基于微表情评价面试者的方法、装置、设备和存储介质与流程
本申请涉及人工智能技术领域,尤其涉及一种基于微表情评价面试者的方法、装置、设备和存储介质。
背景技术:
普通面试程序复杂,基本上所有的企业单位对于人员的招聘,都是要从很多应聘者的简历中挑选出合格的简历,然后通过一系列的面试步骤对应聘者进行面试和考察,每一个面试步骤都要对面试方式和面试时间进行精心安排,以减少对面试官或者应聘者的日常工作和生活的影响。因此大部分的面试过程都是繁杂并且耗时的,白白浪费了参与面试的相关人员的时间,浪费了企业的资源。
目前,智能机器人的面试题库相对固定,对于被面试人的情绪识别比较缺乏,不能确定被面试人的信用度。
技术实现要素:
基于此,有必要针对对于被面试人的情绪识别比较缺乏,不能确定被面试人的信用度的问题,提供一种基于微表情评价面试者的方法、装置、设备和存储介质。
一种基于微表情评价面试者的方法,包括如下步骤:
获取预面试人员的身份信息,根据所述身份信息向所述预面试人员发送初始面试问题,根据所述预面试人员对所述初始面试问题的答题结果,得到面试方案;
获取所述预面试人员在回答面试问题时的微表情,将所述微表情入参到微表情欺诈识别模型,得到所述预面试人员的多个信用参数值;
汇总所述预面试人员对所述面试方案中各个问题的答题结果,将所述面试方案中各个问题的答题结果与标准答案进行比较后得到初始分数,根据多个所述信用参数值对所述初始分数进行修正后得到最终评价分数。
在其中一个可能的实施例中,所述获取预面试人员的身份信息,根据所述身份信息向所述预面试人员发送初始面试问题,根据所述预面试人员对所述初始面试问题的答题结果,得到面试方案之前,还包括:
发送面部生物学特征采集指令至所述预面试人员所在终端;
接收所述预面试人员所在终端发送的面部生物学样本,提取所述面部生物学样本中的数个面部生物学特征点;
将数个所述面部生物学特征点与注册人员信息表中各个注册人员的面部生物学特征进行逐个比较;
若所述预面试人员的面部生物学特征与所述注册人员信息表中的任一注册人员的面部生物学特征相匹配,则赋予所述预面试人员以面试权限,否则不赋予。
在其中一个可能的实施例中,所述获取预面试人员的身份信息,根据所述身份信息向所述预面试人员发送初始面试问题,根据所述预面试人员对所述初始面试问题的答题结果,得到面试方案,包括:
获取预面试人员的身份信息,从面试题库中抽取出所述预面试人员的身份信息对应的初始面试问题;
获取所述预面试人员对所述初始面试问题的答题结果,抽取所述答题结果中的关键词;
将所述关键词入参到预设的兴趣取向模型,得到所述预面试人员的兴趣取向,根据所述兴趣取向从所述面试题库中抽取出数个面试问题;
抽取数个所述面试问题中的任一面试问题作为初始面试问题,根据所述预面试人员对所述初始面试问题的回答结果中的特征词确定接续面试问题,将所述接续面试问题作为新的初始面试问题,直到所有所述面试回答完毕后得到所述面试方案。
在其中一个可能的实施例中,所述获取所述预面试人员在回答面试问题时的微表情,将所述微表情入参到微表情欺诈识别模型,得到所述预面试人员的多个信用参数值,包括:
获取历史面试人员微表情样本集,并根据所述历史面试人员微表情样本集构建微表情欺诈识别模型;
获取所述预面试人员在回答面试问题时的原始视频流,所述原始视频流包括所述预面试人员在回答面试问题过程中的微表情;
将所述原始视频流入参至所述微表情欺诈识别模型进行微表情识别,获得所述原始视频流的微表情识别结论;
根据原始视频流的微表情识别结论生成对应的信用参数值。
在其中一个可能的实施例中,所述汇总所述预面试人员对所述面试方案中各个问题的答题结果,将所述面试方案中各个问题的答题结果与标准答案进行比较后得到初始分数,根据多个所述信用参数值对所述初始分数进行修正后得到最终评价分数,包括:
获取所述预面试人员的对所述面试方案中各个问题的答题结果,应用文本比较算法将所述答题结果和预存于数据库中的标准答案进行文本比较,根据比较结果得到每一道问题的初始分数;
根据所述信用参数值对所述每一道问题的初始分数进行修正后得到每一道问题的真实分数;
获取各面试问题的问题等级,根据所述问题等级赋予各所述面试问题以权重,加权求和各所真实分数后得到所述最终评价分数。
在其中一个可能的实施例中,所述将所述关键词入参到预设的兴趣取向模型,得到所述预面试人员的兴趣取向,根据所述兴趣取向从所述面试题库中抽取出数个面试问题,包括:
获取数个测试测试人员的兴趣信息,提取所述兴趣信息中的特征参数,根据所述特征参数建立兴趣取向模型;
将所述关键词入参到所述兴趣取向模型中进行归类后得到所述预面试人员的兴趣取向;
遍历所述面试题库,从所述面试题库中抽取出具有所述兴趣取向对应的兴趣标签的所有面试问题,将所有所述面试问题按照生成时间进行排列后形成一面试问题序列。
在其中一个可能的实施例中,所述获取历史面试人员微表情样本集,并根据所述历史面试人员微表情样本集构建微表情欺诈识别模型,包括:
获取历史面试人员表情样本,提取所述历史面试人员表情样本的特征属性,根据预设的聚类算法将所述历史面试人员表情样本进行聚类后得到数个历史面试人员表情样本组;
从各所述历史面试人员表情样本组中均抽取出一个随机表情样本,汇总各所述随机表情样本后得到所述历史面试人员微表情样本集,将所述微表情样本集中的微表情样本分为训练样本和测试样本,在预设坐标系中绘制所述训练样本对应的训练特征点和所述测试样本对应的测试特征点;
根据所述训练特征点的位置对所述预设坐标系进行区域划分,并根据区域划分情况获取对应的分隔函数;
通过所述测试特征点对所述分隔函数进行迭代调整,直至所述分隔函数的正确分隔率达到预设阈值,得到所述微表情欺诈识别模型。
一种基于微表情评价面试者的装置,包括如下模块:
面试提问模块,设置为获取预面试人员的身份信息,根据所述身份信息向所述预面试人员发送初始面试问题,根据所述预面试人员对所述初始面试问题的答题结果,得到面试方案;
信用评价模块,设置为获取所述预面试人员在回答面试问题时的微表情,将所述微表情入参到微表情欺诈识别模型,得到所述预面试人员的多个信用参数值;
面试评分模块,设置为汇总所述预面试人员对所述面试方案中各个问题的答题结果,将所述面试方案中各个问题的答题结果与标准答案进行比较后得到初始分数,根据多个所述信用参数值对所述初始分数进行修正后得到最终评价分数。
一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,使得所述处理器执行上述基于微表情评价面试者的方法的步骤。
一种存储有计算机可读指令的存储介质,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述基于微表情评价面试者的方法的步骤。
与现有机制相比,本申请具有以下优点:
(1)通过在面试过程中引入微表情反欺诈识别,从而精准的获得面试者真实的个人情况,同时利用面试者对每一道面试题目的回答结果来确定下一道问题,从而更加准确的获知面试者的职业取向和职位契合度;
(2)通过对预面试人员进行生物特征检验以防止非面试人员进行冒名顶替,从而增强了面试的公平性;
(3)通过对面人员在参加面试过程中微表情的变化,从而有效捕捉面试人员的心理活动,从而防止面试人员做出违背自身想法的回答,从而保证了面试合格者能够胜任相关岗位;
(4)通过对面试问题进行等级划分,从而更加真实准确的对面试者是否符合相关岗位要求做出客观评价。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本申请的限制。
图1为本申请在一个实施例中的一种基于微表情评价面试者的方法的整体流程图;
图2为本申请在一个实施例中的一种基于微表情评价面试者的方法中的身份验证过程示意图;
图3为本申请在一个实施例中的一种基于微表情评价面试者的方法中的原面试提问过程示意图;
图4为本申请在一个实施例中的一种基于微表情评价面试者的方法中的信用评价过程示意图;
图5为本申请在一个实施例中的一种基于微表情评价面试者的方法中的交面试评分过程示意图;
图6为本申请在一个实施例中的一种基于微表情评价面试者的装置的结构图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本申请的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。
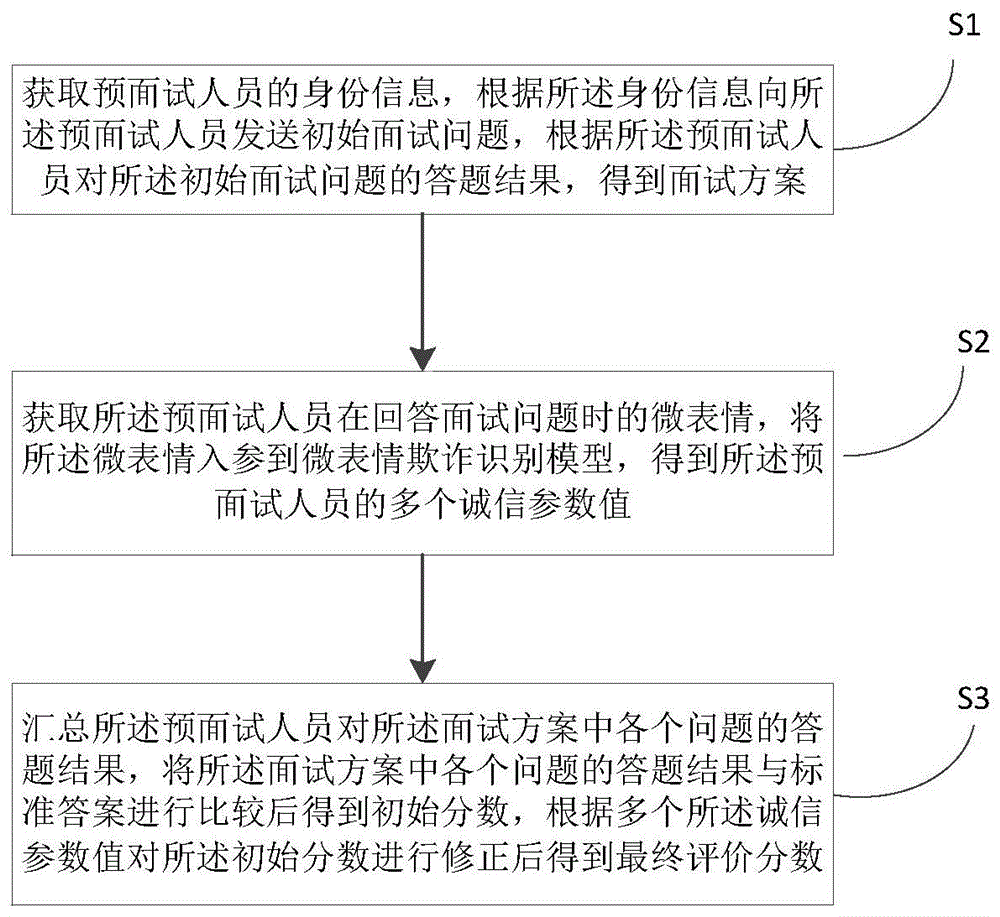
图1为本申请在一个实施例中的一种基于微表情评价面试者的方法的整体流程图,如图1所示,一种基于微表情评价面试者的方法,包括以下步骤:
s1、获取预面试人员的身份信息,根据所述身份信息向所述预面试人员发送初始面试问题,根据所述预面试人员对所述初始面试问题的答题结果,得到面试方案;
具体的,针对不同的面试人员的身份信息选择不同的面试问题,比如,对于一位曾经当过部门经理的面试者,向其发出的初始面试问题可以是管理方面的,而对于一名当毕业的大学生,初始面试问题可以人生规划方面的。在对初始问题的答题结果进行分析时,可以采用将回答问题划分成数个子块,然后从各个子块中进行关键词提取,在汇总关键词提取的结果,得到面试方案。
s2、获取所述预面试人员在回答面试问题时的微表情,将所述微表情入参到微表情欺诈识别模型,得到所述预面试人员的多个信用参数值;
具体的,微表情欺诈模型可以根据历次面试数据统计后得到,在面试的过程中提取面试人员的图像,然后将图像入参到神经网络模型中进行训练后即可得到专门用于进行微表情识别的一微表情欺诈识别模型。具体的,在应用神经网络模型进行训练时,可以将同一组测试人员分2次回答相同的问题,第一次不欺诈,第二次在某些问题上欺诈,然后将第1次的数据作为标准样本,第2次的数据作为测试样本,分别入参到在神经网络模型中进行训练。
s3、汇总所述预面试人员对所述面试方案中各个问题的答题结果,将所述面试方案中各个问题的答题结果与标准答案进行比较后得到初始分数,根据多个所述信用参数值对所述初始分数进行修正后得到最终评价分数。
具体的,在对答题结果和标准结果进行比较时,可以设置一个误差阈值,若所述答题结果和所述标准答案的文字不一致的数量大于误差阈值,则答题结果为“错误”打0分,小于误差阈值则打“1”分。
本实施例,通过在面试过程中引入微表情反欺诈识别,从而精准的获得面试者真实的个人情况,同时利用面试者对每一道面试题目的回答结果来确定下一道问题,从而更加准确的获知面试者的职业取向和职位契合度。
图2为本申请在一个实施例中的一种基于微表情评价面试者的方法中的身份验证过程示意图,如图所示,所述s1、获取预面试人员的身份信息,根据所述身份信息向所述预面试人员发送初始面试问题,根据所述预面试人员对所述初始面试问题的答题结果,得到面试方案之前,还包括:
s01、发送面部生物学特征采集指令至所述预面试人员所在终端;
具体的,面部生物学特征可以是虹膜特征或者是面部特征,在采集到预面试人员的面部生物学样本后,需要对面部生物学样本进行特征点识别,比如,对面部特征的识别可以是对鼻子特征、嘴部特征进行识别。注册人员信息表是在每一个参见面试人员首次登录到面试系统进行报名时采集的,在注册人员信息表上存储有参加面试人员的姓名、年龄等信息和面部生物学特征信息。预面试人员所在终端可以是pc端也可以是app端,针对于面试人员采用手机app进行远程面试的场景,在发送面部生物学特征采集指令至预面试人员所在终端时,还需要对手机进行gps定位,以便在后续步骤对面试人员微表情进行判断时,排除场景的干扰。
s02、接收所述预面试人员所在终端发送的面部生物学样本,提取所述面部生物学样本中的数个面部生物学特征点;
其中,面部生物学特征点主要是指鼻子高度,嘴型轮廓或者指纹中的交叉点和终止点的位置等。
s03、将数个所述面部生物学特征点与注册人员信息表中各个注册人员的面部生物学特征进行逐个比较;
s04、若所述预面试人员的面部生物学特征与所述注册人员信息表中的任一注册人员的面部生物学特征相匹配,则赋予所述预面试人员以面试权限,否则不赋予。
其中,在将预面试人员的面部生物学特征与注册人员信息表中的注册人员面部生物学特征信息进行比较前,可以根据预面试人员输入的姓名、性别和年龄等身份信息,遍历所述注册人员信息表,若所述注册人员信息表中没有该预面试人员的身份信息,则向预面试人员发出重新输入身份信息的指令,若所述预面试人员再次输入的身份信息仍然不在与注册人员信息表中,则不向该预面试人员开放面试系统。
本实施例,通过对预面试人员进行生物特征检验以防止非面试人员进行冒名顶替,从而增强了面试的公平性。
图3为本申请在一个实施例中的一种基于微表情评价面试者的方法中的原面试提问过程示意图,如图所示,所述s1、获取预面试人员的身份信息,根据所述身份信息向所述预面试人员发送初始面试问题,根据所述预面试人员对所述初始面试问题的答题结果,得到面试方案,包括:
s11、获取预面试人员的身份信息,从面试题库中抽取出所述预面试人员的身份信息对应的初始面试问题;
具体的,预面试人员的身份信息主要是指姓名、年龄、工作经历等信息,根据这些身份信息,遍历面试题库中各个题目所标记的关键词,通过关键词检索获得最符合所述身份信息的初始面试问题。比如,一位30岁的硕士工程师,在面试题库中可以搜索的关键词为“30”、“工程师”,在遍历各个题目后将带有“30”和“工程师”的题目全部抽取出来,根据历次面试过程中这些题目的使用率,得到最优初始面试问题。
s12、获取所述预面试人员对所述初始面试问题的答题结果,抽取所述答题结果中的关键词;
其中,结果关键词是指具有倾向性的词语,通常初始面试问题为选择性问题,即面试者只需要进行选择数个结果中的一个或者多个。比如,初始面试问题为:“可以加班吗”,回答的关键词为“是”或者“否”这样具有倾向性的词语。
s13、将所述关键词入参到预设的兴趣取向模型,得到所述预面试人员的兴趣取向,根据所述兴趣取向从所述面试题库中抽取出数个面试问题;
其中,兴趣取向模型是根据历史数据统计获得的,兴趣取向主要是指适合做什么类型的工作,比如,a的兴趣取向为钻研问题,则给a的面试问题为“研发类”问题。
s14、抽取数个所述面试问题中的任一面试问题作为初始面试问题,根据所述预面试人员对所述初始面试问题的回答结果中的特征词确定接续面试问题,将所述接续面试问题作为新的初始面试问题,直到所有所述面试回答完毕后得到所述面试方案。
其中,特征词是指具有倾向性的词语,比如“愿意”、“不可以”等词语,如果是“愿意”则跳转到问题“a”不愿意则跳转到问题“b”,若在回答问题“b”依次根据每一个题目的回答结果中的特征词确定下一题的内容。
本实施例,通过对面试人员回答初始面试问题后得到的结果来确定下一道面试问题,从而准确的获知了面试人员的职业取向。
图4为本申请在一个实施例中的一种基于微表情评价面试者的方法中的信用评价过程示意图,如图所示,所述s2、获取所述预面试人员在回答面试问题时的微表情,将所述微表情入参到微表情欺诈识别模型,得到所述预面试人员的多个信用参数值,包括:
s21、获取历史面试人员微表情样本集,并根据所述历史面试人员微表情样本集构建微表情欺诈识别模型;
具体的,微表情样本集是根据历次面试过程数据进行分析后得到的,在面试者进行面试的过程中对某一个问题是否存在着瞳孔突然放大,目光飘忽为欺骗特征等欺诈特征,若存在这些特征则进行标记,然后将带有标记的训练样本入参到机器学习模型中进行训练,以获得微表情欺诈识别模型。其中,机器学习模型可以是通过神经网络、遗传算法、支持向量机等多种方式实现。
s22、获取所述预面试人员在回答面试问题时的原始视频流,所述原始视频流包括所述预面试人员在回答面试问题过程中的微表情;
其中,原始视频流的获取,可以先从面试视频中进行关键帧提取,比如面试人员开始回答问题的帧作为开始进行原始视频流的开始帧,结束答题时的面试人员可以点击面试屏幕的结束按钮,当接收到结束按钮别出发的信息后,屏幕上的画面作为原始视频流的结束帧。
s23、将所述原始视频流入参至所述微表情欺诈识别模型进行微表情识别,获得所述原始视频流的微表情识别结论;
其中,在将原始视频流入参到微表情欺诈识别模型时,可以根据面试人员回答问题情况,将每一个问题作为一个单元实时入参到微表情欺诈识别模型中进行欺诈识别,进而得到面试人员在回答每一个问题时是否存在欺诈行为进行判断。更进一步的,可以对面试人员回答每一个问题时的每一个语句入参到微表情欺诈识别模型,从而识别出哪一个语句存在着欺诈。
s24、根据原始视频流的微表情识别结论生成对应的信用参数值。
具体的,汇总面试人员在回答每一个问题时是否存在着欺诈行为,若在某一个问题回答时存在着欺诈行为,则该题目对应的回答结果作废,即该题目的信用参数值为“0”,对于不存在欺诈行为的题目,信用参数值为“1”。
本实施例,通过对面人员在参加面试过程中微表情的变化,从而有效捕捉面试人员的心理活动,从而防止面试人员做出违背自身想法的回答,从而保证了面试合格者能够胜任相关岗位。
图5为本申请在一个实施例中的一种基于微表情评价面试者的方法中的交面试评分过程示意图,如图所示,所述s3、汇总所述预面试人员对所述面试方案中各个问题的答题结果,将所述面试方案中各个问题的答题结果与标准答案进行比较后得到初始分数,根据多个所述信用参数值对所述初始分数进行修正后得到最终评价分数,包括:
s31、获取所述预面试人员的对所述面试方案中各个问题的答题结果,应用文本比较算法将所述答题结果和预存于数据库中的标准答案进行文本比较,根据比较结果得到每一道问题的初始分数;
具体的,在进行文本比较时,可以将每一道问题的答题结果划分成数个子语段,子语段的长度可以根据标准答案中语句长度进行划分。比如,标准答案为:“首先向组长回报,再向部门经理汇报。”则相应的答题结果可以划分为“首先向组长回报”和“再向部门经理汇报”两个子语段。然后,将每一个子语段的内容和标准答案进行文本相似性比较。汇总比较的结果,若所有子语段与标准答案的误差都在误差阈值以内,则对该题目打“1”分,否则打“0”分。
s32、根据所述信用参数值对所述每一道问题的初始分数进行修正后得到每一道问题的真实分数;
其中,修正的依据是若该面试参加者在回答任一问题时是否存在着欺诈行为,若存在欺诈行为则该问题的回答记为“0”分,而对于其它未出现欺诈行为的题目,则按照实际答题结果进行评分。
s33、获取各面试问题的问题等级,根据所述问题等级赋予各所述面试问题以权重,加权求和各所真实分数后得到所述最终评价分数。
具体的,可以将问题等级分为3个等级,第一级为“核心问题”,比如,是否可以出差;第二级为“主要问题”,比如,预期收入是多少;第三级为“一般问题”,比如,兴趣爱好是什么。针对不同等级的问题设置有不同的权重,比如,第一等级的问题权重是1,第二等级的问题权重是0.8,第三等级的问题权重是0.4;然后进行加权求和就可以得到对于该面试人员的面试评价分数,然后将此面试评价分数与预设的期望分数进行比较,大于期望分数则进行下一环节工作,否则通知该参加面试人员面试失败。
本实施例,通过对面试问题进行等级划分,从而更加真实准确的对面试者是否符合相关岗位要求做出客观评价。
在一个实施例中,所述s13、将所述关键词入参到预设的兴趣取向模型,得到所述预面试人员的兴趣取向,根据所述兴趣取向从所述面试题库中抽取出数个面试问题,包括:
获取数个测试测试人员的兴趣信息,提取所述兴趣信息中的特征参数,根据所述特征参数建立兴趣取向模型;
其中,特征参数是根据兴趣信息中所反映的兴趣,然后将不同的兴趣进行数值转换后得到的。在进行转换时,可以将类似的兴趣进行聚类后采用同一个特征参数,比如,“游泳”和“跑步”就可以用体育对应的特征参数。
将所述关键词入参到所述兴趣取向模型中进行归类后得到所述预面试人员的兴趣取向;
其中,在进行分类时可以采用马儿科夫模型进行兴趣度相关性计算,计算公式为
式子中,fg()表示兴趣度函数,kg表示任一兴趣点,kj表示第j个兴趣点,n表示兴趣点总个数。
遍历所述面试题库,从所述面试题库中抽取出具有所述兴趣取向对应的兴趣标签的所有面试问题,将所有所述面试问题按照生成时间进行排列后形成一面试问题序列。
本实施例,利用兴趣取向模型对面试者需要回答的问题进行了有效筛选,从而获知面试者与相关岗位的契合度。
在一个实施例中,所述s21、获取历史面试人员微表情样本集,并根据所述历史面试人员微表情样本集构建微表情欺诈识别模型,包括:
获取历史面试人员表情样本,提取所述历史面试人员表情样本的特征属性,根据预设的聚类算法将所述历史面试人员表情样本进行聚类后得到数个历史面试人员表情样本组;
具体的,表情样本的特征属性可以是瞳孔、目光或者是嘴角张开的幅度等。所使用的聚类算法可以是k-means(k均值)聚类、均值漂移聚类等常用的聚类算法。
从各所述历史面试人员表情样本组中均抽取出一个随机表情样本,汇总各所述随机表情样本后得到所述历史面试人员微表情样本集,将所述微表情样本集中的微表情样本分为训练样本和测试样本,在预设坐标系中绘制所述训练样本对应的训练特征点和所述测试样本对应的测试特征点;
其中,可以将训练样本或者测试样本中的数据分为两组,一组为正常数据,一组为欺诈数据,正常数据在预设坐标系的第一象限为正数,欺诈数据在预设坐标系的第四象限为负数。训练特征点或者测试特征点就是指在预设坐标系上处于这两个象限的数据点。
根据所述训练特征点的位置对所述预设坐标系进行区域划分,并根据区域划分情况获取对应的分隔函数;
其中,分割函数的作用是将训练特征点进行划分,分割函数可以是径函数等对于坐标系进行划分的函数。通过对坐标系进行划分可以有效获得训练特征点所处于的象限位置,从而得到训练样本中存在着多少个欺诈数据。
通过所述测试特征点对所述分隔函数进行迭代调整,直至所述分隔函数的正确分隔率达到预设阈值,得到所述微表情欺诈识别模型。
其中,在进行迭代调整时可以采用一次迭代法,也可以采用多次迭代法,在采用多次迭代法时可以对分割函数进行动态调整,从而更加快速的达到预设阈值。
本实施例,将面试人员的微表情进行分组,总而避免了采用一组数据对面试人员微表情进行分析造成的误差。
在一个实施例中,提出了一种基于微表情评价面试者的装置,如图6所示,包括如下模块:
面试提问模块51,设置为获取预面试人员的身份信息,根据所述身份信息向所述预面试人员发送初始面试问题,根据所述预面试人员对所述初始面试问题的答题结果,得到面试方案;
信用评价模块52,设置为获取所述预面试人员在回答面试问题时的微表情,将所述微表情入参到微表情欺诈识别模型,得到所述预面试人员的多个信用参数值;
面试评分模块53,设置为汇总所述预面试人员对所述面试方案中各个问题的答题结果,将所述面试方案中各个问题的答题结果与标准答案进行比较后得到初始分数,根据多个所述信用参数值对所述初始分数进行修正后得到最终评价分数。
在一个实施例中,提出了一种计算机设备,所述计算机设备包括存储器和处理器,存储器中存储有计算机可读指令,计算机可读指令被处理器执行时,使得处理器执行上述各实施例中的所述基于微表情评价面试者的方法的步骤。
在一个实施例中,提出了一种存储有计算机可读指令的存储介质,该计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述各实施例中的所述基于微表情评价面试者的方法的步骤。其中,所述存储介质可以为非易失性存储介质。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(rom,readonlymemory)、随机存取存储器(ram,randomaccessmemory)、磁盘或光盘等。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请一些示例性实施例,其中描述较为具体和详细,但并不能因此而理解为对本申请专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!