基于深度学习的遮挡行人检测方法与流程
本发明属于图像处理技术领域,特别涉及一种针对遮挡行人检测方法,可用于无人驾驶或辅助驾驶。
背景技术:
目前,模式识别技术和计算机视觉技术炙手可热,而行人检测作为图像处理的和机器视觉的一个研究领域,起到了举足轻重的作用。机器视觉的广泛应用,引领了新的科技潮流。因此,越来越多的学者投入到了这股浪潮之中。这场新兴技术革命正在全球席卷而来,全球的学者和商人都将战略的眼光投入到这块领域,力争能够取得制高点。
近年来,越来越多的大学、汽车生产厂家、互联网巨头、国家科研所都设立了专门的研究中心,力争能够将模式识别技术和机器视觉技术应用到工业、商业领域,创造出巨大的价值。而行人检测作为图像处理和机器视觉炙手可热的热点,更是受到了更加广泛的关注。近年来间,随着人工智能与互联网爆炸式增长,欧盟斥巨资资助成立了多个行人检测系统;本田汽车公司将行人检测应用到汽车辅助驾驶系统,以提高汽车的安全驾驶性能;苹果、谷歌、facebook等互联网巨头早已将行人检测应用到无人驾驶汽车,通过将行人检测应用到汽车智能辅助驾驶系统,来引领下一次科技革命。
行人检测成为一个非常具有挑战性的研究课题。现有的方法包括基于手工提取特征的方法和基于深度学习的方法。
基于手工提取特征的方法已有十多年的快速发展,很多学者做了大量的工作。2005年,dalal等人提出了梯度方向直方图表征图像的局部方差,并使用了线性的支持向量机进行特征的分类。2007年,dollar等人组合了局部通道特征和标准的boosting算法进行行人检测。2013年,r.benenson等人使用了局部通道特征(icf)进行行人检测,并对影响icf效果的多种因素做了详细的探讨。同年,prioletti等人使用基于haar特征的级联分类器产生可能存在的行人目标区域,并通过基于hog特征的滤波器进一步确认这些区域中是否存在行人目标。2014年,nam等人提出将行人目标的梯度特征和颜色特征进行局部去相关处理,增强boosted分类器的分类能力。2017年,j.baekthe等人提出了一种“附加核支持向量机(aksvm)”作为特征分类器,并采用遗传算法对aksvm进行优化。然而手工提取特征方法的准确率已经远远达不到现在人们对于高精度的需求。
随着训练数据的大规模增长和计算能力的大幅增强,深度学习方法在行人检测领域取得了成功。2015年,yang等人提取卷积通道特征ccf中的低层特征,使用增强森林模型作为特征分类器实现行人检测。同年,cai等人提出复杂感知级联训练compact,用于整合手工提取特征和cnn提取的特征,在精度和速度之间得到了一个良好的平衡。2016年,zhang等人使用rpn得到行人目标的卷积特征,然后使用增强森林分类器实现行人检测。2018年,you等人使用了简单的三个卷积层增强“聚集通道特征”,并使用adaboost分类器来判断输入图像是否包含行人。然而,上述深度学习方法没有考虑到卷积层对于不同输入图像表达效果不同的问题,也没有考虑到实际情况中遮挡行人样本数量较少的问题,导致上述方法对遮挡行人的检测效果较差。
技术实现要素:
本发明的目的在于针对上述已有技术的不足,提出一种基于深度学习的遮挡行人检测方法,以提高对遮挡行人的检测效果。
为实现上述目的,本发明提出了判别网络和掩码网络,其实现方案包括如下:
(1)读取行人检测数据库数据,使用vgg卷积神经网络提取数据的卷积特征,将vgg卷积神经网络不同层提取的特征进行叠加融合,得到融合特征,并将vgg网络最后一层特征作为非融合特征;
(2)构建掩码网络,将融合特征和非融合特征分别输入到该掩码网络中,得到两种对行人表达效果不佳的卷积特征;
(3)构建由掩码网络、rpn网络和softmax分类器组成的判别网络,将(2)得到的两种卷积特征分别输入到rpn网络中得到两种可能含有行人目标的候选区域,将该候选区域输入到softmax分类器中,得到两种概率得分,这两种概率得分的数值均在0到1之间;根据概率得分选择输出对于遮挡下的行人目标更为有效的卷积特征,当融合特征得到的概率得分高于非融合特征得到的概率得分时,输出融合特征,反之,则输出非融合特征;
(4)根据(3)中输出的特征,得到回归边界和分类概率:
4a)将(3)中输出的特征输入到rpn网络中,得到行人目标的候选区域,把候选区域映射到vgg卷积神经网络的卷积特征层中,得到每个候选区域在卷积特征层中对应的卷积特征;
4b)将4a)得到的卷积特征输入到两个全连接层中,得到数千个分类概率,其中每一个分类概率都有其对应的回归边界;
(5)根据4b)得到的回归边界和分类概率,通过损失函数l对vgg卷积神经网络、判别网络和rpn网络进行训练,得到最终的网络模型:
5a)利用损失函数l包括的分类概率损失子函数lcls和回归边界损失子函数lreg,计算分类概率损失子函数lcls和回归边界损失子函数lreg;
5b)根据分类概率损失子函数lcls和回归边界损失子函数lreg的值,计算得到损失函数l;
5c)通过逐步迭代减小损失函数l的值,完成对vgg卷积神经网络、判别网络和rpn网络的训练,得到最终的网络模型;
(6)将待检测的图像输入到最终的网络模型中,得到数千个待检测图像的分类概率,其中每个分类概率都有其对应的回归边界;保留大于设定阈值的分类概率,并将这些分类概率对应的回归边界映射到待检测的图像中,得到一个或多个矩形框,即为最终的检测结果。
本发明由于构建了判别网络和掩码网络,可以选择出对于遮挡下的行人目标更为有效的卷积特征,提高了对遮挡行人的检测效果。
附图说明
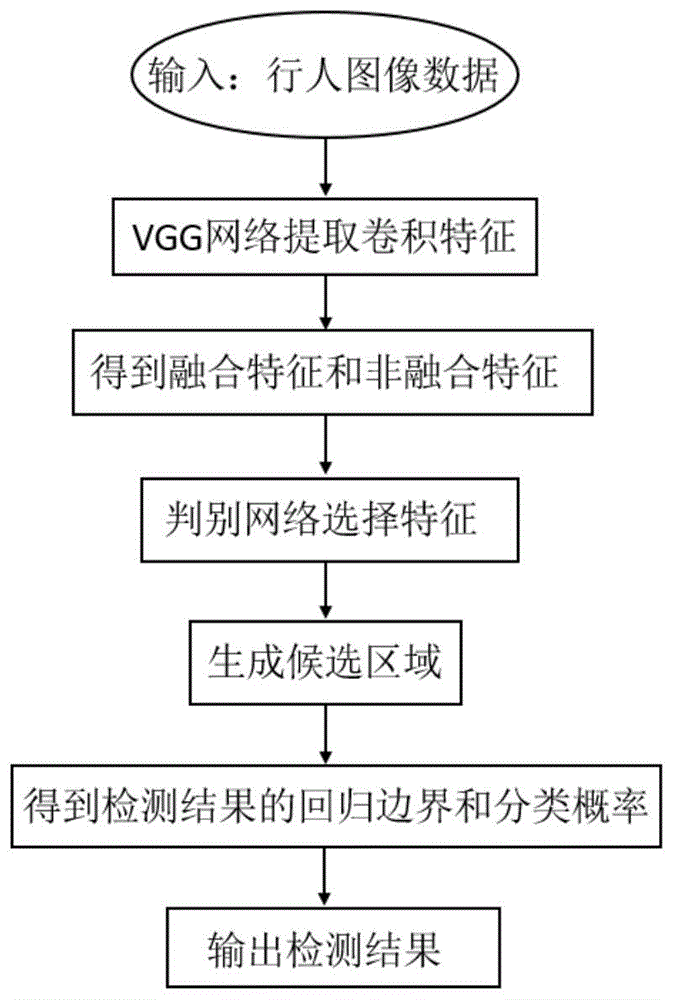
图1是本发明的实现流程图;
图2是本发明中的判别网络和掩码网络结构示意图;
图3是用本发明对caltech行人检测数据库中遮挡行人的实验结果图;
图4是用本发明对caltech行人检测数据库所有行人的实验结果图。
具体实施方式
以下结合附图对本发明的实施例和效果作进一步描述。
参照图1,本发明的具体实施步骤如下:
步骤1,得到融合特征和非融合特征。
1.1)读取行人检测数据库数据,使用vgg卷积神经网络提取数据的卷积特征:
1.1a)使用卷积核对输入数据进行卷积计算,得到神经网络中的第一个卷积特征图;
1.1b)使用卷积核对当前卷积特征图进行卷积计算,得到神经网络下一个卷积特征图;
1.1c)重复步骤1.1b),计算得到十六个卷积特征图,该第十六个卷积特征图中的数据为最终提取出来的卷积特征;
1.2)将vgg卷积神经网络不同层提取的卷积特征进行叠加融合,得到融合特征,并将vgg网络最后一层特征作为非融合特征。
步骤2,构建掩码网络,获得对行人表达效果不佳的卷积特征。
2.1)设掩码网络共有5层,其中:
第一层为卷积层,用于对尺寸为w×h×c的输入特征进行卷积操作,得到尺寸为w×h×c/16的特征图;
第二层为池化层,用于对第一层卷积得到的特征图进行步长为4的池化操作,得到宽为w/4、高为h/4的特征图;
第三层为上采样,用于对第二次池化得到的特征图进行上采样,得到宽为w、高为h的特征图;
第四层为融合层,用于把第三层上采样得到的特征图和输入特征图进行融合,得到尺寸为深度为17/16×c的特征图;
第五层为卷积层,用于对第四层融合得到的特征图进行卷积操作,得到尺寸为w×h×c的特征图;
2.2)将步骤1得到的融合特征和非融合特征分别输入到掩码网络中,得到两种对行人表达效果不佳的卷积特征。
步骤3,构建判别网络,选择输出特征。
3.1)将步骤2构建的掩码网络与现有的rpn网络和softmax分类器并联,构成判别网络,如图2所示,其中:
rpn网络,用于是把任意尺度的一个图片作为输入,输出一系列的矩形候选区域,每个候选区域都带有一个分类得分的网络;
softmax分类器,其输入是一个向量,输出是归一化的分类概率;,
3.2)将步骤2.2)得到的两种卷积特征分别输入到rpn网络中,得到两种可能含有行人目标的候选区域,将该候选区域输入到softmax分类器中,得到两种概率得分,这两种概率得分的数值均在0到1之间;
3.3)根据概率得分选择输出对于遮挡下的行人目标更为有效的卷积特征:当融合特征得到的概率得分高于非融合特征得到的概率得分时,输出融合特征,反之,则输出非融合特征。
步骤4,根据判别网络输出的特征得到分类概率和回归边界。
4.1)将判别网络输出的特征输入到rpn网络中,得到行人目标的候选区域,把候选区域映射到vgg卷积神经网络的卷积特征层中,得到每个候选区域在卷积特征层中对应的卷积特征;
4.2)在rpn网络后面连接全连接层,将4.1)中映射得到的卷积特征输入到全连接层中,将全连接层的每一个结点都与输入的卷积特征所有结点相连,再将之前提取到的特征综合起来,得到长度为3000-4000的二维数组,该二维数组中的每一个值代表每个候选区域属于行人和背景的概率,由数组的数千个值得到数千个分类概率,其中每一个分类概率都有其对应的回归边界。
步骤5,使用分类概率和回归边界计算损失函数,通过损失函数对vgg卷积神经网络、判别网络和rpn网络进行训练,得到最终的网络模型。
5.1)设损失函数l包括表示分类概率的损失子函数lcls和表示回归边界的损失子函数lreg;
5.2)通过下式计算分类概率的损失子函数lcls:
其中,i为候选区域的索引,pi为每个候选区域是否代表一个行人的分类概率,
5.3)通过下式计算回归边界的损失子函数lreg:
其中,i为候选区域的索引,ti为候选区域的回归边界,
5.4)根据上述两个子lcls和lreg的值,计算损失函数l:
其中,i为候选区域的索引,pi为每个候选区域是否代表一个行人的概率,
5.5)通过逐步迭代减小损失函数l的值,完成对vgg卷积神经网络、判别网络和rpn网络的训练,得到最终的网络模型。
步骤6,获得检测结果。
6.1)将待检测的图像输入到最终的网络模型中,得到数千个待检测图像的分类概率,其中每个分类概率都有其对应的回归边界;
6.2)设定一个阈值为0.5,保留大于该阈值的分类概率,并将保留的分类概率的对应回归边界映射到待检测的图像中,得到一个或多个矩形框,即为最终的检测结果。
下面结合仿真实验对本发明的效果做进一步的描述。
1.仿真条件:
硬件设施上,使用的是配有一个i7-5930k处理器和四块泰坦x显卡的高性能计算机。
实验使用caltech行人检测数据库进行评估,该caltech行人检测数据库是目前规模较大的行人数据库,采用车载摄像头拍摄,标注了约250000帧图像,共有350000个矩形框,包括2300个行人。
仿真实验使用本发明和现有的三种行人检测方法在caltech行人检测数据库上进行的对比实验,其中第一种现有方法方法是发表在iccv2015的卷积信道特征方法ccf,第二种现有方法是发表在eccv2016的区域生成网络级联增强森林方法rpn+bf,第三种现有方法是发表在tpami2017的特征联合学习方法udn+。
2.仿真内容:
仿真实验1:用本发明和现有的三种方法对数据库中遮挡程度为40%到80%的行人进行检测,得到mr-fppi曲线,如图3所示,其中纵坐标为丢失率mr,丢失率是正样本被错误判别为负样本的数目和全部正样本数目的比率;横坐标为每张图像中错误正样本数目fppi,其中错误正样本指检测结果为行人,实际上不是行人的一些样本。
由图3可见,本发明对遮挡程度为40%到80%的行人目标的检测结果要优于其它三种方法,验证了本发明对遮挡行人有良好的检测效果。
仿真实验2:用本发明和现有的三种方法对caltech行人检测数据库中所有的行人目标进行检测,得到mr-fppi曲线,如图4。
从图4可以看出,本发明对所有行人的检测结果要优于其它三种方法。仿真实验2验证了本发明对所有的行人同样有良好的检测效果。
上述仿真结果验证了本发明的正确性、有效性和可靠性。
- 还没有人留言评论。精彩留言会获得点赞!