基于复杂网络模型中社团划分的个性化推荐方法与流程
本发明涉及一种信息处理技术,特别涉及一种基于复杂网络模型中社团划分的个性化推荐方法。
背景技术:
作为网络科学中的一个重要分支,链路预测通过已知的网络结构等信息预测网络中尚未产生连边的两个节点之间产生连接的可能性,广泛应用于生物网络分析、社交网络连接预测和推荐系统算法等方面。在生物网络中,以蛋白质相互作用网络为例,酵母菌蛋白质之间80%的相互作用不为人们所知,而对于人类自身,人们知道的仅有0.3%。如果能根据已有的网络结构,通过设计合理精确的链路预测算法,就能为节点间潜在的边的研究提供重要的理论与实验依据,减少盲目实验带来的昂贵实验成本。对于在线社交网络,链路预测通过推荐一些存在潜在关系的好友给用户,可以更好地帮助用户找到新朋友。在推荐系统中,链路预测可以帮助挖掘具有相同兴趣爱好的客户,也可以基于预测向用户推荐需要的物品。
现有的链路预测算法仅利用用户间好友和互动等社交关系来进行链路预测进行加强或辅助,并不依赖网络建模之后的社团发现与社团特征进行预测过程中的相似性计算以及链路预测。因此现有主流研究方法对于推荐系统中用户节点间基于属性或行为的信息利用不够充分。
技术实现要素:
本发明是针对传统的链路预测算法中信息利用不充分、预测精度低的问题,提出了一种基于复杂网络模型中社团划分的个性化推荐方法,通过全面考察用户节点的属性和用户评分的行为等信息来构造适当的复杂网络模型,并结合模型中的社团发现特征,进一步发掘潜在社团结构信息,实现更加精准的链路预测和推荐服务。
本发明的技术方案为:一种基于复杂网络模型中社团划分的个性化推荐方法,具体包括如下步骤:
1)基于推荐系统中用户对物品评分数据,提取因素相关信息的进行因素间的相关性计算;
2)依据因素间的相关性构造复杂网络模型,每个因素作为一个节点,基于构造的复杂网络拓扑通过fastunfolding社团发现算法进行社团发现,并标记节点所处不同社团,连边权值代表两个因素间的相关性大小;
3)根据因素间相关性计算结果选择目标节点的邻居节点集合;
4)基于社团发现标记的结果与邻居节点集合对目标节点的链路进行预测;
5)遍历所有m个物品,利用步骤4)进行预测,最终将预测评分从高到低排序,并评分高的物品推荐给用户。
所述步骤1)中因素为物品,则步骤1)中物品间相关性计算如下:
首先通过公式(1)对推荐系统用户评分数据归一化:
公式(1)中riα为用户ui对物品α的评分,rimax和rimin分别代表用户ui评分记录中的最高分和最低分,若最高分与最低分相等,可将归一化值赋为0,eiα∈[-1,1],eiα为归一化后用户ui对物品α的评分值;
然后,对所有m个物品之间进行相关性计算:通过公式(2)计算物品之间的相关性,对于任意两个物品α和β,其相关性计算公式为:
公式(2)中,其中m代表参与预测计算的用户数量;kα表示物品α的度,为用户对该物品评分的次数;ki表示用户ui的度,为该用户评分过的物品的个数;aiα代表用户ui是否对物品α评过分,其取值为1或0,aiα=1表示用户ui对物品α评过分,aiα=0表示用户ui没有对物品α评过分;
所述步骤3)预测如下:依据公式(3)对用户ui搜索到的每个物品β对物品α进行评分预测的值:
其中
所述步骤1)中因素为用户,则步骤1)中用户间相关性计算如下:
首先,统计用户评分分布;然后,通过公式(4)计算用户ui对物品k评分值为lz的次数fiz,通过公式(4)计算用户ui与用户uj之间的相关性sij:
公式(4)中,v为物品集合,aik代表用户ui是否对物品k评过分,其取值为1或0,aik=1表示用户ui对物品k评过分,aik=0表示用户ui没有对物品k评过分;
公式(5)中,rik表示用户ui对物品k的评分;lz表示特定的评分值;l表示数据集中评分等级集合;当某用户从未做出评分时,则sij为0。
所述步骤3)预测如下:依据公式(6)对用户评分物品α进行用户倾向分类预测;
其中
本发明的有益效果在于:本发明基于复杂网络模型中社团划分的个性化推荐方法,通过考虑用户评分分布的相似性,以及物品基于用户评分的相似性,分别构造复杂网络模型,并分别将相关性计算结果作为网络中边的权值。基于模型上进行社团发现计算结果,进行链路预测。这种基于多因素社团发现对节点相关性和预测过程的修正,在链路预测实验中有效地提高了预测精度,并为复杂网络中链路预测研究提供了新的思路与方法。
附图说明
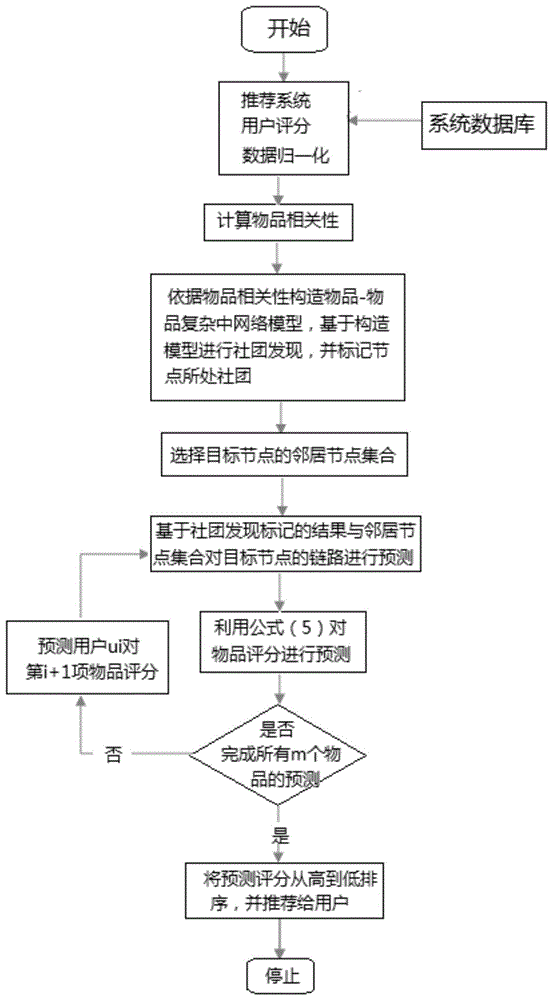
图1为本发明基于物品相关性复杂网络建模与社团发现的链路预测方法流程图;
图2为本发明基于用户倾向相关性复杂网络建模与社团发现的链路预测方法流程图;
图3为本发明item-mios社团划分标记图;
图4为本发明user-mrdc社团划分标记图。
具体实施方式
本发明通过设计统一框架,在不同因素下构造的复杂网络拓扑结构,并应用社团发现算法在复杂网络结构中进行社团发现,基于目标用户或物品所处社团,进行相关性的计算,提出一种基于复杂网络模型中社团划分的个性化推荐方法,分别为物品相关性网络社团划分算法(modulizedimprovedopinionspreading),简记为item-mios;用户评分分布行为分类社团发现算法(modulizedratingdistributionclassification),简记为user-mrdc。
本发明的基于物品相关性复杂网络建模与社团发现的链路预测方法,如图1所示包括以下步骤:
s1:首先通过公式(1)对推荐系统用户评分数据归一化:
公式(1)中riα为用户ui对物品α的评分,rimax和rimin分别代表用户ui评分记录中的最高分和最低分,若最高分与最低分相等,可将归一化值赋为0,eiα∈[-1,1],eiα为归一化后用户ui对物品α的评分值。
s2:对所有m个物品之间进行相关性计算:通过公式(2)计算物品之间的相关性,对于任意两个物品α和β,其相关性计算公式为:
公式(2)中,其中m代表参与预测计算的用户数量;kα表示物品α的度,为用户对该物品评分的次数;ki表示用户ui的度,为该用户评分过的物品的个数;aiα代表用户ui是否对物品α评过分,其取值为1或0,aiα=1表示用户ui对物品α评过分,aiα=0表示用户ui没有对物品α评过分;
s3:依据物品相关性构造物品-物品复杂中网络模型,每个物品作为一个节点,基于构造的复杂网络拓扑通过fastunfolding社团发现算法进行社团发现,并标记节点所处不同社团,结果如图3,其中节点表示数据集中的物品,连边权值代表两个物品间的相关性大小,不同灰度表示不同社团;
s4:根据公式(2)中相关性计算结果选择目标节点的邻居节点集合,选择的依据为:物品集合根据与当前物品的相似度从高到低排序,若所需邻居数量b,则选择该集合前b个元素;
s5:基于社团发现标记的结果图3(其中节点表示数据集中的节点,连边权值代表两个物品间的相关性大小,不同灰度表示不同社团),与邻居节点集合对目标节点的链路进行预测,根据物品相似性通过公式(3)计算用户对物品的评分预测;
依据公式(3)对用户ui搜索到的每个物品β对物品α进行评分预测的值:
其中
s6:遍历所有m个物品,利用步骤s5进行预测,最终将预测评分从高到低排序,并评分高的物品推荐给用户。
本发明的基于用户倾向相似性复杂网络建模与社团发现的链路预测方法,如图2所示包括以下步骤:
s1、统计用户评分分布;
s2:通过公式(4)计算用户ui对物品k评分值为lz的次数fiz,通过公式(4)计算用户ui与用户uj之间的相关性sij:
公式(4)中,v为物品集合,aik代表用户ui是否对物品k评过分,其取值为1或0,aik=1表示用户ui对物品k评过分,aik=0表示用户ui没有对物品k评过分;
公式(5)中,rik表示用户ui对物品k的评分;lz表示特定的评分值;l表示数据集中评分等级集合;当某用户从未做出评分时,则sij为0。
s3:依据用户相关性构造用户-用户复杂中网络模型,基于构造的复杂网络拓扑通过fastunfolding社团发现算法进行社团发现,并标记节点所处不同社团,结果如图4,其中节点表示数据集中的用户,连边权值代表两个用户间的相关性大小,不同灰度表示不同社团;
s4:根据公式(5)中相关性计算结果选择目标节点的邻居节点集合,选择的依据为:用户集合根据与当前用户的相似度从高到低排序,若所需邻居数量α,则选择该集合前α个元素;
s5:基于社团发现标记的结果图4(其中节点表示数据集中的用户节点,连边权值代表两个物品间的相关性大小,不同灰度表示不同社团),与邻居节点集合对目标节点的链路进行预测,依据公式(6)对用户评分物品α进行用户倾向分类预测;
其中
s6:遍历所有m个物品,利用步骤s5进行预测,最终将预测评分从高到低排序,并评分高的物品推荐给用户。
结合附图以用户评分分布行为分类社团发现算法为例,对本发明进行进一步详细说明。
设实验所用数据集中评分等级集合为l={l1,l2,...,lz},利用上述公式(3)用户ui对物品评分值为lz的次数;
利用公式(4)计算用户ui与用户uj之间的相似性,若某用户从未做出评分时,相似度为0;
以用户为复杂网络节点,以两个用户评分分部相似性计算结果作为边的权值,构造“用户-用户”网络,建立用户评分分布相似性复杂网络模型。构造复杂网络的实例如图4所示。
通过fastunfolding社团发现算法,对上述用户评分分布相似性复杂网络模型进行社团划分,最终为每个节点赋予一个社团编号,用于下一步中用户物品评分预测。部分数据集的社团划分情况如图4所示,图中相同灰度的节点属于同一社团。
基于社团划分结果通过公式(6)对用户评分进行预测。
将预测评分从高到低进行排序,并推荐给用户。
- 还没有人留言评论。精彩留言会获得点赞!