基于卷积神经网络的水泥原料立磨生料细度指标预测方法与流程
本发明涉及水泥生产生料细度预测领域,尤其涉及到一种基于卷积神经网络的水泥原料立磨生料细度指标预测方法
背景技术:
水泥生料立磨粉磨是水泥生产过程的重要生产环节和典型耗能环节。生料细度是反映生料粉磨质量的重要指标,当生料细度过细时,会使水泥产量下降,而过细的生料粉末对产品质量的提升极为有限,从而造成能源的浪费;当生料过粗时,会使后续回转窑烧成过程中的游离氧化钙含量过高,对成品的质量产生影响。所以,生料细度的粗细程度对水泥产量和质量极为关键,是实现水泥高产量,高效益的重要因素。水泥生料立磨粉磨生产过程具有非线性、强耦合、时滞性等特点,难以实现生料细度的实时预测。针对上述问题,有学者采用了不同的算法来研究生料细度的软测量模型。现有技术中,有一种方法采用基于最小支持向量机的方法对生料细度进行在线预测,但是最小二乘支持向量机适合小数据样本,并且需要进行复杂的数据清洗工作。还有采用基于elm(极限学习机)的方法对生料细度及磨内压差同时进行在线预测,但是该模型由于自身局限性难以解决生料细度预测存在的时变时延问题,因此在解决时变时延问题的同时进行在线的预测,显得尤为重要。
技术实现要素:
为了克服现有技术的不足,本发明提供了一种基于卷积神经网络(convolutionneuralnetwork,cnn)的水泥原料立磨生料细度指标在线预测方法,解决了水泥生料生产过程中变量数据与生料细度指标之间的时变时延问题,同时避免了复杂的时序匹配和数据清洗工作。
为实现上述目的,本发明是根据以下技术方案实现的:
一种基于卷积神经网络的水泥原料立磨生料细度指标预测方法,包括以下步骤:
步骤1:选取与生料细度相关的8个输入变量,对选取后的变量数据进行归一化处理,构建8个变量时间序列输入层,同时对归一化后的变量数据进行时间序列的处理;
步骤2:对输入的变量数据进行卷积池化及全连接运算,首先对输入数据进行卷积运算,并对经过卷积运算的输入数据进行池化,经过多次卷积池化后对输出数据进行全连接操作,再经过droupout层处理完成对卷积神经网络预测模型前向训练的过程;其中,droupout层是为了防止训练过程出现过拟合现象。
步骤3:卷积神经网络模型采用反向传播技术更新权值参数以提高生料细度预测精度,通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率,更新卷积层的权值和偏置,完成对网络的参数微调,使生料细度模型的预测误差小于设定阈值,完成卷积神经网络模型训练;
步骤4:利用训练好的cnn模型对水泥原料立磨生料细度指标进行实时预测。
上述技术方案中,在步骤1中根据生产过程选取8个与生料细度相关的关键控制因素作为输入变量,输入变量包括回渣皮带电流、回渣斗提电流、主机电流、喂料反馈、磨机压差、阀门开度反馈、磨机出口温度、磨机入口负压,采用时间序列来处理归一化后的输入变量数据,确定涵盖所有变量时延区间的时间范围,将该时间范围内的变量数据作为输入,使其对应于某一时刻的生料细度指标,其处理过程如下:
确定包含各变量时延的时间区间,构建时间序列输入层,将一个时间区间内各变量数据对应于某一时刻的生料细度,使输入层包含各变量与生料细度指标的耦合关系,设时间区间为n,将8个变量按行依次输入构成矩阵,由生料细度预测模型选取的8个输入变量构成的时间序列表示为:
x=(x1,x2,....,x8)(1)
式(1)中每个过程变量时间序列包含t个采样点:
xi=(xi(1),xi(2),...,xi(t))(2)
其中,xi(i=1,2,...,8)为第i个过程变量的时间序列。
上述技术方案中,步骤2具体包括如下过程:
输入层的数据矩阵通过卷积层提取数据特征,根据水泥数据变量之间的特性,采用一维卷积核,使用n1个卷积核对输入数据进行卷积计算,该过程权值共享,得到n1个不同的特征图,设卷积层为第l层,则该层输出神经元的输入zl和卷积层的输出xl的表达式分别为式(3)和式(4):
zl=xl-1*wl+bl(3)
式中,xl-1代表卷积层输入的特征向量,wl代表一维卷积核,bl表示输出特征向量对应的偏置;
xl=f(zl)(4)
式中f(·)为激活函数,为提高模型的非线性能力,使用relu函数作为激活函数,其表达式为:
f(x)=max(0,x)(5)
根据水泥数据的特性,采用平均池化使模型具有更好的学习能力,池化层不含激活函数,池化层的输出神经元的输入al+1与池化层输出pl+1相等,第l+1层池化层输入pl与输出pl+1之间的关系表示为:
式中,
全连接层的输入为卷积池化过程得到的所有特征值,经过该层整合所有的特征信息,该层的输入xk-1与输出yk-1之间的关系表示为:
yk-l=f(wk-1*xk-1+bk-1)(7)
式中wk-1,bk-1分别为全连接层的权值和偏置;
防止训练过程出现过拟合现象,在全连接层之后加入dropout层,提升网络模型的泛化能力,dropout率设置为0.5;
输出层采用线性加权求和直接计算生料细度值,设该层权值和偏置分别为wk和bk,则输入xk与输出生料细度值y′之间的计算公式为:
y′=wkxk+bk(8)。
上述技术方案中,步骤3采用反向微调的方法更新权值和偏置,在反向微调过程中,首先按照反向传播算法求得各层的误差灵敏度δ,然后根据误差灵敏度实现参数更新,输出层、全连接层、与全连接层相连的卷积层和池化层的误差灵敏度均由bp算法得到,卷积层与池化层相连时的反向传播算法如下:
卷积层到池化层的反向传播过程中,设第l层为池化层,后接卷积层第l+1层时,池化层的误差灵敏度δl计算如式(9)所示,其中,池化层输出神经元的输入al和输出pl相等,
其中,zl+1=pl*wl+1+bl+1(10)
式(9)中,δl+1表示l+1层的误差灵敏度,zl+1是卷积层输出神经元的输入,rot180(·)表示旋转180度;
池化层到卷积层的反向传播过程中,当第l-1层卷积层之后连接第l层池化层时,卷积层的误差灵敏度计算方式为:
其中,
式中,zl-1为卷积层输出神经元的输入,xl-1为卷积层的输出,同为池化层的输入,al为池化运算的结果,up(·)完成了池化误差数组放大与误差重新分配,其数组大小与卷积之后的大小保持一致,f′(·)为激活函数的导数;
由式(11)得到卷积层的误差灵敏度后,卷积核梯度和偏置梯度计算过程如式(13)和式(14),
式中,xl-2是卷积过程中与卷积核wl-1做卷积运算的特征值;
分别根据式(15)和式(16)对卷积核w和偏置b进行更新;
wl-1=wl-1-μ*δwl-1(15)
bl-1=bl-1-μ*δbl-1(16)
式中,μ表示网络的学习率。
本发明与现有技术相比,具有如下有益效果:
本发明建立的水泥原料立磨生料细度预测模型,针对输入变量数据与预测指标之间存在的时变时延问题,采用时间序列的方法构建输入层,即确定一个包含各变量时延的区间,并将该区间的变量数据对应于某一时刻的生料细度值,从而消除了各变量变时延对生料细度预测的影响。
本发明建立的水泥原料立磨生料细度指标预测模型,避免了复杂的数据清洗和时序匹配问题,简化了模型复杂度,同时采用反向传播技术更新权值参数以进一步提高预测精度,为提高水泥的产量和质量提供了依据。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
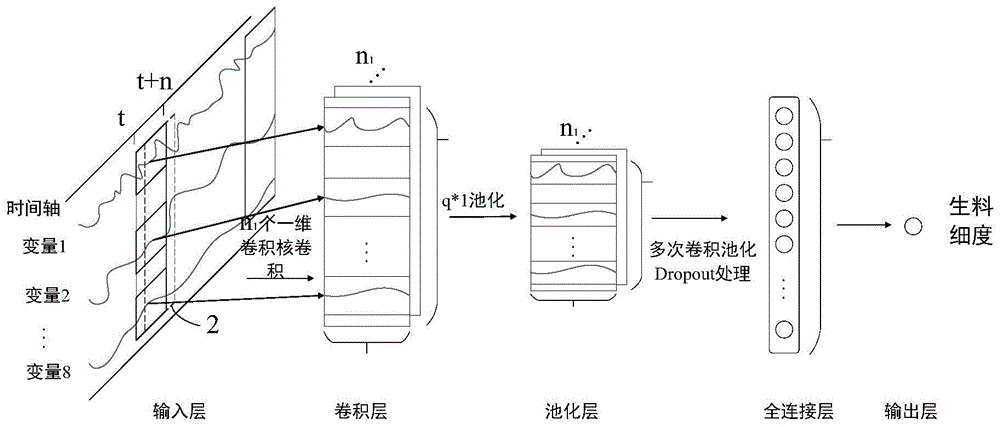
图1为本发明提出的基于卷积神经网络的水泥原料立磨生料细度指标预测模型结构图;
图2为本发明提出的cnn模型预测水泥原料立磨生料细度指标的系统流程框图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
本发明提出了一种基于卷积神经网络的水泥原料立磨生料细度指标预测方法,首先从水泥生料磨系统数据库中提取与生料细度相关的8个输入变量数据,根据输入变量与输出变量之间的时延关系,构建时间序列输入层,对模型进行前向训练,并采用反向传播技术对权值进行微调。图1所示为建立的生料细度指标预测模型的具体结构示意图。图2所示为基于卷积神经网络的水泥原料立磨生料细度指标预测模型流程图。
根据本发明的一个具体实施例,其预测方法包括如下步骤:
步骤1:提取与生料细度指标相关的8个输入变量数据,对提取的变量数据进行归一化处理,将处理后的变量数据按时间序列排列作为输入数据,避免了输入变量与输出预测值之间时序匹配问题,简化了模型结构。
如图1所示,在步骤1中根据实际生产过程选取8个与生料细度相关的关键控制因素作为输入变量,本分别是:回渣皮带电流x1、回渣斗提电流x2、主机电流x3、喂料反馈x4、磨机压差x5、阀门开度反馈x6、磨机出口温度x7、磨机入口负压x8,采用时间序列来处理归一化后的输入变量数据,确定涵盖所有变量时延区间的时间范围,将该时间范围内的变量数据作为输入,使其对应于某一时刻的生料细度指标,避免了复杂的数据清洗与时序匹配操作,处理过程如下:
确定包含各变量时延的时间区间,构建时间序列输入层,将一个时间区间内各变量数据对应于某一时刻的生料细度,使输入层包含各变量与生料细度指标的耦合关系,设时间区间为n,将8个变量按行依次输入构成矩阵,由生料细度预测模型选取的8个输入变量构成的时间序列表示为:
x=(x1,x2,....,x8)(1)
式(1)中每个过程变量时间序列包含t个采样点:
xi=(xi(1).xi(2),...,xi(t)(2)
其中,xi(i=1,2,...,8)为第i个过程变量的时间序列。
步骤2:对输入的变量数据进行卷积池化及全连接运算,首先对输入数据进行卷积运算,并对经过卷积运算的输入数据进行池化,经过多次卷积池化后对输出数据进行全连接操作,再经过droupout层处理完成对卷积神经网络预测模型前向训练的过程,具体包括如下过程:
输入层的数据矩阵通过卷积层提取数据特征,根据水泥数据变量之间的特性,采用一维卷积核,使用n1个卷积核对输入数据进行卷积计算,该过程权值共享,得到n1个不同的特征图,设卷积层为第l层,则该层输出神经元的输入zl和卷积层的输出xl的表达式分别为式(3)和式(4):
zl=xl-1*wl+bl(3)
式中,xl-1代表卷积层输入的特征向量,wl代表一维卷积核,bl表示输出特征向量对应的偏置;
xl=f(zl)(4)
式中f(·)为激活函数,为提高模型的非线性能力,使用relu函数作为激活函数,其表达式为:
f(x)=max(0,x)(5)
cnn模型中池化层的作用是减少特征数据,简化网络计算复杂度。根据水泥数据的特性,采用平均池化使模型具有更好的学习能力,池化层不含激活函数,池化层的输出神经元的输入al+1与池化层输出pl+1相等,第1+1层池化层输入pl与输出pl+1之间的关系表示为:
式中,
全连接层的输入为卷积池化过程得到的所有特征值,经过该层整合所有的特征信息,该层的输入xk-1与输出yk-1之间的关系表示为:
yk-1=f(wk-1*xk-1+bk-1)(7)
式中wk-1,bk-1分别为全连接层的权值和偏置;
防止训练过程出现过拟合现象,在全连接层之后加入dropout层,提升网络模型的泛化能力,dropout率设置为0.5;
输出层采用线性加权求和直接计算生料细度值,设该层权值和偏置分别为wk和bk,则输入xk与输出生料细度值y′之间的计算公式为:
y′=wkxk+bk(8)
步骤2中,对输入层的变量数据进行不同方向的卷积,其中纵向卷积提取变量间特征,横向卷积提取同一变量不同时刻的数据特征,并且在每次卷积计算后进行池化运算,以减少运算参数。预测模型按照从卷积层与池化层到卷积层与池化层,再到全连接层的顺序设计结构,卷积层对输入的时间序列数据进行卷积计算,卷积过程权值共享,池化过程减少特征数据,简化网络计算复杂度,全连接层整合所有信息输出全连接层神经元,droupout层的设计是为了防止训练过程中出现过拟合现象,最后由输出层输出预测值。
步骤3:卷积神经网络模型采用反向传播技术更新权值参数以提高生料细度预测精度,通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率,更新卷积层的权值和偏置,完成对网络的参数微调,使生料细度模型的预测误差小于设定阈值,完成卷积神经网络模型训练;
步骤3采用反向微调的方法更新权值和偏置,在反向微调过程中,首先按照反向传播算法求得各层的误差灵敏度δ,然后根据误差灵敏度实现参数更新,输出层、全连接层、与全连接层相连的卷积层和池化层的误差灵敏度均由bp算法得到,卷积层与池化层相连时的反向传播算法如下:
卷积层到池化层的反向传播过程中,设第l层为池化层,后接卷积层第l+1层时,池化层的误差灵敏度δl计算如式(9)所示,其中,池化层输出神经元的输入al和输出pl相等,
其中,zl+1=pl*wl+1+bl+1(10)
式(9)中,δl+1表示l+1层的误差灵敏度,zl+1是卷积层输出神经元的输入,rot180(·)表示旋转180度;
池化层到卷积层的反向传播过程中,当第l-1层卷积层之后连接第l层池化层时,卷积层的误差灵敏度计算方式为:
其中,
式中,zl-1为卷积层输出神经元的输入,xl-1为卷积层的输出,同为池化层的输入,al为池化运算的结果,up(·)完成了池化误差数组放大与误差重新分配,其数组大小与卷积之后的大小保持一致,f′(·)为激活函数的导数;
由式(11)得到卷积层的误差灵敏度后,卷积核梯度和偏置梯度计算过程如式(13)和式(14),
式中,x1-2是卷积过程中与卷积核wl-1做卷积运算的特征值;
分别根据式(15)和式(16)对卷积核w和偏置b进行更新;
wl-1=wl-1-μ*δwl-1(15)
bl-1=bl-1-μ*δbl-1(16)
式中,μ表示网络的学习率。
步骤4:利用训练好的cnn模型对水泥原料立磨生料细度指标进行实时预测。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!