一种分数阶C-支持向量机及其设计方法和应用与流程
本发明涉及libsvm工具箱中c-支持向量分类领域,尤其是一种分数阶c-支持向量机的设计方法、通过该设计方法设计得到的分数阶c-支持向量机,和利用分数阶c-支持向量机进行心脏病数据分类的方法。
背景技术:
rong-enfan,pai-hsuenchen,chih-jenlin在《workingsetselectionusingsecondorderinformationfortrainingsupportvectormachines》一文中公开了libsvm的c-支持向量分类方法。其包括以下流程:
1、选取拉格朗日乘子α的下标i,j
2、更新拉格朗日乘子α
当yi≠yj时,
当yi=yj时,
3、更新辅助变量
4、对法向量w和阈值b更新
5、确定分类结果
将w*,b*代入判别函数(如下),确定分类结果。
sign(wtφ(x)+b)
上述方法可以实现对数据的分类,但是,其结果属于整数阶导层次,分类精度不高。
技术实现要素:
本发明的发明目的在于:针对上述存在的问题,提供一种分数阶c-支持向量机的设计方法、利用该设计方法设计出的分数阶c-支持向量机,和利用分数阶c-支持向量机进行心脏病数据分类的方法。以实现对数据的高精确度分类。为心脏病确诊提供可靠数据支撑。
本发明采用的技术方案如下:
一种分数阶c-支持向量机的设计方法,分数阶c-支持向量机的分数阶梯度向量设计为:
ψ(v)(α)=b0α1-vqα-eb0α1-v
其中,
q为n乘n阶对称矩阵,qij=yiyjk(xi,xj),其中k(xi,xj)是核函数,i、j代表下标,y是数据点集的标签,在二分类中,其取值定义为+1或-1;
ψ(α)表示目标函数的对偶形式,ψ(v)(α)表示目标函数的对偶形式的分数阶梯度;
α是拉格朗日乘子,在smo算法中是一个约束条件,其约束范围是0<αi<c,c>0称为惩罚参数;
n表示数据点集的个数;
所述分数阶c-支持向量机的设计方法包括:
a.选取向量机的拉格朗日乘子α的下标i,j的步骤;
b.更新步骤a中的拉格朗日乘子α的步骤;
c.根据步骤b中所更新的拉格朗日乘子α,更新分数阶导数集合的步骤;
d.根据步骤c中所更新的分数阶导数集合,更新法向量w和阈值b的步骤;和
e.将步骤d中所更新的法向量w和阈值b带入判别函数,确定出分类结果。
通过上述方法的设计结果对数据进行分类,可以实现对数据的分数阶导分类,其分类结果较整数阶导更为精确,分类准确度更高。
进一步的,所述步骤a中选取向量机的拉格朗日乘子α的下标i,j的方法为:
iup(αk)和对应的ilow(αk),是关于αt下标t的集合
对于α的下标i的选取使用的是firstorder的方法,对j的选择除需要满足违反对,还需要使目标函数减少最多,根据泰勒公式将目标函数在αk处展开,假设αk每次的偏移量都是d,其中d=(d1,d2,…,dn)。
进一步的,所述步骤b更新数据的方法为:
当yi≠yj时,
当yi=yj时,
进一步的,所述步骤c更新数据的方法为:
其中,c>0称为惩罚参数。其由问题决定,c值大时对误分类的惩罚增大,c值小时对误分类的惩罚减小。libsvm为了加速运算设置了一个集合g-bar,g-bar是目标函数的分数阶导数的集合。smo算法的一个核心就是对α的更新。拉格朗日乘子在训练的过程中,α_i会经过多次迭代,这时候一部分α_i就会落到边界上,即α_i=0或α_i=c。此时α的值落在边界上不会发生改变,所以把此时的状态称为inactive。对那些处于0和c之间α_i的状态称为active。
进一步的,所述步骤d更新数据的方法为:
假设给定一个特征空间上的训练数据集为,
t={(x1,y1),(x2,y2),…,(xn,yn)}
其中,xi∈x=rn,yi∈y={+1,-1},i=1,2,…,n,xi为第i个特征向量,也称为实例,yi为xi的类标签,当yi=+1时,称为正例;当yi=-1时,称为负例,(xi,yi)称为样本点。超平面函数(判别函数)定义为:
f(x)=wtx+b=0
其中,w是法向量,b为阈值(偏移量)
w*在此表示法向量的最优值。
b*表示阈值(偏移量)的最优值。理论上b*的值是不定的,当程序达到最优后,用任意一个标准支持向量机0<αi<c的样本带入计算公式,得到的b*都是可以的。求取b*的方法有很多,libsvm采取了更为鲁棒的方法求,求所有支持向量的平均值。
设
本发明提供了一种分数阶c-支持向量机,其通过上述的分数阶c-支持向量机的设计方法设计而成。
本发明的分数阶c-支持向量机的分类效果具有高精确度和高准确度的特点。
本发明提供了一种心脏病数据分类方法,该心脏病数据分类方法采用上述的分数阶c-支持向量机对心脏病数据进行分类。
通过分数阶c-支持向量机对心脏病数据进行分析,可以得到较整数阶分类精确度更高的结果,以为心脏病的诊断提供更加准确的数据支撑。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
1、本发明对于分数阶c-支持向量机的设计和优化方法非常简单,仅需在现有方案基础上进行少量修改即可得到预期效果。
2、本发明的向量机可实现对数据的分数阶次导数的分类,使得对于数据的分类结果更加精确。
3、本发明的心脏病数据分类方法可以对心脏病数据进行高准确率分类,进而为心脏病的诊断提供准确的数据支撑。
附图说明
本发明将通过例子并参照附图的方式说明,其中:
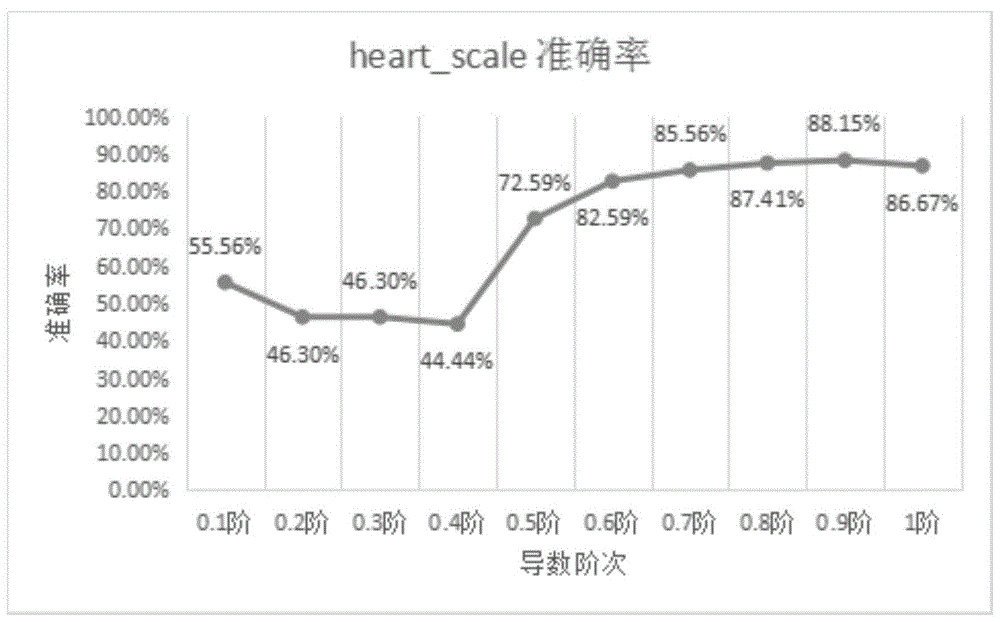
图1是利用本发明的分数阶c-支持向量机对heart_scale进行分类的准确率示意图。
图2是smo算法流程图。
具体实施方式
本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。
本说明书(包括任何附加权利要求、摘要)中公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换。即,除非特别叙述,每个特征只是一系列等效或类似特征中的一个例子而已。
实施例一
本实施例公开了一种分数阶c-支持向量机的设计方法,分数阶梯度向量设计为:
ψ(v)(α)=b0α1-vqα-eb0α1-v
其中,
q是一个n乘n对称矩阵,qij=yiyjk(xi,xj),其中k(xi,xj)是核函数;i、j代表的是下标;
ψ(α)表示目标函数的对偶形式,ψ(v)(α)表示目标函数的对偶形式的分数阶梯度;
α是拉更朗日乘子,在smo算法中对是一个约束条件,其约束范围是0<αi<c;
y是数据点集的标签,在二分类中一般定义为±1;
n是数据点集的个数。
向量机设计方法包括以下步骤:
a.选取向量机的拉格朗日乘子α的下标i,j。
iup(αk)和ilow(αk),是关于αt下标t的集合
对于α的下标i的选取使用的是firstorder的方法,对j的择除需要满足违反对还需要使目标函数减少最多,根据泰勒公式将目标函数在αk处展开,即αk为展开点,假设αk每次的偏移量都是d,其中d=(d1,d2,…,dn)。
b.更新向量机的拉格朗日乘子α。
当yi≠yj时,对于
对于
当yi=yj时,对于
对于
所以:
当yi≠yj时,
当yi=yj时,
c.更新分数阶导数集合。
这里,c>0称为惩罚参数,一般由问题决定,c值大时对误分类的惩罚增大,c值小时对误分类的惩罚减小。libsvm为了加速运算设置了一个集合g-bar,g-bar是目标函数的分数阶导数的集合。smo算法的一个核心就是对α的更新,smo算法流程如图2所示。拉格朗日乘子在训练的过程中,αi会经过多次迭代,这时候一部分αi就会落到边界上,即αi=0或αi=c。此时α的值落在边界上不会发生改变,所以把此时的状态称为inactive。对那些处于0和c之间αi的状态称为active。
d.更新法向量w和阈值b。
当0<αi<c时,
将目标函数表示成分数阶拉格朗日函数为
smo算法以kkt条件为基础,总的来说包括约束条件(原始约束和拉格朗日乘子约束)、求偏导等于0、对偶互补条件,其流程如图2所示。根据kkt的对偶互补条件,
当0<αi<c时,
变形后有:
等式两边同时除以
假设给定一个特征空间上的训练数据集为
t={(x1,y1),(x2,y2),…,(xn,yn)}
其中,xi∈x=rn,yi∈y={+1,-1},i=1,2,…,n,xi为第i个特征向量,也称为实例,yi为xi的类标签,当yi=+1时,称为正例;当yi=-1时,称为负例,(xi,yi)称为样本点[1]。超平面函数(判别函数)定义为:
f(x)=wtx+b=0
其中,w是法向量,b为阈值(偏移量)。
当0<αi<c时,η=b,所以,
在libsvm工具箱中提取所有支持向量机,因为在对偶优化问题的解α*获得之后,变量b必须被计算出来,在决策函数中将被用到。b*表示阈值(偏移量)的最优值。理论上b*的值是不定的,当程序达到最优后,用任意一个标准支持向量机0<αi<c的样本带入计算公式,得到的b*都是可以的。求取b*的方法有很多,libsvm采取了更为鲁棒的方法求,即所有支持向量的平均值。实践中,为了得到对b*更稳健的估计,也是采用求取平均值的方式,得到:
即得到:
w*表示法向量的最优值,
w*在支持向量机中,对拉格朗日函数
求w的偏导令其等于0,即可求得。
e.确定分类结果。
将w*,b*代入判别函数sign(wtφ(x)+b),确定分类结果。
通过上述方法,即可设计出分数阶c-支持向量机,较整数阶c-支持向量机,分类精度更高。
实施例二
本实施例公开了一种分数阶c-支持向量机,其由实施例一中的设计方法设计而成。
实施例三
本实施例公开了对实施例二的向量机的验证过程。
对uci中statlog(heart)dataset所含有的270个13维样本数据进行分类,其中有150个标签为-1的负例,120个标签为+1的正例。使用libsvm默认参数(
-ssvm类型:svm设置类型(默认0)
-t核函数类型:核函数设置类型(默认2)
-ddegree:核函数中的degree设置(针对多项式核函数)(默认3)
)下,采用整数阶c-支持向量分类方法的准确率为86.67%,使用本发明的分数阶c-支持向量机进行分类的准确率为:
通过上表可知,1阶导时,正确分类率是86.67%;0.8阶时,正确分类率是87.41%;0.9阶时,正确分类率是88.15%。通过对比发现0.8阶导和0.9阶导的分类效果均比1阶导的分类准确。
本实施例的另一验证方式为:以libsvm工具箱中的heart_scale.mat数据集作为测试集。其包含270个13维样本,其中有150个标签为-1的负例,120个标签为+1的正例。根据上述设计方法的流程,使用visualstudio2017对libsvm工具箱的svm.cpp文件的源代码进行对应修改,再使用matlab2017编译修改后的libsvm工具箱,对heart_scale.mat数据集进行0.1-1阶分类,分类结果如图1所示。
由图1可以发现,在各参数的选取上,分数阶c-支持向量分类算法较整数阶c-支持向量分类算法的取值范围更大,在精确度方面,分数阶c-支持向量分类算法要强于整数阶c-支持向量分类算法。
实施例四
本实施例公开了一种基于上述分数阶c-支持向量机的心脏病数据分类方法,其具体为采用所述分数阶c-支持向量机对心脏病数据进行分类。
本发明并不局限于前述的具体实施方式。本发明扩展到任何在本说明书中披露的新特征或任何新的组合,以及披露的任一新的方法或过程的步骤或任何新的组合。
- 还没有人留言评论。精彩留言会获得点赞!