一种粒子滤波器的粒子数自适应方法与流程
本发明属于信号处理领域,具体是信号处理领域的粒子滤波问题,特别是涉及到粒子滤波中自适应粒子数的问题。
背景技术:
由于粒子滤波算法摆脱了动态系统线性、高斯的限制,与传统的滤波方法相比,粒子滤波简单易实现,因此近年来在多个领域得到了很好的应用。比如,在经济学领域,它被应用在经济数据预测;在交通管制领域,它被应用在对车或人视频监控;在军事领域,它被应用于雷达跟踪空中飞行物,空对空、空对地的被动式跟踪。
粒子滤波使用蒙特卡罗仿真来实现贝叶斯滤波,其主要思想是使用一组带有相应权值的粒子来表示动态系统状态空间所需的后验概率密度,用样本均值来代替积分计算,由此获得状态的估计值。当粒子数足够多时,可以较为精确地近似后验分布,然而粒子的数量又在一定程度上决定了粒子滤波器的复杂度,粒子数量越多会导致复杂度越大,因此如何更有效地利用到现有的粒子集是一个值得探索的问题。比如,文献“w.r.gilksandc.berzuini.followingamovingtarget-montecarloinferencefordynamicbayesianmodels.journaloftheroyalstatisticalsociety,seriesb,61(1),2001.”中给出了一种结合马尔可夫链蒙特卡罗步骤的方法来提高基于采样的后验近似性能。另外,文献“m.k.pittandn.shephard.filteringviasimulation:auxiliaryparticlefilters.journaloftheamericanstatisticalassociation,94(446),1999.”给出了一种辅助粒子滤波的方法,通过一步预测法将重要性函数与目标分布之间的失配度最小化,进一步将权重变化的风险最小化,从而提高粒子滤波器的工作效率。
然而,到目前为止,大多数现有的粒子滤波方法在整个状态估计过程中都使用固定数量的粒子,这可能是非常低效的,因为随着时间的推移,粒子分布的状态可能会急剧变化。也就是说提高粒子滤波器效率的一个重要手段很少被研究,即随着时间的推移调整粒子的数量。文献“d.fox,w.burgard,f.dellaert,ands.thrun.montecarlolocalization:efficientpositionestimationformobilerobots.inproc.ofthenationalconferenceonartificialintelligence,1999.”中提出一种基于似然的方法来自适应粒子数,并将这种方法应用于机器人定位,具体地说,该方法不停地生成样本,直到非标准化的粒子权重之和超过预先指定的阈值,此方法的本质是:如果样本集与传感器的测量值一致,那么每个粒子的重要性权重都很大,而样本集仍然很小;然而,如果样本集与传感器的测量值有很大差异,单个粒子权重就会变小,样本集就会变大;这种方法的性能在一定程度上比固定粒子数的方法有所提升,然而,这种方法却没有充分发挥出调整样本集大小的潜力。最近,fox在文章“d.fox,adaptingthesamplesizeinparticlefiltersthroughkld-sampling,theint.journalofroboticsresearch22(12)(2003)985–1003.”中提出了一种基于kullback-leiblerdistance(kld)采样法来在线调整样本集的大小(以下称此方法为foxkld),实现了粒子滤波器的性能与复杂度的折中,并在各个领域得到了广泛的应用;然而,在fox的方法中采用了固定大小的容器,这可能会导致滤波初期粒子数的激增。
技术实现要素:
本发明的目的在于提出粒子滤波器的一种自适应粒子数方法,用于在估计过程中实时调整样本集的大小,以提高粒子滤波器的性能。
为实现上述目的,本发明采用的技术方案如下
一种粒子滤波器的粒子数自适应方法,其特征在于,包括以下步骤:
步骤1:在k时刻,计算粒子散布的范围:
当目标在x轴运动(一维):
sk=max{(2×3α11),(2×3α22)}=6max{α11,α22}
当目标在x-y平面运动(二维):
sk=max{(2×3α11)×(2×3α33),(2×3α22)×(2×3α44)}
=36max{α11α33,α22α44}
当目标在x-y-z平面运动(三维):
sk=max{(2×3α11)×(2×3α33)×(2×3α55),(2×3α22)×(2×3α44)×(2×3α66)}
=216max{α11α33α55,α22α44α66}
其中,
步骤2:在时刻k自适应调整容器大小δk:
其中,εk>0表示预先设定的kld的上限,参数λ满足条件:
步骤3:在时刻k,初始化期望粒子数
步骤4:根据当前粒子数和期望粒子数计算时刻k需要的粒子数
步骤5:更新期望粒子数:
其中,
步骤6:判断当前粒子数是否满足条件:
本发明的有益效果在于:
本发明提出的粒子滤波器的一种自适应粒子数方法具有如下优点
1.本发明提出的方法,利用kullback-leiblerdistance(kld)测量由粒子滤波器的采样表示引入的近似误差,进一步通过约束该误差,来实时调整所需要的粒子数,可实现粒子滤波器跟踪性能和算法复杂度的折中;
2.本发明提出的方法既适用于集中式粒子滤波算法,也适用于分布式粒子滤波算法,应用范围广;
3、本发明提出的方法与fox的方法相比,可以更快速地确定所需要的粒子数,有利于实现粒子数在线、实时地调整;
4、本发明提出的方法通过限制粒子数的上限以及下限值来自适应调整容器大小,与fox的方法相比,可以削弱滤波初期可能出现的粒子数激增的问题,并提升粒子滤波的稳态跟踪性能;
5、本发明提出的方法包含若干可调参数,可根据实际应用选择不同的参数值,有较强的灵活性;例如:粒子数上限
6、即使在实际先验知识匮乏的情况下,本发明提出的方法也可以通过设置合理的参数,自适应地调整所需的粒子的数目。
附图说明
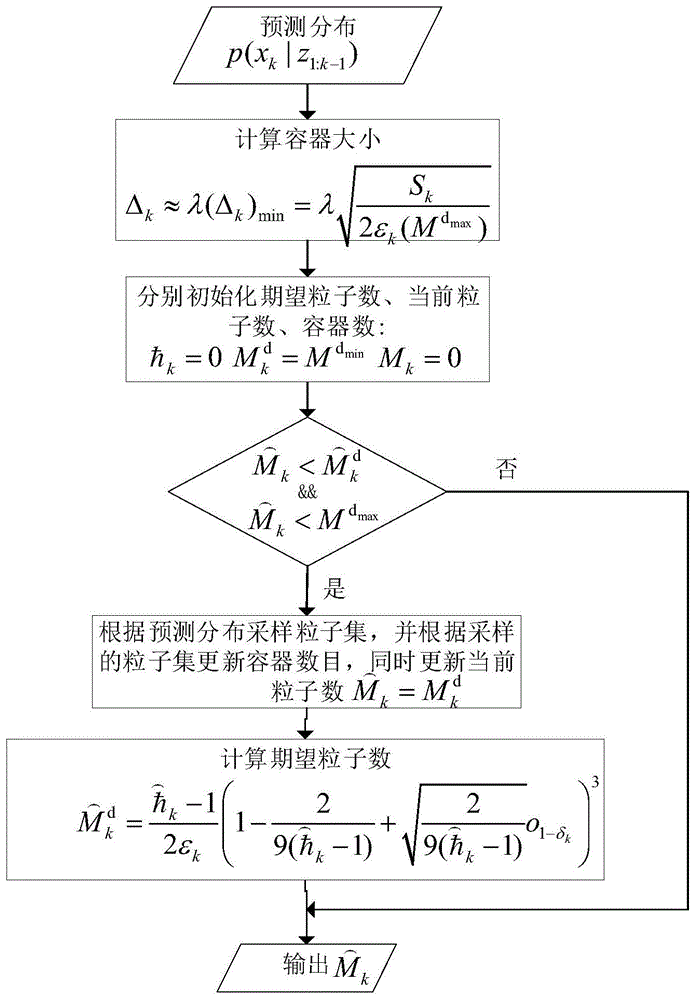
图1为实施例中采用本发明方法的粒子滤波算法实现结构图。
图2为实施例中正态分布的“3σ”原则说明图。
图3为实施例中网络拓扑结构(以网络中有15个节点为例)。
图4~图9为实施例中仿真结果图。
具体实施方式
下面结合附图对本发明作进一步说明:
本实施例中提供一种粒子滤波器的粒子数自适应方法,其流程如图1所示,由于粒子滤波器的基于采样的表示会引入近似误差,本发明为了约束该近似误差,用kld来测量该近似误差,定义真实分布和基于采样的最大似然估计之间的kld为:
其中,p(x)表示真实的后验分布,q(x)表示基于采样的最大似然估计;注意到,由于粒子滤波算法中真实的后验分布是未知的,本发明用基于粒子采样的预测分布来代替真实的后验分布。
具体步骤如下:
步骤1:在k时刻,设定目标在x-y平面运动(二维),
下面计算k时刻粒子散布的范围sk:本发明提取出粒子的协方差矩阵
sk=max{(2×3α11)×(2×3α33),(2×3α22)×(2×3α44)}
=36max{α11α33,α22α44}
若是目标在x-y-z平面运动(三维),则计算粒子散布的范围sk:
sk=max{(2×3α11)×(2×3α33)×(2×3α55),(2×3α22)×(2×3α44)×(2×3α66)}
=216max{α11α33α55,α22α44α66}
若是目标在x轴运动(一维),则计算粒子散布的范围sk;
sk=max{(2×3α11),(2×3α22)}=6max{α11,α22}
步骤2:通过限制粒子的数量,根据粒子状态空间的变化,在时刻k自适应调整容器大小δk,即跟踪初期,容器δk可以大一些,因为此时粒子分散范围较大,选择较大的δk可以有效地削弱粒子数;而随着跟踪逐渐达到相对稳定状态,δk可以小一些,因为此时粒子已经相对集中,采用更小的容器可以在一定程度上增加粒子数,进一步提升跟踪性能;
容器大小δk根据下式计算
其中,εk表示预先设定的kld的上限(εk>0),参数λ满足条件
步骤3:在时刻k,初始化期望粒子数
步骤4:根据当前粒子数和期望粒子数计算时刻k需要的粒子数
步骤5:更新期望粒子数,为了保证真实的预测分布与基于采样的最大似然分布之间的kld以1-δk的概率不超过上限εk,期望粒子数通过下式计算:
其中,
步骤6:判断当前粒子数是否满足条件:
需要说明的是:
根据步骤6中期望粒子数的更新公式:
另外说明的是:正态分布的“3σ”原则为:
数值分布在(μ-σ,μ+σ)中的概率为0.6827
数值分布在(μ-2σ,μ+2σ)中的概率为0.9545
数值分布在(μ-3σ,μ+3σ)中的概率为0.9973
在正态分布中σ代表标准差,μ代表均值;可以认为,y的取值几乎全部集中在(μ-3σ,μ+3σ)区间内,超出这个范围的可能性仅占不到0.3%。
下面通过将本发明方法(简称kld)和foxkld方法分别嵌入集中式粒子滤波和分布式粒子滤波的典型实施例,来说明本发明的可行性、优越性。
仿真1:采用包含15个节点的分布式网络,网络拓扑结构如图3所示,假定目标在x-y平面移动,具体仿真条件如下:将本发明方法(kld)嵌入一种基于时延和多普勒的集中式自适应粒子滤波直接跟踪问题(a.y.sidi,a.j.weiss,delayanddopplerinduceddirecttrackingbyparticlefilter,ieeetrans.aerosp.electron.syst.50(1)(2014)559–572.)中(以下简称其为cpfkld),将foxkld方法嵌入上述基于时延和多普勒的集中式自适应粒子滤波直接跟踪问题中(以下称其为cpffoxkld),与单独的cpf方法对比,网络中节点信噪比都设为0db,起始粒子数50个,蒙特卡罗实验100次,εk=0.2,为了进一步吻合我们的设计目标,λ设置为λ=1+0.99k;三者的位置误差仿真结果对比如图4所示,三者速度误差的仿真结果如图5所示,三者的粒子数随迭代次数变化结果如图6所示。
由图4、5可知,在集中式场景中,foxkld方法(即图中的cpffoxkld)相比单独的cpf方法,提高了位置的nrmse曲线的收敛速度,但稳态性能改进效果不显著,并且二者速度跟踪性能也很接近;而本发明提出的方法相比于cpffoxkld和单独的cpf,无论是位置还是速度的nrmse曲线的稳态性能均有大幅度提升;同时,相比单独的cpf方法,本发明提出的方法也提高了位置nrmse曲线的收敛速度。
由图6可见,在集中式场景中,foxkld方法在滤波的初期,粒子数有大幅度的激增,而本发明提出的方法可以有效地削弱滤波初期粒子数的激增,并且在滤波后期通过适当减小容器大小,进一步了提升粒子滤波的跟踪性能。
仿真2:采用包含15个节点的分布式网络,网络拓扑结构如图3所示,假定目标在x-y平面移动,具体仿真条件如下:将本发明方法(kld)嵌入一种基于时延和多普勒的分布式自适应粒子滤波直接跟踪定位方法(夏威,王岩岩,朱菊蕾.申请号:2017105840733.申请日期:2017.7.18.申请公布号:cn107367710a)中(以下简称为d-gpfkld),将foxkld方法嵌入上述基于时延和多普勒的分布式自适应粒子滤波直接跟踪定位方法中(以下简称为d-gpffoxkld),与单独的d-gpf方法对比。在分布式粒子滤波条件下,网络中节点信噪比都设为0db,起始粒子数50个;蒙特卡罗实验100次,εk=0.2,为了进一步吻合我们的设计目标,λ设置为λ=1+0.99k;三者的位置误差仿真结果对比如图7所示,三者速度误差的仿真结果如图8所示,三者的粒子数随迭代次数变化结果如图9所示。
由图7、8可见,在分布式场景中,foxkld方法(即图中的cpffoxkld)相比单独的d-gpf方法,虽然提升了位置的nrmse曲线的收敛速度,但对于其稳态性能的改进效果不显著,并且二者速度跟踪性能也很接近。而本发明提出的方法相比于d-gpffoxkld和单独的d-gpf,无论是位置还是速度的nrmse曲线的稳态性能均有大幅度提升。同时,相比单独的d-gpf方法,本发明提出的方法也提高了位置nrmse曲线的收敛速度。
由图9可见,在分布式场景中,foxkld方法在滤波的初始阶段,粒子数有大幅度的激增,而本发明提出的方法可以有效地削弱滤波初期粒子数的激增,并且在滤波后期通过适当减小容器大小,进一步提升了粒子滤波的跟踪性能。
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。
- 还没有人留言评论。精彩留言会获得点赞!