一种分布式系统文件快速、准确迁移方法和装置与流程
本发明属于数据处理技术领域,具体地涉及到分布式系统文件迁移技术。
背景技术:
elasticsearch(es)是一种分布式可扩展的实时搜索和分析引擎,使用es可以实现多种功能,例如分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。es是一种实时分析的分布式搜索引擎,可以扩展到上百台服务器,处理pb(petabyte)级别的结构化或非结构化数据。
在新系统开发升级过程中有时候会需要进行数据迁移工作,由于分布式系统文件数据量极大,进行数据迁移耗时很长,并且存在着严重的数据丢失问题。
cn107943889a公开了一种数据库间的迁移方法及系统。首先,将第一数据库迁移到第二数据库,其次,将第二数据库迁移到第三数据库。cn108959470a公开了一种数据库数据跨平台迁移方法和装置,该方法包括:对于数据库数据的源端和数据库数据的目标端各自所在的平台环境进行扫描;根据扫描结果与迁移算法,生成迁移评估报告与建议的迁移方案;根据用户对建议的迁移方案的选择和迁移算法,生成迁移向导,其中,迁移向导提示用户采取相应的迁移方案,以实现跨平台半自动迁移数据库数据。
上述两个发明都不能实现既快又准确的进行数据迁移的目的,有必要针对分布式系统数据迁移进行改进。
技术实现要素:
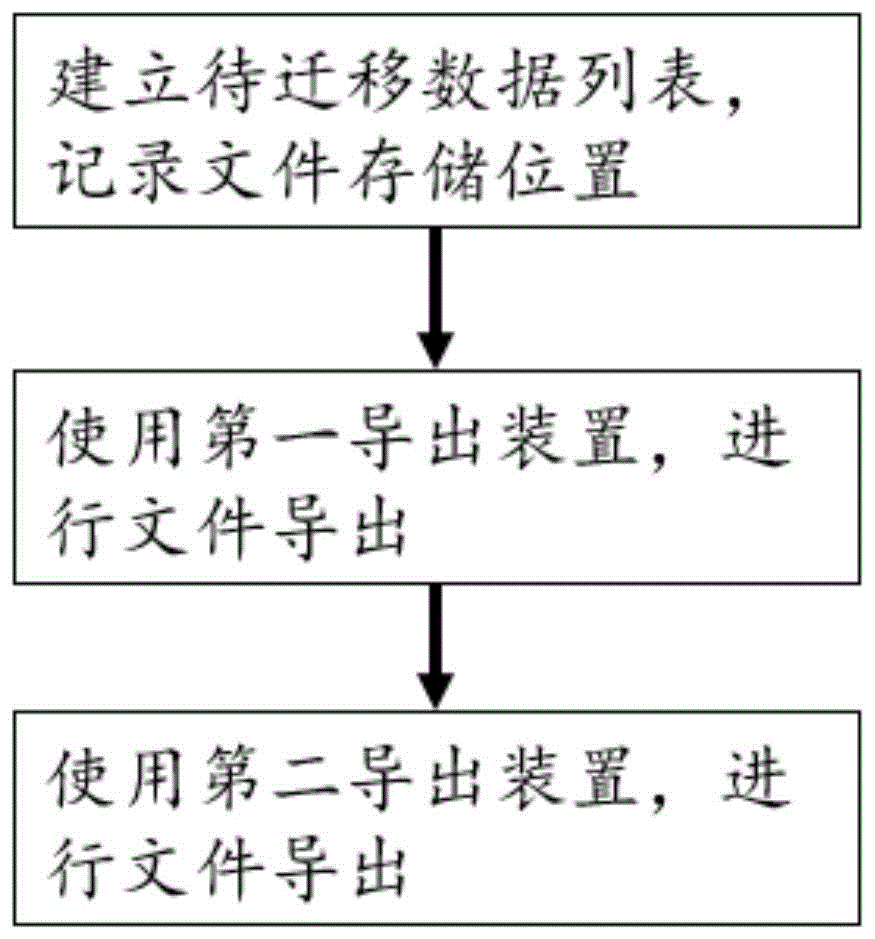
本发明涉及一种分布式系统文件快速、准确迁移方法,包括以下步骤:建立待迁移数据列表,记录文件存储位置;使用第一导出装置,进行文件导出;使用第二导出装置,进行文件导出。
还使用第三导出装置,进行文件导出。
针对第一导出装置导出的数据建立第一导出数据列表,比较第一导出数据列表和待迁移数据列表,生成第一导出差异数据列表;第二导出装置依据第一导出差异数据列表进行文件导出。
针对第二导出装置导出的数据建立第二导出数据列表,比较第二导出数据列表和待迁移数据列表,生成第二导出差异数据列表;第三导出装置依据第二导出差异数据列表进行文件导出。
使用第一导入装置,将第一导出装置导出的文件导入目标系统内;使用第二导入装置,将第二导出装置导出的文件导入目标系统内。
针对第一导入装置导入的数据,建立第一导入数据列表,比较第一导入数据列表和待迁移数据列表,生成第一导入差异数据列表;第二导入装置依据第一导入差异数据列表进行文件导入。
针对第二导入装置导入的数据建立第二导入数据列表,比较第二导入数据列表和待迁移数据列表,生成第二导入差异数据列表;第三导入装置依据第二导入差异数据列表进行文件导入。
数据列表生成装置,用于生成数据列表;导出装置,用于进行文件导出;控制装置,根据数据列表生成装置生成的数据列表决定文件的操作或者提示进行人工数据清理。
还包括导入装置;其中导出装置可以为多个,导入装置可以为若干个。
其中数据列表生成装置在导出或者导入完成后,进行数据列表生成;控制装置根据当前数据差异列表决定导入、导出或者提示进行人工数据清理。
本发明利用了不同的导出、导入装置在导出文件时的特性,设计了完整的数据迁移流程,在大幅节约时间的基础上,又提高了数据迁移的完整性和稳定性。此外,通过使用多个导出装置和多个导入装置,实现了数据快速导出和稳定、全面导出的兼顾;再者,通过对导出和导入数据的分析监控,实现分布式系统文件的完整、无遗漏的迁移。
附图说明
图1为本发明方法的流程图;
图2为本发明的装置示意图。
具体实施方式
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。本发明为了说明分布式数据库数据迁移的特点,下面将以elasticsearch为例,来说明本发明的基本构思和具体实施的细节方案。
在实际应用环境中,例如一个线上商城系统,用户需要搜索商城上的商品,可以用es存储所有的商品信息和库存信息,例如用户需要寻找“手机”产品,只需要输入“手机”就可以搜索到他需要搜索到的商品。例如,运行的系统需要收集日志,用这些日志来分析、挖掘从而获取系统业务趋势,就可以利用一些工具,例如logstash(elk中的一个产品,elasticsearch/logstash/kibana)收集、转换日志,并将他们存储到es中。一旦数据到达es中,就可以在里面搜索、运行聚合函数等操作来挖掘任何你感兴趣的信息。再比如,基于大量数据(数百万甚至数十亿的数据)进行快速调查、分析,就可以利用es来存储数据,并进行相应的调查、分析。总的来说es是一个企业级海量数据的搜索引擎。对es系统,在系统进行升级的过程中,需要进行数据迁移。由于es系统的数据量很大,迁移往往耗时很久,迁移过程的稳定性影响了迁移效率,并且迁移的数据常常出现完整性的问题。本发明解决了迁移过程中数据的完整性问题。
es系统数据迁移目前有几个工具,例如elasticdump\reindex\logstash,也可以是自行编写的其他数据迁移工具,根据不同的系统、数据库,不同的迁移工具会有不同的特点。其中elasticdump工具的特点是:单次启动时间较快;不过elasticdump存在部分数据无法导出的情况;存在丢失数据的情况。因此使用这个工具无法实现数据快速迁移。使用logstash工具进行导入,存在一些其他问题:logstash执行速度慢;如果要导入大量的数据,很容易造成失败,需要反复重试;导入的时间较慢。使用reindex也可以进行数据迁移,但是存在速度非常慢的问题;如果要迁移大量(10亿以上)的数据,可能最终需要的时间需要几十多天,相较使用logstash工具进行迁移更慢。
本发明将数据迁移过程整体上分为两个步骤,导出和导入。也即先将数据从系统完整导出,在完整导出后,利用工具再将数据完整导入到的新的系统中,从而最终实现数据的迁移。
参见图1,本发明首先进行elasticsearch系统全局范围的文件计算,从而建立待迁移数据列表,在数据列表中,记录文件的存储位置。通过建立数据列表,从而建立相对的数据参照标准,有了数据参照标准,在后续的数据迁移过程中,可以对照该待迁移数据列表,从而检查数据传输的完整性,决定下一步骤中需要传输的文件范围。
建立待迁移数据列表后,使用第一导出装置进行文件导出。第一导出装置可以是elasticdump,该工具存在的问题是部分数据无法导出,但是该工具导出速度较快,利用该工具,可以进行快速的文件导出。例如,利用elasticdump可以实现数据库文件量的95%的导出。利用elasticdump导出文件的同时或者导出后,对导出的文件建立数据列表。在第一导出装置进行导出的同时或者导出后,获得第一导出数据列表,该第一导出数据列表中记录了正确导出的文件信息,在第一导出装置导出结束后,对比第一导出数据列表和待迁移数据列表,可以获得第一导出差异数据列表。该第一导出差异数据列表内文件是第一导出装置elasticdump无法导出或者导出存在错误的文件,这部分文件占整个分布式系统文件量的比例并不大,但是该部分内容如果缺失,就意味着数据迁移工作失败。获得第一导出差异列表后,就可以使用第二导出装置,将第一导出差异列表内的数据进行导出。
第二导出装置可以是reindex或者logstash。这两种导出装置速度较第一导出装置慢,但是导出的正确率较高。第二导出装置针对第一导出差异列表内的文件进行导出,第二导出装置必须不同于第一导出装置,第一导出差异列表内的文件系第一导出装置无法导出或者导出失败的文件,使用容错率更高、速度较慢的导出装置,可以将第一导出差异列表内的文件大部分导出或者全部导出。在第二导出装置导出的同时或者导出后,获得第二导出装置导出的第二导出文件列表,结合待迁移文件列表和第一导出文件列表、第二导出文件列表,可以获得第二导出差异列表。第二导出差异列表可能为空,也即待迁移文件列表通过第一导出装置和第二导出装置导出后,已经全部导出完毕;第二导出差异列表也可能不为空,如果不为空,可以考虑采用手工方式进行数据清理,也可以继续使用第三导出装置进一步的导出。
第三导出装置可以是reindex或者logstash,但是不同于第二导出装置。利用第三导出装置,针对第二导出差异列表的文件进行导出,在导出同时或者导出完成后,生成第三导出文件列表。结合待迁移文件列表和第一导出文件列表、第二导出文件列表、第三导出文件列表,可以获得第三导出差异列表。获得第三导出差异列表后,明确当前未能成功导出的文件。此时,未能成功导出的文件数量通过人工清理进行清理。
采用分步导出的方式进行数据导出,大大节约了导出的时间。本发明利用了不同软件环境下导出装置导出速度和正确率的差别,导出速度快的工具正确率低,导出速度慢的工具正确率高。利用导出速度快的工具快速导出大量数据,再针对数据差异列表中的数据,使用正确率高的工具导出差异化数据,从而实现大量数据整体导出速度的提高。
数据导出完成后,进行数据迁移的第二步,也即数据导入。数据导入的过程类似于数据导出过程,同样是利用不同的工具导出速度和正确率的差别,实现数据的完整导入。
首先使用第一导入装置,将导出的文件导入目标系统内;针对第一导入装置导入的数据,建立第一导入数据列表,比较第一导入数据列表和待迁移数据列表,生成第一导入差异数据列表。接下来使用第二导入装置,针对第一导入差异数据列表进行数据导入,针对第二导入装置导入的数据,建立第二导入数据列表,综合第一导入数据列表、第二导入数据列表和待迁移数据列表,生成第二导入差异数据列表。根据第二导入差异数据列表的情况,决定是否使用第三导入装置进行数据导入。如果使用第三导入装置进行数据导入,还需要生成第三导入差异列表,针对该差异列表,判断是否需要进行人工数据清理。第一导入装置、第二导入装置和第三导入装置分别为不同的导入装置,其中第一导入装置为导入速度快的工具,第二和第三导入装置应当为导入数据准确且不同的导入装置。
参见附图2,本发明公开了一种分布式系统文件迁移装置,包括数据列表生成装置,用于生成数据列表,生成的数据列表可以是导出数据列表、导入数据列表、差异数据列表;数据列表生成后,可以根据数据列表情况,决定是否进行导出导入操作以及导出导入的具体范围。导出装置,包括第一导出装置、第二导出装置和第三导出装置,以上导出装置均用于进行文件导出。导入装置,包括第一导入装置、第二导入装置和第三导入装置,以上导入装置均用于进行文件导入。
控制装置,根据数据列表生成装置生成的数据列表决定导入、导出或者提示进行人工数据清理。一般来说,在第一导出/导入装置完成工作后,控制装置根据导出/导入情况,决定是否使用第二导入/导出装置进行数据导出/导入;在第二导出/导入装置完成工作后,控制装置决定是否进行第三导出/导入,或者控制装置提示进行人工数据清理。
以上内容是结合具体的优选技术方案对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!