、进气量数据、燃机负荷数据、汽机负荷数据及状态数据,其中,所述状态数据包括测量时的气体流压力数据、烟道气体的每小时平均积流量数据及测量时的气体温度数据;
步骤2,利用所述碳排放浓度数据和所述状态数据将所述碳排放浓度数据转化为碳排放质量数据;
步骤3,通过所述碳排放质量数据和所述进气量数据确定单位碳排量数据,且单位碳排量为在同一时间下的碳排放质量与进气量的比值;
步骤4,将所述单位碳排量数据、所述进气量数据、所述燃机负荷数据及所述汽机负荷数据共同作为样本数据,利用所述样本数据对初始bp神经网络模型进行训练,从而得到训练后的bp神经网络模型;其中,将所述进气量数据、所述燃机负荷数据以及所述汽机负荷数据作为bp神经网络模型的输入数据,并令bp神经网络模型的输出为单位碳排量幅值;
步骤5,利用所述训练后的bp神经网络模型对燃气机组进行碳排放量核算。
基于上述的技术方案,本发明能够根据燃气机组碳排放相关历史数据得到用于核算碳排放的bp神经网络模型,从而实现准确且及时地对燃气机组碳排放数据进行核算,以较好地解决现有技术存在的诸多问题。
进一步地,步骤5包括如下步骤;
步骤5-1,利用所述训练后的bp神经网络模型确定随进气量变化而变化的单位碳排量波动幅值的预测区间;
步骤5-2,在进气量相同的情况下,将与待进行碳排放量核算的单位碳排量数据与所述单位碳排量波动幅值的预测区间进行比较,将预测区间之外的待进行碳排放量核算的单位碳排量数据剔除。
基于上述改进的技术方案,本发明提供了一种基于bp神经网络的碳排放量异常数据筛查机制,其能够对燃气机组碳排放异常数据进行有效地去除,保证碳排放量数据的准确性。
进一步地,步骤5-1中,利用所述随进气量变化而变化的单位碳排量波动幅值的预测区间确定碳排放基准线,所述碳排放基准线为随进气量变化而变化的单位碳排量曲线;
步骤5-2中,获取已被剔除的待进行碳排放量核算的单位碳排量数据对应的进气量数据,并将该进气量数据对应在基准线上的碳排量数据作为修正后的碳排量数据。
基于上述改进的技术方案,在保证碳排放数据的准确性的基础上,本发明还能够对燃气机组碳排放异常数据进行补充,保证了碳排放量数据的完整性,以准确地对燃气机组碳排放量进行核算。
进一步地,步骤2中,通过如下方式将所述碳排放浓度数据转化为碳排放质量数据;
其中,
进一步地,步骤2中,还包括将碳排放质量数据转换为水分校正处理后的碳排放质量数据的步骤;
步骤3中,利用进气量数据和所述水分校正处理后的碳排放质量数据计算单位碳排量。
进一步地,步骤2中,通过如下方式对碳排放质量数据进行水分校正处理;
其中,
基于上述改进的技术方案,通过直接处理碳排放干基数据,本发明还能够进一步地提高碳排放量核算的准确性。
进一步地,步骤4中,通过如下方式得到训练后的bp神经网络模型;
步骤4-1,对初始bp神经网络模型的隐层中各神经元进行初始化;
步骤4-2,将样本数据中的进气量数据、燃机负荷数据及汽机负荷数据送入至bp神经网络模型的输入层,然后计算bp神经网络模型的输出层给出的输出结果与样本数据中的单位碳排量之间的误差;
步骤4-3,如果所述误差大于或等于预设的精度值,则执行步骤4-4;如果所述误差小于预设的精度值,则执行步骤4-5;
步骤4-4,修正当前bp神经网络模型的隐层中各神经元的网络权值和阈值,然后返回步骤4-2;
步骤4-5,将当前bp神经网络模型作为训练后的bp神经网络模型。
进一步地,所述初始bp神经网络模型为3×k×1的三层bp神经网络模型,即所述三层bp神经网络模型的输入层数量为3、输出层数量为1、隐层数量为k,而且每个隐层具有l个神经元;其中,k≥1,3≤l≤12。
进一步地,所述三层bp神经网络模型具有一个隐层,通过如下方式确定该隐层具有的神经元个数;
其中,l表示隐层具有的神经元个数,n表示输入层的神经元个数,m表示输出层的神经元个数,a表示[1,10]之间的常数。
进一步地,步骤1中,从烟气连续监测系统中获取燃气机组的碳排放浓度数据、进气量数据、燃机负荷数据、汽机负荷数据及状态数据,且步骤1还包括将排口标定不为零时的数据和处于排口故障时间段内的数据剔除的步骤。
本发明的有益效果为:本发明能够对燃气机组的碳排放数据进行准确校核,包括对异常碳排放数据进行筛查和对剔除的数据进行合理补充,以实现对燃气机组碳排放量的准确且实时核算,保证火电行业碳排放数据的准确完整性,进而实现对积极参与碳减排的企业进行鼓励以及对不履行碳减排的企业进行强力约束的作用,为火电行业参与碳排放交易提供坚实的数据支持,从而推动碳市场交易的活跃度,进而彻底解决现有技术存在的诸多问题。
附图说明
图1为基于bp神经网络的燃气机组碳排放量的核算方法的流程示意图。
图2为随进气量变化而变化的单位碳排量波动幅值的预测区间示意图。
图3为随进气量变化而变化的单位碳排量幅值波动状态以及碳排放基准线示意图。
图4为bp神经网络应用模型的组成示意图。
具体实施方式
下面结合说明书附图对本发明提供的一种基于bp神经网络的燃气机组碳排放量的核算方法进行详细的解释和说明。
如图1至3所示,本实施例公开了一种基于bp神经网络的燃气机组碳排放量的核算方法,具体为一种基于bp神经网络的燃气机组二氧化碳排放量的核算方法;本实施例中,该核算方法包括如下步骤。
步骤1,获取燃气机组的碳排放浓度数据、进气量数据、燃机负荷数据、汽机负荷数据及状态数据,其中,状态数据包括测量时的气体流压力数据、烟道气体的每小时平均积流量数据及测量时的气体温度数据。具体来说,本发明用于对烟气连续排放进行监测,从烟气连续监测系统中获取燃气机组的碳排放浓度数据、进气量数据、燃机负荷数据、汽机负荷数据以及状态数据,实施时可通过已安装的针对火电行业灰尘、硫化物、氮化物等污染物排放的在线连续监测系统或者成熟的烟气排放连续监测系统(continuousemissionmonitoringsystemoffluegas,cems)获取上述数据,而且,本步骤还包括将排口标定不为零时的数据和处于排口故障时间段内的数据剔除的步骤,从而提高碳排放量核算的准确性。
步骤2,利用碳排放浓度数据和状态数据将碳排放浓度数据转化为碳排放质量数据,比如通过在先构建的碳排放连续监测模型将连续监测的碳排放浓度数据转化为碳排放质量数据。
具体地,步骤2中,本实施例通过如下方式将碳排放浓度数据转化为碳排放质量数据;
其中,
另外,为进一步提高本发明核算的准确性,步骤2中还包括将碳排放质量数据转换为水分校正处理后的碳排放质量数据的步骤,以实现对二氧化碳的干基测量。
步骤2中具体通过如下方式对碳排放质量数据进行水分校正处理:
其中,上述的
步骤3,通过碳排放质量数据和进气量数据确定单位碳排量数据,本实施例利用进气量数据和水分校正处理后的碳排放质量数据计算单位碳排量,其中,单位碳排量为在同一时间下的碳排放质量与进气量的比值,单位碳排量即单位进气量下的二氧化碳排放量。
步骤4,利用单位碳排量相对稳定且随机波动、受进气量变化的影响等特点,本实施例将单位碳排量数据、进气量数据、燃机负荷数据及汽机负荷数据共同作为样本数据,然后利用样本数据对初始bp神经网络模型(又称“反向神经网络”)进行训练,从而得到训练后的bp神经网络模型;其中,将进气量数据、燃机负荷数据以及汽机负荷数据作为bp神经网络模型的输入数据,并令bp神经网络模型的输出为单位碳排量幅值,即以单位碳排放量为输出;bp神经网络模型由输入层、隐层及输出层组成,在本步骤中,通过如下方式得到训练后的bp神经网络模型。
步骤4-1,对初始bp神经网络模型的隐层中各神经元进行初始化,本实施例初始bp神经网络模型为3×k×1的三层bp神经网络模型,即三层bp神经网络模型的输入层数量为3、输出层数量为1、隐层数量为k,而且每个隐层具有l个神经元;其中,k≥1,3≤l≤12。隐层k可以为一层或多层,有一个隐层的神经网络,只要隐节点足够多,就可以以任意精度逼近一个非线性函数,本实施例采用含有一个隐层的三层多输入单输出的bp网络建立预测模型,在网络设计过程中,隐层神经元数的确定十分重要,这是因为:隐层神经元个数过多,会加大网络计算量并容易产生过度拟合问题;神经元个数过少,则会影响网络性能,达不到预期效果,本实施例经过大量的试验和论证,最终确定本实施例三层bp神经网络模型具有一个隐层,通过如下方式确定该隐层具有的神经元个数(即节点数);
其中,l表示隐层具有的神经元个数,n表示输入层的神经元个数,m表示输出层的神经元个数,a表示[1,10]之间的常数。如图4所示,“gasinflow”表示进气量,“gasturbineload”表示燃机负荷,“steamturbineload”表示汽机负荷,“inputlayer”表示输入层,“implicitlayer”表示隐层,“outputlayer”表示输出层,“amplitude”表示碳排量幅值。
另外,本实施例中训练的bp神经网络采用sigmoid可微函数和线性函数作为网络的激励函数,并选择s型正切函数tansig作为隐层神经元的激励函数,由于网络的输出归一到[-1,1]范围内,因此预测模型选取s型对数函数tansig作为输出层神经元的激励函数。
步骤4-2,将样本数据中的进气量数据、燃机负荷数据及汽机负荷数据送入至bp神经网络模型的输入层,本实施例对燃气机组9e的碳排放相关数据作为样本数据,比如,选取燃气机组6月份的监测数据,并剔除停机状态数据(“燃机负荷<0.1mw或燃机进气量为负”),然后再计算bp神经网络模型的输出层给出的输出结果与样本数据的单位碳排量之间的误差。具体实施时,本实施例能够将样本数据划分为训练集和测试集,可随机选取各区间段内碳排放监测实际值作为测试集,从而得到筛选一系列异常碳排放数据的预测区间。
步骤4-3,如果误差大于或等于预设的精度值,则执行步骤4-4;如果误差小于预设的精度值,则执行步骤4-5。
步骤4-4,修正当前bp神经网络模型的隐层中各神经元的网络权值和阈值,从而使bp神经网络的误差函数沿负梯度方向下降、使结果逼近期望输出,然后返回步骤4-2。
步骤4-5,将当前bp神经网络模型作为训练后的bp神经网络模型。
步骤5,利用上述的训练后的bp神经网络模型对燃气机组进行碳排放量核算,本实施例的步骤5包括如下步骤5-1和步骤5-2。
步骤5-1,利用训练后的bp神经网络模型确定随进气量变化而变化的单位碳排量波动幅值的预测区间,本实施例以燃机进气量为横坐标、以单位碳排量(碳排放量/燃机进气量)为纵坐标作曲线图,并且删除单位碳排量>100或<10的异常点,由于进气量<12knm3/h时不稳定,因此横坐标进气量从12开始,另外,具体实施时,由于进气量<40knm3/h数据过少,补充1、2、3、4月中进气量<40knm3/h的点,本实施例得到进气量<40knm3/h的数据点共7757个,进气量>40knm3/h的数据点共9121个,将进气量12knm3/h~48knm3/h分为36个长度为1的区间,分别计算36个区间段内点集合均值,得到36个区间的碳排放基准线;将实测碳排放数据减去对应的区间的均值得到碳排放实测波动幅值,如图2、3所示,其中,“co2emissions/gasinflow”表示在同一时间下的碳排放质量与进气量的比值,“gasinflow”表示进气量,“baseline”表示碳排放基准线,“upperboundary”表示上边界,“lowerboundary”表示下边界,“textpoint”表示待进行碳排放量核算的单位碳排量测试点,“rawdata”表示随进气量变化而变化的单位碳排量波动幅值;在本步骤中利用随进气量变化而变化的单位碳排量波动幅值的预测区间确定碳排放基准线,碳排放基准线为随进气量变化而变化的单位碳排量曲线。如图3所示,当燃气进气量小于40时,燃气机组处于启动或停止以状态,在此期间进气量随时间波动较大,由于天然气燃烧不足导致单位碳排量降低,当进气量大于40时,燃气机组进入稳定运行状态,负荷率>75%,天然气的充分燃烧使得单位碳排量增加。bp神经网络输入层节点数为3,分别为燃机负荷、进气量和汽机负荷,输出层节点数为1为单位碳排放幅值,隐层神经元数为10,本实施例采用matlab神经网络工具箱8.2对16878组样本数据进行训练可知,当设置训练为10000时,曲线收敛的最优拟合误差为1.67%。
步骤5-2,在进气量相同的情况下,将与待进行碳排放量核算的单位碳排量数据与单位碳排量波动幅值的预测区间(数据)进行比较,将预测区间之外的待进行碳排放量核算的单位碳排量数据剔除;图2中的异常数据点为3个,且作为进一步优化的技术方案,本实施例在步骤5-2中获取已被剔除的待进行碳排放量核算的单位碳排量数据对应的进气量数据,并将该进气量数据(可为多个数据)对应在基准线上的碳排量数据作为修正后的碳排量数据。
在本说明书的描述中,参考术语“本实施例”、“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明实质内容上所作的任何修改、等同替换和简单改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!