一种面向微博的突发事件触发词识别方法与流程
本发明涉及一种自然语言的识别方法,尤其涉及一种面向微博的突发事件触发词识别方法。
背景技术:
当前,我国正处于经济快速发展期,各类突发事件时有发生,这些突发事件具有很强的新闻性和敏感性。对突发事件触发词进行抽取,旨在为进一步分析事件发展趋势,研究事件舆情动态提供技术支撑。
目前突发事件触发词识别方法,已经取得了很多成果,其研究大致分成如下两大类:基于模式匹配的方法和基于机器学习的方法。
传统基于模式匹配触发词识别方法是以人工构建模式匹配规则为基础,对事件进行规则抽取,在文本数据串中寻求一个模式串的匹配结果,是数据检索的核心。李培峰等采用基于核心论元和辅助论元的规则构建方法进行了触发词的识别实验;孟环建等采用基于依存句法的规则匹配方法进行了事件识别实验。基于模式匹配的方法触发词识别中人工工作量大、效率和识别率偏低,难以满足实践工作需要。
基于机器学习的方法通常将词向量作为输入特征进行模型训练,并进行触发词的识别,模型训练中又有单一模型和融合模型识别。
(1)基于单一模型的方法中,王红斌等采用神经网络作为分类器,将词向量作为神经网络的输入对事件句的语义进行分类,并在中文突发事件语料库(chineseemergencycorpus,cec)语料库进行实验,取得较好结果;yubochen等使用动态多池卷积神经网络对句子中的每个单词进行分类从而识别触发词,并在ace(automaticcontentextraction)语料库中进行了实验,实验结果较好。基于单一模型的方法中,虽然事件触发词识别模型训练快捷,识别率较传统有所提高,但是建立准确的模型需要大量进行实验和学习,学习周期长,实验效果并不是很理想。同时,该方法更多的关注于词语本身,而忽略整篇文章的整体语义信息与篇章结构信息。
(2)基于融合模型的方法中,苏晓丹等采用了一种将规则与二值分类相结合的混合模型方法,并在人民日报的1998年全语料中随机抽取500篇文本进行实验;陈亚东等将高置信度词典的特征分别加入到最大熵和条件随机场模型当中,融合两个模型进行触发词的识别,并在kbp2015英文语料库中进行实验,实验结果相比于me最大熵模型识别效果较好。基于融合模型的方法中,触发词识别模型训练高效,同时避免了大量人工工作,提高了触发词识别效率。
为弥补传统基于模式匹配触发词识别中效率低和基于单一模型识别方法中识别率低等不足,本发明提出了一种新的基于融合模型的面向微博的突发事件触发词识别方法。
技术实现要素:
本方法避免了传统模式识别中效率偏低的缺点,同时遵循了机器学习中模型训练快速简单的优点。两者兼顾,取长补短,提出一种基于p-multi模型的微博触发词识别方法,将待分析的微博数据构成预料库的预料,其特征在于所述方法包括如下步骤:
1)对突发事件语料库进行原始触发词统计,记录统计特征;
2)对所述语料进行分词、分句等数据预处理,对所述分句后的语料数据按照分句进行依存句法分析,整理凝练出词对间依存关系,建立模式匹配规则;
3)对所述预处理后的文本数据逐一进行模式规则匹配和潜在语义分析,进一步抽取分句语义信息,选取同时满足二者条件的词作为候选触发词,得到候选触发词集;
4)计算所述候选触发词集与基于扩展触发词表的触发词识别出触发词进行相似度分析,将满足相似度要求的触发词确定为微博突发事件触发词。
本发明提出的所述的方法,其特征在于所述步骤1)中原始触发词统计包括事件类型、事件数量、触发词和触发词数量。
本发明提出的所述的方法,其特征在于所述步骤2)中根据词对建依存关系,建立模式匹配规则,得到触发词词对。
本发明提出的所述的方法,其特征在于所述步骤3)中根据潜在语义分析得到所述候选触发词集的步骤如下:
a.使用词袋模型对文本进行向量化,其中文本为微博数据;
b.将所有的词向量拼接起来构成词-文本矩阵,并进行奇异值分解svd操作;
c.根据svd结果将词-文本矩阵映射到一个低维度的语义空间中,以此表达svd结果;
d.每个词和文本都表示为低维度空间中的一个点,通过kl(kullback-leiblerdivergence)相似度计算,选取相似度较高的词作为候选词,加入到候选触发词集中。
本发明提出的所述的方法,其特征在于所述步骤4)中所述的基于扩展触发词表的触发词识别方法,包括如下步骤:首先,对文本数据进行数据预处理,包括分词、词性标注和分句等步骤;其次,预处理后从文本中筛选出触发词词性,缩小候选触发词集范围;最后,计算并选取触发词权重比较高的词作为事件触发词;其中,采用词频-逆文档频次算法来计词权重,计算公式如下:
scorei=tf(wi)×idf(wi)
其中wi为候选触发词,ni为候选触发词wi在语料库中触发的事件总数,mi为训练语料中该类事件总数,ni为训练语料中事件总数,mi为含有触发词wi为的事件总数,scorei代表触发词的权重,tf为词频,它反映触发词对整个事件的贡献程度;idf为逆文本频率指数,它过滤掉常见的词语,将权重较大的候选触发词作为突发事件触发词。
本发明提出的方法,借鉴融合模型的方式提出基于p-multi模型的触发词识别,并在特征选取中考虑文本语义信息,对微博突发事件进行触发词识别,具有效率高和识别率高的优点。
附图说明
为了更清楚的说明本发明实施例的技术方案,下面将对本发明的实施例中所需要使用的附图作简单地介绍。
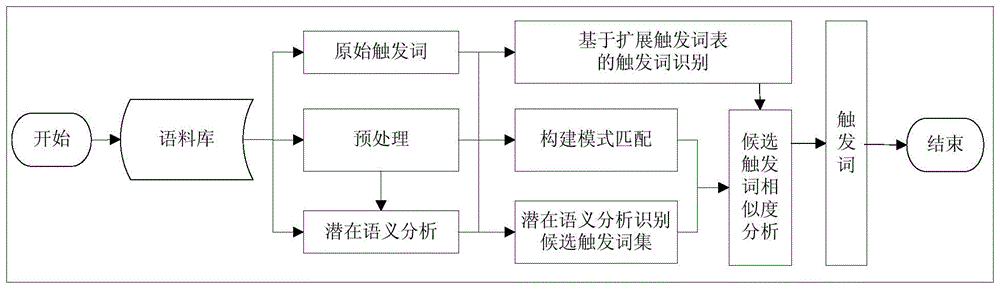
图1是本发明提出的基于p-multi模型触发词识别流程图。
图2是本发明示例的依存句法分析结果。
图3是本发明实验中语义维度权重-准确率关系图。
图4是本发明实验中语义维度权重-召回率关系图。
图5是本发明实验中相似度权重-准确率影响图。
图6是本发明实验中相似度权重-召回率影响图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。
本发明提出的基于p-multi模型触发词识别流程图如图1所示,在扩展触发词表的触发词识别基础上,构建触发词模式匹配规则,分析文本中潜在语义,确定候选触发词集,将候选触发词和扩展触发词表识别的触发词进行相似度分析,进而完成对微博突发事件中触发词的识别。
对照图1,本发明基于p-multi模型的触发词识别,其主要包括以下四个步骤:
1)对突发事件语料库进行原始触发词统计,记录统计特征;
2)对所述语料进行分词、分句等数据预处理,对所述分句后的语料数据按照分句进行依存句法分析,整理凝练出词对间依存关系,建立模式匹配规则;
3)对所述预处理后的文本数据逐一进行模式规则匹配和潜在语义分析,进一步抽取分句语义信息,选取同时满足二者条件的词作为候选触发词,得到候选触发词集;
4)计算所述候选触发词集与基于扩展触发词表的触发词识别出触发词进行相似度分析,将满足相似度要求的触发词确定为微博突发事件触发词。
下面将对上述步骤中的重点步骤进行详细说明。
1.触发词统计
本发明中数据主要来源于微博和cec语料库,并沿用对中文事件和事件要素标注较全面的cec语料库构建原始触发词表。通过统计学习对cec语料库进行统计研究,并整理出语料中出现频率较高五类事件及各类事件的触发词,将此触发词作为原始触发词,同时对数据进行预处理,进行数据清洗,剔除无效数据。
通过统计学习对cec语料库进行统计研究,并整理出语料中出现频率较高五类事件(地震、交通事故、恐怖袭击、食物中毒、火灾)及各类事件的触发词,原始触发词统计结果如表1所示(以地震事件为例):
表1原始触发词统计表
记录统计特征,包括事件类型、事件数量、触发词和触发词数量,分别语义记录。
2.模型结构
2.1基于扩展触发词表的触发词识别
上述方法的第4)中,计算候选触发词集与基于扩展触发词表的触发词识别出触发词进行相似度分析,确定突发事件触发词。在进行相似度分析之前,首先需要确定基于扩展触发词表的触发词识别出触发词,基于扩展触发词表的触发词识别方法如下。
2.1.1扩展原始触发词表
语料库中去除停用词后采用统计学习计算出高频词,以此构建出原始触发词表,进而采用同义词林扩展技术在语料库中进行扩展,得到扩展触发词表。
本发明中针对原始触发词结合人工检查并采用哈工大同义词林对原始触发词表进行扩展,扩展规则如下:
从原始触发词表中提取事件类型主题词,对其进行同义词林扩展,得到其相对应的词汇集。
为避免原始触发词过度扩展,筛选词语编码的前三级词语,筛选后的词语表达意义相似,符合原始触发词扩展。
最后进行人工筛选,选择事件触发词,得到扩展后的事件触发词表。
例如在原始触发词统计表中的“地震”事件,我们提取出地震相关触发词,包括地震、震感、余震等7个原始触发词进行扩展,本发明中采用哈工大同义词林扩展原始触发词表,例如“余震”该词扩展后的结果为:余震:1.0、地震:0.7676294、震级:0.729728、主震:0.70171624、黎克:0.67222035、震央:0.65997815、震中:0.60635084、风灾:0.5619928、震后:0.53781664、山崩:0.51335514,避免原始触发词过度扩展,人工筛选词语编码的前三级,即选取地震、震级和主震添加入原词触发词,以此构建原始触发词扩展表。
2.1.2基于扩展触发词表的触发词识别方法
基于扩展触发词表的触发词识别方法,包括如下步骤:首先,对文本数据进行数据预处理,使用结巴分词工具,包括分词、词性标注和分句等步骤;其次,预处理后从文本中筛选出触发词词性,缩小候选触发词集范围;最后,计算并选取触发词权重比较高的词作为事件触发词。
词语是表达文本处理的最基本单元,因此,基于word2vec技术生成词向量,采用词频-逆文档频次算法来计词权重,计算公式如下:
scorei=tf(wi)×idf(wi)
其中wi为候选触发词,ni为候选触发词wi在语料库中触发的事件总数,mi为训练语料中该类事件总数,ni为训练语料中事件总数,mi为含有触发词wi为的事件总数,scorei代表触发词的权重,tf为词频,它反映触发词对整个事件的贡献程度;idf为逆文本频率指数,它过滤掉常见的词语,将权重较大的候选触发词作为突发事件触发词。
例如,针对文本数据“甘肃岷县发生余震,地震发生后,武警国家级救援队陇原方舟救援队接到命令后,迅速集结120名专业救援力量,从兰州赶赴地震灾区。”数据预处理为:“甘肃岷县发生余震\地震发生后\武警国家级救援队陇原方舟救援队接到命令后\迅速集结120名专业救援力量\从兰州赶赴地震灾区”,其中根据原始触发词表可知:余震事件:n(余震)=8,w余震=62,根据预处理结果分析可知:n余震=3,m余震=1,因此按照公式可知:
基于扩展触发词表的触发词识别方法基于词向量模型,仅考虑数据统计特征信息,忽略了词句之间的语义信息,触发词识别率偏低。基于此,为进一步提升触发词识别正确率和召回率,改变触发词识别率偏低的弊端,本发明提出一种新模型——p-multi模型,该模型对基于扩展触发词表的触发词识别方法进行补充,在选取特征时不仅包含了一般统计特征信息,还包含了语义特征信息,进一步提升了触发词识别准确度。
2.2构建模式匹配
句子的构成单元是词,本发明中利用哈尔滨工业大学的语言云平台对语料库进行依存句法分析后发现触发词是满足一定的句法关系,且这些句法关系是有规律可循,并非杂乱无章。因此,本发明首先根据哈尔滨工业大学的语言云平台依存句法分析结果,总结出以下6种主要依存关系,如表2所示:
表2主要依存句法关系表
上述表2中,各缩写词如hed、att、cmp等含义采用的是哈尔滨工业大学的语言云平台关系类型描述,其具体含义如表3所示:
表3语言云平台关系类型描述表
根据上面分析,利用词对间依存关系,本发明中制定了如下抽取规则:
规则1:当句中存在att关系类型,候选触发词可能处于谓语位置,那么识别<att的核心词>。
规则2:当句中存在cmp关系类型,候选触发词可能处于动补结构中,那么识别<cmp的核心词>。
规则3:当句中存在sbv关系类型,候选触发词可能处于主语、谓语位置,那么识别<sbv的修饰词,sbv的核心词>。
规则4:当句中存在vob关系类型,候选触发词可能为sbv的核心词和vob的核心词,那么识别<vob的核心词>。
规则5:当句中存在fob关系类型,候选触发词可能为fob的核心词和adv的核心词,那么识别<fob的核心词>。
规则6:当句中存在adv关系类型,候选触发词可能处于状中结构中,那么识别<adv的核心词>。
对语料信息进行分析和总结,人工归纳出现频次较多的触发词词对。
例如:针对文本数据“重庆市区有明显震感电线杆在摇晃”按照表2进行依存句法分析,分析后的结果如图2所示。
从图2所示的句法分析中,我们可以分析出触发词“震感”有关联的是“明显”,并用(明显,a,震感,n,att)对其进行描述,其中“关系类型”、“标签”、“关系描述”说明借鉴于平台“词性标注集”中描述,触发词词对描述如下表4所示:
表4触发词词对描述表
根据上述主要依存关系,对语料库进行训练,按照抽取规则初步模式匹配出触发词词对。
触发词词对的获得是为下一步潜在语义分析识别候选触发词集做准备,其能使潜在语义分析识别更加聚焦在识别的触发词词对上,减少潜在语义分析识别的迭代次数,提高潜在语义分析识别的效率。
2.3.潜在语义分析识别候选触发词集
lsa(latentsemanticanalysis,潜在语义分析)是提取文本语义上的实现方法,本发明中的lsa通过奇异值分解将词-文本映射到低维度的语义空间,挖掘出词、文本的潜在语义信息,从而更好的提取文本语义信息,提高了文本分析质量。
lsa主要步骤包括以下四个步骤:
使用词袋模型对文本进行向量化,其中输入数据为文本数据,也即微博数据;
将所有的词向量拼接起来构成词-文本矩阵,并进行svd(奇异值分解)操作;
根据svd结果将词-文本矩阵映射到一个低维度的语义空间中,以此近似表达svd结果;
每个词和文本都可以表示为低维度空间中的一个点,通过kl(“kullback-leiblerdivergence”,相对熵)相似度计算,选取相似度较高的词作为候选词,加入到候选触发词集中。
lsa具体算法思路描述如下:
输入:语料库文本,停用词表,文本句子,模式匹配中触发词词性。
输出:句子中的候选触发词。
具体过程为将语料库文本进行分句和分词处理,并过滤掉停用词,同时标记“模式匹配中触发词词性”,通过分析语料库,建立文本term-document矩阵,对term-document矩阵进行奇异值分解,对矩阵进行降维操作,构建潜在语义空间,其中奇异值k为降维后矩阵相似度,对应“语义”相似度(“奇异值k”需要先验知识,人工设定,目的是对词语见的语义相似度进行衡量,例如:k=1时,两次可能互为反义词,而k=0时,即为词语本身);分句中逐一查找每个实体描述词,迭代匹配候选触发词集,如果该词满足词性与原始触发词词性一致,不属于停用词,不是时间描述数字和该词与候选触发词之间的欧式距离小于奇异值k(语义维度权重),就认为该词相似度较高,将该词添加入潜在语义分析识别出的候选触发词,构建潜在语义分析识别候选触发词集。
lsa具体算法流程如下:
输入:语料库文本,停用词表s,文本句子,模式匹配中触发词词性p。
输出:句子中的候选触发词e
首先,初始化e=[];
分析语料库,建立term-document矩阵;
对term-document矩阵进行奇异值分解,奇异值k对应的是“语义”维度的权重;
for句子中的第j个实体描述ej
for句子中的第i个候选触发词wi
if
andthen
将ej添加到候选触发词e中;
endfor
endfor
例如:针对文本数据“重庆市区有明显震感电线杆在摇晃”进行依存句法分析后的结果为:在模式匹配阶段,在句子“重庆市区有[明显震感]电线杆在摇晃”会根据规则匹配识别出触发词词对“[明显震感]”,而对该句进行语义分析之中,具体算法流程示例如下:
1.初始化候选触发词集e=[]
2.建立文本term-document矩阵:
3.对term-document矩阵进行奇异值分解,方便进行降维处理,其文本term-document矩阵c(其秩为r)和正整数k,其秩不大于k。其思想是将n维特征映射到k维上(k<n),通常情况下,该方法会计算数据协方差矩阵∑的特征向量λ,我们通常会考虑降维过程中数据保留方差百分比,其计算公式为:
其中,k为数据保留方差百分比,λ_j为协方差矩阵的第j个特征值,为此,本发明中用其表示语义相似信息。当k远小于r时,矩阵低阶近似,语义信息保存较为完整。因为需要先验知识的假定,因此本发明中取值k=0.5较为合适;
4.针对文本数据“重庆市区1有2[明显3震感4]电线杆5在6摇晃7”,进行停用词过滤后为:“重庆市区1[明显2震感3]电线杆4摇晃5”对第一个实体“重庆市区”进行和触发词集进行匹配,由于触发词集是:地震事件={地震(n/v),震感(n),余震(n),震源(n),震区(n),震中(n),震带(n)};接下来对实体“重庆市区”进行判定,解释如下:
(1.1)由于“明显(n)”∈p(n/v);
(1.2)
(1.3)“明显(n)”不属于数值及时间描述;
(1.4)距离计算:“明显(n)”-“地震”=0.2280小于0.5(k),不添加至候选触发词中;开始下一个实体词比对,迭代:
(2.1)由于“震感(n)”∈p(n/v);
(2.2)
(2.3)“震感(n)”不属于数值及时间描述;
(2.3)距离计算:“震感”-“地震”=0.7118大于0.5(k),添加至候选触发词中,迭代执行上述过程。
在潜在语义分析识别触发词中,候选触发词满足模式匹配规则识别出的触发词词对要求的同时,还要满足一定的相似度要求,这样才能添加至候选触发词中,此种技巧的目的是缩小候选触发词范围,进一步提升事件触发词识别准确率。
2.4候选触发词相似度分析
在结合模式匹配和潜在语义分析基础上得到基于多值(p-multi)确定的候选触发词集,为进一步提升触发词识别准确率,将该候选触发词集与基于扩展触发词表识别出的触发词进行相似度分析,本发明中基于哈工大同义词词林扩展版计算词语相似度,选取相似度较高的候选触发词作为事件触发词。
例如:上述示例句:“重庆市区有明显震感电线杆在摇晃中”,“震感”一词被基于扩展触发词表的触发词识别出,同时也被潜在语义分析识别出,经过触发词相似度计算:“震感”-“震感”之间相似度为:1.0,因此视为基于p-multi模型触发词识别确定为事件触发词;但是如果例句中出现“震落”等相似词,基于扩展触发词表的触发词识别没有识别出该词,但是被潜在语义分析识别出,经过候选触发词的相似度计算:“震感”-“震落”之间相似度为:0.3381,因此视为基于p-multi模型触发词识别不能确定为事件触发词。
3.发明的效果
3.1实验数据
本发明实验阶段所采用文本数据主要来源于微博,其中模型训练阶段实验数据选用中文突发事件语料库进行训练,突发事件语料库的分类体系,包括三个层次:
一级包括5个大类;
二级包括33个子类;
三级包括94个小类。
标注的中文突发事件语料库主要包括地震、交通事故、恐怖袭击、食物中毒和火灾5个类别,总共332篇。
文本数据主要来源于微博和cec语料库。通过数据爬取,剔除无效数据,保留了14257条微博文本数据作为测试集。
文本数据预处理包括中文分词、词性标注和文本数据等描述的回填等步骤,同时,本发明中对微博数据进行人工标注,用于校对模型抽取结果。实验基于python软件实现,python开发效率高且编程容易,其被称之为“胶水语言”,为顺利进行实验验证提供了可能。
模型评价标准采用通用的评价指标:准确率(precision)、召回率(recall)以及两者结合计算得到的f值(f1-measure)对事件触发词识别性能进行评价。具体定义如下:
correct:如果模型识别为触发词与人工标注为触发词相同;
incorrect:如果模型识别为触发词与人工标注为触发词不同;
missing:如果人工标注为触发词,但模型未识别;
spurious:如果模型识别为触发词,但人工未标注;
通过使用以下参数评价模型性能:
本发明中对语料库进行数据预处理并统计分析,多次训练语料库使模型趋于稳定,而后针对人工标注的微博数据进行测试,通过实验结果衡量和评估模型性能。
3.2语义维度权重对实验结果影响
实验中在触发词识别中涉及到的语义维度权重k,需要设置阈值提取文本语义信息,参数设置对实验结果具有一定影响,模型中语义维度权重因子对实验结果影响如图2,图3所示。
从图中分析可知,当设置语义维度权重较大时,触发词识别准确率呈现上升趋势;相反,触发词识别召回率却呈现下降趋势。由此可见,触发词识别中考虑语义信息多时,对触发词精准识别具有明显提升。
3.3相似度权重对实验结果影响
但是在事件触发词识别中,仅仅考虑识别准确率是不够的,还应考虑召回率,模型训练中涉及到触发词相似度权重因子对实验结果同样具有一定影响,相似度权重因子对实验结果影响如图4,图5所示。
进一步分析可知,当相似度权重较大时,触发词识别准确率呈现下降趋,触发词识别召回率呈现上升趋势。当相似度权重接近于1时,基于融合模型方法接近于基于模式匹配方法。
3.4模型评价
本发明进行多次实验,进一步衡量模型优劣,实验结果取值多次实验结果平均值,实验结果如表5所示:
表5模型衡量指标表
通过实验结果可以看出,基于p-multi模型在触发词检测阶段p值(p值为总体模型提高的p值,具体计算方式为:(p(地震)+p(交通事故)+p(恐怖袭击)+p(食物中毒)+p(火灾)),两模型总体p值之差即为实验模型提高的p值)提高了0.24,r值提高了0.35,f值提高了0.28;基于p-multi模型的触发词识别较基于传统扩展触发词表的触发词识别在触发词识别阶段准确率、召回率和f值均有所提升。通过实验可知,基于p-multi模型的触发词识别衡量指标较基于传统扩展触发词表的触发词识别得到了有效提升,证明了本发明触发词识别方法的有效性。
- 还没有人留言评论。精彩留言会获得点赞!