一种基于网页分割和搜索算法的服务包装方法与流程
本发明涉及服务计算领域,具体涉及一种基于网页分割和搜索算法的服务包装方法。
背景技术:
随着互联网的发展,服务提供者倾向于通过网页来展示自己的服务数据,然而各式各样提供便利的网页反而对开发者使用这些源数据造成了很大的限制。服务包装系统旨在将网页中的数据进行封装,包装成一个服务,并提供调用该服务的restfulapi以供开发者在开发过程中使用该服务。
web页面块分割技术是对现有网页文档进行分析和处理,具体将整个web页面分割成包含信息数据的多个块的技术,从而实现广告去除、主要信息提取等功能,主要包括基于节点熵的页面分块技术,基于视觉特征的页面分块技术,基于内容距离的网页分块技术等,web网页分割技术已被广泛应用于互联网行业的各个领域。
服务是具有多种属性,从属于某一具体服务类别,由某个或某类开发者提供的api集合。
api是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。api具有多种输入输出属性,属于某个具体开发者,从属于某一具体服务。
网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
技术实现要素:
本发明的目的是提供一种基于网页分割和搜索算法的服务包装方法。该服务包装方法极大地提升了用户获取数据的效率。
为实现上述发明目的,本发明提供以下技术方案:
一种基于网页分割和搜索算法的服务包装方法,包括以下步骤:
服务提取阶段,包括动态包装和/或静态包装;针对动态包装,对动态网页进行解析,并在解析获得的动态表单信息中标记可能存在的表单,用户在可能存在的表单中标记并定义需要的表单;针对静态包装,对静态网页进行解析,并对解析得到的静态表单进行分块和标记,用户选择并定义所需的分块,并填写服务的名称和描述信息和提取规则;
服务调用阶段,用户输入调用服务的相关信息,后端系统根据接收的服务调用相关信息,按照提取规则生成相应服务,并返回前端。
本发明提供的基于网页分割和搜索算法的服务包装方法,可自动分析页面,通过若干点击和少量的输入即可完成对一个网页的封装的模块,可以将网页封装成一个服务,生成爬虫规则,并按照用户需求返回相应结构化的数据。极大地提升了用户获取数据的效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动前提下,还可以根据这些附图获得其他附图。
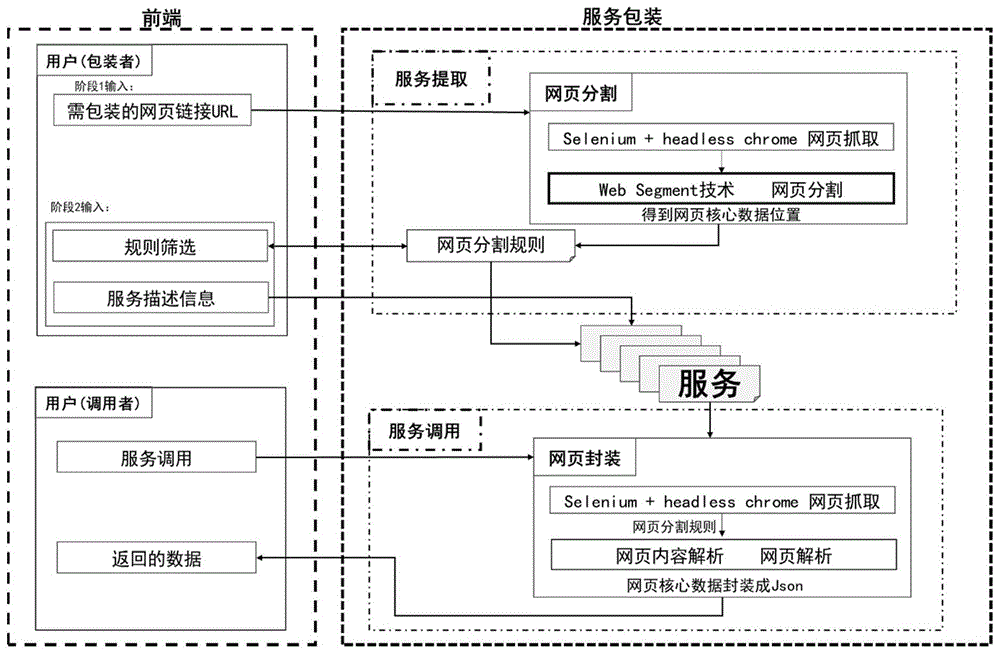
图1是本发明基于网页分割和搜索算法的服务包装方法及系统的实现框架;
图2是本发明基于网页分割和搜索算法的服务包装方法及系统的用户使用流程图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。
本发明提供的基于网页分割和搜索算法的服务包装方法,包括服务提取阶段和服务调用阶段,服务提取是包装者通过若干点击和少量的输入即可完成对一个网页的封装的模块,可以将网页封装成一个服务。服务调用是指调用已封装的服务,并且提供了若干参数以供满足输入和筛选的需求,这些参数既包括统一的参数,也包含针对不同网页生成的特定参数。
下面以http://www.ceic.ac.cn/history页面为例,解释基于网页分割和搜索算法的服务包装方法运行规则。
如图1和图2所示,本发明一种基于网页分割和搜索算法的服务包装方法,包括以下过程:
阶段一:服务提取
服务提取主要包含静态包装和动态包装两个功能,即对数据直接呈现在网页中的网页进行静态包装;对需要输入一定的查询内容并点击按钮才能呈现数据的网页进行动态包装。
对用户而言,服务提取只需要用户进行少量点击和填写部分对服务描述性信息即可。服务提取会根据网页隐式地进行两种不同的提取规则。对静态网页,也就是数据直接呈现在网页中的网页,进行静态网页提取;对动态网页,也就是需要用户进行一定的输入和点击,数据才会呈现的网页,进行动态网页提取。
动态包装包括以下步骤:
s1-1、动态页面信息解析,具体包括:
s1-1-1、用户自己填写一个url地址,此地址为任意一个可被国际互联网访问的web链接。
s1-1-2、使用爬虫技术爬取此url地址对应web页面的源码;爬虫工具可以为python3.6环境下的selenium+beautifulsoup+pyquery。
s1-1-3、查找页面中是否存在<form>标签,将网页源码转换为结构化类数据,在类数据中查找form标签,并做好标记。标记信息为json格式文件,示例如下:
json文件解析如下:
*url是网址。
*form_check为1/0,如果是0就不使用form检测,如果是1就使用form检测。
*main_form_index为下面默认选择forms数组的索引号,配合form_check使用。
*forms为一个数组,里面存储了页面中所有的form信息(一般情况下页面中最多只有一个form,但这里检索了所有的form,第一个为默认),最终,前端根据用户实际的选择修改"main_form_index"的值。
*forms中的每一个元素解析如下,如forms[0]:
*id和len是辅助信息。
*所有的css_selector为form的选择器。
*main_btn_index为下面submit_button_list中主要按钮的索引号,根据用户选择修改。
*input_list为表单的参数列表,同时也是后台api的输入参数列表,如input_list[0]:
*query_name是可以让用户修改的,我们的api使用的查询name。
*required是用户是否必须输入的标识。
*value是用户输入值的默认项,可以让用户修改。
s1-1-4、在gui显示后台不断打印出解析日志信息。
其中,日志信息格式为logging+时间戳–>+正在处理的事情。最后一行成功情况下为200+网页表格规则json文件地址+网页截图地址;失败情况下为503+procedurefailed,pleaseretry!,如:
logging2018-11-2620:23:14.572181->crawlhtmldocumentfromhttp://www.ceic.ac.cn/history,pleasewaitforabout40s(max60s)
logging2018-11-2620:23:18.772222->findingformlableonhttp://www.ceic.ac.cn/history
logging2018-11-2620:23:18.974834->finishedonhttp://www.ceic.ac.cn/history200http://183.129.170.180:18088/statics/form_test1/form_list.jsonhttp://183.129.170.180:18088/static/form_test1/form_seg_shot.png
s1-1-5、使用图像处理技术(python中的pil库),标记页面中所有可能存在的表单信息,以及每个表单中的每一个输入框的位置、可能的提交按钮的位置。
标记过程中,需要获得所标记元素的位置,这里使用javascript的getboundingclientrect函数获取所属元素的宽高和相对图片的位置。
s1-2、用户选择表单并定义输入参数信息,具体包括:
s1-2-1、用户自主选择自己是否需要使用表单,如需要,选择表单编号,如不需要,跳过此步骤。
s1-2-2、用户自主定义每个输入框的名称以及示例值,选择提交按钮编号。
s1-2-3、将用户修改后的信息提交给后台,后台根据此信息生成form表单提取规则。
静态包装包括以下步骤:
s1-3、静态页面信息解析,具体包括:
s1-3-1、使用爬虫技术爬取url地址对应web页面的源码。
s1-3-2、使用广度优先搜索算法,找到页面中所有可能存在的项。
其中,广度优先搜索算法为:生成页面的dom结构树,创建遍历顺序列表,将html节点放入列表,顺序遍历列表,将每个节点的子节点放入列表最后,直到所有节点遍历完毕。
s1-3-3、使用网页分割算法将页面中所有结构相同的项合并成一个分块。
其中,网页分割算法为:将所有节点的标签路径计算出来,并和自己的兄弟节点的标签路径比较,如果相同,则两个为同一个块。算法会将所有标签路径相同的节点合并为同一个块。
s1-3-4、使用加权排序算法,筛选出最多10个最大的分块。
其中,加权排序算法为:按照每个块内列表项数目从大到小排序,取前15个块;按照每个块内长度从大到小排序,取前15个块;两个列表取交集,并取前10个块作为最后选择到的最大的分块。
s1-3-5、使用图像处理技术,将筛选出的分块进行标记。
s1-3-6、在gui显示后台不断打印出的解析日志信息。日志信息格式为logging+时间戳–>+正在处理的事情。最后一行成功情况下为200+网页表格规则json文件地址;失败情况下为503+procedurefailed,pleaseretry!,如:
2018-11-2613:31:21.723678->crawlhtmldocumentfromhttp://www.ceic.ac.cn/history,pleasewaitforabout40s(max60s)
2018-11-2613:31:25.826979->handlingtheinputformsonhttp://www.ceic.ac.cn/history
2018-11-2613:31:31.362985->runpruningonhttp://www.ceic.ac.cn/history
2018-11-2613:31:31.365060->runpartialtreematchingonhttp://www.ceic.ac.cn/history
2018-11-2613:31:31.380825->runbacktrackingonhttp://www.ceic.ac.cn/history
2018-11-2613:31:31.381136->mergingandgeneratingrulesandblocksonhttp://www.ceic.ac.cn/history,process:1%
2018-11-2613:31:31.381136->mergingandgeneratingrulesandblocksonhttp://www.ceic.ac.cn/history,process:50%
2018-11-2613:31:43.596304->mergingandgeneratingrulesandblocksonhttp://www.ceic.ac.cn/history,process:99%
2018-11-2613:31:43.672126->selectingthemainsegmentonhttp://www.ceic.ac.cn/history
2018-11-2613:31:44.780230->generatingsectionsonhttp://www.ceic.ac.cn/history
2018-11-2613:31:45.128704->generatingapi_infoonhttp://www.ceic.ac.cn/history
2018-11-2613:31:45.183179->generatingrulesonhttp://www.ceic.ac.cn/history
2018-11-2613:31:45.183506->outputresultjsonfileonhttp://www.ceic.ac.cn/history
2018-11-2613:31:45.194587->finishedonhttp://www.ceic.ac.cn/history
200http://183.129.170.180:18088/statics/15432390785389/api_info.json
s1-4、用户选择分块并定义输入参数信息
s1-4-1、用户自主选择自己想要的分块的编号。
s1-4-2、用户定义系统自动分析好的分块内数据编号的名称及描述,以及是否需要此分块。
s1-4-3、用户填写所生成服务的名称,描述信息。
s1-4-4、系统将用户修改后的服务信息和每个项的提取规则以json格式提交给服务生成后台。
提取规则算法为:按照dom树结构从html标签开始,通过>表示递进关系,使用nth-child(i)表示节点属于该层的第i个节点,从而生成css_selector形式的提取规则。
服务信息文件示例如下:
json文件格式说明如下:
*api_name为用户定义好的api名字。
*api_description为用户定义好的api描述。
*img_link字段即截取的主要部分的图片链接地址。
*api_crawl_rules_link字段为爬虫规则的json文件地址。
*json_link字段为默认最大块的文件地址。
*main_sec_id为默认选择的主题块的索引值,一般为0,根据用户实际需求修改此值
*sections是一个字符串数组,每个项为每个块的文字内容,直接索引访问setctions[main_sec_id]即可得到此块的文字内容。
*api_info["candidate"]是二维数组,每一个项为每一个主题块中的元素信息。元素信息解析如下:
{
"id":0,//元素id信息
"name":"text_0",//元素名称
"description":"text_description",//元素描述
"type":"text",//元素类型
"example":"纬度:",//元素示例值
"select":1,//是否选择输出此元素
"parent_id":-1//此元素的上级元素id
},
其中,type类型分为三种:text,img,link分别代表文字,图片和超链接类型。parent_id用来在服务调用阶段查询此元素时,后台识别所用。
爬虫规则json文件示例及说明如下:
其中,text信息需要根据css_selector和rank两个信息同时定位;img分为img标签中的图像信息和css中的背景图片信息,需要根据不同类型的提取规则进行图片提取。提取规则为:如图片为img标签中的图片,则提取img标签的链接地址;如为背景图片的链接信息,则需要找到图片所在元素的css属性中的background-img属性,然后提取相应链接。
后台文件即可根据此解析规则对页面进行解析。
s1-5、生成服务
s1-5-1、服务生成后台解析传过来的服务信息和提取规则信息,并进行容错检查。
s1-5-2、后台生成用户所需要的服务和对应服务调用的地址和查询参数,等待调用。
这里的服务生成后台需要将用户所定义的服务信息以及提取规则存储在自己的数据库中,等待服务调用时再次查询服务相关信息。
如此例中生成的服务api地址为:url://call_service/79,代表着生成的服务id号为79,此接口符合restapi规范,因此可以使用此接口对此服务信息进行查询,调用,删除和修改的功能。
阶段二:服务调用
服务调用是指调用已封装的服务,并且提供了若干参数以供满足输入和筛选的需求,这些参数既包括统一的参数,也包含针对不同网页生成的特定参数。
用户通过查看服务信息填写restfulapi即可调用对应服务。
具体步骤如下:
s2-1、用户填写服务规定的查询参数,调用api。
查询参数为form输入选项中的每一项,从而进行输入查询;同时,还包括返回结果中的每一项,用户因此可根据该类参数对返回结果进行筛选。同时,最大页数参数为__max_page,从而解决网页中有分页问题的情况,默认为5页数据。
如用户调用的url为:
url://call_service/79?__max_page=7&weidu1=30&jingdu2=20&震级(m)=3.5&link_5.参考位置=云南临沧市耿马县
其中,__max_page为系统最大分页数目;weidu1和jingdu2为表单的输入查询参数;震级(m)和link_5.参考位置为服务的返回结果参数,“link5.参考位置”指的是链接link5下的参考位置参数。
则上述链接意义为:将分页内容捕捉下来,最多7页,输入参数weidu1值为30,jingdu2值为20,输出时候选择结果为震级(m)=3.5、link_5.参考位置=云南临沧市耿马县的数据进行显示。
如存在中文字符,需使用utf-8编码。
s2-2、调用后台根据用户所调用的api的地址,利用爬虫技术,打开api对应的真实url地址。
s2-3、调用后台根据用户包装服务时的选择,决定是否填写并查询表单信息。
如需要填写表单信息,则根据用户所输入的查询参数值填写表单内容,支持的输入框类型为html5支持的元素form标签,如:
text,number,email,password,textarea,radio,checkbox,select,datalist,button,submit,rest。
s2-4、调用后台利用爬虫技术,爬取处理完表单后的页面源码。
s2-5、系统根据已存储的提取规则信息,对页面中相关项进行提取,并按照用户所定义的返回结果的名字和参数,进行结构化转化,生成返回结果。
s2-6、调用后台根据用户的查询参数,对返回结果进行筛选。
s2-7、系统将调用结果返回给前端。
示例返回结果:
[{"link_5":{"href":"http://news.ceic.ac.cn/cd20181127064153.html","参考位置":"云南临沧市耿马县"},"record_id":0,"发震时刻(utc+8)":"2018-11-2706:41:53","深度(千米)":"8","纬度(°)":"23.49","经度(°)":"99.46","震级(m)":"3.5"}]
上述基于网页分割和搜索算法的服务包装方法,该包装方法可以尝试分析任意类型的网页页面,并自动分析出网页中可能存在的主要信息,将信息分块后,分析出每块内容所拥有的格式,经过用户简单的修改后,即可将此页面转化成可以直接调用的服务,并返回用户需要的格式化、结构化的数据。同时,本发明提供动态表单查询功能,如页面中存在动态表单,可将表单查询框转化为查询参数供用户使用。相对于传统的爬虫程序,本发明可自动分析页面,生成爬虫规则,并按照用户需求返回相应结构化的数据。因此,极大地提升了用户获取数据的效率。
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!