一种基于B树数据结构的MapReduce计算过程优化方法与流程
本发明属于mapreduce计算
技术领域:
,尤其涉及一种基于b树数据结构的mapreduce计算过程优化方法。
背景技术:
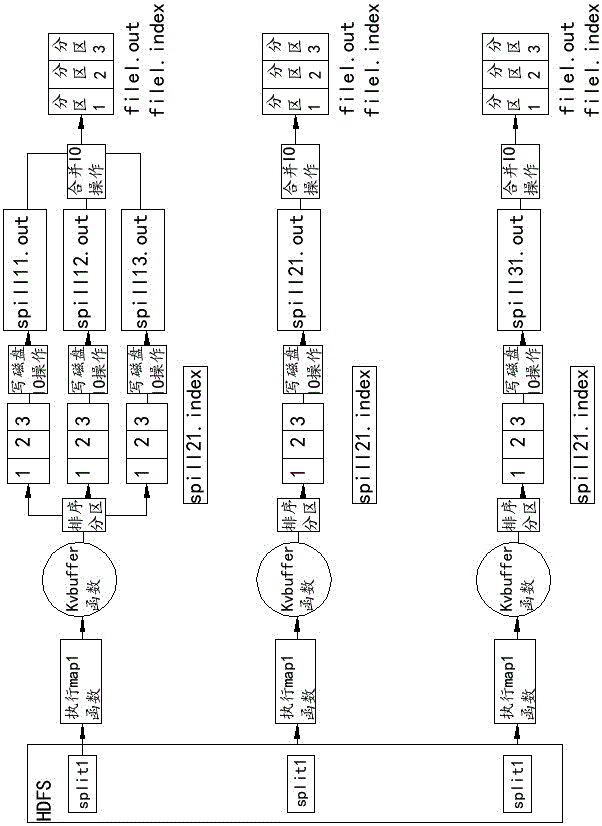
:mapreduce是一种分布式计算模型,是hadoop生态圈的主要组成之一,承担大批量数据的分布式计算功能。mapreduce包括两个重要的阶段:map阶段是映射,负责数据的过滤分发;reduce阶段是规约,负责数据的计算归并。map的输出即是reduce的输入,reduce需要通过shuffle来获取数据。在map过程中,每个输入分片(split)会分配给一个map任务来处理,默认情况下,以hdfs的一个块的大小(默认为64m)为一个分片。map过程的计算结果会暂时放在一个环形内存缓冲区中,当该缓冲区快要溢出时,会进行spill溢写操作,即在本地磁盘中创建两个文件:*.out和*.index保存内存数据。其中out文件保存了缓冲区中的数据,index文件是索引文件,使用起始位置、原始长度和压缩后长度三个字段来记录out文件中数据的详细位置信息。如果map任务输出数据量很大,可能会有很多的spill溢出文件,在生成out文件和合并操作的过程中都存在读写磁盘(io操作),耗时较长,工作效率低。技术实现要素:本发明旨在提供一种耗时短,可以有效提高工作效率的基于b树数据结构的mapreduce计算过程优化方法。为解决上述技术问题,本发明提供了如下的技术方案:一种基于b树数据结构的mapreduce计算过程优化方法,包括如下步骤:1)对输入到片区内的数据执行map任务;2)执行map任务后输出的结果包含索引文件*.index和数据文件*.out;3)将索引文件*.index和数据文件*.out存放在一个环形内存缓冲区中;4)当该环形内存缓冲区快要溢出时,判断是否是最后一个map任务;5)如果否,则数据文件*.out排序合并后写入磁盘,索引文件*.index留在环形内存缓冲区中;如果是,则数据文件*.out直接输入到reduce函数,索引文件*.index留在环形内存缓冲区中。索引文件*.index在环形内存缓冲区中以类b树的形式保存。数据文件*.out存入磁盘之前合并的过程不断地进行排序和压缩操作。判断该环形内存缓冲区是否快要溢出的标准为:当环形内存缓冲区存储量达到百分之八十时判断为快要溢出。在步骤5)数据文件*.out排序合并后写入磁盘之前需要根据reduce任务的数目将数据划分为相同数目的分区,一个reduce任务对应一个分区的数据。通过以上技术方案,本发明的有益效果为:1)将mapreduce计算过程中多个溢写到磁盘上的索引文件直接保存在环形内存缓冲区中,减少磁盘写操作;2)优化计算过程中数据文件*.out合并步骤,将原本需要从磁盘上读取索引文件再合并数据文件的操作优化为:直接从环形内存缓冲区中读取索引文件信息合并数据文件,从而减少磁盘读操作;3)内存中的索引文件以类b树的形式保存,使用子树来区分不同reduce过程所需数据,同时通过已排序的叶子节点来存储map过程产生的索引文件,reduce过程拷贝数据时可根据索引文件顺序拷贝,减少磁头反复寻址过程。附图说明图1为本发明所述的mapreduce计算过程;图2为类b树的索引文件示意图。具体实施方式一种基于b树数据结构的mapreduce计算过程优化方法,如图1所示,包括如下步骤:1)对输入到片区内的数据执行map任务;2)执行map任务后输出的结果包含索引文件*.index和数据文件*.out;3)将索引文件*.index和数据文件*.out存放在一个环形内存缓冲区中;4)当该环形内存缓冲区快要溢出时,判断是否是最后一个map任务,其中判断该环形内存缓冲区是否快要溢出的标准为:当环形内存缓冲区存储量达到百分之八十时判断为快要溢出。5)如果否,则数据文件*.out排序合并后写入磁盘,同时,数据文件*.out存入磁盘之前合并的过程会不断地进行排序和压缩操作,索引文件*.index留在环形内存缓冲区中,在合并的过程中不断地进行排序和压缩操作,以减少每次写入磁盘的数据量。如果是最后一个map任务,则数据文件*.out直接输入到reduce函数,索引文件*.index留在环形内存缓冲区中。其中,索引文件*.index在环形内存缓冲区中以类b树的形式保存,因为b树的叶子节点是按升序排序,同时map计算结果也是分区有序的,所以使用类b树结构方便存储map阶段的计算结果文件spill*.index文件,存储方便,存储起来比较有序,提高查找速度。由图2可知,索引文件以类b树形式保存,其中索引文件的类b树包含三层结构,第一层是根节点,第二层是根据map操作中的分区情况增加的子树节点,如分区1、分区2、分区n等,map计算过程中有多少个分区,这里就生成相等数量的子树节点。每一个map计算完成后将结果中的索引文件信息按照分区情况保存到响应的分区子节点中,并且每个分区的子节点都是升序排列,在进行合并操作时可以顺序读取磁盘文件,读头不需要频繁变更位置,提高数据读取效率。例如:map1线程产生多个*.index索引文件,其中属于分区1的索引文件有三个,三个索引文件的起始位置分别是1,2,3,则索引文件在b树种的位置如图2矩形框所示。本步骤中,数据文件*.out排序合并后写入磁盘之前需要根据reduce任务的数目将数据划分为相同数目的分区,一个reduce任务对应一个分区的数据。为了减少mapreduce计算时间消耗,提高框架计算效率,本发明改变map计算过程中spill*.index索引文件的存储方式,由磁盘存储优化为采用类b树结构的内存存储,减少map过程中spill溢写操作的磁盘写入次数和merge合并时索引文件的读取次数,从而加快map过程计算速度,进而提高程序的执行效率。测试分析:以写文件速度进行比较,分别比较传统io流和缓冲流写64m的数据进行测试。本次测试环境是jdk8,8g内存。分别测试5次后的耗时如表1所示:表1磁盘读写io操作耗时测试次数传统io流耗时(ms)缓冲流耗时(ms)137292345237588342336913490437772344537772341平均耗时37467.4372.4根据表1所示磁盘读写io耗时情况,计算使用本发明所述mapreduce计算1g数据节约的时间,每个split分片按照hdfs默认大小(64m),并且每个map计算只spill溢写一次。计算结果如表2所示:表2本发明所述mapreduce减少计算耗时读写1g数据减少io次数传统io流缩减耗时(ms)缓冲流缩减耗时(ms)测试结果1024/64=1616*37467.4=599478.416*372.4=5958.4由表2可以看出,理论上使用本发明所述mapreduce计算1g数据量时,如果采用传统io流方式可以缩减约600秒计算时长,采用缓冲流方式可以缩减约6秒计算时长。针对目前动辄tb甚至pb数量级的数据,使用本发明所述的mapreduce计算框架,可以显著缩短计算时间,提高计算效率。本发明所述的方法减少了磁盘读写次数,缩短了计算时间,显著缩短计算时间,提高了计算效率,可以有效提高工作效率。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1