基于词向量和集成SVM的文本数据流分类方法与流程
本发明涉及文本数据流分类领域;具体的说是一种基于词向量和集成svm的文本数据流分类方法。
背景技术:
随着自媒体和社交网络的不断发展,从这些实时产生、数据量庞大、结构复杂的非结构化短文本数据中识别特征,进行数据分类,已经成为一个热门研究领域。由此可以帮助用户快速从中提取出有价值的信息和知识。然而,传统的knn、svm、nb、深度学习等方法对多分类算法存在要求大训练样本,准确率低等情况,而且以上的算法动态适应性不强。依旧存在以下问题:
社交媒体流中传播的大部分信息是无效信息;社交媒体流中的分类算法具有较高的计算成本;将文本数据转换为结构化格式的步骤在文本挖掘中起着关键作用,并对最终的实验效果产生很大的影响。而在社交媒体平台上发布的信息以非结构化文本信息为主,不能简单地用传统的定量数据算法来测量。
论文《objectdetectionusinghybridizationofstaticanddynamicfeaturespacesanditsexploitationbyensembleclassification》提出一种用于数据流分类的动态极限学习机,利用在线学习机制训练极限学习机为基本分类器,训练双层隐藏层结构以提高极限学习机的性能,并设置概念漂移警告,触发时加入更多的隐藏层节点,提高分类器的泛化能力。论文《基于半监督学习的数据流集成分类算法》,利用少量已标记数据和大量未标记数据,训练和更新集成分类器,并使用多数投票方式对测试数据进行分类。论文《onlineactivelearningensembleframeworkfordrifteddatastreams》提出一种新的在线主动学习集成框架,用于基于混合标记策略的漂移数据流,包括集成分类器以及非固定标记算法,动态调整分类器以及决策阈值,当发生概念漂移时,逐渐减小阈值以优先查询最不确定的实例以尽可能地降低请求费用。以上算法,都针对目前已有的动态学习、弱分类器分类精度较低等问题有一定的改进工作,但集成学习关于构造方案复杂,需要利用大量标记数据,以及时间复杂度高等缺点,仍未能得到很好的解决,需要进一步的改进完善。
技术实现要素:
本发明为了克服现有技术存在的不足之处,提出一种基于词向量和集成svm的文本数据流分类方法,以期能在降低计算复杂度的情况下,通过充分利用数据特征来提高分类结果的准确率,从而满足解决实际问题的需要。
本发明为解决技术问题采用如下技术方案:
本发明一种基于词向量和集成svm的文本数据流分类方法的特点是按如下步骤进行:
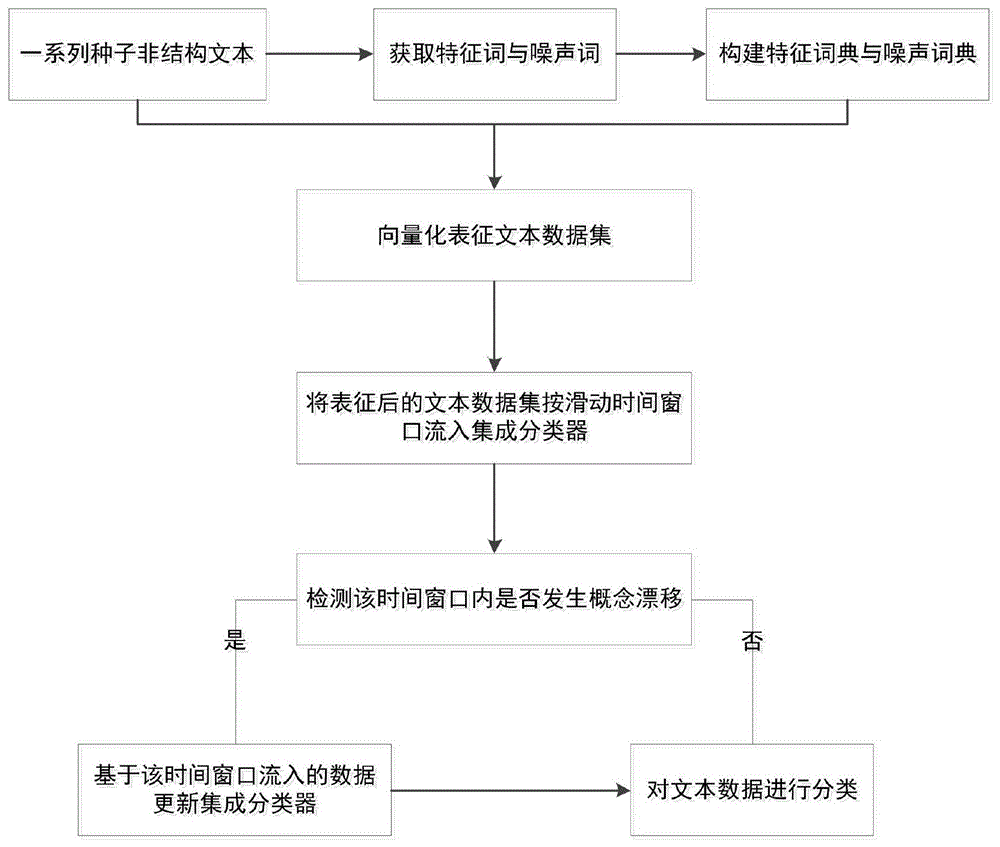
步骤1、获取文本数据集,并对所述文本数据集中部分文本进行标记,得到带标签的文本集合并作为种子文本集;
步骤2、对所述种子文本集进行词向量扩充处理,获得相应的特征词典及噪声词典;
步骤2.1、将所述种子文本集中的种子文本分割成单词;
步骤2.2、根据词频对分割后的单词进行排序,并将排序靠前的单词进行筛选,得到原始特征词以及噪声词;
步骤2.3、利用词向量算法分别对所述原始特征词和噪声词进行扩展,从而构造特征词典e和噪声词典n;
步骤3、对所述文本数据集进行特征加权向量化处理,获得相应的文本向量集;
步骤3.1、对所述文本数据集中的文本进行分词,得到每篇文本的分词结果;
步骤3.2、根据噪声词典n,从所述分词结果中剔除噪声词,得到每篇文本的去噪后的分词结果;
步骤3.3、利用词向量算法对所述去噪后的分词结果进行词向量化处理,得到每篇文本的单词词向量化表示;
步骤3.4、根据特征词典e,对每篇文本的特征词赋予权重,并利用式(1)得到文本p的向量化表示vector(p),从而由每篇文本的向量化表示构成文本向量集:
式(1)中,vecw表示文本p中属于特征词典e的特征词w的词向量化结果;weightw表示特征词w的权重;vecw′表示文本p中不属于特征词典e的特征词w’的词向量化结果;|vec(p)|表示文本p的去噪后的分词结果中的单词总个数;
步骤4、获得所有文本的分类结果:
步骤4.1、定义时间窗口为t、最大时间窗口为tmax;并初始化t=0;
定义集成分类器为ec,并初始化ec为空集,定义集成分类器ec的容量为k;
定义当前基分类器的个数为num,并初始化num=0;
定义集成分类器ec的权重为1×k维的向量weight_ec,并初始化weight_ec为零向量;
步骤4.2、从时间窗口t的文本数据流bt中获取n篇带标签的文本向量,记为
步骤4.3、若num<k,则用时间窗口t的文本数据流bt构造第num+1个基分类器的训练集tnum+1,并利用训练集tnum+1对支持向量机svm进行训练得到基分类器
式(2)中,
步骤4.4、将所述正确率
步骤4.5、用时间窗口t-1的集成分类器
对所述k个基分类器分类结果进行加权投票,得到时间窗口t-1的集成分类器
步骤4.6、根据时间窗口t-1的集成分类器
步骤4.7、将时间窗口t-1的集成分类器
将时间窗口t-1的集成分类器
步骤4.8、利用正确率
步骤4.9、利用式(3)进行假设性检验,若式(3)成立,则表明在文本数据流bt中发生概念漂移,并执行步骤4.10;反之,则说明在文本数据流bt中未发生概念漂移,跳转执行步骤4.16;
式(3)中,μ0是一个常量;α为给定的假设显著性水平;
步骤4.10、使用错误分类缓冲区errinst构造第k+1个基分类器
步骤4.11、计算集成分类器ecbt中k个基分类器对错误分类缓冲区errinst进行分类,得到的分类结果代入式(2),得到k个基分类器在错误分类缓冲区errinst中的正确率
步骤4.12、计算集成分类器
步骤4.13、若
步骤4.14、利用错误分类缓冲区errinst与训练集tj组成第k+2个分类器的训练集tk+2对支持向量机svm进行训练,得到第k+2个基分类器
利用所述第k+2个基分类器
步骤4.15、利用第k+2个分类器
步骤4.16、将t+1赋值给t;并判断t>tmax是否成立,若成立,则表示获得集成分类器对所有时间窗口的文本数据的分类结果;否则执行步骤4.2。
与已有技术相比,本发明的有益效果体现在:
1、本发明采用滑动时间窗口思想:利用滑动时间窗口进行集成分类的优势在于每个滑动时间窗口内的数据只用来训练一个基分类器,这样极大程度上解决了集成学习需要利用大量标记数据,以及时间复杂度高等问题。且对每个时间窗口内数据进行概念漂移检测,在保证时间效率的同时,有效利用训练数据,训练集成分类器,提高了分类准确率。同时,根据可用的缓冲区大小或者实验需求等,还可以变换滑动时间窗口大小,使分类方法具有较好的伸缩性和可扩展性。
2、本发明针对非结构化短文本的特点,采用词向量技术,在表示过程中,利用特征词典与噪声词典,提高了文本向量化表示的准确性。
3、本发明采用滑动时间窗口思想,对每个滑动时间窗口内的文本数据流,只用来训练一个基分类器;由此,解决目前集成分类器中所遇到的需要利用大量标记数据,导致较高的时间复杂度;以及可根据实验具体需求,变化滑动时间窗口大小,使该方法具有较好伸缩性以及可扩展性;
4、本发明在每个时间窗口内进行概念漂移的检测,以解决目前集成分类器在适应数据概念变动特征,所带来的时间复杂度高等问题;从而,在保证时间效率的同时,有效利用训练数据来训练集成分类器,进一步提高了分类准确率;
5、本发明以均衡考虑当前数据块和错误分类实例中的基分类器分类效果,在被替换基分类器的选择中,能够选择分类效果最差的基分类器;替换分类器则将由错误分类的实例与被替换分类器的训练集共同训练得到;从而降低了该方法的整体构造复杂度。
附图说明
图1为本发明基于词向量和集成svm的文本数据流分类方法流程图。
具体实施方式
本实施例中,如图1所示,一种基于词向量和集成svm的文本数据流分类方法是按如下步骤进行:
1、一种基于词向量和集成svm的文本数据流分类方法,其特征是按如下步骤进行:
步骤1、获取文本数据集,并对所述文本数据集中部分文本进行标记,得到带标签的文本集合并作为种子文本集;种子文本由随机选取10%左右总文本数据集得到。
步骤2、对所述种子文本集进行词向量扩充处理,获得相应的特征词典及噪声词典;词向量算法由维基百科语料训练谷歌公司所提出的深度学习词向量算法而得到。
步骤2.1、将所述种子文本集中的种子文本分割成单词;
步骤2.2、根据词频对分割后的单词进行排序,并将排序靠前的单词进行筛选,得到原始特征词以及噪声词;
步骤2.3、利用词向量算法分别对所述原始特征词和噪声词进行扩展,从而构造特征词典e和噪声词典n;利用词向量算法对每个原始特征词和噪声词取相似词,选取排序前十的相似词进行非重复扩展。
步骤3、对所述文本数据集进行特征加权向量化处理,获得相应的文本向量集;
步骤3.1、对所述文本数据集中的文本进行分词,得到每篇文本的分词结果;
步骤3.2、根据噪声词典n,从所述分词结果中剔除噪声词,得到每篇文本的去噪后的分词结果;
步骤3.3、利用词向量算法对所述去噪后的分词结果进行词向量化处理,得到每篇文本的单词词向量化表示;
步骤3.4、根据特征词典e,对每篇文本的特征词赋予权重,并利用式(1)得到文本p的向量化表示vector(p),从而由每篇文本的向量化表示构成文本向量集:
式(1)中,vecw表示文本p中属于特征词典e的特征词w的词向量化结果;weightw表示特征词w的权重;vecw′表示文本p中不属于特征词典e的特征词w’的词向量化结果;|vec(p)|表示文本p的去噪后的分词结果中的单词总个数;weightw是根据特征词w的词频所设置的定量。如:特征词w的词频为5,则可设置weightw为1.5。
步骤4、获得所有文本的分类结果:
步骤4.1、定义时间窗口为t、最大时间窗口为tmax;并初始化t=0;
定义集成分类器为ec,并初始化ec为空集,定义集成分类器ec的容量为k;k取参数定值9。
定义当前基分类器的个数为num,并初始化num=0;
定义集成分类器ec的权重为1×k维的向量weight_ec,并初始化weight_ec为零向量;
步骤4.2、从时间窗口t的文本数据流bt中获取n篇带标签的文本向量,记为
步骤4.3、若num<k,则用时间窗口t的文本数据流bt构造第num+1个基分类器的训练集tnum+1,并利用训练集tnum+1对支持向量机svm进行训练得到基分类器
式(2)中,
步骤4.4、将所述正确率
步骤4.5、用时间窗口t-1的集成分类器
对所述k个基分类器分类结果进行加权投票,得到时间窗口t-1的集成分类器
步骤4.6、根据时间窗口t-1的集成分类器
步骤4.7、将时间窗口t-1的集成分类器
将时间窗口t-1的集成分类器
步骤4.8、利用正确率
步骤4.9、利用式(3)进行假设性检验,若式(3)成立,则表明在文本数据流bt中发生概念漂移,并执行步骤4.10;反之,则说明在文本数据流bt中未发生概念漂移,跳转执行步骤4.16;
式(3)中,μ0是一个常量;α为给定的假设显著性水平;μ0初始化为前五个数据块分类错误率的平均值。α为给定假设显著性水平95%。
步骤4.10、使用错误分类缓冲区errinst构造第k+1个基分类器
步骤4.11、计算集成分类器ecbt中k个基分类器对错误分类缓冲区errinst进行分类,得到的分类结果代入式(2),得到k个基分类器在错误分类缓冲区errinst中的正确率
步骤4.12、计算集成分类器
步骤4.13、若
步骤4.14、利用错误分类缓冲区errinst与训练集tj组成第k+2个分类器的训练集tk+2对支持向量机svm进行训练,得到第k+2个基分类器
利用所述第k+2个基分类器
步骤4.15、利用第k+2个分类器
步骤4.16、将t+1赋值给t;并判断t>tmax是否成立,若成立,则表示获得集成分类器对所有时间窗口的文本数据的分类结果;否则执行步骤4.2。
- 还没有人留言评论。精彩留言会获得点赞!