一种共享式的AI科学仪器数据分析处理系统及方法与流程
本发明属于分析化学、生物学、统计计算、计算机科学等多学科交叉领域,具体来说,涉及一种共享式的ai科学仪器数据分析处理系统及方法。
背景技术:
目前,科学分析仪器的发展,为化学、生物等科学研究领域带来新的研究方向,也出现了将ai智能算法应用于该领域的科学研究文献报道。但由于大部分ai智能算法是基于大数据背景下的学习算法,因此对科学样品数据的质量和代表性有很严苛的要求。而科研过程中的数据往往存在着数据量有限,代表性不足等弊端,给科学研究成果转化为实际成果带来了阻碍。
目前尚未存在一个可以为各种科学数据以及分析处理方法提供的共享的平台。
针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现要素:
针对相关技术中的上述技术问题,本发明提出一种共享式的ai科学仪器数据分析处理系统及方法,能够解决现有的科学仪器数据ai分析门槛过高、难度较大、同时由于数据代表性等客观情况的限制,导致相关的科研成果不便于推广、快速转化成果的问题。
为实现上述技术目的,本发明的技术方案是这样实现的:
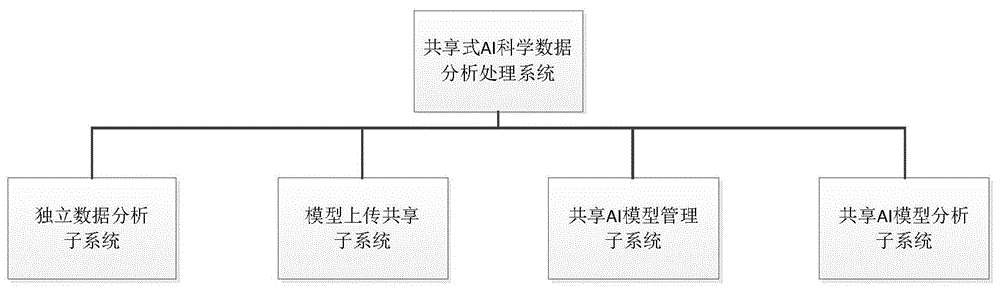
一种共享式的ai科学仪器数据分析处理系统,包括数据分析子系统、模型上传共享子系统、模型管理子系统、模型分析子系统;
所述数据分析子系统用于跨分析仪器平台的大俗据分析和复杂体系质量控制;
所述模型上传共享子系统用于将数据分析子系统建立的模型以及数据上传至云服务器;
所述模型管理子系统用于对上传模型和数据进行管理及处理;
所述模型分析子系统用于调用上传模型对科学仪器检测出来的数据进行分析。
进一步的,所述数据分析子系统包括数据导入模块、数据前处理模块、多元特征分析模块、ai智能分析建模模块。
进一步的,所述数据导入模块支持*.cdf、*.csv、*.txt、*.jdx、*.dx、*.spc、*.spa、*.sp、*.0、*.raw、*.mzxml数据文件格式。
进一步的,所述数据前处理模块针对色谱具有积分、平滑、去背景、保留时间校正功能;
所述数据前处理模块针对光谱具有自动标峰、平均光谱计算、吸光度与透过率转化、nm与cm-1转化、一或二阶求导、平滑功能;
所述数据前处理模块针对质谱具有去背景、平滑、积分、保留时间校正、提取离子峰、解卷积功能。
进一步的,所述多元特征分析模块包括如下算法:聚类分析、方差分析、主成分分析、偏最小二乘得分分析、正交偏最小二乘得分分析。
进一步的,所述ai智能分析建模模块包扩ai定量建模和ai模式识别两部分,所述ai定量建模包括偏最小二乘回归算法,所述ai模式识别建模包括k最近邻法、偏最小二乘判别、正交偏最小二乘判别、支持向量机。
进一步的,所述模型上传共享子系统除了具备模型及数据上传功能,同时具备完善的实验信息管理功能,包括账户登录、权限管理、程序完整性校验、系统日期校验、用户证书请求管理、数据完整性校验、数据电子签名及验证、操作日志。
进一步的,所述模型管理子系统的使用者为拥有最高权限的系统管理员。
进一步的,所述模型分析子系统提供有分析结果数据接口,供使用者付费调用。
一种共享式的ai科学仪器数据分析处理方法,应用于前述中共享式的ai科学仪器数据分析处理系统。
本发明的有益效果:
(1)本发明通过数据分析子系统对不同种类的科学仪器分析数据文件进行直接读取并利用封装好的ai智能算法对其进行分析,该子系统采用模块化设计,操作界面友好,可视化程度高,降低了科学研究过程中对ai算法使用要求的门槛。使ai算法分析技术大众化,缩短了科研周期,提高了科研成果的产出效率,对该技术推广起到了积极的推动作用。
(2)本发明通过模型上传共享子系统,为每个系统的使用者账户提供模型数据上传服务,子系统具备完善的账户管理体系,为上传者的个人信息以及其数据提供合理的安全保障。
(3)本发明通过模型管理子系统,对上传的模型和数据进行管理以及适当的处理,该系统管理员可以根据上传者的要求对模型和数据进行合理的保护操作,同时将存在共性的数据进行合并以及模型优化,保证模型的稳定性,提高模型样品数据的代表性,扩大模型的使用范围。解决了先前由于数据片面性造成的模型使用范围狭窄的弊端。
(4)本发明通过模型分析子系统,为使用者提供了调用上传模型对科学仪器检测出来的数据进行分析的功能,使用者可以根据个人需要快速找到适合自己使用的ai模型分析,省去了使用者ai建模工作过程,有效提高工作效率。同时模型采用有偿方式使用,为模型提供上传者和系统管理者以及系统的日常运营提供了资金保障,有效提高上传者、管理者的积极性。
(5)本发明是一个整体综合系统,提供了完善的和外部通讯的软件数据接口,同时也为科学仪器供应商提供了完善的后备支持,保证供应商也可通过简单的通讯方式对系统的分析结果进行调用,提高二次开发效率,为科学仪器的销售提供了技术支持。
综上所述,本发明将ai分析方法开发为一套独立的数据处理系统,同时搭建了与之配套的ai模型以及数据共享平台。科研工作者可以利用系统对自己拥有的数据进行相应的ai学习并建立ai模型。将ai模型以及数据上传至共享平台,并与平台中已有的与自己研究方向相近的数据进行融合处理,对已有的样品数据集进行补充,提高当前数据的代表性,在平台上建立更完善的ai模型。同时ai模型使用者可以借助平台找到适合使用ai模型,进行使用,为实际生产提供指导。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是根据本发明实施例所述的一种共享式的ai科学仪器数据分析处理系统的框架图。
图2是根据本发明实施例所述的独立数据分析子系统框架及功能使用流程图。
图3是根据本发明实施例所述的模型上传共享子系统框架及功能使用流程图。
图4是根据本发明实施例所述的模型管理子系统框架及功能使用流程图。
图5是根据本发明实施例所述的模型分析子系统框架及功能使用流程图。
图6是根据本发明实施例所述的主成分分析(pca)算法流程图。
图7是根据本发明实施例所述的偏最小二乘(pls)算法流程图。
图8是根据本发明实施例所述的聚类分析算法流程图。
图9是根据本发明实施例所述的k最近邻算法流程图。
图10是根据本发明实施例所述的支持向量机(svm)算法流程图。
图11是根据本发明实施例所述的特征信息筛选功能流程图。
图12是根据本发明实施例所述的模型处理方法优化功能流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,根据本发明实施例所述的一种共享式的ai科学仪器数据分析处理系统,包括数据分析子系统、模型上传共享子系统、模型管理子系统以及模型分析子系统等四个子系统。
如图2所示,在本优选实施例中,数据分析子系统是一种跨分析仪器平台的大俗据分析和复杂体系质量控制系统,该子系统又包括:数据导入模块、数据前处理模块、多元特征分析模块、ai智能分析建模模块四个模块。
在本优选实施例中,数据导入模块可以导入包括色谱仪、质谱仪、光谱仪在内的多种类不同厂家的仪器数据,该模块支持多种仪器产生的数据文件格式,如:*.cdf、*.csv、*.txt、*.jdx、*.dx、*.spc、*.spa、*.sp、*.0、*.raw、*.mzxml等。
在本优选实施例中,数据前处理模块针对色谱、光谱、质谱等各种类型分析仪器的数据分别设计开发了适用于各自的独立的前处理方法,当前为色谱开发了:积分、平滑、去背景、保留时间校正等功能;为光谱开发了自动标峰、平均光谱计算、吸光度与透过率转化、nm与cm-1转化、一(二)阶求导、平滑等功能;为质谱开发了去背景、平滑、积分、保留时间校正、提取离子峰、解卷积等功能。
在本优选实施例中,多元特征分析模块是由使用者通过各种数学算法对科学仪器采集得到的高维数据进行处理后人工对数据特征进行观察和处理的模块,包含多种高维数据进行特征提取和降维的算法,如:聚类分析、方差分析、主成分分析、偏最小二乘得分分析、正交偏最小二乘得分分析等。
多元特征分析模块算法部分:
聚类分析,采用无监督的系统聚类方法,判断过程中借助距离或相似度的概念对数据的自然归属状态进行分析判断,系统中分别可以使用:街区距离(公式1),欧氏距离(公式2),马氏距离(公式3),夹角余弦(公式4)以及相关系数(公式5)四种指标用于聚类分析,计算流程可参见图8:聚类分析算法流程图。
dis马氏=(xi-xj)ts-1(xi-xj),s为样本的协方差矩阵公式3
方差分析,是一种经典的统计学分析方法,用于对多组间样品的因素差异进行统计分析的方法,通过这种分析方法可以根据各因素的概率分布状况对于组间差异的显著程度进行评价,同时也可以用于挑选反映组间差异显著的特征因素。该方法只适用于因素个数小于样本总数的情况。
主成分分析,是一种经典的针对高维数据进行降维处理的方法,该方法以追求样本数据的方差最大化为目的,通过线性投影的方式将高维数据进行投影降维处理,该方法也是一种无监督式的降维算法。计算时算法需对样本数据矩阵进行奇异值分解处理,将样本矩阵分解为三个矩阵(usv)相乘的形式,如公式6所示,其中u和v为两个正交矩阵,s为一个斜对角矩阵。u与s的乘积作为主成分分析的得分,vt作为主成分的载荷矩阵,如公式7所示。整个运算过程可参见图6:主成分分析(pca)算法流程图。
data=u·s·vt公式6
score=u·s,load=vt公式7
偏最小二乘分析,是一种有监督方式的分析算法,该算法可应用于多元数据特征分析,也可以直接用于定量分析和模式识别运算。算法首先①提取通过科学仪器采集的样本数据矩阵x以及样本的属性矩阵y,y矩阵可以是每个样本的成分含量矩阵,也可以是类别归属矩阵。②利用公式8计算协方差矩阵cov;③对cov矩阵进行奇异值分解,将cov分解为矩阵r、s、c三个矩阵相乘的形式,提取最大奇异值对应的向量和元素r1、s1、c1;④利用公式9计算x对应的投影向量并对其进行归一化处理得到向量t,t也就是x矩阵偏最小二乘的一组得分向量xs;⑤利用公式10计算x和y的载荷xl和yl;⑥根据公式11,利用yl计算y矩阵的得分ys;⑦利用公式12计算x矩阵得分的系数矩阵w;⑧通过上述运算的结果计算协方差矩阵cov的残差,并将残差矩阵作为新的cov矩阵,返回公式③继续根据提取的残差矩阵计算x和y其余的偏最小二乘的得分、载荷以及系数;⑨x的得分xs即为偏最小二乘分析的多元数据特征分析的降维结果,使用者可以根据其分布状况分析当前数据的特征和分布情况;⑩根据公式13利用计算得到的w和yl即可计算出偏最小二乘的系数beta,该系数可用于定量回归或模式识别分析的模型系数。整个运算过程可参见图7:偏最小二乘(pls)算法流程图。
cov=xt·y公式8
ys=y·yl公式11
beta=w*yl'公式13
正交偏最小二乘,是一种基于偏最小二乘改进的有监督分析方法,与偏最小二乘类似,该算法可应用于多元数据特征分析以及模式识别运算,但不用于定量分析计算。算法过程与偏最小二乘过程类似,在⑦获取系数向量w以及x的载荷xl后,对其进行正交化处理,处理方法如公式14所示。使用正交化的系数w,重新计算正交化的xs,ys,xl,yl的过程。
w正交=xl-[wt·xl/wt·w]w公式14
通过上述四种算法对科学仪器采集的数据进行分析,使用者人工根据结果进行初步判断数据质量和分析效果,该过程中使用者可以根据个人需要对样品数据进行筛选。
在本优选实施例中,ai智能分析建模包含ai定量建模和ai模式识别两部分,ai定量建模包括偏最小二乘回归算法,ai模式识别建模包括:k最近邻法(knn),偏最小二乘判别(pls-da),正交偏最小二乘判别(opls-da),支持向量机(svm)等。
ai智能分析建模算法部分:
本系统定量算法采用偏最小二乘算法,其运算过程与多元特征分析模块算法部分的偏最小二乘算法类似。算法运算后返回偏最小二乘系数beta,运算时科学仪器数据直接与系数beta相乘后即可计算出最终结果。系统为定量模型提供了多种质量判断方法,如:相关系数(r2,公式15),误差均方根(rmse,公式16)等。
针对模式识别算法,k最近邻法(knn)是一种直接根据样品的空间分布利用投票法进行种类识别的方法,其流程如图9:k最近邻算法流程图所示。①系统计算出待测样品数据与所有样品的距离d;②对距离d进行排序;③取前k个距离最近的样品作为投票者;④统计出k个样品属于不同类别的个数作为投票依据,票数最多的类别,待测样品即被判断为该类别。
偏最小二乘判别(pls-da)与正交偏最小二乘判别(opls-da)的算法原理与多元特征分析模块算法部分的介绍类似。计算建模时,系统将样品的类别信息归纳整理为一个矩阵数表,将该矩阵作为上述算法中描述的y进行计算。判别式利用系数beta与样品科学仪器数据进行乘法,计算出来的结果越接近类别信息表中的种类数据,则被判别为该类别。
支持向量机(svm)是一种新兴的非线性判别算法,其概念在于在不同种类的样品数据中间规划寻找出一个最优的分割面,将不同类别的样品进行最大限度的区分。其算法计算流程如图10支持向量机(svm)算法流程图所示。
模式识别部分的结果,系统使用准确率作为评价依据,准确率越高说明模型预测效果越好。
在本优选实施例中,数据分析子系统中加入了自动优化的功能,主要可以针对特征变量筛选(如光谱的特征波段,色谱、质谱的特定峰位)以及特殊预处理方法选择设计了两个自动优化功能。特征变量筛选使用移动窗口方式进行选择优化,即优化过程中软件从所有变量中选择部分进行分析计算并对此时的计算结果进行评价,选出结果较好时对应的变量作为筛选出的特征变量,过程如图11:特征信息筛选功能流程图所示。
在本优选实施例中,预处理方法选择功能用于不同数据的所有预处理方法进行所有可能组合,进行建模计算,最佳结果即最为最理想的结果进行选择,整个过程如图12:模型处理方法优化功能流程图所示。
如图3所示,在本优选实施例中,模型上传共享子系统是一种用于将数据分析系统建立的模型以及数据上传至云服务器的系统,该系统除了具备模型及数据上传功能,同时具备完善的实验信息管理功能,可以进行账户登录、权限管理、程序完整性校验、系统日期校验、用户证书请求管理、数据完整性校验、数据电子签名及验证、操作日志等操作。
如图4所示,在本优选实施例中,模型管理子系统是一种用于对上传模型和数据进行管理同时进行处理的系统,该系统的使用者通常为拥有最高权限的系统管理员,主要对上传的模型进行审查评判,当模型样品量不足时,管理员可将该模型放置入待发布模型列表,待数据充足优化后进行发布,同时对存在共性的数据进行合并优化建模等操作。该功能可以有效提高平台上模型的质量以及模型样品数据的代表性,提高模型的自身价值。
如图5所示,模型分析子系统是一种用于调用上传模型对科学仪器检测出来的数据进行分析的系统,该系统与上传共享系统类似,均具备完善的实验信息管理功能。系统调用不同的模型使用不同的算法进行判断处理,调用k最近邻法(knn)模型时,计算方法与上文描述的过程类似,未知样品数据在所有数据集中进行距离计算,计算后根据投票的结果确定最终类别;调用偏最小二乘回归(pls-r)、偏最小二乘判别(pls-da)、正交偏最小二乘判别(opls-da)时,系统将未知样品数据经过设定的预处理方法处理后,与系数向量beta直接相乘,相乘的结果即为最终的结果,若模型时定量模型,最终结果即为含量的测定结果,若模型为定型模型,预测的结果为类别矩阵,根据类别矩阵的分布情况,判断最终的归属类别;使用支持向量机(svm)判别,系统将未知样品数据经过设定的预处理方法处理后,与分界面方程计算距离,距离的正负结果决定了最终的类别归属。
同时,模型分析子系统可以提供分析结果数据接口,使用者根据个人需要调用相应的模型进行分析,同时采用积分或网络支付等方式支付模型使用的费用,该费用主要用于平台日常的运营维护以及对模型上传者、系统管理者进行相应的奖励提高各自的积极性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!