一种基于自适应深度特征滤波器的多场景下目标跟踪方法与流程
本发明属于计算机视觉技术领域,涉及多媒体技术中的视频目标跟踪,为一种基于自适应深度特征滤波器的多场景下目标跟踪方法,通过使用深度特征相关滤波器,自适应地在多种复杂场景中鲁棒地跟踪目标。
背景技术:
视频目标跟踪任务是使用第一帧中已经标记的目标区域信息,自动化地预测后续帧中的目标区域信息,这些信息包括了目标区域的位置和大小。视频目标跟踪是广大科研人员重点关注的领域之一,并且已经在现实生活中取得了诸如眼球追踪、自动驾驶、智能监控等许多实际的应用。总的来说,根据目标跟踪模型的不同,目标跟踪算法大体上可以分为基于生成式模型的跟踪和基于判别式模型的跟踪。一般而言,典型的基于生成式模型的目标跟踪方法首先进行初始化以确定目标区域的状态,然后对当前帧的目标区域进行建模作为当前区域的特征表述,最后在下一帧中使用滑动窗口搜索候选目标,选择与上帧中目标区域模型最相似的窗口作为新的目标区域,mean-shift和粒子滤波便属于这种跟踪模型。与生成式模型不同,判别式模型区分了前景和背景信息,通过训练分类器分离背景和前景目标,跟踪结果更为鲁棒,也成为广泛使用的跟踪方法。诸如kcf、c-cot便属于这种跟踪模型。
但是,现有的目标跟踪方法存在许多缺陷。第一,现有跟踪方法大多在训练时使用循环矩阵来获取正负样例,这样会引入边界信息从而造成很强的边界效应。汉明窗能在一定程度上解决这个问题,但是会屏蔽掉背景中的关联信息,并且当前景物体不分布在中心时会造成模型漂移。第二,传统的滤波模型直接使用颜色直方图、hog等手工设计特征进行训练,这些低层次的信息在光照突变、非刚性形变等复杂条件下表现并不好。深度特征能够从更加抽象的层次对目标进行表示,但目前大多数方法仅使用单层神经网络进行特征提取,其他使用多层深度特征的方法也不能很好的与滤波模型融合。第三,目前的使用多层深度特征滤波器的跟踪方法通常对不同层的深度特征滤波器分配固定的权重。由于低层深度特征能够表示物体轮廓、边缘等低维信息,高层深度特征表示语义信息,因此在面对非刚性形变、遮挡等不同场景时,不同层深度特征的重要性也不同,固定的权重无法发挥深度特征强大的表示能力。第四,目前的跟踪方法通常设置固定的模型学习率来进行模型更新,在目标发生快速变化时会由于模型更新不及时而产生漂移,在发生漂移时又会由于更新过慢而加速错误在模型中的传播。
技术实现要素:
本发明要解决的问题是:现有的视频目标跟踪技术存在的边界效应,不能很好地融合深度特征,深度特征滤波器权重固定,模型学习率固定,不能适应多种复杂场景的缺点。
本发明的技术方案为:一种基于自适应深度特征滤波器的多场景下目标跟踪方法,在视频目标跟踪过程中对视频帧进行处理,实现目标跟踪,包括以下步骤:
1)生成训练样例:第一帧的训练样例为手工标注的跟踪目标区域,后续帧的训练样例是预测出的目标区域,在训练样例上使用循环矩阵生成正样例和负样例,用于训练深度特征滤波器;
2)自适应地提取前景目标:先将原始视频帧图像的rgb颜色空间转换到颜色命名空间当中,然后在颜色命名空间当中计算颜色命名分布直方图,每个像素的前景概率使用颜色命名分布直方图近似计算,由贝叶斯准则推导出来,通过对先验概率进行近似化表示,通过对每个像素计算前景概率生成前景概率图,确定前景目标区域;
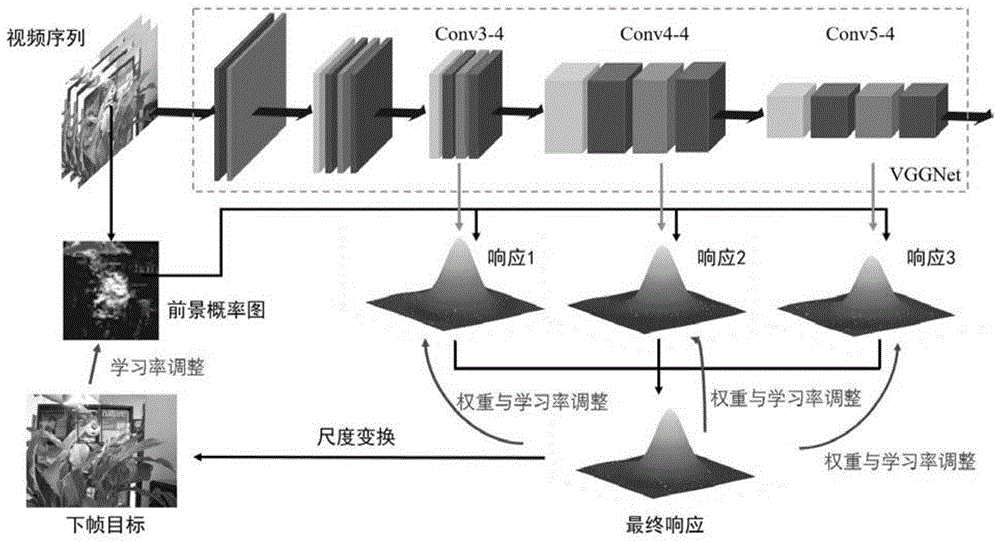
3)深度特征滤波器的训练和目标区域的位置计算:使用vggnet-19的第3、4、5层卷积层分别对训练样例进行特征提取,仅选取前景目标区域提取到的深度特征训练对应的相关滤波器,每一层的深度特征分别有一个对应的相关滤波器,针对各层深度特征,分别使用训练好的滤波器在当前处理的视频帧中计算响应图,各个响应图加权融合后生成最终响应图,最终响应图中响应最大的位置为目标区域的预测位置;
4)自适应地更新深度特征滤波器权重:根据深度特征滤波器产生的响应计算对应的损失函数,用一段时间周期内各个滤波器损失的均值和标准差建立高斯分布,以此来估计这段时间周期内各个滤波器的稳定性,并使用滤波器的稳定性因子来构建遗失函数,通过最小化遗失函数来自适应地确定新的滤波器权重;
5)自适应地更新学习模型;分别计算前景概率模型和深度特征滤波器模型的置信度,根据置信度的高低自适应地调整相应模型的学习速率;
6)对目标区域进行尺度估计:由于目标区域的大小会发生改变,单独使用一维尺度相关滤波器来估计目标区域的尺度,在预测的目标区域处采用不同的尺度变换,将采集到的不同尺度块送入尺度滤波器,使用响应最大的尺度作为目标区域的预测尺度,预测位置和预测尺度作为目标区域的预测结果。
进一步的,步骤2)中前景概率图的计算方式具体为:
2.1)将原始图像x0位置处的rgb颜色空间映射到颜色命名空间中,所述映射为:
其中,i表示各个语义颜色通道,x表示像素在原始图像中的位置,g为高斯函数,σ为其标准差,ωc(x0)表示以x0为中心半径为c的一片区域,φi(x)表示位置x处的像素属于第i个颜色通道的概率;
2.2)在转换到颜色命名空间的图像l中计算某片区域ω的直方图,计算方式为:
其中,ω表示图像l中的某片区域,f和b分别表示图像l的前景区域和背景区域,δ为狄拉克函数,binx表示统计区间,l(x)表示颜色命名图像l中位置x处的像素值。
2.3)分别对前景区域f和背景区域b计算颜色命名直方图,由贝叶斯准则可以计算出x处为前景区域的概率为:
对先验概率进行近似化表示,后验概率可以通过统计直方图进行计算,因此前景和背景的先验概率近似表示为:
其中f和b表示前景区域和背景区域的基数面积,则区域属于前景区域的概率为:
通过在目标区域中各个像素计算前景概率,即可生成前景概率图。
作为优选方式,步骤3)中,仅使用前景概率图中前景概率较高的区域提取到的特征训练深度特征滤波器,每一层的深度特征分别有一个对应的相关滤波器。使用前景概率图中前景区域提取的特征比直接使用整个区域的特征更加鲁棒,缓解了边界效应。每层深度特征分别对应一个相关滤波器,相比于融合多层深度特征之后使用单个相关滤波器,更能发挥深度特征强大的表达能力。
进一步的,步骤4)中,滤波器权重更新的具体方式为:
4.1)假定第t帧画面在
4.2)在△t的时间周期内,第k个滤波器的损失可以通过平均值为
4.3)在△t的时间周期内,通过历史损失的均值和标准差来衡量该滤波器的稳定性,该滤波器的稳定性因子计算为:
通过稳定性因子来构建该滤波器的遗失函数为:
其中,
其中,
进一步的,步骤5)中前景概率模型置信度的计算采用相邻两帧的平均像素差:
其中,
进一步的,步骤5)中深度特征滤波器模型置信度的计算采用相关滤波峰旁比:
其中,max(ft)为第t帧响应图的最大响应值,μt和δt分别为响应值的均值和方差。
进一步的,步骤5)中根据相邻两帧平均像素差的取值来调整前景概率模型的学习速率,预先定义阈值
其中,α0为前景概率模型的初始学习率。
进一步的,步骤5)中根据相关滤波峰旁比的取值来调整深度特征滤波器模型的学习速率,预先定义阈值
其中,β0为深度特征滤波器模型的初始学习率。
作为优选方式,步骤6)中进行尺度估计时,仅在深度特征滤波器处于稳定状态时才执行尺度估计。相比于每次都执行尺度估计的策略减小了计算复杂度,提升了跟踪性能。
本发明提供了一种基于自适应深度特征滤波器的多场景下目标跟踪方法,该方法先将原始图像的目标区域从rgb空间转换到颜色命名空间当中,减小了颜色变化带来的干扰。通过颜色命名直方图计算目标区域的前景概率图,根据前景概率图使用前景区域提取到的特征进行训练,这样可以缓解边界效应,有效抑制背景中的噪声,使得本发明能够自适应地提取目标特征。本发明使用多层深度特征分别在相应的相关滤波器中进行训练,并且自适应地根据跟踪效果更新相应深度特征滤波器的权重,在不同场景中引导跟踪模型自适应地选择有用的深度特征,能够在多种复杂场景中鲁棒地跟踪目标。同时本发明根据前景概率模型和深度特征滤波器模型的置信度自适应地调整对应模型的学习率,能够很好地处理模型发生污染和目标变化过快的问题。
本发明与现有技术相比有如下优点
本发明方法的优点是在多种复杂场景中都具有较高性能,有效缓解边界效应并抑制背景噪声,在不同场景中都能完全发挥深度特征的表达能力,能很好地处理模型污染和目标变化较快的问题。
第一,本发明通过计算前景概率图来确定目标区域中的前景目标,使用前景目标的特征训练跟踪模型。相比于直接提取特征进行训练的技术或者使用汉明窗提取特征进行训练的技术,本发明缓解了边界效应,在抑制背景噪声的同时又保留了背景中的关联信息。
第二,本发明使用多层深度特征分别在相应的相关滤波器中进行训练,并且自适应地根据跟踪效果更新相应深度特征滤波器的权重。相比与固定权重的技术,由于在诸如遮挡、快速运动等不同场景中,不同层的深度特征发挥的作用不同,本发明能够自适应地更新不同层深度特征的权重,在不同场景中引导跟踪模型自适应地选择有用的深度特征,能够在多种复杂场景中鲁棒地跟踪目标。
第三,本发明根据前景概率模型和深度特征滤波器模型的置信度自适应地调整对应模型的学习率,相比于固定学习率的技术,本发明在模型发生污染和目标变化较快时仍然可以准确地跟踪到目标。
附图说明
图1是本发明实施例的视频目标跟踪过程。
图2是不同的前景目标提取方法,a为目标区域,b为前景概率图提取到的前景目标,c为汉明窗提取到的前景目标。
图3是本发明的尺度计算过程。
图4是本发明在跟踪评测数据集otb2013上与现有先进方法的对比曲线。
图5是本发明在跟踪评测数据集otb2013上与现有先进方法的对比跟踪结果。
具体实施方式
本发明提出了一种基于自适应深度特征滤波器的多场景下目标跟踪方法。使用matlab编程语言实现了一个目标跟踪系统。系统通过读取第一帧中带有目标区域标记的视频,自动在后续帧中标记系统预测的目标区域。
图1是本发明实施例的视频目标跟踪过程。本发明具体实施步骤如下:
1.生成训练样例。第一帧的训练样例为手工标注的跟踪目标区域,后续帧的训练样例是预测出的目标区域,在训练样例上使用循环矩阵生成正样例和负样例,用于训练深度特征滤波器;
2.自适应地提取前景目标。目标区域包含了许多背景噪声,汉明窗不能缓解边界效应,并且会屏蔽背景中的关联信息,所以本发明使用前景概率图来获取前景目标。图2展示了不同的前景目标提取方法,a为目标区域,b为前景概率图提取到的前景目标,c为汉明窗提取到的前景目标。
首先计算训练样例的前景概率图,具体方式为:
2.1)将原始图像x0位置处的rgb颜色空间映射到颜色命名空间中,所述映射为:
其中,i表示各个语义颜色通道,x表示像素在原始图像中的位置,g为高斯函数,σ为其标准差,ωc(x0)表示以x0为中心半径为c的一片区域,φi(x)表示位置x处的像素属于第i个颜色通道的概率;
2.2)在转换到颜色命名空间的图像l中计算某片区域ω的直方图,计算方式为:
其中,ω表示图像l中的某片区域,f和b分别表示图像l的前景区域和背景区域,δ为狄拉克函数,binx表示统计区间,l(x)表示颜色命名图像l中位置x处的像素值。
2.3)分别对前景区域f和背景区域b计算颜色命名直方图,由贝叶斯准则可以计算出x处为前景区域的概率为:
对先验概率进行近似化表示,后验概率可以通过统计直方图进行计算,因此前景和背景的先验概率近似表示为:
其中f和b表示前景区域和背景区域的基数面积,统计区间与语义颜色通道取值范围相同,表示是在各个通道中统计。则区域属于前景区域的概率为:
通过在目标区域中各个像素计算前景概率,即可生成前景概率图。在前景概率图中,前景概率较大的区域即为前景目标区域。
3.深度特征滤波器的训练和目标区域位置计算。使用vggnet-19的第3、4、5层卷积层分别对训练样例进行特征提取,仅选取前景区域提取到的深度特征训练对应的相关滤波器。假定第d层神经网络提取到的深度特征向量为x,其长、宽、通道数分别为m、n、d,σ为其标准差,训练样本集表示为xm,n,(m,n)∈{0,1,…m-1}×{0,1,…n-1},每个样本在叠加高斯分布之后均有一个期望输出
其中λ为正则化系数,w*为某层特征学习到的相关滤波器。本发明对于三层深度特征,使用了三个对应的相关滤波器来预测目标区域位置,上述优化问题可以在各自的滤波器中使用快速傅里叶变换来进行加速求解,各自学习到的滤波器可以表示为:
大写字母表示转换到傅里叶域中的信号,如y为y(m,n)转换到傅里叶域的信号,wd表示第d层特征学习到的相关滤波器,表示hadamard积。使用前面帧中训练好的滤波器,在当前帧中计算响应图,假定神经网络在第d层提取到的深度特征为z,那么该层特征对应的滤波器在后面视频帧图像中产生的响应图为:
其中f-1为逆向快速傅里叶变换,该响应图的最大值即为该层深度特征训练的滤波器在下一帧中预测的目标位置,假定
其中,
4.自适应地更新深度特征滤波器权重。滤波器权重更新的具体方式为:
4.1)假定第t帧画面在
4.2)在△t的时间周期内,第k个滤波器的损失可以通过平均值为
4.3)在△t的时间周期内,使用历史损失的均值和标准差来衡量该滤波器的稳定性,该滤波器的稳定性因子计算为:
通过稳定性因子来构建该滤波器的遗失函数为:
其中,
其中,
5.自适应地更新学习模型。分别计算前景概率模型和深度特征滤波器模型的置信度,根据置信度的取值调整相应模型的学习率。首先,采用相邻两帧的平均像素差来评估前景概率模型的置信度:
其中,
根据相邻两帧平均像素差的取值来调整前景概率模型的学习速率,预先定义阈值
其中,α0为前景概率模型的初始学习率。
然后,采用相关滤波峰旁比来评估深度特征滤波器模型的置信度:
其中,max(ft)为第t帧响应图的最大响应值,μt和δt分别为响应值的均值和方差。
根据相关滤波峰旁比的取值来调整深度特征滤波器模型的学习速率,预先定义阈值
其中,β0为深度特征滤波器模型的初始学习率。
6.对目标区域进行尺度估计。目标跟踪是使用一个矩形框在视频中框出目标物体。物体在视频中的位置和大小都会变化,因此目标跟踪可以分为两个方面:1.预测目标的位置,本发明把响应图的最大响应值位置作为预测位置,可以理解为预测矩形框的中心点位置;2.预测目标的大小(尺度估计),可以理解为在确定中心点后,计算矩形框的大小。本发明的步骤1-5是位置预测,步骤6为尺度估计。
由于目标区域的大小会发生改变,本发明单独使用一维尺度滤波器独立进尺度的计算。考虑到跟踪任务中位置的变化往往比尺度变化更明显,因此在预测目标区域位置之后才进行尺度估计。在预测的目标位置采集不同尺度的候选块进行相关滤波分析。假定当前帧训练样本x的目标大小为p×r,尺度大小为s,则以当前目标为中心截取大小为anp×anr的图像区域jn,其中a表示尺度缩放因子,n的取值范围为:
图3是本发明的尺度计算过程。其中f为位置滤波器确定的中心,在不同尺度上提取特征之后,使用三维高斯滤波后构建输出g,最后根据g中的最大响应值确定最终尺度信息。
在进行尺度估计时,仅在深度特征滤波器处于稳定状态时才执行尺度估计。相比于每次都执行尺度估计的策略减小了计算复杂度,提升了跟踪性能。
本发明使用otb2013数据集进行评估。otb2013数据集包含了50个视频序列,也称为otb50。该数据集包含了诸如水面、演唱会、野外等多种复杂场景,被跟踪的物体则包括了人脸、汽车、球等。这些不同的场景涵盖了许多跟踪任务中有挑战性的问题,比如:出视野、快速运动、尺度变化、光照变化、遮挡等。otb2013数据集采用距离精度dp和重叠成功率os两个指标对跟踪效果进行评估。其中,dp表示了跟踪算法预测框与真实框中心位置距离小于某个阈值的帧的百分比,通过一系列的阈值进行评估即可生成距离精度曲线。os表示了跟踪算法预测框与真实框的交并比大于某个阈值的帧的百分比,即重叠成功率,通过一系列的阈值进行评估即可生成重叠成功率曲线。otb数据集采取三种不同的评估方法对算法进行评估:一次通过评估ope是经典的评估方法,在第一帧中给定真实值经过一次运行给出评估结果。时域鲁棒性评估tre加入时间干扰因子,在随机一帧开始评估。空域鲁棒性评估sre在第一帧的真实值中加入干扰。本发明的方法在相同数据集上没有随机性,因此采用一次通过评估ope对距离精度dp和重叠成功率os进行评估。
本发明使用vggnet-19中的第3、4、5层卷积层作为深度特征的提取器,各层对应滤波器的初始权重分别设为:1,0.5,0.25,颜色命名直方图和相关滤波器的初始学习速率均设为0.11。本实施例的实验环境为ubuntu16.04lts,具有i7-6850k的和nvidiageforce1080ti的显卡,64gb内存。
图4是本发明在跟踪评测数据集otb2013上与现有先进方法的对比曲线。(a)为距离精度曲线dp,(b)为重叠成功率曲线os,通过计算不同阈值下的距离精度和重叠成功率来进行绘制。
表1是本发明在otb2013数据集中与先进方法的性能对比结果。第一行是对比的目标跟踪方法名称,本发明的名称为savt。本发明给出了各个方法在距离精度阈值为20时的距离精度dp以及阈值为0.6时的重叠成功率os,可见本发明均有很好的表现。
图5是本发明在跟踪评测数据集otb2013上与其他先进方法的对比跟踪结果。展示了本发明的方法与其他先进方法在不同视频序列中的跟踪效果,可见本发明的跟踪结果更加精确。
从表1、图4、图5可以看出,本发明在各项指标中都取得了最好的结果。
表1:本发明在otb2013数据集中与目前先进方法的性能对比结果
- 还没有人留言评论。精彩留言会获得点赞!