一种基于无人机遥感的玉米田间杂草识别方法与流程
一种基于无人机遥感的玉米田间杂草识别方法,属于图像处理
技术领域:
。
背景技术:
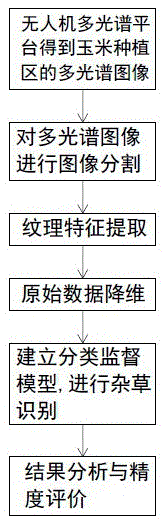
:在农业生产过程中,田间杂草被视为严重影响作物生长的因素之一,我国因杂草导致的粮食作物产量损失达总产量的10%。杂草由于其生长周期短、生长速度快、易于传播等特点,容易集中大规模爆发,在田间与作物幼苗争夺土壤养分、水分、光照等植物生长所需的资源,导致作物幼苗生长发育缓慢、产量降低等危害,因此必须对田间杂草生长及时加以控制。化学除草法由于其高效性,已成为国内外的主要除草手段,但地毯式地使用化学除草剂不仅对农田及周围生态环境造成一定的破坏,其残留在作物叶片上的药剂也对食品安全造成危害。因此,研究精准、快速的作物杂草识别方法,对于农药精准变量喷施技术的发展具有重要意义。近年来,利用图像识别进行杂草识别是一个重要的研究方向,当前杂草识别研究中,根据图像信息获取手段及图像特征提取方式不同,可分为基于光谱特征、机器视觉以及光谱成像的杂草识别方法,目前广泛采用的是基于机器视觉的识别方法,针对获取的作物及杂草图像,利用计算机分析图像中作物与杂草所表现出的形状、纹理、颜色等特征,提取差异较大的特征参数对目标进行识别检测。但是现有技术中的杂草识别方法普遍存在识别率低的问题,影响了杂草识别技术的发展,同时传统的地面图像采集难以实现试验区域的均布采样,因此容易受到样本密集区域的影响,增加样本的方法多为旋转原有图像或再次田间图像采集,费时费力。技术实现要素:本发明要解决的技术问题是:克服现有技术的不足,提供一种实现了试验区域的均布采样,同时具有较高识别率的基于无人机遥感的玉米田间杂草识别方法。本发明解决其技术问题所采用的技术方案是:该基于无人机遥感的玉米田间杂草识别方法,其特征在于:包括如下步骤:步骤1,在玉米种植区域,通过无人机获取玉米种植区域的图像数据,对图像数据进行预处理,得到玉米种植区域的多光谱图像;步骤2,使用主成分分析法对玉米种植区域的多光谱图像进行图像分割;步骤3,利用灰度共生矩阵法作为纹理分析方法对主成分分析处理后转换波段组合的伪彩色图像进行纹理特征提取,得到纹理特征参数;步骤4,对步骤3中得到的纹理特征参数进行降维处理,得到降维后的纹理特征参数;步骤5,建立分类监督模型,并对分类监督模型进行训练,通过分类监督模型对玉米种植区域内的杂草进行识别。优选的,步骤1中所述预处理的过程为:首先对单幅图像进行辐射校正、几何校正,然后根据飞行pos数据寻找同名点,通过空三测量计算原始影像生成点云模型,最后添加纹理并将单通道图像组合为多光谱图像,得到玉米种植区域的多光谱图像。优选的,步骤3中所述的纹理特征参数包括:选择均值、方差、协同性、对比度、相异性、信息熵、二阶矩、相关性。优选的,在步骤1中,通过无人机得到玉米种植区域中蓝光、绿光、红光、红外、近红外五个通道的图像数据。优选的,步骤4中所述降维后的纹理特征参数包括:红色方差、蓝色方差、红边方差、蓝色对比度、近红外方差、近红外对比度、红边对比度、蓝色相异性。优选的,在步骤3中进采用relief算法或主成分分析法行降维处理。优选的,在步骤5中建立的分类监督模型为随机森林模型或c4.5模型。优选的,所述的分类监督模型为随机森林模型,且将基决策树数量5的识别精度作为随机森林模型的识别精度。优选的,在执行步骤5之后,对步骤5中建立的分类监督模型进行结果分析与精度评价,并采用查准率p、查全率r以及f1值作为精度评价指标,查准率p、查全率r以及f1值的计算公式分别为:其中,tp表示真正例,fn表示假反例,fp表示假正例,tn表示真反例。与现有技术相比,本发明所具有的有益效果是:1、通过本基于无人机遥感的玉米田间杂草识别方法,实现了试验区域的均布采样,同时具有较高的识别率。2、利用无人机遥感获取的低空多光谱图像,其蓝、绿、红波段合成的rgb图像可以通过主成分分析有效地增强植被与裸土、阴影的色彩差异,实现植被与背景的分割。3、c4.5决策树模型及随机森林模型能够有效地对玉米、杂草进行识别,识别精度分别可达99.0%,96.501%,相比较传统的杂草识别方法,识别率大大提高。4、主成分分析算法及relief算法均能有效地对原始数据降维,pca算法侧重于单一数据识别准确性,relief算法侧重于整个数据集的识别精度。c4.5模型及rf模型处理relief算法选择的特征数据用时少于处理pca算法主成分的用时,运算时间分别缩短51.76%,3.57%,具有较高的效率。附图说明图1为基于无人机遥感的玉米田间杂草识别方法流程图。具体实施方式图1是本发明的最佳实施例,下面结合附图1对本发明做进一步说明。实施例1:如图1所示,一种基于无人机遥感的玉米田间杂草识别方法(以下简称杂草识别方法),包括如下步骤:步骤1,得到玉米种植区域的多光谱图像;在玉米种植区域,通过无人机得到携带的rededge-m多光谱相机获取图像数据,该传感器包含蓝光、绿光、红光、红外、近红外五个通道,无人机在飞行高度为30m,飞行速度3m/s的飞行状态下,采用垂直方式采集图像,获得五个单通道图像共计2630幅。将在玉米种植区得到的图像通过agisoftphotoscan软件进行较正、拼接等预处理操作,首先对单幅图像进行辐射校正、几何校正,然后根据飞行pos数据寻找同名点,通过空三测量计算原始影像生成点云模型,最后添加纹理并将单通道图像组合为多光谱图像,得到玉米种植区域的多光谱图像。步骤2,对玉米种植区域的多光谱图像进行图像分割;使用主成分分析法(principalcomponentanalysis,pca)对玉米种植区域的多光谱图像进行图像分割。在使用主成分分析法时,将当前正交坐标系中的数据通过矩阵变换操作映射到一个新的坐标系,其第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴选择与第一坐标轴正交且具有最大方差的方向,坐标轴选择重复直到新坐标轴数与原始数据中特征数目相等。使用主成分分析法可以有效地去除多光谱图像各波段间冗余信息,降低各波段间的相关性,将图像信息压缩为几个有效转换波段。变换后的新波段各主成分所包含的信息量呈递减趋势,第一主成分包含最大的方差信息,第二、三主成分的信息量依次减少,至最后几个主成分,信息量几乎为零。对玉米种植区的多光谱图像进行主成分分析变换,得到的第一、二、三主成分分别含有92.57%、5.99%、1.43%的信息量,将含信息量最多的前三个转换波段作为红、绿、蓝波段合成显示伪彩色图像,不同地物间的像素颜色显示有较大的差异,且裸土、阴影与植被像素辐射亮度值在绿光波段差异明显,通过设立阈值提取裸土、阴影像素区域,将其制作为掩膜文件,应用于多光谱图像,实现植被与背景的分割。步骤3,纹理特征提取;玉米及杂草在经步骤2的主成分分析法处理后转换波段组合的伪彩色图像中有明显的色彩差异,通过实地调查发现,部分杂草未能在伪彩色图像中与玉米叶片显示出色彩差异,且杂草像元与玉米像元辐射亮度值在各波段相似,仅依据辐射亮度值采用阈值法无法将玉米与杂草区分,因此选择提取多光谱图像中玉米、杂草叶片的纹理特征进行分类。在本步骤中,利用灰度共生矩阵法作为纹理分析方法对主成分分析处理后转换波段组合的伪彩色图像进行纹理特征提取。灰度共生矩阵法是图像灰度的二阶统计度量,反映了图像灰度在方向、邻域及变化幅度的综合信息。在实际应用中,多采用基于灰度共生矩阵计算出的统计量作为纹理识别的特征参数,在本杂草识别方法中,选择均值、方差、协同性、对比度、相异性、信息熵、二阶矩、相关性等8个纹理特征参数进行分析。使用envi软件co-occurrence-measures功能,对玉米种植区域的玉米、杂草叶片纹理特征进行提取,将灰度质量级设置为64,滤波窗口大小为5×5,空间相关性矩阵x、y的变化量为1,分别计算在蓝、绿、红、红边、近红外各波段下的上述8个纹理特征参数,共得到40种特征参数。步骤4,对纹理特征参数进行降维;由步骤3可知,若在蓝、绿、红、红边、近红外等五个波段下分别计算选择均值、方差、协同性、对比度、相异性、信息熵、二阶矩、相关性等8个纹理特征参数,一共可得到40种特征参数,若直接使用上述的40个特征参数作为监督分类模型的输入项,会因冗余信息导致模型效率下降,增加运算时间。在本杂草识别方法中,利用relief算法对样本数据进行降维处理。relief算法是一种过滤式特征选择方法,主要用于二分类问题的特征选择。该方法使用相关统计量度量特征重要性,相关统计量为向量,其分量分别对应一个初始特征,分量越大证明其对应的特征分类能力越强。样本数据经主成分分析得到的第一至第八主成分分别含有55.39%、17.28%、12.60%、3.83%、3.00%、1.58%、1.01%、0.93%的信息量,累积贡献率达95.62%,可以解释特征参数矩阵中大部分变量,因此有效地取代原有的40种特征参数。使用python实现relief特征选择,对40种特征参数按照相关统计量分量大小排序,然后取前12项特征:红色方差、蓝色方差、红边方差、蓝色对比度、近红外方差、近红外对比度、红边对比度、蓝色相异性、绿色方差、红色对比度、绿色相关性、绿色对比度,优选的,选择上述12项特征中的前8项特征,实现了对纹理特征参数的降维。步骤5,建立分类监督模型,进行杂草识别;在本实施例中,选取随机森林模型(randomforest,简称rf模型)作为监督分类模型,对随机森林模型进行分类模型训练,通过随机森林模型在玉米种植区域内进行杂草识别。在进行随机森林模型的建立时,假设给定样本集合d={xi,yi}(i=1,2,…m)包含m个样本,通过自主采样法有放回地随机选取t个与原样本合集d同样大小的采样集合dt=(t=1,2,…t),基于采样集合dt训练出t个基决策树,且每个基决策树结点的最优划分由该结点属性集合d中随机选出的包含k个属性的子集决定,统称k=log2d。将t个基决策树进行集成学习所得的组合分类器,即为随机森林,其输出的分类决策采用所述投票法:其中,h(x)表示随机森林模型,ht(x)为基决策树模型,y表示输出变量,i()表示示性函数。步骤6,结果分析与精度评价;在进行结果分析与精度评价时,基于随机森林模型分类结果进行精度评价,采用查准率(p)、查全率(r)、f1值3各支部作为精度凭借指标:以上公式中,tp表示真正例,fn表示假反例,fp表示假正例,tn表示真反例,使用宏平均值综合考察准确率与召回率:式中,n表示交叉验证次数,pi表示第i次验证准确率,ri表示第i次验证召回率。在本杂草识别方法中,将480处样本区域的玉米、杂草作为训练样本,120处样本区域作为测试样本。提取各图像5个波段的8种纹理特征,共计40种特征参数,最终得到480×40特征参数矩阵,然后以,relief算法筛选的前8项纹理特征数据记为a组数据,relief算法筛选的前12项纹理特征数据记为b组数据。利用python构建随机森林模型,取随机森林基决策树数量为1、5、10、15,并分别得到a、b两组数据的识别精度,如表1所示:数据a/基决策树数量1用时5用时10用时15用时随机森林97.667%1.9898.000%8.8598.500%18.0098.667%28.22数据b/基决策树数量1用时5用时10用时15用时随机森林97.500%2.9898.000%13.6298.833%27.7999.000%41.16表1测试样本识别率通过表1数据可知,rf模型识别精度随基决策树数量增加而有所提高,当基决策树数量由1提升至10时,识别精度增长明显,随着基决策树数量继续增加,识别精度增长逐渐变缓,10棵基决策树的rf模型与15棵基决策树的rf模型识别精度差距极小,且随基决策树数量增加模型运行时间增长。综合考虑精度及运算耗时,将基决策树数量5的识别精度作为rf模型的识别精度。对比a、b两组数据识别精度发现,随b组数据特征数量增加,rf模型在基决策树数量为1、5时识别精度未增长,基决策树数量为10、15时识别精度略有增长,表明b组添加的特征参数信息冗余,未能为两种模型提供足够的分类信息,relief算法选取的前八项特征能够有效替代原始数据中的40项特征。表2测试样本精度评价由表2数据可知,随机森林模型的查准率、查全率均在96%以上,基于查准率与查全率的调和平均值f1均在97%以上,因此随机森林模型对玉米、杂草样本测试集的分类识别效果良好。其中,rf模型的基决策树数量为10时,处理a组数据时有最高查全率达99.355%。实施例2:本实施例与实施例1的不同之处在于:在本实施例中,在进行步骤4的对纹理特征参数进行降维时采用主成分分析法完成,并在步骤6进行结果分析与精度评价时,将采用主成分分析法得到的前8个主成分数据记为c组数据,并结合实施例1中的表1及表2数据得到如下所示的表3及表4数据:数据a/基决策树数量1用时5用时10用时15用时随机森林97.667%1.9898.000%8.8598.500%18.0098.667%28.22数据b/基决策树数量1用时5用时10用时15用时随机森林97.500%2.9898.000%13.6298.833%27.7999.000%41.16数据c/基决策树数量1用时5用时10用时15用时随机森林97.500%2.0797.667%9.4298.400%18.8898.833%28.79表3测试样本识别率由表3数据可知,除了可以得到表1数据的结论之外,纵向对比a、c两组数据识别精度发现,rf模型在处理a组数据时基决策树数量为1、5的识别精度较c组分别提高了0.167%、0.333%,且总体用时较c组缩短了3.57%。表明实施例1中所采用的中relief算法对原始数据的降维处理效果优于主成分分析算法,但是通过主成分分析法对原始数据的降维处理时最后得到的杂草识别方法的效果相比较现有技术的杂草识别方法,仍具有较大优势。表4测试样本精度评价由表4数据可知,除了可以得到表2数据的结论之外,当rf模型的基决策树数量为15时,处理c组数据时有最高查准率,达99.298%,处理a组数据时有最高f1,达99.018%;rf模型的基决策树数量为10时,处理a组数据时有最高查全率,达99.355%,表明经主成分分析算法处理的数据有利于提高模型对玉米、杂草识别的准确性。实施例3:本实施例与实施例1的区别在于:在本实施例中,在进行步骤5时,采用c4.5决策树模型作为监督分类模型,在构建决策树的过程中,id决策树算法以信息增益作为属性划分的依据。假设当前样本合集d中第i类样本所占比例为pi(i=1,2,…m),则信息熵info(d)公式为:假设属性a有j(j=1,2,…n)个可能的取值{a1,a2,…aj},若使用属性a将集合d划分为j个不同的类,则第j类包含集合d中所有在属性a上取值为an的样本,记为dj。则信息增益gain(d,a)公式为:信息增益准则倾向于可取值较多的属性,为了减少其对于可取值较少的属性可能的分类影响,c4.5决策树算法在id3决策树算法的基础上加以改进,选择使用增益率而非直接使用信息增益进行属性划分,增益率公式为:其中:iv(a)称为属性a的固有值,当属性a的可取值j越大时,iv(a)的值也会增大。在本实施例中,采用c4.5决策树模型作为监督分类模型后,在步骤6进行结果分析与精度评价时,将采用主成分分析法得到的前8个主成分数据记为c组数据,并结合实施例1中的表1及表2数据以及实施例2中的表3及表4数据,得到如下所示的表5及表6数据:数据a/基决策树数量1用时5用时10用时15用时c4.5决策树95.837%4.10//////随机森林97.667%1.9898.000%8.8598.500%18.0098.667%28.22数据b/基决策树数量1用时5用时10用时15用时c4.5决策树95.669%8.74//////随机森林97.500%2.9898.000%13.6298.833%27.7999.000%41.16数据c/基决策树数量1用时5用时10用时15用时c4.5决策树96.501%8.50//////随机森林97.500%2.0797.677%9.4298.440%18.8898.833%28.79表5测试样本识别率由表5可知,除了可以得到表1及表3的相关结论外,还可以得到如下结论:rf模型的总体识别精度较c4.5模型高,识别精度最高可达99.000%,表明集成学习可以在基学习器基础上进一步提升识别精度。c4.5模型在处理3组数据时的识别精度虽低于rf模型,但均达到95%以上,最高达96.501%。c4.5模型运算用时相较rf模型大大减少,考虑到快速识别的要求,可以使用该c4.5决策树精度作为识别精度结果。纵向对比a、c两组数据识别精度发现,c4.5模型纵向对比a、c两组数据识别精度发现,c4.5模型在处理a组数据时识别精度较c组降低了0.764%,但运算时间较c组缩短了51.76%。综合考虑识别精度及运算用时,c4.5模型及rf模型在处理a组数据时的识别效果优于c组,表明在本试验中relief算法对原始数据的降维处理效果优于主成分分析算法。对比a、b两组数据识别精度发现,随b组数据特征数量增加,c4.5模型识别精度未增长,rf模型在基决策树数量为1、5时识别精度未增长,基决策树数量为10、15时识别精度略有增长,两种模型的运算用时分别较a组增加了113.17%、49.80%,表明b组添加的特征参数信息冗余,未能为两种模型提供足够的分类信息,relief算法选取的前八项特征能够有效替代原始数据中的40项特征。表6测试样本精度评价由表6数据可知,除了可以得到表2以及表4的结论之外,c4.5模型及rf模型的查准率、查全率均在94%以上,基于查准率与查全率的调和平均值f1均在95%,两种模型的对玉米、杂草样本测试集的分类识别效果良好。rf模型的查准率、查全率、f1总体高于c4.5模型。两种模型处理a组数据时的查准率均低于c组数据,查全率均高于c组数据,表明经主成分分析算法处理的数据有利于提高模型对玉米、杂草识别的准确性,经relief算法处理的数据则有利于提高模型对数据整体的识别精度。以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例。但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1