高并发数据查询方法、装置、系统、设备及可读存储介质与流程
本发明涉及大数据技术领域,特别涉及一种高并发数据查询方法、装置、系统、设备及计算机可读存储介质。
背景技术:
在大数据实时分析领域,需要在短时间内从海量数据中查询数据并聚合为结果,具:数据量大、计算密集型、响应时间短(通常在5秒内)。为了提升查询性能,通常会把数据按照一定的逻辑切成多个数据分片,分别存储在多台服务器上,用户进行查询时,从多个服务器上并行查询数据,然后交给汇总服务器汇总结果返回给用户。数据分片通常为主备两个副本,分别存在不同的服务器上,这样可以提高系统的容错能力和可用性。
在少量用户查询情况下,上述的大数据实时分析可以在相对合理的时间内响应,当查询并发量大时,由于对数据分片的读写(io)、计算(cpu)出现争抢的情况,导致查询的响应时长急聚上升,例如:2个用户并发查询情况下,在1秒返回结果,20个用户并发查询,在10秒返回结果,高并发查询情况下,用户查询等待时间变长。
技术实现要素:
为了解决现有技术的问题,本发明实施例提供了一种高并发数据查询方法、装置、系统、设备及可读存储介质,在大数据高并发查询场景下,使得用户的查询性能不会降低,查询性能稳定,波动小。所述技术方案如下:
第一方面,提供了一种高并发数据查询方法,所述方法包括:根据数据分片的查询历史数据获取查询并发数;根据所述查询并发数计算得到写入副本数;根据所述写入副本数,按照写入负载指数由低到高分别写入到对应节点;根据数据分片的查询请求,按照查询负载指数由低到高到相应节点获取查询结果。
结合第一方面,在第一种可能的实现方式中,根据所述查询并发数计算得到写入副本数,包括:根据所述查询并发数以及每个副本支持并发数计算得到写入副本数。
结合第一方面,在第二种可能的实现方式中,根据所述写入副本数,按照写入负载指数由低到高分别写入到对应节点,包括:根据每个节点当前的io利用率、cpu利用率以及第一预设权重规则计算得到所有节点的写入负载指数。
结合第一方面,在第三种可能的实现方式中,根据数据分片的查询请求,按照查询负载指数由低到高到相应节点获取查询结果,包括:根据每个节点当前的io利用率、cpu利用率、网络负荷利用率以及第二预设权重规则计算得到所有节点的查询负载指数。
结合第一方面及第一方面的第一至三种可能实现方式的任一种,在第四至七种可能的实现方式中,所述方法还包括:根据所述数据分片的查询历史数据,利用arima时间序列模型预测未来需要增加的增加副本数,根据所述增加副本数进行副本动态调整。
第二方面,提供了一种高并发数据查询装置,所述装置包括:查询并发数获取模块,用于根据数据分片的查询历史数据获取查询并发数;写入副本数计算模块,用于根据所述查询并发数计算得到写入副本数;副本写入模块,用于根据所述写入副本数,按照写入负载指数由低到高分别写入到对应节点;查询结果获取模块,用于根据数据分片的查询请求,按照查询负载指数由低到高到相应节点获取查询结果。
结合第二方面,在第一种可能的实现方式中,所述写入副本数计算模块用于:根据所述查询并发数以及每个副本支持并发数计算得到写入副本数。
结合第二方面,在第二种可能的实现方式中,所述副本写入模块包括第一计算子模块,所述第一计算子模块用于:根据每个节点当前的io利用率、cpu利用率以及第一预设权重规则计算得到所有节点的写入负载指数。
结合第二方面,在第三种可能的实现方式中,所述查询结果获取模块包括第二计算子模块,所述第二计算子模块用于:根据每个节点当前的io利用率、cpu利用率、网络负荷利用率以及第二预设权重规则计算得到所有节点的查询负载指数。
结合第二方面及第二方面的第一至三种可能实现方式的任一种,在第四至七种可能的实现方式中,所述装置还包括副本动态调整模块,用于:根据所述数据分片的查询历史数据,利用arima时间序列模型预测未来需要增加的增加副本数,根据所述增加副本数进行副本动态调整。
第三方面,提供了一种高并发数据查询系统,所述系统包括数据副本管理器、数据加载器、查询负载均衡器以及多个节点,其中,所述数据副本管理器用于:根据数据分片的查询历史数据获取查询并发数,并根据所述查询并发数计算得到写入副本数;所述数据加载器,用于根据所述写入副本数,按照写入负载指数由低到高分别写入到对应节点;所述查询负载均衡器,用于根据数据分片的查询请求,按照查询负载指数由低到高到相应节点获取查询结果。
结合第三方面,在第一种可能的实现方式中,所述数据副本管理器还用于:根据所述数据分片的查询历史数据,利用arima时间序列模型预测未来需要增加的增加副本数,根据所述增加副本数进行副本动态调整。
第四方面,提供了一种高并发数据查询设备,包括:处理器;存储器,用于存储有所述处理器的可执行指令;其中,所述处理器配置为经由所述可执行指令来执行上述方案任一项所述的高并发数据查询方法的步骤。
第五方面,提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述方案任一项所述的高并发数据查询方法的步骤。
本发明实施例提供的技术方案带来的有益效果是:
1、根据数据分片的查询历史数据获取查询并发数,再根据所述查询并发数计算得到写入副本数,能够根据数据分片的一般查询需求获知所需写入副本数量,然后按照写入负载指数由低到高分别将写入副本写入到对应节点,首先采用这样的分发写入策略,避免了数据写入的单点压力,提高了写入性能,
2、当接收到数据分片的查询请求时,按照查询负载指数由低到高到相应节点获取查询结果,动态调度用户的查询请求,有效保障了查询的响应时延,即较短的查询响应时长,确保了查询的响应时间保持平稳,有效提升了系统查询性能,例如:1秒内返回结果的查询,在10倍或更多并发量查询的情况下,用户的查询性能不降低,依然是1秒内返回结果,系统的查询性能比较稳定,波动很小;
3、又由于按照实际查询需求进行数据分片副本配置以及查询节点的合理配置,有效保障了查询性能的稳定性,同时也提高了存储资源的利用率;
4、根据查询请求的历史数据,按照arima时间序列模型预测未来需要保存的副本数量,动态调整副本的数量,保持用户查询性能的平滑性;
5、由于是多副本存储,整体具有足够高的容错性、可靠性。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
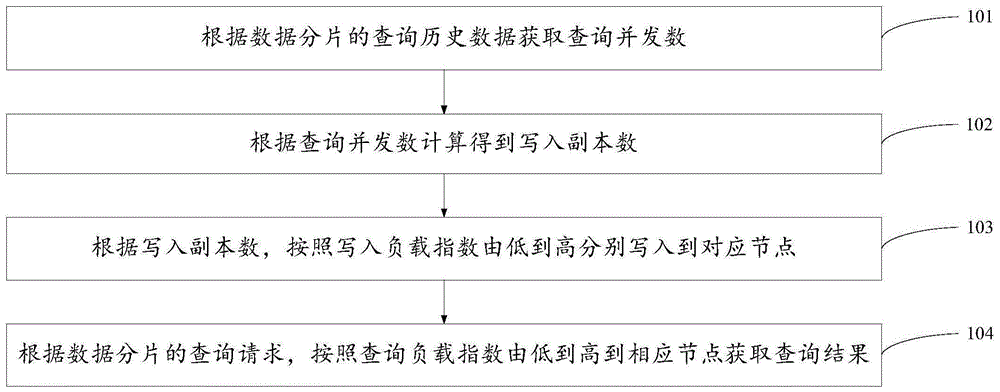
图1是本发明实施例提供的高并发数据查询方法流程图;
图2是本发明实施例提供的高并发数据查询装置结构示意图;
图3是本发明实施例提供的高并发数据查询系统结构示意图;
图4是一优选实施例提供的写入副本的副本写入流程图;
图5是一优选实施例提供的副本数量计算及副本写入过程的演示图;
图6是一优选实施例提供的数据查询请求过程的演示图;
图7是一优选实施例提供的副本动态调整过程的演示图;
图8是本发明实施例提供的高并发数据查询设备结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是两个以上,除非另有明确具体的限定。
本发明实施例提供的高并发数据查询方法、装置、系统、设备及计算机可读存储介质,根据数据分片的查询历史数据获取查询并发数,再根据所述查询并发数计算得到写入副本数,能够根据数据分片的一般查询需求获知所需写入副本数量,然后按照写入负载指数由低到高分别将写入副本写入到对应节点,这里的查询历史数据优选地采用qps平均值统计数据。首先采用这样的分发写入策略,避免了数据写入的单点压力,提高了写入性能,并且,当接收到数据分片的查询请求时,按照查询负载指数由低到高到相应节点获取查询结果,既保障了较短的查询响应时长,确保了查询的响应时间保持平稳,有效提升了系统查询性能,又由于按照实际查询需求进行数据分片副本配置以及查询节点的合理配置,有效保障了查询性能的稳定性,同时也提高了存储资源的利用率,并且整体具有足够高的容错性、可靠性。因此,本发明实施例提供的高并发数据查询方案,可以广泛应用于涉及高并发数据查询的多种大数据应用场景。
下面结合具体实施例及附图,对本发明实施例提供的高并发数据查询方法、装置、系统、设备及可读存储介质作详细说明。
图1是本发明实施例提供的高并发数据查询方法流程图,如图1所示,本发明实施例提供的高并发数据查询方法,包括以下步骤:
101、根据数据分片的查询历史数据获取查询并发数。
具体的,通过数据分片的查询历史数据计算得到用户查询数据分片的查询并发数。
值得注意的是,步骤101根据数据分片的查询历史数据获取查询并发数的过程,除了上述步骤所述的方式之外,还可以通过其他方式实现该过程,本发明实施例对具体的方式不加以限定。
102、根据查询并发数计算得到写入副本数。
具体的,根据查询并发数以及每个副本支持并发数计算得到写入副本数,可以通过以下公式计算得到:
查询并发数/每副本支持并发数=副本数
根据查询并发数计算出需要保存的副本数,副本数量代表支持的并发数,根据业务需求,不同数据集可以支持不同的并发数,避免了存储资源的浪费,通过增加机器(即节点),每台机器上保存相同的副本,可以线性提升系统所能支持的查询并发数。
值得注意的是,步骤102根据查询并发数计算得到写入副本数的过程,除了上述步骤所述的方式之外,还可以通过其他方式实现该过程,本发明实施例对具体的方式不加以限定。
103、根据写入副本数,按照写入负载指数由低到高分别写入到对应节点;
具体的,根据每个节点当前的io利用率、cpu利用率以及第一预设权重规则计算得到所有节点的写入负载指数,然后按照写入负载指数由低到高将写入副本数的副本分别写入到对应节点。这里的,第一预设权重规则是指io利用率与cpu利用率在计算写入负载指数时的权重分布,例如io利用率权重:cpu利用率权重为2:8,io利用率权重+cpu利用率权重=1,等等,可以根据实际情况需要进行相应设置。写入负载指数可以通过以下公式计算得到:
写入负载指数=io利用率*io利用率权重+cpu利用率*cpu利用率权重
将数据分片加载到具有写入副本数量的节点中,形成数据分片的写入副本数个副本,每个副本在每个节点的内容是相同的。
值得注意的是,步骤103根据写入副本数,按照写入负载指数由低到高分别写入到对应节点的过程,除了上述步骤所述的方式之外,还可以通过其他方式实现该过程,本发明实施例对具体的方式不加以限定。
104、根据数据分片的查询请求,按照查询负载指数由低到高到相应节点获取查询结果。
具体的,根据每个节点当前的io利用率、cpu利用率、网络负荷利用率以及第二预设权重规则计算得到所有节点的查询负载指数。然后按照查询负载指数由低到高将写入副本数的副本分别写入到对应节点。这里的,第二预设权重规则是指io利用率、cpu利用率与网络负荷利用率在计算写入负载指数时的权重分布,例如io利用率权重:cpu利用率权重:网络负荷利用率权重为4:4:2,io利用率权重+cpu利用率权重+网络负荷利用率权重=1,等等,可以根据实际情况需要进行相应设置。写入负载指数可以通过以下公式计算得到:
查询负载指数=io利用率*io利用率权重+cpu利用率*cpu利用率权重+网络负荷利用率*网络负荷利用率权重
从以上的查询流程中看出,当某一节点在处理查询请求时,其他的节点没有增加负载,可以接收其他的查询请求,有效的提升了系统查询性能,确保了查询的响应时间保持平稳。
值得注意的是,步骤104根据数据分片的查询请求,按照查询负载指数由低到高到相应节点获取查询结果的过程,除了上述步骤所述的方式之外,还可以通过其他方式实现该过程,本发明实施例对具体的方式不加以限定。
可选的,上述高并发数据查询方法还包括副本动态调整步骤:
根据数据分片的查询历史数据,利用arima时间序列模型预测未来需要增加的增加副本数,根据增加副本数进行副本动态调整,以保持用户查询性能的平滑性。
值得注意的是,副本动态调整步骤的过程,除了上述步骤所述的方式之外,还可以通过其他方式实现该过程,本发明实施例对具体的方式不加以限定。
图2是本发明实施例提供的高并发数据查询装置结构示意图。如图2所示,本发明实施例提供的高并发数据查询装置2包括查询并发数获取模块21、写入副本数计算模块22、副本写入模块23及查询结果获取模块24。
其中,查询并发数获取模块21,用于根据数据分片的查询历史数据获取查询并发数。
写入副本数计算模块22,用于根据查询并发数计算得到写入副本数。具体的,写入副本数计算模块22用于:根据查询并发数以及每个副本支持并发数计算得到写入副本数。
副本写入模块23,用于根据写入副本数,按照写入负载指数由低到高分别写入到对应节点。具体的,副本写入模块23包括第一计算子模块231,第一计算子模块231用于:根据每个节点当前的io利用率、cpu利用率以及第一预设权重规则计算得到所有节点的写入负载指数。
查询结果获取模块24,用于根据数据分片的查询请求,按照查询负载指数由低到高到相应节点获取查询结果。具体的,查询结果获取模块24包括第二计算子模块241,第二计算子模块241用于:根据每个节点当前的io利用率、cpu利用率、网络负荷利用率以及第二预设权重规则计算得到所有节点的查询负载指数。
可选的,上述高并发数据查询装置还包括副本动态调整模块25,具体用于:根据数据分片的查询历史数据,利用arima时间序列模型预测未来需要增加的增加副本数,根据增加副本数进行副本动态调整。
图3是本发明实施例提供的高并发数据查询系统结构示意图,如图3所示,本发明实施例提供的高并发数据查询系统包括数据副本管理器31、数据加载器32、查询负载均衡器33以及多个节点,其中,数据副本管理器31用于:根据数据分片的查询历史数据获取查询并发数,并根据查询并发数计算得到写入副本数;数据加载器32,用于根据写入副本数,按照写入负载指数由低到高分别写入到对应节点;查询负载均衡器33,用于根据数据分片的查询请求,按照查询负载指数由低到高到相应节点获取查询结果。
可选的,数据副本管理器31还用于:根据数据分片的查询历史数据,利用arima时间序列模型预测未来需要增加的增加副本数,根据增加副本数进行副本动态调整。
可选的,查询负载均衡器33将查询结果返回给用户,如果查询涉及多个数据分片,则进行一些数据分片合并的操作,合并完成后再将结果返回给用户。
下面结合一优选实施例进一步说明本发明实施例提供的高并发数据查询方法及装置。
图4是该优选实施例提供的写入副本的副本写入流程图。如图4所示,写入副本的副本写入过程,主要包括以下流程:
1、数据副本管理器31根据数据分片a查询的qps平均值统计数据计算出用户查询的并发数,根据并发数计算出写入副本的数量,计算公式如下:
并发查询数/每副本支持并发数=副本数
例如:并发查询数为8,每副本支持的并发数为2,则写入副本的数量为:4。数据加载器32准备将数据分片a写入4个副本。副本数计算公式如下:
8/2=4
2、数据加载器32选择一个负载最低的节点,做为副本写入首个节点。节点的负载情况从io、cpu两个维度的来进行评估,io利用率占的权重为30%,cpu利用率权重为70%。
例如:io利用率为60%,cpu利用率为50%,则该节点的写入负载指数为:
60%*0.3+50%*0.7=53%
3、数据加载器32将数据写入首个节点,如果首个节点由于某些异常情况导致写入失败,则跳回到步骤2,如果写入成功,则进入下一个步骤。
4、首个节点写入完成,首个节点将副本写入到其他三个节点,在写入其他三个节点时,如果写入失败则重试其他的节点。
图5是该优选实施例提供的副本数量计算及副本写入过程的演示图。
如图5所示,以写入4个数据副本a1、a2、a3、a4的示例来说明数据流向,副本数量计算及副本写入过程,主要包括以下流程:
①数据副本管理器31计算出副本数量;
②数据加载器32将数据写入首个节点;
③首个节点再将数据分发到其余的三个节点,其他节点写入成功,则将写入成功的消息发送给首节点,首节点将写入成功的消息再反馈给数据加载器32。
如果有更多的副本需要写入,则由其他三个节点继续分发到其他节点,采用这样的分发副本策略,避免了数据写入的单点压力,提高写入性能。
图6是该优选实施例提供的数据查询请求过程的演示图,如图6所示,数据查询请求过程,主要包括以下流程:
①用户发起查询数据分片a的请求,查询负载均衡器33接收到查询请求。
②查询负载均衡器33根据存储数据分片a的节点负载情况,选择一个当前负载最轻的节点,优先选择当前没有用户查询的节点,如果所有的节点都有用户查询则选择负荷较低的节点,否则提示系统满负荷,稍后重试。例如发现节点3的负载最轻,被选中作为查询节点。节点的负载情况从io、cpu、网络负荷三个维度的来进行评估,io利用率占的权重为30%,cpu利用率权重为50%,网络负荷利用率权重为20%。
例如:io利用率为60%,cpu利用率为50%,网络利用率为40%,则该节点的查询负载指数为:
60%*0.3+50%*0.5+40%*0.2=51%
③节点3按照查询请求检索数据分片a的数据,将检索结果返回给查询负载均衡器33。如果节点3查询数据时出现异常情况,则跳回到步骤②。
④查询负载均衡器33收到查询请求的结果后,响应给用户,查询流程结束。
从以上的查询流程中看出,当节点3在处理查询请求时,其他的节点没有增加负载,可以接收其他的查询请求,有效的提升了系统的并发度,确保了查询的响应时间保持平稳。
图7是该优选实施例提供的副本动态调整过程的演示图,如图7所示,副本动态调整过程,主要包括以下流程:
①数据副本管理器31根据查询qps平均值统计数据,按照arima时间序列模型预测未来查询的趋势,假设计算出未来需要增加一个副本。
②选择当前负荷比较轻的节点,例如选择了节点4,数据副本管理器31通知该节点将数据副本复制到新节点。
③节点4将数据副本复制到新的节点5,在节点5上保存了副本5。
④查询负载均衡器33感知到新加入的副本5,当有新的查询请求时,根据负载调度策略调度到节点5进行查询。
从以上的流程可以看出,可以根据查询的历史趋势,动态的调整副本数量,当查询并发呈现上涨趋势时,增加副本数量,下降趋势时减少副本数量,有效的保障了查询性能的稳定性,同时也提高了存储资源的利用率。
图8是本发明实施例提供的高并发数据查询设备结构示意图,如图8所示,本发明实施例提供的高并发数据查询设备4,包括:
处理器41;
存储器42,用于存储有处理器41的可执行指令;
其中,处理器41配置为经由所述可执行指令来执行上述任一方案所述的高并发数据查询方法的步骤。
另外,本发明实施例还提供了一种计算机可读存储介质,该计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时实现上述任一方案所述的高并发数据查询方法的步骤。
需要说明的是:上述实施例提供的高并发数据查询装置、高并发数据查询装置在高并发数据查询业务时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将装置、设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的高并发数据查询方法、高并发数据查询装置、高并发数据查询设备以及计算机可读存储介质的实施例均属于同一构思,不必赘述。
上述所有可选技术方案,可以采用任意结合形成本发明的可选实施例,在此不再一一赘述。
综上所述,本发明实施例提供的高并发数据查询方法、装置、系统、设备及计算机可读存储介质,相比现有技术具有以下有益效果:
1、根据数据分片的查询历史数据获取查询并发数,再根据所述查询并发数计算得到写入副本数,能够根据数据分片的一般查询需求获知所需写入副本数量,然后按照写入负载指数由低到高分别将写入副本写入到对应节点,首先采用这样的分发写入策略,避免了数据写入的单点压力,提高了写入性能,
2、当接收到数据分片的查询请求时,按照查询负载指数由低到高到相应节点获取查询结果,动态调度用户的查询请求,有效保障了查询的响应时延,即较短的查询响应时长,确保了查询的响应时间保持平稳,有效提升了系统查询性能,例如:1秒内返回结果的查询,在10倍或更多并发量查询的情况下,用户的查询性能不降低,依然是1秒内返回结果,系统的查询性能比较稳定,波动很小;
3、又由于按照实际查询需求进行数据分片副本配置以及查询节点的合理配置,有效保障了查询性能的稳定性,同时也提高了存储资源的利用率;
4、根据查询请求的历史数据,按照arima时间序列模型预测未来需要保存的副本数量,动态调整副本的数量,保持用户查询性能的平滑性;
5、由于是多副本存储,整体具有足够高的容错性、可靠性。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
本申请实施例中是参照根据本申请实施例中实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本申请实施例中的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本申请实施例中范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
本说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!