基于深度加权神经网络的异常用电检测方法与流程
本发明属于机器学习和电网营销数据挖掘领域,涉及一种基于深度加权随机神经网络不均衡数据分类的异常用电量智能检测方法。
背景技术:
:频繁的异常电力消耗,不仅使电力企业遭受严重的经济损失,同时还会威胁到人们的生命安全。美国智能咨询和服务公司2017年发布的针对50多个发展中国家的用电异常调查报告显示,大多数国家电力企业遭遇了异常电力消耗所带来的严重的非技术损失,每年经济损失高达64.7亿美元;2013至2016年的非技术性损失年均增长率约为11%。因此,智能高效的异常用电检测对电网管理部门至关重要。目前,我国电力企业的异常用电检测都是采用人工排查或用电数据库规则推断的方法,往往存在适用性不高、准确率和效率较低等问题。随着智能电网的蓬勃发展以及用电数据急剧增加,复杂的数据结构和海量的数据流使得传统的用电异常检测算法已不再适用。因此,研究基于人工智能的智能高效用电异常检测算法是智慧用电管理与电力营销的重要保障。根据国家电网浙江电力公司数据统计,目前最具有代表性的用电异常种类高达几十种,但相对于庞大的正常用电数据,异常用电数据总量的比例相对较小,不超过0.3%。使得异常用电检测的建模面临的是一个典型的不均衡数据集学习问题。一方面,传统基于均衡数据集的智能建模算法并不适用于异常用电检测,虽然传统的智能算法在不均衡数据集上仍然能保证很高的识别率,但少数样本类(minorityclass)的识别率却很低,而少数样本类往往又是不均衡数据集处理中最重要的信息;另一方面,传统浅层不均衡集处理算法在处理大规模用电数据时,往往面临着表征能力不够、时效性差等缺点。因此,如何构建高效的表征能力强泛化性能好又同时适用于不均衡用电大数据的异常用电检测模型成为一个亟待解决的问题。针对这个问题,本发明以国网浙江电力公司营销部用电大数据为应用背景,提出基于深度不均衡随机神经网络超限学习机(dwelm)算法的异常用电检测模型,重点分析10种典型的用电异常类别检测问题,提出能够描述传统基于规则推理判别方法的用电异常数据特征表示方法。详细的技术实现要素:如下:
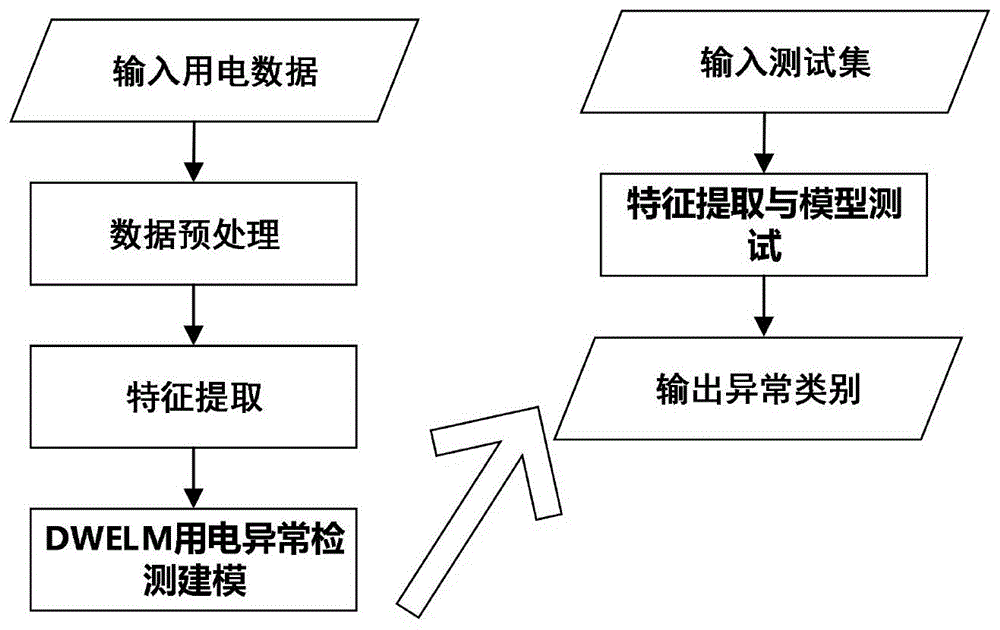
发明内容本发明针对传统异常电量消耗检测方法的不足,提出了一种更适用于不均衡数据集的基于深度加权神经网络的异常用电量检测方法。本专利以10种出现频率较高用电异常检测为例,但实际算法并不局限于10种,易于扩展。这些典型用电异常包括:1)上期电量为0且本期电量大于设定值,该异常在电力系统标示为fh04;2)总峰谷电量异常,该异常在电力系统标示为fh06;3)电量值超过合同最大电量两倍,该异常在电力系统标示为fh08;4)低压居民电量异常波动,该异常在电力系统标示为fh09;5)低压非居民电量异常波动,该异常在电力系统标示为fh10;6)高压电量异常波动,该异常在电力系统标示为fh11;7)无功异常,该异常在电力系统标示为fh14;8)光伏电量异常,该异常在电力系统标示为fh22;9)光伏电量异常波动,该异常在电力系统标示为fh24;10)环比电量异常波动,该异常在电力系统标示为fh28。为方便说明,本专利选取来自杭州余杭区部分用户近两年历史用电数据为例。本发明的技术方案主要包括如下步骤:步骤1、数据预处理;步骤2、对预处理后的数据进行特征提取,形成特征库;步骤3、依据提取出的特征库,用dwelm算法构建异常电量的检测模型。所述步骤1的数据预处理主要包括对相关用电数据的整合和用户分类。具体实现包括以下几个步骤:1-1.把分布在不同数据源的用户的户号、用电客户类型、年月、总电量、峰电量、谷电量、总止度、尖止度、峰止度、谷止度、合同容量、有功抄表电量、无功抄表电量、光伏用户发电表电量、上网表电量及对应电量异常标签收集、整理、清洗,转换加载到一个新的数据源,同时剔除重复数据,形成新数据;1-2.对整合后新数据按照用电客户类型划分成高压、低压居民、低压非居民和光伏用户这4种类别。所述的步骤2对预处理后的用电数据进行特征提取;2-1、首先把上月电量、本月电量、去年同期电量、尖电量、峰电量、谷电量、总电量、总止度、尖止度、峰止度、谷止度、合同容量、有功抄表电量、无功抄表电量、执行力调、光伏用户发电表电量和上网表电量分别记为xp、xc、xs、xse、xpe、xve、xte、xtd、xsd、xpd、xvd、xcc、xa、xr、xd、xg和xn,因此可得到电量同比(ecfl)和环比(ecfp)的计算公式为:2-2.对上述4种用电客户类型一共进行了25维特征提取,分别记为f1、f2,…,f25。由于不同用电客户类型具有的电量异常种类不同,因此具有维度信息不完全一致,具体如下所述:对于低压居民,只有f1~f5、f12和f14~f23,其中,f1=xp,f2=xc-200,f3=xc-100,f4=ecfl,f5=ecfp,f12=xs,f14=xt-xsd-xpd-xvd,f15=xse+xpe+xve,f16=xte,f17=xpe,f18=xve,f19=xse,f20=xcc*24*30*2,f21=xa,f22=xr,其余特征维度向量设置为0;对于低压非居民,只有f1、f2、f6~f8、f12和f14~f23,其中,f6=xc-10000,f7~f8在低压非居民类别内的计算方法分别与f4~f5相同,其余特征维度向量设置为0;对于高压居民,只有f1、f2、f9~f12、和f14~f23,其中,f9~f11在高压居民类别内的计算方法和f6、f4~f5一样,其余特征维度向量设置为0;对于光伏用户,只有f13、f24~f25,其中f13=ecfp,f24=xg和f25=xn,其余特征维度向量设置为0;所述步骤2中需要注意如下:本专利中这10种电量异常具体审核规则为:(1)异常fh04的审核规则为:xp=0&xc>200。(2)异常fh06的审核规则为:(xt-xsd-xpd-xvd>2)|(xse+xpe+xve>xte)|(xte=xpe&xte>0)|(xte=xve&xte>0)|(xte=xse&xte>0)。(3)异常fh08的审核规则为:xte>xcc*24*30*2。(4)异常fh09的审核规则为:xc>100&|ecfl|>2&|ecfp|>2。(5)异常fh14的审核规则为:(xd=1&xa=0&xr>0)(xd=1&xa≠0&xr=0)。(6)异常fh10的审核规则为:xc>1000&|ecfl|>0.5&|ecfp|>0.5。(7)异常fh11的审核规则为:xc>1000&|ecfl|>0.5&|ecfp|>0.5。(8)异常fh22的审核规则为:xg<xn|xg=0。(9)异常fh24的审核规则为:|ecfp|>0.3。(10)异常fh28的审核规则为:xc>100&|ecfp|>2&xs=0。所述的步骤3将样本提取后的特征库,用dwelm算法构建异常电量的检测模型。3-1.采用已标定正常与异常用电数据类别的数据,构建分类模型。3-2.输入训练样本{(xi,ti)|xi∈rd,ti∈r,i=1,2,...,n},初始化训练样本的权重dk(xi),令d1=diag(d1(x1),...,d1(xn))。其中,xi表示第i个样本,ti是对应的样本标签,n为总的训练样本数量,m为类别数量,r(ti)是属于ti类的样本数。3-3.在k个特征提取块中对训练样本依次进行k次迭代,进行样本2次特征提取。在第k次迭代中,随机产生输入权重和偏置b(k)。3-4.依次计算隐含层输出矩阵h(k)、输出权重β(k)、预测函数ωk(x)以及属于第j类的样本权重其中,σ(.)是非线性映射函数3-5.更新样本权重dk+1(xi)。3-6.计算样本的决策权重ak。其中,εk为第k个分类器的加权误差率:3-7.随机生成投影权重矩阵且所有元素服从正态分布,并计算下一个特征提取块的输入x(k+1)。3-8.分别调整网络结构参数,包括特征提取构建块数量k、隐含层节点数lk、正则化参数ck和随机位移步长γ,使得在保证训练时间与训练收敛的均衡性下达到最高的识别率。3-9.经过3-2至3-8步骤的训练后,得到训练好的异常电量检测模型。3-10.把测试样本集x投入训练好模型中,通过k次迭代对测试样本进行2次特征提取,依次计算每一次迭代中第k个特征提取块的输出o(k)和下一个特征提取块的输入x(k+1)。o(k)=ωk(x(k))3-11.计算dwelm中第k个welm分类器的输出o(k)。o(k)=ωk(x(k))3-12.计算最后的测试异常类别输出o(x)。本发明有益效果如下:本发明的正常实验数据比例约为87%左右,而其他10种异常电量数据中每一种所占的比例几乎都低于2%,甚至有的部分异常不足于1%,明显属于一种典型的数据极不均衡问题。传统的基于均衡集分类算法或浅层的不均衡集处理算法在这种大规模的极不均衡数据的分类问题下,表征能力和泛化能力差,导致少数样本的识别率很低。而本发明采用的dwelm算法由eh-drelm和改进的adaboost-id两种算法结合而成,很好的解决了上述问题,而且大大提高了少数样本的识别率,证明了算法的有效性。其中,eh-drelm比原始的elm更好提高了表示能力(即提取特征或有用信息的能力),而且改进的adaboost-id解决了原始adaboost算法中不适用于不平衡的多类数据问题,更适用于数据类别极度不均衡的异常用电量的检测。dwelm算法中包含多个级联的特征提取块,能够在原来特征提取的基础上,更好的进一步提取样本的2次特征,有利于提高样本分类检测精度。同时,dwelm学习速度比传统人工神经网络更快且泛化性能更好,可以很快地实现模型的训练和测试。本发明结合用电客户类别和电量异常审核规则来进行特征抽取,可以把源数据具有强烈的时间序列特点变成具有无序列特点,使得在后面的电量异常检测分类算法的选择上更加具有普适性。附图说明图1为发明流程示意图;图2为本发明dwelm算法中eh-drelm的基本结构。具体实施方式下面结合附图和具体实施方式对本发明作详细说明。如图1所示,首先对用电数据进行预处理,对预处理后的数据进行特征提取,然后把特征提取后的训练集用dwelm算法进行用电异常检测建模,得到异常检测模型。最后把测试集投入到训练好的模型中进行特征提取和测试,得到电量异常的测试结果。图2显示了dwelm算法中eh-drelm的基本结构,由k个级联的特征提取块和一个分类器组成。k个级联的特征提取块可以在样本进行1次特征提取的基础上,对样本进行2次特征提取。几类常见的典型电量异常检测方法的实现步骤,在
发明内容内已有详细的介绍,即本发明的技术方案主要包括如下步骤:1、数据预处理;2、对预处理后的数据进行特征提取。3、依据提取出的特征库,用dwelm算法构建异常电量的检测模型。所述步骤1的数据预处理主要包括对相关用电数据的整合和用户分类。具体实现包括以下几个步骤:1-1.把分布在不同数据源的用户的户号、用电客户类型、年月、总电量、峰电量、谷电量、总止度、尖止度、峰止度、谷止度、合同容量、有功抄表电量、无功抄表电量、光伏用户发电表电量、上网表电量及对应电量异常标签收集、整理、清洗,转换加载到一个新的数据源,同时剔除重复数据。1-2.对整合后新数据按照用电客户类型划分成高压、低压居民、低压非居民和光伏用户这4种类别。所述的步骤2对预处理后的用电数据进行特征提取;2-1、首先把上月电量、本月电量、去年同期电量、尖电量、峰电量、谷电量、总电量、总止度、尖止度、峰止度、谷止度、合同容量、有功抄表电量、无功抄表电量、执行力调、光伏用户发电表电量和上网表电量分别记为xp、xc、xs、xse、xpe、xve、xte、xtd、xsd、xpd、xvd、xcc、xa、xr、xd、xg和xn,因此可得到电量同比(ecfl)和环比(ecfp)的计算公式为:2-2.对上述4种用电客户类型一共进行了25维特征提取,分别记为f1、f2,…,f25。由于不同用电客户类型具有的电量异常种类不同,因此具有维度信息不完全一致。如下所述:2-3.对于低压居民,只有f1~f5、f12和f14~f23,其中,f1=xp,f2=xc-200,f3=xc-100,f4=ecfl,f5=ecfp,f12=xs,f14=xt-xsd-xpd-xvd,f15=xse+xpe+xve,f16=xte,f17=xpe,f18=xve,f19=xse,f20=xcc*24*30*2,f21=xa,f22=xr,其余特征维度向量设置为0;2-4.对于低压非居民,只有f1、f2、f6~f8、f12和f14~f23,其中,f6=xc-10000,f7~f8在低压非居民类别内的计算方法分别与f4~f5相同,其余特征维度向量设置为0;2-5.对于高压居民,只有f1、f2、f9~f12、和f14~f23,其中,f9~f11在高压居民类别内的计算方法和f6、f4~f5一样,其余特征维度向量设置为0;2-6.对于光伏用户,只有f13、f24~f25,其中f13=ecfp,f24=xg和f25=xn,其余特征维度向量设置为0;所述的步骤3将样本提取后的特征库,用dwelm算法构建异常电量的检测模型。3-1.采用已标定正常与异常用电数据类别的数据,构建分类模型。3-2.输入训练样本{(xi,ti)|xi∈rd,ti∈r,i=1,2,...,n},初始化训练样本的权重dk(xi),令d1=diag(d1(x1),...,d1(xn))。其中,xi表示第i个样本,ti是对应的样本标签,n为总的训练样本数量,m为类别数量,r(ti)是属于ti类的样本数。3-3.在k个特征提取块中对训练样本依次进行k次迭代,进行样本2次特征提取。在第k次迭代中,随机产生输入权重和偏置b(k)。3-4.依次计算隐含层输出矩阵h(k)、输出权重β(k)、预测函数ωk(x)以及属于第j类的样本权重其中,σ(.)是非线性映射函数3-5.更新样本权重dk+1(xi)。3-6.计算样本的决策权重ak。其中,εk为第k个分类器的加权误差率:3-7.随机生成投影权重矩阵且所有元素服从正态分布,并计算下一个特征提取块的输入x(k+1)。3-8.分别调整网络结构参数,包括特征提取构建块数量k、隐含层节点数lk、正则化参数ck和随机位移步长γ,使得在保证训练时间与训练收敛的均衡性下达到最高的识别率。3-9.经过3-2至3-8步骤的训练后,得到训练好的异常电量检测模型。3-10.把测试样本集x投入训练好模型中,通过k次迭代对测试样本进行2次特征提取,依次计算每一次迭代中第k个特征提取块的输出o(k)和下一个特征提取块的输入x(k+1)。o(k)=ωk(x(k))3-11.计算dwelm中第k个welm分类器的输出o(k)。o(k)=ωk(x(k))3-12.计算最后的测试异常类别输出o(x)。为验证本发明专利的有效性,采用国网浙江电力公司营销部杭州市某区两年的用电大数据做实验测试。数据库包含正常用电(normal)以及10种异常电量类别,数据库总体样本数量为101812,正常样本88271(86.7%),10中异常样本分别为1378(1.35%)、695(0.68%)、693(0.68%)、1042(1.02%)、3899(3.83%)、776(0.76%)、1738(1.71%)、1425(1.40%)、805(0.79%)和1090(1.08%)。传统的不均衡数据集加权超限学习机算法(welm)与提示加权超限学习机算法(bwelm)作为对比方法,用于反映本发明dwelm算法的优越性。每一个类别的具体测试准确率如表1所示,其中黑体部分为最优识别率。显而易见,本发明专利的算法能保证更高的用电异常检测率,优于对比的传统方法。表1基于welm、bwelm和dwelm算法的每一种异常识别率对比(%)normalfh10fh09fh04fh11fh24fh28fh06fh08fh14fh22welm69.5898.4698.7997.4898.031009610090.2810098.52bwelm81.998.8810096.299.6210099.5110094.8497.52100本发明算法89.1510010010010010099.5410099.09100100当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1