神经网络运算方法及相关产品与流程
本披露涉及神经网络领域,尤其涉及一种神经网络运算方法及相关产品。
背景技术:
人工神经网络(artificialneuralnetwork,即ann),是20世纪80年代以来人工智能领域兴起的研亢热点。它从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络。在工程与学术界也常直接简称为神经网络或类神经网络。神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。现有的神经网络的运算基于cpu(centralprocessingunit,中央处理器)或gpu(英文:graphicsprocessingunit,图形处理器)来实现神经网络的推理(即正向运算),此种推理的计算量大,功耗高。
技术实现要素:
本披露实施例提供了一种运算数据的量化方法及相关产品,可降低推理、训练的计算量,提升计算芯片的处理速度,提高效率。
第一方面,提供一种运算数据的量化方法,所述方法包括如下步骤:
确定运算数据;获取量化命令,该量化命令包括连续量化精度;依据该运算数据确定该运算数据的量化精度f,依据该量化精度以及量化函数对该运算数据进行量化操作,得到量化后的数据,以使得所述人工智能处理器根据所述量化后的数据执行运算操作。
可选的,所述运算数据包括:输入神经元a、输出神经元b、权重w、输入神经元导数
可选的,所述依据该量化精度以及量化函数对该运算数据进行量化操作,得到量化后的数据具体包括:
依据连续量化精度f以及运算数据的元素值计算得到量化后的数据。
可选的,所述依据连续量化精度f以及运算数据的元素值计算得到量化后的数据具体包括:
连续定点量化函数为公式(1);
其中,y为量化后的连续定点数据,f为连续量化精度,σ为取整函数。
可选的,所述取整函数为:向上取整函数、向下取整函数、四舍五入函数或随机取整函数。
可选的,所述依据该运算数据确定该运算数据的量化精度具体包括:
根据该运算数据绝对值最大值确定f;
或根据该运算数据绝对值最小值确定f;
或根据不同数据类型间关系确定f;
或根据经验值常量确定f。
可选的,所述根据该运算数据绝对值最大值确定f具体包括:
如该所需的定点数据类型为连续定点数据,通过公式2-1来确定f
其中c为常数,bitnum为量化后的数据的比特位数,amax为运算数据绝对值最大值。可选的,所述根据该运算数据绝对值最小值确定f具体包括:
通过公式2-2确定精度f;
fa=amin*d公式2-2
其中d为常数,amin为运算数据绝对值最小值。
可选的,所述运算数据绝对值最大值或所述绝对值最小值的确定方式具体包括:
采用所有层分类寻找绝对值最大值或绝对值最小值;
或采用采用分层分类别寻找绝对值最大值或绝对值最小值;
或采用分层分类别分组进寻找绝对值最大值或绝对值最小值。
可选的,所述根据不同数据类型间关系确定f具体包括:
通过公式2-3来确定连续定点精度
fa(l)=∑b≠aαbfb(l)+βb公式2-3
可选的,所述根据经验值常量确定f具体包括:
设定
其中,
可选的,所述方法还包括:
根据待量化的数据动态调整f。
可选的,所述根据待量化的数据动态调整f具体包括:
根据待量化数据绝对值最大值向上调整f:;
或根据待量化数据绝对值最大值逐步向上调整f;
或根据待量化数据分布单步向上调整f;
或根据待量化数据分布逐步向上调整f;
或根据待量化数据绝对值最大值向下调整f。
可选的,所述方法还包括:
动态调整f的触发频率。
可选的,所述动态调整f的触发频率具体包括:
永远不触发调整;
或每隔δ个训练周期调整一次,δ固定不变;
或每隔δ个训练时期epoch调整一次,δ固定不变;
或每隔step个iteration或epoch调整step=αδ,其中α大于1;
或每隔δ个训练iteration或epoch调整一次,所述δ随着训练次数的增加,逐渐递减。
第二方面,提供一种计算芯片,所述计算芯片包括:
处理单元,用于确定神经网络的运算数据;从计算库中提取与连续定点数据类型对应的量化函数;依据该运算数据确定该运算数据的量化精度f;
量化单元,用于依据该量化精度以及量化函数对该运算数据量化得到量化后的连续定点数据;
所述处理单元,还用于将量化后的连续定点数据执行神经网络运算得到运算结果。
第三方面,提供一种神经网络运算装置,所述神经网络运算装置包括一个或多个第二方面提供的芯片。
第四方面,提供一种组合处理装置,所述组合处理装置包括:第三方面提供的神经网络运算装置、通用互联接口和通用处理装置;
所述神经网络运算装置通过所述通用互联接口与所述通用处理装置连接。
第五方面,提供一种电子设备,所述电子设备包括第二方面提供的芯片或第三方面提供的神经网络运算装置。
第六方面,提供一种计算机可读存储介质,其特征在于,存储用于电子数据交换的计算机程序,其中,所述计算机程序使得计算机执行第一方面提供的方法。
第七方面,提供一种计算机程序产品,其中,上述计算机程序产品包括存储了计算机程序的非瞬时性计算机可读存储介质,上述计算机程序可操作来使计算机执行第一方面提供的方法
附图说明
图1是一种神经网络的训练方法示意图。
图2是一种神经网络运算的方法的流程示意图。
图3是连续定点数据的表示示意图。
图4a是一种芯片示意图。
图4b是另一种芯片示意图。
图5a为本披露还揭露了一个组合处理装置结构示意图。
图5b为本披露还揭露了一个组合处理装置另一种结构示意图。
图5c为本披露实施例提供的一种神经网络处理器板卡的结构示意图。
图5d为本披露实施例流提供的一种神经网络芯片封装结构的结构示意图。
图5e为本披露实施例流提供的一种神经网络芯片的结构示意图。
图6为本披露实施例流提供的一种神经网络芯片封装结构的示意图。
图6a为本披露实施例流提供的另一种神经网络芯片封装结构的示意图。
具体实施方式
为了使本技术领域的人员更好地理解本披露方案,下面将结合本披露实施例中的附图,对本披露实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本披露一部分实施例,而不是全部的实施例。基于本披露中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本披露保护的范围。
本申请提供的运算数据的量化方法可以在处理器内运行,上述处理器可以为通用的处理器,例如中央处理器cpu,也可以是专用的处理器,例如图形处理器gpu,当然也可以在人工智能处理器内实现。本申请对处理器的具体表现形式并不限定。
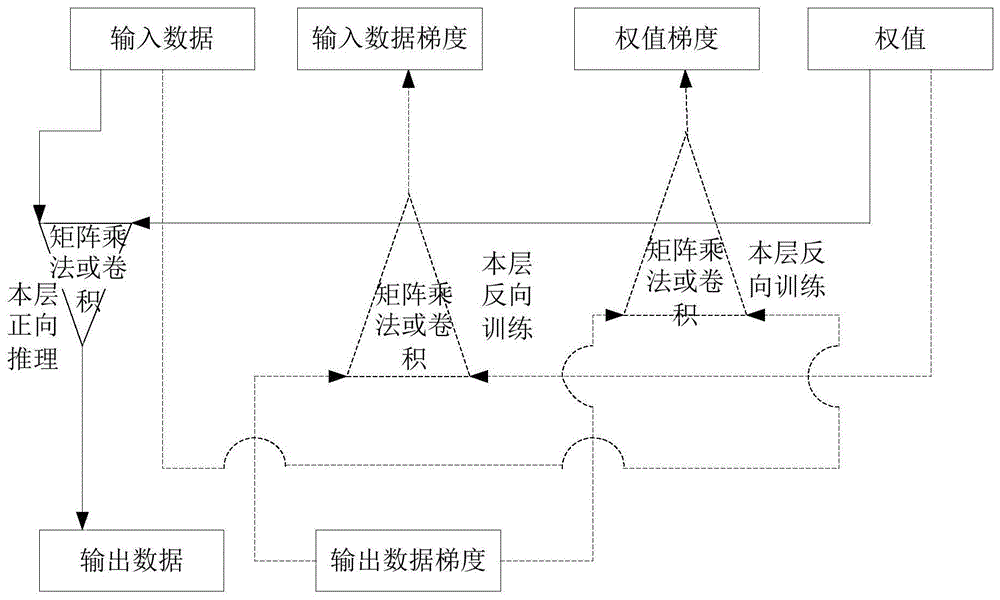
参阅图1,图1为本申请提供的一种神经网络的一个运算层的训练示意图,如图1所示,该运算层可以为全连接层或卷积层,如该运算层为全连接层,其对应的为全连接运算,例如图1所示的矩阵乘法运算,如该运算层为卷积层,其对应的为卷积运算。如图1所示,该训练包含正向推理(简称推理)和反向训练,如图1所示,该实线所示为正向推理的过程,该虚线为反向训练的过程。如图1所示的正向推理,运算层的输入数据与权值执行运算得到运算层的输出数据,该输出数据可以为该运算层的下一层的输入数据。如图1所示的反向训练过程,运算层的输出数据梯度与权值执行运算得到输入数据梯度,该输出数据梯度与输入数据运算得到权值梯度,该权值梯度用于对本运算层的权值进行更新,该输入数据梯度作为该运算层的下一层的输出数据梯度。
参阅图2,图2提供了一种神经网络运算的方法,该运算可以包括,正向推理和/或反向训练;该方法由计算芯片执行,该计算芯片可以为通用的处理器,例如中央处理器、图形处理器,当然其也可以为人工智能处理器(如专用的神经网络处理器)。当然上述方法还可以由包含计算芯片的装置来执行,该方法如图2所示,包括如下步骤:
步骤s201、计算芯片确定运算数据;
可选的,上述步骤s201中的运算数据包括但不限于:输入神经元a、输出神经元b、权重w、输入神经元导数
步骤s202、计算芯片获取量化命令,该量化命令包括连续量化精度;
步骤s203、计算芯片依据该运算数据确定该运算数据的量化精度f,依据该量化精度以及量化函数对该运算数据进行量化操作,得到量化后的数据,以使得所述人工智能处理器根据所述量化后的数据执行运算操作。
本申请提供的技术方案在确定神经网络运算数据后,确定量化精度,依据该量化函数以及量化精度对该运算数据执行数据量化得到量化后的数据,将量化后的数据执行运算得到运算结果,本申请提供的技术方案采用量化后的连续定点数据执行运算,因此能够降低内存的要求,提高运算速度,量化后的数据运算可以降低运算量,提高计算效率,因此本申请提供的技术方案具有减少运算量,提高计算速度,降低功耗的优点。
可选的,所述依据该量化精度以及量化函数对该运算数据进行量化操作,得到量化后的数据具体包括:
依据连续量化精度f以及运算数据的元素值计算得到量化后的数据。
上述依据连续量化精度f以及运算数据的元素值计算得到量化后的数据具体可以包括:
量化函数为公式(1)
其中,y为量化后的数据,x为运算数据中的一个元素值,该f为连续量化精度,该σ为取整函数,该取整函数包括但不限于:向上取整、向下取整、四舍五入、随机取整或其他取整方式。
可选的,上述计算芯片依据该运算数据以及该所需的定点数据类型确定该运算数据的量化精度具体可以包括下述方式的任意一种:
方式a、根据该运算数据绝对值最大值确定f;
具体的,计算芯片确定该运算数据的绝对值最大值amax,通过以下公式确定定点化精度f;
如该所需的定点数据类型为连续定点数据,可以通过公式2-1来确定f
其中c为常数,可取任意有理数,优选的,该c可以为[1,1.2]之间的任意有理数;当然上述c也可以不取上述范围的有理数,只需为有理数即可。上述bitnum为量化后的数据的比特位数;参阅图3,图3为连续定点数据表示示意图,对于离散定点数据,该bitnum可以取8、16、24或32。
可选的,上述amax选取方法可以采用多种方法。具体的,amax可以按数据类别寻找;当还可以分层、分类别或分组寻找。
a1、计算芯片可以采用所有层分类寻找绝对值最大值;计算芯片确定待运算数据的每个元素为
a2、计算芯片可以采用分层分类别寻找绝对值最大值;计算芯片确定待运算数据的每个元素为
a3、计算芯片可以采用分层分类别分组进寻找绝对值最大值;计算芯片确定待运算数据的每个元素为
方式b、根据该运算数据绝对值最小值确定f;
具体的,计算芯片确定该运算数据绝对值最小值amin,依据amin确定f。
如该所需的定点数据类型为连续定点数据,可以通过公式2-2确定精度f;
fa=amin*d公式2-2
其中d为常数,可取任意有理数
上述amin的按数据类别寻找;当还可以分层、分类别或分组寻找。其具体的寻找方式可以采用上述a1、a2或a3的方式,只需将a1、a2或a3中的amax替换成amin即可。
方式c、根据不同数据类型间关系确定f:
如所需的定点数据类型为连续定点数据,第1层数据a(l)的定点精度
fa(l)=∑b≠aαbfb(l)+βb公式2-3
其中αb、βb为整数常数。具体的,对于公式2-3,该αb、βb为有理数常数。
上述数据类型a(l)可以为输入神经元a、输出神经元b、权重w、输入神经元导数
方式d、计算芯片根据经验值常量确定f:
具体地,第1层数据a(l)的定点精度
可选的,上述方法还可以包括“
在执行神经网络运算时,依据待量化的数据动态调整f。
上述调整f的方法包括但不限于:向上调整f(f变大)或向下调整f(f变小)。
对于向上调整f的方式,可以为单步向上调整f,当然也可以为逐级向上调整f。
同理,对于向下调整f的方式,可以为单步向下调整f,当然也可以为逐级向下调整f。
依据待量化的数据动态调整f具体可以包括:
a)计算芯片根据待量化数据绝对值最大值单步向上调整f:
计算芯片确定调整之前f为f_old,定点可表示范围是[neg,pos],其中pos=(2bitnum-1-1)*f_old,neg=-(2bitnum-1)*f_old。当待量化数据的绝对值最大值amaxnew≥pos时,依据公式2-4调整f,否则不调整,即保持f_new=f_old
b)计算芯片根据待量化数据绝对值最大值逐步向上调整f:
调整之前f为f_old,定点可表示范围是[neg,pos]。当待量化数据的绝对值最大值amaxnew≥pos时,f_new=f_old+η,否则不调整f,即维持f_new=f_old;其中,η为逐步向上调整中单次调整的步长,例如可以为1,当然也可以为其他的数值。
c)计算芯片根据待量化数据分布单步向上调整f:
计算芯片调整之前f为f_old,定点可表示范围是[neg,pos]。该统计量可以为绝对值的均值amean和n个绝对值的标准差astd之和。具体的,统计量zmax=amean+nastd,n可取正整数,例如3。当zmax≥pos时,依据公式2-5计算得到fnew;否则不调整f。
d)计算芯片根据待量化数据分布逐步向上调整f:
计算芯片确定调整之前f为f_old,定点可表示范围是[neg,pos]。统计量zmax=amean+nastd,n可取正整数,例如3。当zmax≥pos时,f_new=f_old+η,否则不调整f。
e)计算芯片根据待量化数据绝对值最大值向下调整f:
调整之前f为f_old,定点可表示范围是[neg,pos]。当待量化数据的绝对值最大值amax<2s_old+(bitnum-n),且f_old≥fmin时,fnew=fold-η,其中n为整数常数,fmin为f可以取值范围的最小值(一般为负整数或负无穷)。
优选地n=3,fmin=-40。
可选的,上述方法还可以包括:计算芯片动态调整f的触发频率。
动态调整f的触发频率可以包括但不限于以下方法。
a)永远不触发调整,即固定f。
b)每隔δ个训练周期(iteration)调整一次,δ固定不变,调整方式可以参见上述s、f的调整方式。上述训练周期具体可以为,一个训练样本完成一次迭代运算,即一个训练样本完成一次正向运算和反向训练即一个训练周期。
优选地,上述δ可以依据数据种类设置不同的数值,例如对于输入、输出神经元和权重数据等数据类型,δ可以设置为100。对于神经元导数数据类型,δ可以设置为20。
c)每隔δ个训练epoch(时期)调整一次,δ固定不变。上述训练时期具体可以包括:训练集中的所有样本训练一次为一个训练时期,即一个训练时期可以为训练集的所有样本执行一次正向运算和反向训练即一个训练时期.
d)每隔δ个训练iteration或epoch调整一次,每隔step个iteration或epoch调整step=αδ,其中α大于1。
e)每隔δ个训练iteration或epoch调整一次,δ随着训练次数的增加,逐渐递减,例如训练次数为100时,δ=100,训练次数为180时,δ=90,训练次数为260时,δ=80。
本申请还提供一种工智能处理器,所述人工智能处理器包括:
处理单元,用于确定运算数据;获取量化命令,该量化命令包括连续量化精度;依据该运算数据确定该运算数据的量化精度f;
量化单元,用于依据该量化精度以及量化函数对该运算数据进行量化操作,得到量化后的数据,以使得所述人工智能处理器根据所述量化后的数据执行运算操作。
本披露还揭露了一个神经网络运算装置,其包括一个或多个在如图4a或如图4b所示的芯片,也可以包括一个或多个人工智能处理器。用于从其他处理装置中获取待运算数据和控制信息,执行指定的神经网络运算,执行结果通过i/o接口传递给外围设备。外围设备譬如摄像头,显示器,鼠标,键盘,网卡,wifi接口,服务器。当包含一个以上神如图4a或如图4b所示的芯片时,如图4a或如图4b所示的芯片间可以通过特定的结构进行链接并传输数据,譬如,通过pcie总线进行互联并传输数据,以支持更大规模的神经网络的运算。此时,可以共享同一控制系统,也可以有各自独立的控制系统;可以共享内存,也可以每个加速器有各自的内存。此外,其互联方式可以是任意互联拓扑。
该神经网络运算装置具有较高的兼容性,可通过pcie接口与各种类型的服务器相连接。
本披露还揭露了一个组合处理装置,其包括上述的神经网络运算装置,通用互联接口,和其他处理装置(即通用处理装置)。神经网络运算装置与其他处理装置进行交互,共同完成用户指定的操作。如5a为组合处理装置的示意图。
其他处理装置,包括中央处理器cpu、图形处理器gpu、神经网络处理器等通用/专用处理器中的一种或以上的处理器类型。其他处理装置所包括的处理器数量不做限制。其他处理装置作为神经网络运算装置与外部数据和控制的接口,包括数据搬运,完成对本神经网络运算装置的开启、停止等基本控制;其他处理装置也可以和神经网络运算装置协作共同完成运算任务。
通用互联接口,用于在所述神经网络运算装置与其他处理装置间传输数据和控制指令。该神经网络运算装置从其他处理装置中获取所需的输入数据,写入神经网络运算装置片上的存储装置;可以从其他处理装置中获取控制指令,写入神经网络运算装置片上的控制缓存;也可以读取神经网络运算装置的存储模块中的数据并传输给其他处理装置。
如图5b所示,可选的,该结构还包括存储装置,用于保存在本运算单元/运算装置或其他运算单元所需要的数据,尤其适用于所需要运算的数据在本神经网络运算装置或其他处理装置的内部存储中无法全部保存的数据。
该组合处理装置可以作为手机、机器人、无人机、视频监控设备等设备的soc片上系统,有效降低控制部分的核心面积,提高处理速度,降低整体功耗。此情况时,该组合处理装置的通用互联接口与设备的某些部件相连接。某些部件譬如摄像头,显示器,鼠标,键盘,网卡,wifi接口。
请参照图5c,图5c为本披露实施例提供的一种神经网络处理器板卡的结构示意图。如图5c所示,上述神经网络处理器板卡10包括神经网络芯片封装结构11、第一电气及非电气连接装置12和第一基板(substrate)13。
本披露对于神经网络芯片封装结构11的具体结构不作限定,可选的,如图5d所示,上述神经网络芯片封装结构11包括:神经网络芯片111、第二电气及非电气连接装置112、第二基板113。
本披露所涉及的神经网络芯片111的具体形式不作限定,上述的神经网络芯片111包含但不限于将神经网络处理器集成的神经网络晶片,上述晶片可以由硅材料、锗材料、量子材料或分子材料等制成。根据实际情况(例如:较严苛的环境)和不同的应用需求可将上述神经网络晶片进行封装,以使神经网络晶片的大部分被包裹住,而将神经网络晶片上的引脚通过金线等导体连到封装结构的外边,用于和更外层进行电路连接。
本披露对于神经网络芯片111的具体结构不作限定,可选的,请参照图4a或图4b所示的装置。
本披露对于第一基板13和第二基板113的类型不做限定,可以是印制电路板(printedcircuitboard,pcb)或印制线路板(printedwiringboard,pwb),还可能为其它电路板。对pcb的制作材料也不做限定。
本披露所涉及的第二基板113用于承载上述神经网络芯片111,通过第二电气及非电气连接装置112将上述的神经网络芯片111和第二基板113进行连接得到的神经网络芯片封装结构11,用于保护神经网络芯片111,便于将神经网络芯片封装结构11与第一基板13进行进一步封装。
对于上述具体的第二电气及非电气连接装置112的封装方式和封装方式对应的结构不作限定,可根据实际情况和不同的应用需求选择合适的封装方式并进行简单地改进,例如:倒装芯片球栅阵列封装(flipchipballgridarraypackage,fcbgap),薄型四方扁平式封装(low-profilequadflatpackage,lqfp)、带散热器的四方扁平封装(quadflatpackagewithheatsink,hqfp)、无引脚四方扁平封装(quadflatnon-leadpackage,qfn)或小间距四方扁平式封装(fine-pitchballgridpackage,fbga)等封装方式。
倒装芯片(flipchip),适用于对封装后的面积要求高或对导线的电感、信号的传输时间敏感的情况下。除此之外可以用引线键合(wirebonding)的封装方式,减少成本,提高封装结构的灵活性。
球栅阵列(ballgridarray),能够提供更多引脚,且引脚的平均导线长度短,具备高速传递信号的作用,其中,封装可以用引脚网格阵列封装(pingridarray,pga)、零插拔力(zeroinsertionforce,zif)、单边接触连接(singleedgecontactconnection,secc)、触点阵列(landgridarray,lga)等来代替。
可选的,采用倒装芯片球栅阵列(flipchipballgridarray)的封装方式对神经网络芯片111和第二基板113进行封装,具体的神经网络芯片封装结构的示意图可参照图6。如图6所示,上述神经网络芯片封装结构包括:神经网络芯片21、焊盘22、焊球23、第二基板24、第二基板24上的连接点25、引脚26。
其中,焊盘22与神经网络芯片21相连,通过在焊盘22和第二基板24上的连接点25之间焊接形成焊球23,将神经网络芯片21和第二基板24连接,即实现了神经网络芯片21的封装。
引脚26用于与封装结构的外部电路(例如,神经网络处理器板卡10上的第一基板13)相连,可实现外部数据和内部数据的传输,便于神经网络芯片21或神经网络芯片21对应的神经网络处理器对数据进行处理。对于引脚的类型和数量本披露也不作限定,根据不同的封装技术可选用不同的引脚形式,并遵从一定规则进行排列。
可选的,上述神经网络芯片封装结构还包括绝缘填充物,置于焊盘22、焊球23和连接点25之间的空隙中,用于防止焊球与焊球之间产生干扰。
其中,绝缘填充物的材料可以是氮化硅、氧化硅或氧氮化硅;干扰包含电磁干扰、电感干扰等。
可选的,上述神经网络芯片封装结构还包括散热装置,用于散发神经网络芯片21运行时的热量。其中,散热装置可以是一块导热性良好的金属片、散热片或散热器,例如,风扇。
举例来说,如图6a所示,神经网络芯片封装结构11包括:神经网络芯片21、焊盘22、焊球23、第二基板24、第二基板24上的连接点25、引脚26、绝缘填充物27、散热膏28和金属外壳散热片29。其中,散热膏28和金属外壳散热片29用于散发神经网络芯片21运行时的热量。
可选的,上述神经网络芯片封装结构11还包括补强结构,与焊盘22连接,且内埋于焊球23中,以增强焊球23与焊盘22之间的连接强度。
其中,补强结构可以是金属线结构或柱状结构,在此不做限定。
本披露对于第一电气及非电气装置12的具体形式也不作限定,可参照第二电气及非电气装置112的描述,即通过焊接的方式将神经网络芯片封装结构11进行封装,也可以采用连接线连接或插拔方式连接第二基板113和第一基板13的方式,便于后续更换第一基板13或神经网络芯片封装结构11。
可选的,第一基板13包括用于扩展存储容量的内存单元的接口等,例如:同步动态随机存储器(synchronousdynamicrandomaccessmemory,sdram)、双倍速率同步动态随机存储器(doubledateratesdram,ddr)等,通过扩展内存提高了神经网络处理器的处理能力。
第一基板13上还可包括快速外部设备互连总线(peripheralcomponentinterconnect-express,pci-e或pcie)接口、小封装可热插拔(smallform-factorpluggable,sfp)接口、以太网接口、控制器局域网总线(controllerareanetwork,can)接口等等,用于封装结构和外部电路之间的数据传输,可提高运算速度和操作的便利性。
将神经网络处理器封装为神经网络芯片111,将神经网络芯片111封装为神经网络芯片封装结构11,将神经网络芯片封装结构11封装为神经网络处理器板卡10,通过板卡上的接口(插槽或插芯)与外部电路(例如:计算机主板)进行数据交互,即直接通过使用神经网络处理器板卡10实现神经网络处理器的功能,并保护神经网络芯片111。且神经网络处理器板卡10上还可添加其他模块,提高了神经网络处理器的应用范围和运算效率。
在一个实施例里,本公开公开了一个电子装置,其包括了上述神经网络处理器板卡10或神经网络芯片封装结构11。
电子装置包括数据处理装置、机器人、电脑、打印机、扫描仪、平板电脑、智能终端、手机、行车记录仪、导航仪、传感器、摄像头、服务器、相机、摄像机、投影仪、手表、耳机、移动存储、可穿戴设备、交通工具、家用电器、和/或医疗设备。
所述交通工具包括飞机、轮船和/或车辆;所述家用电器包括电视、空调、微波炉、冰箱、电饭煲、加湿器、洗衣机、电灯、燃气灶、油烟机;所述医疗设备包括核磁共振仪、b超仪和/或心电图仪。
以上所述的具体实施例,对本披露的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本披露的具体实施例而已,并不用于限制本披露,凡在本披露的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本披露的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!