一种题目文本句子向量生成方法及装置与流程
本发明属于文本处理技术领域,特别涉及一种题目文本句子向量生成方法及装置。
背景技术:
将文本转换成向量的方法是目前自然语言处理技术领域中常采用的一种方法,主要的模型有cbow和skip-gram、one_hot、tf/idf等。文本向量化的处理也主要是为了便于文本的分类、聚类和相似度计算,以达到有效处理数据信息的目的。此方法广泛应用在新闻推荐、文档分类、情感分析、自动摘要、信息检索、机器翻译等业务领域,但在基础学科等专业领域,如数学学科,由于数学文本中有大量的公式,且公式大部分都是通过数学专有字符呈现,字符与字符之间的关系紧密,不仅字符占比高,并且共现频率高。因此,通过传统训练方法操作这些数学字符,容易放大句子中的公式对语义的影响,而忽略一些重要信息,导致利用训练结果进行自动化标注知识点、推荐题目时很难达到很好的效果。
技术实现要素:
本发明提供了一种题目文本句子向量生成方法,用于解决基础学科,例如数学中题目文本的句子向量的生成。
本发明实施例之一,一种题目文本句子向量生成方法,包括以下步骤:
s1.根据题目文本表达筛选出所有关键词,加入词典,再对题目文本中的句子进行词典分词,同时对句子中出现的关键词进行标记;
s2.基于分词结果和筛选出的所有关键词,通过分别对每条句子和其内包含的关键词编码后,再建立rnn模型采用随机剔除关键词的方法进行预测训练;
s3.利用训练好的模型提取到的特征,对题目文本中的每条句子生成句子向量。
本发明首先针对某一基础学科专业领域如数学,搜集大量的文本数据进行关键词的筛选,然后通过句子分词训练、句子编码、关键词编码等一系列操作后,利用rnn模型采用随机剔除关键词的方法进行预测训练,最后利用rnn模型提取的特征生成句子向量。本发明根据基础学科的语言特点,摒弃传统词向量、句向量生成方法,利用关键词预测技巧和深度学习算法,可以有效地提取题目文本表达中的重要特征。而且利用生成的句子向量对题目文本的句子进行相似度的计算,有效地改善了基础学科知识点的提取效果,并提高了题目推荐的准确度,对自然语言处理技术在基础学科专业领域上的应用也起到了良好的促进作用。
本发明针对基础学科专业领域的语言特点,专门设计了一种句子向量生成方法用于有效提取文本中的关键信息。首先根据基础学科题目文本中用到的词语的重要性筛选出所有关键词加入词典,然后对大量题目文本中的句子进行词典分词。基于分词结果和筛选出的所有关键词,通过对句子和关键词编码后再采用随机剔除关键词的方法进行rnn模型的预测训练,最后利用训练好后rnn模型提取的特征生成句子向量。本发明利用关键词预测技巧和深度学习算法,相比传统方法产生的向量,可以生成更具区分度的句子向量,即可以有效地提取基础学科文本表达中的重要特征。而且利用生成的句子向量对题目文本的句子进行相似度的计算,有效地改善了基础学科知识点的提取效果,并提高了题目推荐的准确度,对自然语言处理技术在基础学科专业领域上的应用也起到了良好的促进作用。
附图说明
通过参考附图阅读下文的详细描述,本发明示例性实施方式的上述以及其他目的、特征和优点将变得易于理解。在附图中,以示例性而非限制性的方式示出了本发明的若干实施方式,其中:
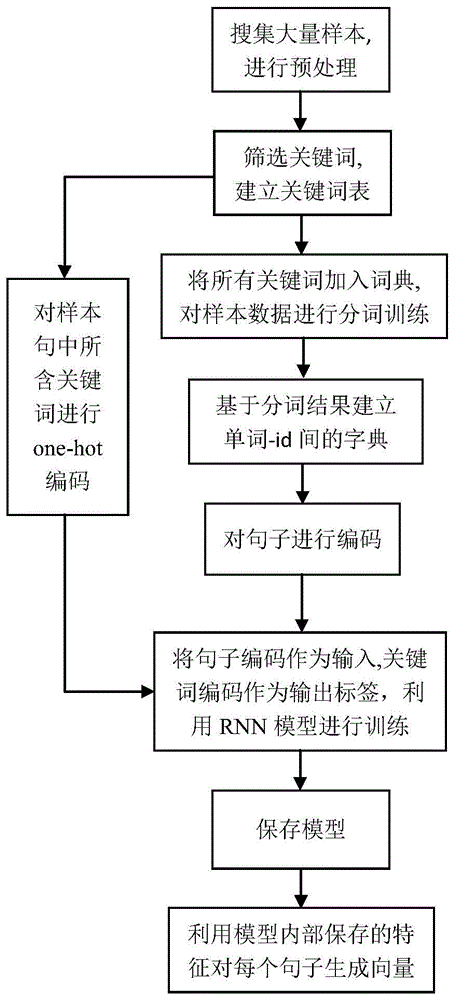
图1是本发明实施例中一种面向基础学科专业领域的句子向量生成方法的流程图。
具体实施方式
根据一个或者多个实施例,如图1所示,一种面向基础学科专业领域的句子向量生成方法,包括如下步骤:
s1,根据基础学科的文本表达筛选出所有关键词,加入词典,再对题目文本中的句子进行词典分词,同时对句子中出现的关键词进行标记;
s2,基于分词结果和筛选出的所有关键词,通过分别对每条句子和其内包含的关键词编码后,再建立rnn模型采用随机剔除关键词的方法进行预测训练;
s3,利用训练好的模型提取到的特征,对题目文本中的每条句子生成句子向量。
句子向量一般是词向量的平均,通过词向量相加求和再求平均可得到句子向量。词向量(wordembedding)是word嵌入式自然语言处理(nlp)中的一组语言建模和特征学习技术的统称。一般而言,也是指来自词汇表的单词或短语被映射到实数的向量,从概念上讲,它涉及从每个单词一维的空间到具有更低维度的连续向量空间的数学嵌入。对于相似的词,其对应的词向量也相近。
所述步骤s1具体包括以下步骤:
s11.首先根据基础学科题目文本中用到的词语的重要性由人工筛选关键词,组成关键词表。也可以通过tf-idf模型对大量的题目文本先初步筛选出关键词后,再由人工进一步确定出最终关键词表。关键词主要是专业领域的一些常见的概念词汇或本身有特殊含义的词语。
s12.把筛选出的所有关键词加入词典。词典是指分词用的通用词典,关键词如果已在词典里则不加入,如果不在则需要加入。将关键词加入词典可以在分词操作的时候将其被正确分出。
s13.搜集并整理大量某基础学科(如数学学科)的题目文本,先进行预处理,包括文本标准化、规范化、去停用词等,再对其中每个句子进行词典分词,并判断句子中的每个词语是不是关键词,做好标记。
所述步骤s2具体包括以下步骤:
s21.根据分词结果建立单词--id间的字典。这里的单词包含了基础学科专业领域内基本上用到的所有字词。
s22.把题目文本的每个句子中出现的每个单词按照整理好的字典进行替换,得到数字填充的编码序列。
s23.基于关键词表,对题目文本中的每个句子所包含的关键词进行one-hot编码。
s24.使用rnn神经网络模型,将步骤s22中得到的数字填充的编码序列作为输入,步骤s23中得到的one-hot矩阵作为标签进行关键词预测的训练。每轮迭代前,随机剔除句子中已标记的关键词用<blank>替代,重复本步骤,迭代训练多轮后得到模型提取到的所有特征参数,并保存模型。
rnn是一种神经网络模型,在普通神经网络基础上,增加了许多可以处理前后特征的记忆细胞,在自然语言处理上有很好的记忆性,并且rnn可以处理不定长序列,并转化为固定维度的向量组。
one-hot编码,也叫独热编码,是自然语言处理中的一种有效编码,主要是采用n位01编码对n个词语进行编码,每个词语所在的固定位置保存为一种状态,共有n^n种状态。
所述步骤s3具体包括以下步骤:
s31,将题目文本中的每个句子进过步骤s22处理后,输入到训练好的模型中进行向量运算。
s32,对rnn模型内部进行一些处理,拿到向量运算的结果作为rnn模型的输出,此输出即为句子向量。
下面以实例对本发明的一种面向基础学科专业领域的句子向量生成方法进行详细的说明:
这里以数学学科为例,选择一道数学题目进行输入,题目信息为:画出函数y=3*x的图象,并说出函数的定义域、值域。
首先根据大量的题目文本总结所有的关键词,得到关键词表。
然后对输入题目利用加入了所有关键词的词典进行分词,得到的结果为:画出/函数/y/=/3/*/x/的/图象/,/并/说出/函数/的/定义域/、/值域/。
根据事先基于大量的题目文本的分词结果建立的单词-id字典,将本题目中的单词使用id进行替换,得到数字填充的编码序列,结果示例为:1,2,3,4,5,6,7,8,9,10,11,12,3,8,13,14。
根据总结的关键词表,得到本题目含有的关键词有:定义域,值域,函数,图象。若关键词表为定义域,值域,函数,图象,周期,单调,则对本题目进行one-hot编码生成的关键词标签矩阵为[1,1,1,1,0,0]。
对本题目文本随机剔除一部分关键词用<blank>替换,<blank>默认id为0,得到新的编码序列为:1,0,3,4,5,6,7,8,9,10,11,12,3,8,0,14。
本案例只列举了一道题目,模型训练时要将大量题目的编码序列作为输入,关键词标签矩阵作为标签,采用rnn中的lstm_classfily模型进行多轮迭代训练,迭代训练时则采用新的编码序列作为输入,最后保存模型训练得到的所有特征参数。
将题目文本中的每个句子经过编码处理后,输入到训练好的模型中进行向量运算,并对lstm_classfily模型内部进行一些处理,拿到向量运算的结果即为句子向量。
值得说明的是,虽然前述内容已经参考若干具体实施方式描述了本发明创造的精神和原理,但是应该理解,本发明并不限于所公开的具体实施方式,对各方面的划分也不意味着这些方面中的特征不能组合,这种划分仅是为了表述的方便。本发明旨在涵盖所附权利要求的精神和范围内所包括的各种修改和等同布置。
- 还没有人留言评论。精彩留言会获得点赞!