一种基于稀疏表示的视频图像烟火分离与检测方法与流程
本发明属于视频图像处理领域,涉及一种基于稀疏表示的视频图像烟火分离与检测方法。
背景技术:
森林火灾破坏生态环境、伤害林内动物和人群、造成巨大的经济损失,因此森林火灾的探测一直是当下研究的热点。为了尽早发现火情,及时扑灭森林火灾,减小人员伤亡和经济损失常对火灾初起的烟火进行探测,传统的烟火检测利用各类传感器对烟雾颗粒进行检测,但此类系统或易发生漏检、或传感器维护成本高,且传感器的安装要求严苛,火灾现场数据不能直观传送至监控室,无法在特殊情况下人为介入判断火灾情况。基于机器视觉的火灾探测方法适用于任何室内外场景,并能实时提供烟火位置,范围浓度等重要信息,因此在森林烟火检测中得到广泛应用。
传统基于机器视觉的检测方法主要依赖于提取检测目标的特征。对于固体目标的检测,例如人脸检测,车牌识别等特征主要从源图像的运动区域或按块提取,这些特征一般会提供关于检测目标的可靠信息。然而,对于早期烟火(主要为烟)来说,因其具有半透明,多变的厚度和发散等特征,烟火常与背景信息混合,传统的特征提取方法无法提供针纯净烟火的可靠信息。
基于以上问题,本发明提出了一种基于稀疏表示的视频图像烟火分离与检测方法。该方法通过字典学习与稀疏表示,得到纯净烟火特征在完备字典上的表征,在此基础上,源图像被看作是非烟的背景成分与纯净烟火的前景成分的线性组合。
技术实现要素:
发明目的:本发明提供了一种基于稀疏表示的视频图像烟火分离与检测方法,该方法针对早期烟火进行检测。
技术方案:为实现上述发明目的,本发明采用以下技术方案:
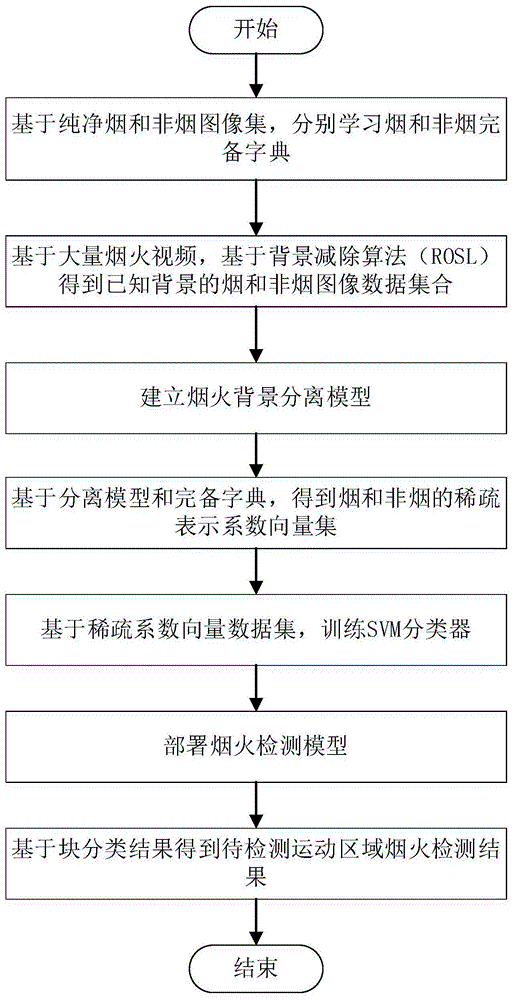
一种基于稀疏表示的视频图像烟火分离与检测方法,包括以下步骤:
(1)建立无背景纯净烟火和非烟图像数据集,采用k-svd算法学习烟雾过完备字典ds以及非烟过完备字典db;
(2)基于大量烟火视频,采用传统背景减除算法得到已知背景的烟和非烟图像数据集合;
(3)建立烟火背景分离模型;
(4)基于步骤(3)的烟火背景分离模型和步骤(1)学习到的过完备字典,得到烟和非烟的稀疏表示系数向量集以及混合系数;
(5)将步骤(4)得到的稀疏系数向量数据集分别作为正负特征样本,训练svm分类器;
(6)部署烟火检测模型;
(7)根据块分类结果得到待检测运动区域烟火检测结果。
进一步的,步骤(1)中纯净烟火图像数据集包括浓烟和无背景透明烟火,非烟图像来自公共数据集cifar-100;字典学习采用经典k-svd算法,k-svd算法公式为:
其中,l为常数阈值,d为过完备字典,α为稀疏系数向量,x为输入图像序列矩阵;
其中采用svd奇异值分解算法更新字典原子,omp正交匹配追踪算法更新稀疏系数;当输入为纯净烟火图像xs,经过交替更新迭代最后得到烟火过完备字典ds,同样地,当输入为非烟图像xb,得到的是非烟过完备字典db。
进一步的,步骤(2)中采用rosl鲁棒正交子空间学习算法,从视频图像中提取背景图像以及前景图像,计算公式为:
其中,视频每帧图像大小为m1×m2,共n帧,则输入的视频序列矩阵
进一步的,步骤(3)在烟火图像中,有烟区域图像块是纯烟与背景成分的线性组合,烟火背景分离模型为:
x=ωs-(1-ω)b,s.t.ω∈[0,1];
其中,x为样本数据原图像,b为背景图像样本,s为前景图像样本,ω为混合系数参数;为保证同一图像块中混合系数相同,该模型建立在小尺寸的图像块上,基于该模型,分别计算纯烟成分和混合系数。
进一步的,步骤(4)采用弹性网络elastic-net和有辨别力约束条件处理稀疏系数;其中弹性网络elastic-net算法公式为:
此外,为了将采用基于烟火字典的稀疏表示方法得到纯烟或非烟成分于基于非烟字典的稀疏表示进一步区分,得到有辨别力的稀疏系数,增加辨别力约束条件
具体为:
(41)求关于αs最优解,固定混合系数ω,令y*=[x-(1-ω)b;0],
(42)增加了辨别力约束条件,进一步对上式做如下改进:
令y**=[y*;0],
当输入为烟火图像数据xs时,得到前景烟火成分的稀疏表示
(43)求关于ω的最优解,固定稀疏系数向量αs,即求式
由ω∈[0,1],进一步得:
进一步的,步骤(5)具体为:
(51)将步骤(4)得到的烟火和非烟稀疏表示相应的稀疏系数向量数据集
(52)将正负特征样本分别归一化,即每一个向量的元素除以该向量中元素的最大值,得到的每一个元素值的取值范围都在0到1之间;
(53)将正负样本以及对应标签yi∈{+1,-1}作为输入样本集s={(αs,i,yi)|i=1,2,...,n}来训练svm分类器,i表示第i个样本;由于αs,i是多维向量线性不可分,因此采用高斯核函数将其映射到高维空间使其线性可分;最后训练得到识别烟火和非烟的分类模型。
进一步的,步骤(6)包括以下步骤:
(61)输入视频图像序列;
(62)采用rosl鲁棒正交子空间学习算法得到低秩视频背景以及稀疏前景运动区域
(63)遍历运动区域图像块,采用基于稀疏表示的烟火与背景分离模型得到图像块稀疏系数αs以及混合系数ω;
(64)混合系数ω<0.01的区域首先判定为非烟区域;ω≥0.01时,采用步骤(5)训练得到的svm分类器对稀疏系数向量αs进行分类识别;对于识别为烟的图像块,若ω∈[0.01,0.6),则标记为淡烟;若ω∈[0.6,1],则标记为浓烟。
进一步的,步骤(7)中运动区域的属性由多数图像块属性决定,若被识别为某一属性浓烟、淡烟或非烟的图像块数最多,则将运动区域标记为该属性。
有益效果:与现有技术相比,本发明具有如下优点:
1、本发明采用基于字典学习与稀疏表示的方法,将纯净烟火与背景分离,避免了背景信息对烟火特征的干扰,从而提高了烟火识别与检测的准确率。
2、本发明考虑了稀疏表示中稀疏系数的相关性,采用elastic-net代替一般基于lasso的稀疏表达,该方法更加适用于稀疏系数个数大于所表达图像大小的情况下归一化和变量选择。
3、本发明将基于烟字典的稀疏系数向量作为特征,采用非烟火字典作为辨别力约束条件,为进一步提高了特征的辨别能力。本发明在烟火分离和检测效果上都优于现有方法。
附图说明
图1为基于稀疏表示的视频图像烟火分离与检测方法流程图;
图2为烟火与背景分离效果对比图;
图3为烟火检测效果图。
具体实施方式
下面结合说明书附图和实例,清楚、完整地描述本发明方法的详细过程。
应理解下述实施例仅用于说明本发明技术方案的具体实施方式,而不用于限制本发明的范围。在阅读了本发明之后,本领域技术人员对本发明的各种等同形式的修改和替换均落于本申请权利要求所限定的保护范围。
如图1所示,一种基于稀疏表示的视频图像烟火分离与检测方法,包括以下步骤:
步骤1:建立无背景纯净烟火和非烟图像数据集,采用k-svd算法学习烟火过完备字典ds以及非烟过完备字典db;
纯净烟火图像数据集包括浓烟和无背景(背景为黑色,像素为0)透明烟火,非烟图像来自公共数据集cifar-100。字典学习采用经典k-svd算法,k-svd基本思想如下:
其中,l为常数阈值,d为过完备字典,α为稀疏系数向量,x为输入图像序列矩阵;其中采用svd(singularvaluedecomposition,奇异值分解)算法更新字典原子,omp(orthogonalmatchingpursuit,正交匹配追踪)算法更新稀疏系数。当输入为纯净烟火图像xs,经过交替更新迭代最后得到烟火过完备字典ds,同样地,当输入为非烟图像xb,得到的是非烟过完备字典db。
本实施例中纯净烟火和非烟图像数据集分别由4000张16*16大小的图像组成,根据图像大小,过完备字典大小为256*500,稀疏系数向量大小为500*1。
步骤2:基于大量烟火视频,采用rosl(robustorthonormalsubspacelearning,鲁棒正交子空间学习)算法,从视频图像中提取背景图像以及前景图像,计算公式为:
其中,视频每帧图像大小为m1×m2,共n帧,输入的视频序列矩阵
步骤3:建立烟火背景分离模型。
在烟火图像中,有烟区域图像块是纯烟与背景成分的线性组合,烟火背景分离模型为:
x=ωs-(1-ω)b,s.t.ω∈[0,1](3);
其中,样本数据原图像x,背景图像样本b以及前景图像样本s分别截取自步骤2中大图像样本x,b,e,ω为混合系数参数。为保证同一图像块中混合系数相同,该模型建立在小尺寸的图像块上(本实施例中为16*16图像块),基于该模型,分别计算纯烟成分和混合系数。
步骤4:基于步骤3的烟火背景分离模型和步骤1学习到的过完备字典,采用弹性网络elastic-net和有辨别力约束条件处理稀疏系数。弹性网络elastic-net可以较一般lasso(套索算法)更适用于稀疏系数个数大于所表达图像大小的情况,若系数存在对组相关性,则lasso条件只能选择一个值作为特征系数而忽略了组相关性,本发明所采用的elastic-net方法被证明可以解决以上问题:
此外,为了将采用基于烟火字典的稀疏表示方法得到纯烟或非烟成分于基于非烟字典的稀疏表示进一步区分,得到有辨别力的稀疏系数,本发明增加辨别力约束条件
步骤4具体为:
步骤401:求关于αs最优解,固定混合系数ω,令y*=[x-(1-ω)b;0],
步骤402:增加了辨别力约束条件,进一步对上式做如下改进:
令
当输入为烟火图像数据(记为xs)得到前景烟火成分的稀疏表示
步骤403:求关于ω的最优解,固定稀疏系数向量αs,即求式
由ω∈[0,1],进一步得:
步骤5:将步骤4得到的稀疏系数向量数据集
步骤5具体为:
步骤501:将步骤4得到的烟火和非烟稀疏表示相应的稀疏系数向量数据集
步骤502:将上述样本归一化,即每一个向量的元素除以该向量中元素的最大值,得到的每一个元素值的取值范围都在0到1之间。
步骤503:将正负样本以及对应标签yi∈{+1,-1}作为输入样本集s={(αs,i,yi)|i=1,2,...,n}来训练svm分类器,i表示第i个样本。由于αs,i是多维向量线性不可分,因此采用高斯核函数将其映射到高维空间使其线性可分。最后训练得到识别烟火和非烟的分类模型。
本实施例中:通过样本采集和筛选,得到2000个烟火图像和2000个非烟图像数据集分别作为训练正负样本,1000个烟火图像和1000个非烟图像数据集分别作为测试正负样本,截取的图像大小均为16*16。采用基于rbf核函数的svm作为分类器训练样本。本发明训练精度达到98.77%,测试精度达到92.25%。
步骤6:部署烟火检测模型,其具体步骤为:
步骤601:输入视频图像序列;
步骤602:采用rosl(鲁棒正交子空间学习)算法得到低秩视频背景以及稀疏前景运动区域
步骤603:遍历运动区域图像块,每个图像块采用基于稀疏表示的烟火与背景分离模型得到图像块稀疏系数αs以及混合系数ω;
步骤604:混合系数ω<0.01的区域首先判定为非烟区域;ω≥0.01时,采用步骤5训练得到的svm分类器对稀疏系数向量αs进行分类识别。对于识别为烟的图像块,若ω∈[0.01,0.6),则标记为淡烟,若ω∈[0.6,1]则标记为浓烟。
步骤7:运动区域的属性由多数图像块属性决定,当被识别为某一属性(浓烟,淡烟或非烟)的图像块数最多,则将运动区域标记为该属性。
运动区域大小和形状不定,各区域烟的浓度或透明度不确定,本发明实施例采用的块大小为16*16可识别区域中各图像块的烟火属性,分别标记为非烟,淡烟或浓烟,则该区域属性由多数图像块属性决定。
以上步骤2-5是基于视频帧图像中截取图像块来建立训练与测试数据集。步骤6按重叠块遍历视频每一帧图像的运动区域,得到每一个图像块的基于烟字典的前景成分以及前景与背景的混合系数,分类时是对每个图像块进行分类检测。
本发明基于稀疏表示的视频图像烟火分离与检测方法的应用实验中,对大量实际场景中的烟火视频进行了测试。图2是所测试视频中一帧图像的烟火分离效果,其中(a)为原图,(b)为利用传统背景减除算法得到的前景烟火图像,(c)为利用本发明所述烟火与背景分离算法得到的前景烟火图像。可以看出,采用简单的背景减除算法无法得到纯净烟火成分,图像中背景特征纹理会影响烟火特征的提取,采用本发明所述方法能够将烟火与背景完全分离。图3为采用本发明素数方法得到的烟火检测结果,其中(a)为原图,(b)为烟火检测效果图。图中亮色框标记了淡烟区域,暗色框标记了浓烟区域。该区域半数图像块被判定为浓烟,最终该运动区域被判定为浓烟区域。
- 还没有人留言评论。精彩留言会获得点赞!