一种可自动更新的用于金融文本分析的情感字典构建方法与流程
本发明属于文本情感分析和观点挖掘技术领域,具体是一种用于金融文本分析的情感词典构建方法。
背景技术:
投资者的情绪变化对其投资决策的影响巨大。大部分中小投资者的投资情绪易受社会舆论以及其他投资者的言论所左右。因此量化地计算分析投资者对个股以及各个板块的情绪值显得尤其重要,它能为投资者进行投资决策提供参考,亦能作为选股因子构建模型进行量化交易。因此,分析投资者情绪成为日前日趋重要的一个研究领域。
通过分析互联网上各种对有关金融市场的评论文本,可以有效地获得投资者对当下市场的看法,当前情感分析技术可以分为两类,一类是基于机器学习的方法,另一类是基于情感词典的方法。现有技术中中文情感词典的构建方法大致可以分为三类,一是基于知识库的构建方法,主要是在当前普遍认可的知网(hownet)情感词典、台湾大学简体中文情感极性词典(ntusd)等中文情感词典的基础上,通过词语扩展、统计词频等方法进行构建;二是基于语料库方法,常见的有so-pmi法等;三是知识库与语料库结合方法。然而,由于中文与英文的先天差异、中文语言分析工具不够成熟,以及生硬地照搬英文分析模型等原因,中文情感词典质量较差。此外,金融领域发展迅猛,大量新词、热词不断涌现,这使得基于传统情感词典的文本分析结果缺少准确性。因此为了更好地分析互联网上金融相关的语料,构建一个包含金融领域特定词语,并且可以准确分析新词,自动更新的情感词典必不可少。本发明提供一种可自动更新的用于金融文本分析的情感词典构建方法。
技术实现要素:
本发明的目的是提供一种可自动更新的用于金融文本分析的情感字典构建方法,其构建的词典可以用于金融文本语料的情感分析。
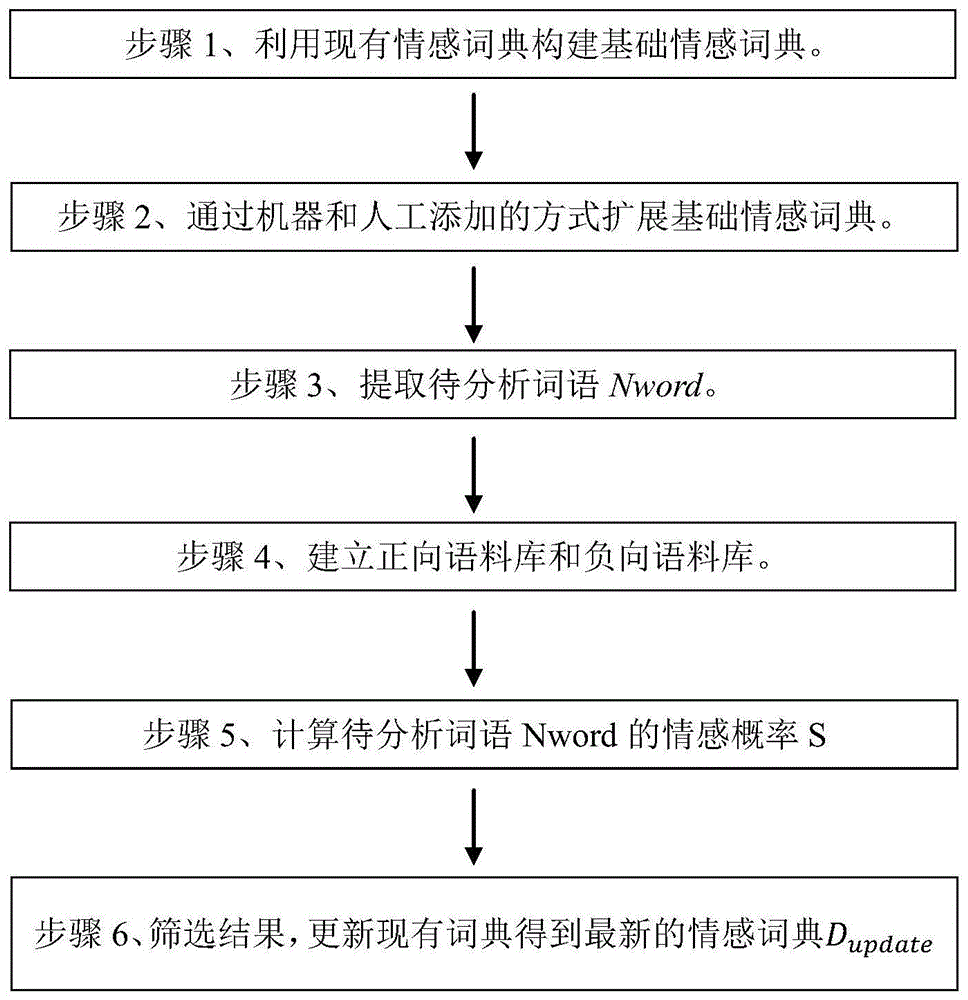
本发明所提供的情感词典构建方法具体如下:
步骤1、构建基础情感词典。整合现有的情感词典,本发明采用目前得到广泛认可的知网(hownet)情感词典和台湾大学简体中文情感极性词典(ntusd)。其中知网(hownet)情感词典包含的中文情感词典有:正面情感词语、正面评价词语、负面情感词语、负面评价词语、程度级别词语和主张词语。台湾大学简体中文情感极性词典包括:ntusd-negative和ntusd-positive两个情感词典。具体整合方法为将知网(hownet)里面的正面评价词语、正面情感词语和ntusd的positive词典合并去重得到正向情感词典,将知网(hownet)里面的负面评价词语、负面情感词语和ntusd的negative词典合并去重得到负向情感词典,由上述正向情感词典和负向情感词典构成基础情感词典dinitial。
步骤2、扩展基础情感词典。一是利用现有同义词词库对基础情感词典中情感词进行同义词扩展,现有同义词词库可以是《同义词词林》和/或《哈工大同义词词林拓展版》;二是人工添加具有情感色彩的网络新兴词汇;三是人工添加金融领域具有情感色彩的非情感词,如“三只乌鸦”、“直线拉升”等,得到扩展情感词典dextend。
步骤3、提取待分析词语nword。运用互联网工具抓取一定量金融文本语料。(1)运用互联网工具进行分词、去停用词、去噪等,得到分词语段库,去除扩展情感词典dextend中已经包含的词语、转折词、程度词以及非中文字符,采用词频法对所有词汇统计词频,并按词频由高到低排序,选取词频数大于n(n>0)的词语,然后,利用公式1计算每个语段的前缀和后缀的信息熵,设定信息熵阈值i,保留前缀和后缀信息熵都大于该阈值的语段,作为待分析词语nword;
其中w为语块,a为其前(后)缀,c为频数,然后根据具体计算结果,选取筛选效果理想(即识别为自然词汇相对准确)的数值作为信息熵阈值,优选信息熵阈值i>0.8。
(2)在语料库中对nword的邻近词(语段距离<m,0<m<8)进行频率排序,提取k个频率最高的词语,利用扩展情感词典dextend。确定k个频率最高词语中正向情感词的个数k正,负向情感词的个数k负。
上述分词工具可以是中国科学院的ictclas汉语分词系统、盘古分词、庖丁解牛、jie分词等中的一种;m优选范围为[4,8]。
步骤4、建立正向语料库和负向语料库。基于现有情感词典,对步骤3收集的金融文本语料进行情感分析,创建正向语料库和负向语料库,其中现有情感词典为扩展情感词典或上次更新的情感词典dhistory。
步骤5、计算待分析词语nword的情感概率s。首先利用公式2、3计算待分析词语nword同正向语料库的相关性概率pa正,同负向语料库的相关性概率pa负;然后利用公式4、5计算待分析词语nword的情感倾向概率pb正和pb负;利用公式6、7分别计算待分析词nword的正向情感p正和负向情感的概率p负;最后利用公式8计算待分析词语nword的情感概率s。
p正=α*pa正+β*pb正公式6
p负=α*pa负+β*pb负公式7
s=p正-p负公式8
其中,α+β=1,α≥0,β≥0。α、β的取值范围为[0.2,0.8],优选为α=[0.55,0.75],β=[0.25,0.45]。
步骤6、筛选结果,更新情感词典。
设置正向阀值
当s>0并且
上述
本发明所述情感词典构建方法利用知识库中的现有情感词典构成基础词典dinitial,通过机器添加以及人工添加的方式扩展基础情感词典,得到扩展情感词典dextend,通过计算前后缀信息熵提高提取新词的准确性,然后利用朴素贝叶斯分类器和情感倾向概率对语料库中提取的新词进行概率计算,通过设置阀值将满足条件的具有正向或负向情感的情感词添加到情感词典中。结果表明,同现有技术已有的情感词典构建方法相比有如下优点:(1)新词提取更为准确,减少噪音和后续计算量;(2)情感分析计算量小,通过参数优化,可以得到更为准确的情感分析结果;(3)情感词典可根据需要不断更新,从而提高了基于情感词典的金融文本情感分析方法的准确性。
附图说明
图1是本发明情感词典构建流程示意图;
图2是本发明情感词典构建程序中识别词汇部分程序。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干调整和改进。这些都属于本发明的保护范围。
图1、图2分别是本发明情感词典构建流程示意图和本发明情感词典构建程序中识别词汇部分程序。基于本发明的技术框架,现提供以下三个实施例加以进一步说明:
实施例1
步骤1、构建基础情感词典。整合现有的情感词典,本发明采用目前得到广泛认可的知网(hownet)情感词典和台湾大学简体中文情感极性词典(ntusd)。其中知网(hownet)情感词典包含的中文情感词典有:正面情感词语、正面评价词语、负面情感词语、负面评价词语、程度级别词语和主张词语。台湾大学简体中文情感极性词典包括:ntusd-negative和ntusd-positive两个情感词典。具体整合方法为将知网(hownet)里面的正面评价词语、正面情感词语和ntusd的positive词典合并去重得到正向情感词典,将知网(hownet)里面的负面评价词语、负面情感词语和ntusd的negative词典合并去重得到负向情感词典,由上述正向情感词典和负向情感词典构成基础情感词典dinitial。
步骤2、扩展基础情感词典。一是利用现有同义词词库对基础情感词典中情感词进行同义词扩展,现有同义词词库可以是《同义词词林》和/或《哈工大同义词词林拓展版》;二是人工添加具有情感色彩的网络新兴词汇;三是人工添加金融领域具有情感色彩的非情感词,如“三只乌鸦”、“直线拉升”等,得到扩展情感词典dextend。
步骤3、提取待分析词语nword。运用爬虫工具从股吧随机抓取2000篇2017年1月1日至2017年12月31日公布的金融文本语料,构成语料库c。(1)运用中国科学院的ictclas汉语分词系统进行分词、去停用词、去噪等,得到分词语段库,去除扩展情感词典dextend中已经包含的词语、转折词、程度词以及非中文字符,采用词频法对所有词汇统计词频,并按词频由高到低排序,选取词频数大于5的词语,然后,利用公式1计算每个语段的前缀和后缀的信息熵,设定信息熵阈值i,保留前缀和后缀信息熵都大于该阈值的语段,作为待分析词语nword;
其中w为语块,a为其前(后)缀,c为频数,信息熵阈值i=1.1。
(2)在语料库c中对nword的邻近词(语段距离≤6)进行频率排序,提取k个频率最高的词语,利用扩展情感词典dextend。确定k个频率最高词语中正向情感词的个数k正,负向情感词的个数k负。
步骤4、建立正向语料库和负向语料库。基于现有情感词典,对步骤3收集的金融文本语料库c进行情感分析,创建正向语料库c正和负向语料库c负,其中现有情感词典为扩展情感词典dextend。
步骤5、计算待分析词语nword的情感概率s。首先利用公式2、3计算待分析词语nword同正向语料库的相关性概率pa正,同负向语料库的相关性概率pa负;然后利用公式4、5计算待分析词语nword的情感倾向概率pb正和pb负;利用公式6、7分别计算待分析词nword的正向情感p正和负向情感的概率p负;最后利用公式8计算待分析词语nword的情感概率s。
p正=α*pa正+β*pb正公式6
p负=α*pa负+β*pb负公式7
s=p正-p负公式8
其中,α=0.5,β=0.5。
步骤6、筛选结果,更新情感词典。
设置正向阀值
当s>0并且
实施例2
采用与实施例1同样的流程构建情感词典,不同之处在于α=0.6,β=0.4,最终得到情感词典dupdate-2。
实施例3
步骤1、构建基础情感词典。整合现有的情感词典,本发明采用目前得到广泛认可的知网(hownet)情感词典和台湾大学简体中文情感极性词典(ntusd)。其中知网(hownet)情感词典包含的中文情感词典有:正面情感词语、正面评价词语、负面情感词语、负面评价词语、程度级别词语和主张词语。台湾大学简体中文情感极性词典包括:ntusd-negative和ntusd-positive两个情感词典。具体整合方法为将知网(hownet)里面的正面评价词语、正面情感词语和ntusd的positive词典合并去重得到正向情感词典,将知网(hownet)里面的负面评价词语、负面情感词语和ntusd的negative词典合并去重得到负向情感词典,由上述正向情感词典和负向情感词典构成基础情感词典dinitial。
步骤2、扩展基础情感词典。一是利用现有同义词词库对基础情感词典中情感词进行同义词扩展,现有同义词词库可以是《同义词词林》和/或《哈工大同义词词林拓展版》;二是人工添加具有情感色彩的网络新兴词汇;三是人工添加金融领域具有情感色彩的非情感词,如“三只乌鸦”、“直线拉升”等,得到扩展情感词典dextend。
步骤3、提取待分析词语nword。运用爬虫工具从股吧随机抓取2000篇2017年1月1日至2017年12月31日公布的金融文本语料,构成语料库c。运用中国科学院的ictclas汉语分词系统进行分词、去停用词、去噪等,得到分词语段库,去除扩展情感词典dextend中已经包含的词语、转折词、程度词以及非中文字符,采用词频法对所有词汇统计词频,并按词频由高到低排序,选取词频数大于5的词语,然后,利用公式1计算每个语段的前缀和后缀的信息熵,设定信息熵阈值i,保留前缀和后缀信息熵都大于该阈值的语段,作为待分析词语nword;
其中w为语块,a为其前(后)缀,c为频数,信息熵阈值i=1.1。
步骤4、建立正向语料库和负向语料库。基于现有情感词典,对步骤3收集的金融文本语料库c进行情感分析,创建正向语料库c正和负向语料库c负,其中现有情感词典为扩展情感词典dextend。
步骤5、计算待分析词语nword的情感概率s。首先利用公式2、3计算待分析词语nword同正向语料库的相关性概率pa正,同负向语料库的相关性概率pa负;然后利用公式9计算待分析词语nword的情感概率s。
s=pa正-pa负公式9
步骤6、筛选结果,更新情感词典。
设置正向阀值
当s>0并且
本发明采用准确率rp、召回率rr、f值对上文所述构建方法进行。其中准确率是衡量情感判断的正确率,召回率是对于整体语料库样本的,表示的是语料库样本中正确情感词被预测到的比例,具体计算方法如下:
评价结果如表1所示:
表1基于实施例1~3所述算法词语情感倾向判断
由此可见,本发明所述构建方法对新词判断的准确性得到了提高。
- 还没有人留言评论。精彩留言会获得点赞!