基于时空重要性和3DCNN的视频中行为识别方法与流程
本发明涉及一种视频中行为识别方法,尤其涉及一种基于时空重要性和3dcnn的视频中行为识别方法,其中3dcnn指三维卷积神经网络,属于深度学习和视频识别技术领域。
背景技术:
视频是一种重要的信息载体,人们常常需要通过观察、识别视频中人体行为以达到特定的目的。然而,传统的依靠人眼观察、人脑处理的人体行为识别模式已经不能满足海量视频数据处理的需求。随着计算机处理数据能力的增强,用计算机模仿人类大脑处理视频并识别其中发生的行为已逐渐变为现实,该项技术在视频监控、虚拟现实、机器人等领域具有广阔的应用前景。
然而,由于行为本身复杂的动特性以及视频拍摄环境的不可控性,利用计算机识别视频中的人体行为并非是一项简单的任务。近年来,深度学习的兴起将行为识别向前推进了一大步。在大规模训练集和gpu支持下,深度学习通过卷积神经网络(cnn)的卷积层特征提取功能、全连接层分类功能以及随机梯度学习算法,全面地挖掘目标多层次特征并进行分类,实现由像素到类别的“end-to-end”的识别模式。虽然在某些图像分类任务中深度学习的识别能力甚至超过人类,但深度学习用于行为识别远没有图像分类成功,其根本原因在于视频是由多帧图像按时间顺序堆叠构成,具有复杂的时空特性,如何有效提取视频整体时空信息是行为识别的关键。
时域片段网络(tsn)是一种典型的获取视频整体时空信息进行行为识别的方法,该方法先将视频在时域分割成多个片段,再利用cnn提取每个片段特征并计算其类别分值,最后通过平均法获取视频类别分值。这种方法平等地对待视频所有时空位置的信息,然而,视频中除了行为信息外还存在大量背景或干扰信息,它们对行为识别的重要性是不同的。首先,人们在识别视频中的行为时,并不是均匀地观察整个空域场景,而是习惯地将目光集中在行为发生的区域,这意味着视频中不同空域位置对行为识别的贡献不同。其次,对于实际场景拍摄的视频,不是所有时间段内都有感兴趣的行为发生,尤其是没有剪辑的视频中存在大量和感兴趣行为无关的帧或片段,它们包含对行为识别有用的信息很少。因此,根据视频不同时空位置对行为识别的重要性,有选择地提取时空信息更有利于改善行为识别性能。
技术实现要素:
本发明的目的在于提供一种基于时空重要性和3dcnn的视频中行为识别方法,将空域重要位置选择、时域重要片段选择和3dcnn特征提取及分类功能相结合,以选择时域、空域重要信息进行行为识别,抑制无关信息的影响,提高行为识别性能。
为了解决所述技术问题,本发明采用的技术方案是:基于时空重要性和3dcnn的视频中行为识别方法,包括以下步骤:
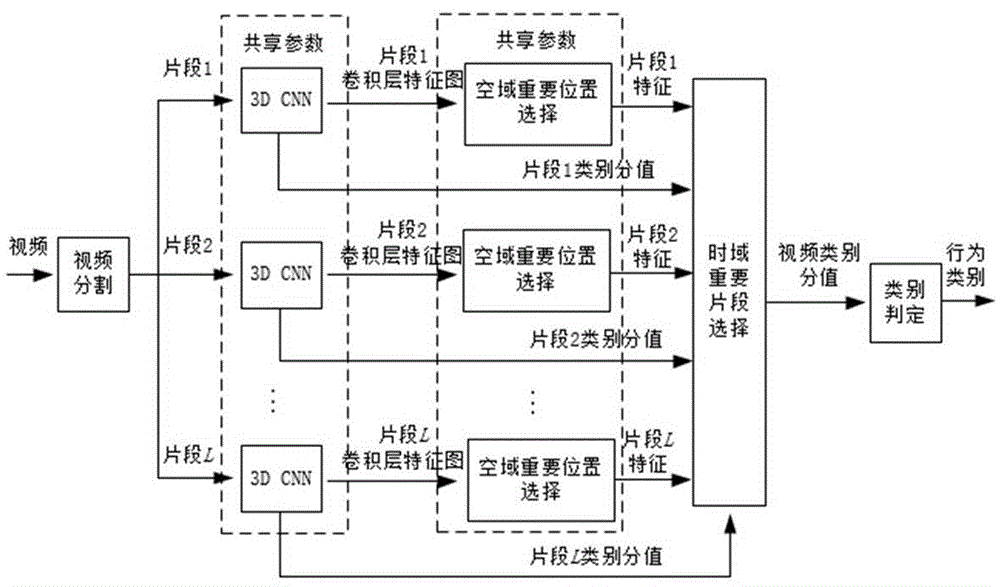
s01)、构建一个行为识别模型,用于判别输入视频中正在发生的行为类别,行为识别模型包括视频分割模块、3dcnn模块、空域重要位置选择模块、时域重要片段选择模块和类别判定模块,视频分割模块将输入的行为视频在时域进行分割得到多个视频片段;3dcnn对分割后的每个视频片段进行特征提取与分类,从其中一个卷积层输出片段特征图,从softmax层输出片段的类别分值;空域重要位置选择模块根据每个片段特征图计算其空域位置的重要性,再利用位置重要性对特征图中各个位置的局部特征进行空域选择,得到片段特征;时域重要片段选择模块根据视频每个片段特征计算其重要性,再依据片段重要性对视频各个片段的类别分值进行时域选择,得到视频的类别分值;类别判定模块将分值最大的类别判定为当前视频中行为的类别;
s02)、利用大量已知类别的行为视频作为样本构建训练数据集,并将其中每个视频的空域尺寸缩放到固定大小;
s03)、基于步骤s02构建的训练数据集,采用分阶段的方式对步骤s01中的行为识别模型进行训练,使其具有自动选择时域重要片段和空域重要位置的信息进行行为识别的能力;
s04)、将待识别的行为视频的空域尺寸缩放到固定大小,再输入到训练后的行为识别模型,模型输出视频中行为的类别。
进一步的,步骤s01中,视频分割模块在时域按照相等的间隔将整个视频分割成给定数目的子视频,对每一个子视频,利用随机的方法确定一个时域位置,再从该位置开始向前或者向后截取一定数目的连续帧构成视频片段,所有子视频的片段按照时间顺序组成一个片段序列。
进一步的,步骤s01中,空域重要位置选择模块包括全连接层、softmax层和特征加权求和子模块,全连接层根据3dcnn输出的片段特征图中每个空域位置局部特征计算该位置的重要性,第l个片段特征图中第k个空域位置局部特征xl,k输入到全连接层,全连接层输出该位置的重要性:
进一步的,步骤s01中,时域重要片段选择模块包括一个全连接层、两个softmax层和一个类别分值加权求和子模块,全连接层神经元个数为行为类别数c,全连接层根据空域重要位置选择模块输出的片段特征计算每个片段对所有行为类别的重要性,第l个片段特征
进一步的,步骤s03中,训练参数包括3dcnn的参数、空域重要位置选择模块中的全连接层参数、时域重要片段选择模块中的全连接层参数。
进一步的,模型训练包括以下步骤:
s31)、初始化模型的训练参数;
s32)、将模型中的空域重要位置选择模块和时域重要片段选择模块的参数设置为不可训练,将空域位置重要性和片段重要性固定为等概率分布,利用训练数据集对模型中3dcnn的参数进行训练;
s33)、将模型的所有训练参数设置为可训练,取消空域位置重要性和片段重要性的等概率分布设置,设置模型中3dcnn的学习速率远小于空域重要位置选择模块和时域重要片段选择模块的学习速率,利用训练数据集对模型的所有训练参数进行训练。
本发明的有益效果:本发明将空域重要位置选择功能、时域重要片段选择功能和3dcnn的特征提取和分类功能相结合,通过计算视频的空域位置重要性和时域片段重要性,并利用重要性对空域位置特征和片段类别分值进行选择,突出对行为识别有用的时空信息在行为识别中的贡献,抑制背景或其他无关信息的影响,从而提高行为识别性能。
附图说明
图1为行为识别模型的系统框图;
图2为视频时域分割示意图;
图3为3dcnn结构示意图;
图4为空域重要位置选择模块的结构示意图;
图5为时域重要片段选择模块的结构示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步的说明。
实施例
本实施例公开一种基于时空重要性和3dcnn的视频中行为识别方法,具体包括以下步骤:
s01)、行为识别模型构建
首先,构建一个行为识别模型,本实施例中,所述行为识别模型输入为视频,输出为视频中行为的类别。如图1所示,该模型包括视频分割模块、3dcnn模块、空域重要位置选择模块、时域重要片段选择模块和类别判定模块。视频分割模块将输入的行为视频在时域进行分割得到多个视频片段;3dcnn对分割后的每个视频片段进行特征提取与分类,从其中一个卷积层输出片段特征图,从softmax层输出片段的类别分值;空域重要位置选择模块根据每个片段特征图计算其空域位置的重要性,再利用位置重要性对特征进行空域选择,得到视频每个片段特征;时域重要片段选择模块根据视频每个片段特征计算其重要性,再依据片段重要性对片段的类别分值进行时域选择,得到视频的类别分值;类别判定模块将分值最大的类别判定为当前视频中行为的类别。各模块的具体设计如下:
(1)视频分割模块
如图2所示,视频分割模块先在时域按照相等的间隔将整个视频分割成l个子视频,对每一个子视频,利用随机的方法确定一个时域位置,再从该位置开始向前或者向后截取t个连续帧构成视频片段,所有子视频的片段按时间顺序组成一个片段序列。
(2)3dcnn(三维卷积神经网络)
如图3所示,3dcnn采用dutran提出的c3d构架,包含五个卷积层五个最大值池化层,两个全连接层和一个softmax层。除最后一个卷积层外,每一个卷积层经池化层后和后一卷积层相连,最后一个卷积层经池化层后和第一个全连接层相连,第二个全连接层连接到softmax层。所有卷积层的卷积核大小为3×3×3,步长为[1,1,1];第一个池化层的池化核大小为1×2×2,步长为[1,2,2],其它池化层的池化核大小为2×2×2,步长为[2,2,2];各卷积层的滤波器个数依次为64,128,256,512,512;第一个全连接层神经元个数为4096,第二个全连接层神经元个数为行为类别数c。
将视频每个片段输入到一个共享参数的3dcnn,从第四个卷积层输出片段特征图,对第l个片段,其特征图包含的所有局部特征为[xl,1,xl,2,…xl,k],其中,xl,k为特征图中第k个空域位置的局部特征,k为位置总数;从softmax层输出片段的类别分值,第l个片段的类别分值为[sl,1,sl,2,…,sl,c],其中,sl,c为第c个类别分值。
(3)空域重要位置选择模块
如图4所示,空域重要位置选择模块由全连接层、softmax层和特征加权求和子模块组成。
全连接层根据3dcnn的第四个卷积层输出的特征图中每个空域位置的局部特征,计算该位置的重要性。全连接层包含一个神经元,其权重向量为
softmax层将各个空域位置的重要性归一化。将第l个片段第k个空域位置的重要性
特征加权求和子模块以归一化的重要性为权值,对3dcnn第四个卷积层输出的片段特征图中各个空域位置的局部特征加权求和获取片段特征,第l个片段特征为
(4)时域重要片段选择模块
如图5所示,该模块由一个全连接层、两个softmax层和一个类别分值加权求和子模块组成。
全连接层根据片段特征获取片段对每一个行为类别的重要性。全连接层神经元个数为行为类别数c,其权重矩阵为
第一个softmax层将视频所有片段的重要性归一化。对第c个类别,所有片段归一化的重要性为
类别分值加权求和子模块以片段归一化的重要性为权值对视频所有片段的同一个类别的分值进行加权求和,获取视频的类别分值。若3dcnn输出的各个片段对第c个类别的分值为[s1,c,s2,c,…,sl,c],视频第c个类别的分值为
第二个softmax层将视频各个类别的分值归一化,得到归一化的视频类别分值
(5)类别判定模块
类别判定模块求视频类别分值最大值对应的类别
s02)、训练数据集构建
训练数据集可采用ucf101split1的数据集,共包含9537个训练视频,分为101个行为类别,训练前将每个视频空域尺寸缩放到112×112像素。
s03)、模型训练
利用训练数据集对行为识别模型进行训练,使其具有自动选择时域重要片段和空域重要位置的信息进行行为识别的能力。模型训练参数包括:3dcnn的参数、空域重要位置模块中的全连接层参数、时域重要片段选择模块中的全连接层参数。采用分阶段的训练方式,具体过程如下:
(1)初始化模型训练参数,模型的权重参数采用xavier方法初始化,模型的偏置参数初始化为0;
(2)将模型中的空域重要位置选择模块和时域重要片段选择模块的参数设置为不可训练,将空域位置重要性和片段重要性固定为等概率分布,利用训练数据集对模型中3dcnn的参数进行训练;
(3)将模型的所有训练参数设置为可训练,取消空域位置重要性和片段重要性的等概率分布设置,设置模型中3dcnn的学习速率远小于空域重要位置选择模块和时域重要片段选择模块的学习速率,利用训练数据集对模型的所有训练参数进行训练。
上述每一阶段均采用批量的方式进行多轮训练。每一轮开始前利用随机的方法重新设置训练数据集中的视频顺序,每次从训练数据集中按序取出给定数目视频输入到行为识别模型判别视频类别,根据视频的真实类别和模型的判别类别计算交叉熵损失函数,并求交叉熵损失函数对训练参数的导数用于修正参数。上述过程不断重复,直至训练数据集中所有视频都输入到模型,训练过程完成一轮。对模型进行一轮一轮的训练,直至达到预定的训练轮数为止。
s04)、行为识别
将待识别的行为视频的空域尺寸缩放到112×112像素,再输入到训练后的行为识别模型,模型输出视频中行为的类别。
以上描述的仅是本发明的基本原理和优选实施例,本领域技术人员根据本发明做出的改进和替换,属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!