一种基于图熵的社交网络推荐方法与流程
本发明涉及一种推荐系统。
背景技术:
随着信息技术和互联网的发展,信息过载的问题日益严重,如何从海量的数据中快速准确地获取有价值的信息成为社会发展的关键问题。推荐系统作为解决信息过载的重要途径之一,可以很好的满足用户的需求,受到越来越多的关注。它是建立在海量数据挖掘基础上的一种高级商务智能系统,为用户提供了完全个性化的决策支持和信息服务,使人们更加受益于互联网、大数据。
个性化推荐系统是根据用户的历史行为和购买记录等信息,构建针对具体用户的个性化用户特征,将商品进行筛选,推荐给与用户特征相近的商品。目前,个性化推荐系统已经在互联网的各个领域得到了广泛的应用,如亚马逊,淘宝等电子商务领域,今日头条等新闻领域,网易云音乐等音乐领域,netflix、豆瓣等电影领域都在使用推荐算法。
目前个性化推荐系统方法主要有基于规则的推荐、协同过滤推荐、基于内容的推荐、基于网络的推荐和混合推荐系统等。其中基于网络的推荐是一种比较重要的推荐策略,不考虑用户和产品的内容特性,而把它们看成抽象的节点,将用户的行为信息表示成图的形式,算法利用的所有信息都藏在用户和物品的选择关系当中,并有效缓解了数据稀疏性所带来的不良影响。
在推荐系统领域,早期的工作主要围绕协同过滤和历史信息做推荐,特别是矩阵分解在很多应用中展示出了巨大效果。基于图的推荐是一种比较直观和灵活的推荐算法,通过在二分图上展开随机游走算法,得到与目标用户最为相似的物品,但是存在着数据稀疏和冷启动的问题,导致推荐性能下降。后来提出基于社交网络结构的推荐,但大多数只考虑了相似邻居集而忽略了用户对物品的多反馈信息,于是引入了用户好友信息,在一定程度上能够缓解冷启动问题,但算法性能依旧不好,仍存在着数据稀疏的问题。
技术实现要素:
本专利提供一种基于图熵的社交网络推荐方法,将用户对物品的多反馈信息和社交网络用户信任度融合到图推荐算法当中,且考虑利用图熵对用户物品相似度进行加权以获得最终的用户物品相似度,从而提高推荐性能,以获得更个性化的推荐结果。技术方案如下:
一种社交网络中基于图熵的推荐方法,包括下列步骤:
(1)结合用户对物品的评分数据以及一些反馈信息,首先对已有数据集进行预处理,对于重复和异常的数据进行清洗和删除;
(2)利用一个无向图构建用户-物品二分图(uig),通过用户对物品的点击、收藏和搜索等反馈信息计算用户与物品边上的权重,以确定用户物品的相似度;根据数据集构建用户信任图(utg),并由用户在社交网络上的信任传播距离计算用户信任度,以获得信任的用户物品相似度;
(3)对于上述两个无向图,采用随机游走策略,不断地对步骤(2)中的相似度进行计算迭代更新,得到用户对物品相似度的收敛值;
(4)通过计算用户-物品图和用户信任图的熵获得加权系数,从而得到用户对物品相似度的最终值;
(5)进行top-n项排序,将候选集中相似度最高的商品推荐给用户。
附图说明
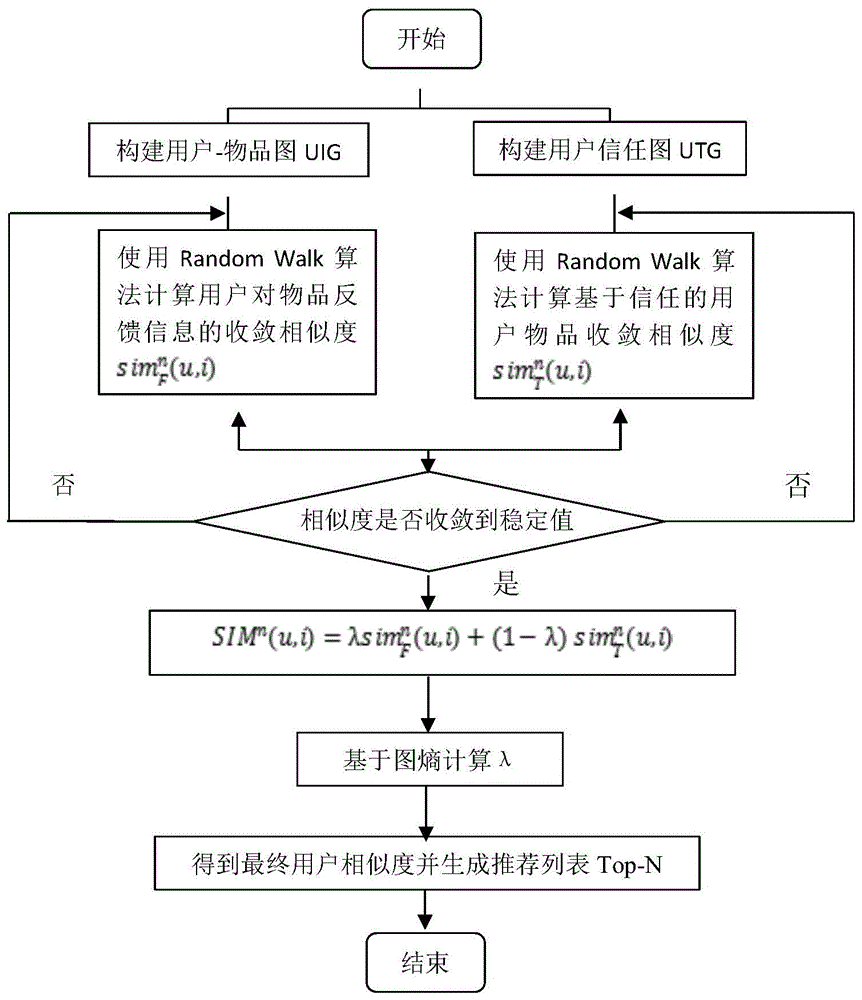
图1本发明的程序流程图。
图2为用户-物品图的一个例子。
具体实施方式
本专利的主要思想是:首先根据用户对物品的反馈信息构建用户-物品二分图,然后根据信任机制构建用户信任图,利用随机游走策略,在两图上生成用户物品相似度和信任图用户的相似度,重复迭代算法直到相似度稳定到收敛值,采用图熵的方法来分配两个相似度值的权重以得到最终的相似度。最后,根据最终的用户物品相似度计算每个用户的推荐列表。算法流程示意图如图1,具体步骤如下:
1选取数据样本
在本专利中,选取一组用户对物品的历史评分数据,评分是从1到5的整数,1代表很不喜欢,5代表非常喜欢。除了评分数据之外还有社交信息,数据中包含用户的好友网络,并且用户好友也各自对物品进行过评分,这里的好友为与某一具体用户有相互交互的好友,也可以是用户关注的热门人物。除此之外,用户和好友对物品有过相关的反馈信息,如用户对物品的点击、搜索、收藏、评论、分享、屏蔽等。
2构建训练和测试数据
对数据集进行预处理,对于重复数据和异常数据进行删除,并将数据进行归一化结构化处理。将所选数据集随机的分为9:1,其中90%作为训练集,10%作为测试集。实验每次随机划分数据后将进行10次取平均值比较推荐结果。top-n推荐列表的n值取为30。
3构建用户-物品图
首先利用一个无向图g=(v,e,w)来表示用户-物品二分图(uig),其中v是两种不同对象用户u和物品i的集合;顶点之间通过带权无向边e相连接,边上的权重w表示用户对该物品的感兴趣程度。图2为用户-物品图的一个例子。
如何确定用户与物品边上的权重是确定用户物品相似度的关键,对此考虑用户多种反馈行为的影响。假如用户对物品产生了n种反馈,我们为每种反馈的具体情况进行分析设计权重。譬如用户对物品的评分为3(总分为5),那么就其评分而言其所占权重为0.6,假如用户点击了该物品,则反馈信息值设置为1,搜索了该物品则反馈信息值设置为2,收藏该物品的反馈信息值设置为2,分享的反馈信息值设置为1。综上某用户对物品的反馈所融合成的权重计算如下:
其中:n表示用户对物品产生的反馈类型数;frep表示用户对物品的屏蔽或举报等反馈信息,如有设置为0,无该信息则设置为1;fj(u,i)分别表示用户对物品各种反馈信息的值。假如用户a观看了a、b、c、d四部电影,收藏了b、c,点击了b、c、d,分享了b、d,并分别对其评为2、3、4、5分,则w(a,a)、w(a,b)、w(a,c)、w(a,d)分别为0.4、1.867、1.9、2.0。
4构建用户信任图
构建用户信任图(utg)的目的是在信任社交网络上找寻与目标用户相似度高的用户,使得目标用户对没有选择的物品分配相应的权重,从而有利于推荐的多样性。首先计算用户的信任度,公式如下:
其中:da,b表示用户a、b在信任社交网络上的信任传播距离;dmax表示信任社交网络上允许用户间传播的最大距离,计算公式如下所示:
其中n和k分别表示系统中信任网络范围大小和平均度。
接着计算信任的用户物品相似度,方法如下:
其中:nt为目标用户有信任度的用户集合;|nt|表示其用户节点个数;simf(u',i)表示基于用户反馈信息的用户物品相似度;tu,u'表示信任度公式计算得出的用户之间信任度。
5计算用户物品相似度收敛值
利用随机游走(randomwalk)策略,以每个用户u作为出发点,游走到下一个节点时,判断是以概率β继续游走还是停止游走,以1-β的概率返回出发节点重新游走;若为前者,则按权重比例随机选择下个节点作为游走节点;重复迭代游走过程直至用户和各节点的游走概率收敛到稳定值。假设simn(u,i)表示完成第n轮randomwalk之后用户u和节点i的相似度收敛值,i∈v,则simn(u,i)计算公式如下:
其中:vi、vi分别表示图中与节点i、j直接相连的节点集合;β为随机游走转移概率,w(u,j)为用户对物品反馈的权重。结合5.3中权重公式w(u,j)和randomwalk游走公式可得到用户对物品反馈的收敛相似度
6利用图熵进行top-n推荐
信息熵描述信息量的大小,熵值越大表示图的信息量越丰富,所占的权重越多。计算节点的熵时我们只考虑整个图的拓扑结构,不区分节点类型,因此不同于多个相邻矩阵描述不同节点之间的连接,而是使用单个相邻矩阵来描述整个主图的拓扑结构,然后计算所有节点熵总和。计算公式如下:
综合考虑用户对物品的反馈信息和信任用户的信息,最终各节点的相似度为:
其中:λ为加权系数,λ=hf/(hf+ht),hf、ht分别表示用户-物品图和用户信任图的熵。
7算法评估
对于目标用户,根据各节点相似度的大小对物品进行排序,如果目标用户喜欢的商品集中在排序的靠前部分,则证明算法有效,反之,说明算法无效。在推荐系统中通常用度量指标来评估算法的性能,本文采用f1指标来描述算法的精确性,同时用覆盖率(coverage,cvr)来描述算法推荐的多样性。
1.f1指标是是两种度量指标准确率(p)和召回率(r)的加权平均,令r(u)是根据用户在训练集上的行为给用户做出的推荐列表,t(u)是用户在测试集上的行为列表。计算公式如下:
f1=(2*p*r)/(p+r)
2.推荐的覆盖率表示推荐系统所推荐的物品列表top-n在全部物品集合vi中所占的比例,cvr越高表示推荐给用户的物品多样性越大,越有新颖性。计算公式如下:
本专利提出一种基于图熵的社交网络推荐方法,综合考虑了用户对物品的多反馈和信任信息,对用户数据进行更加全面的挖掘,在用户反馈数据稀疏的情况下,很大程度上提升了推荐的准确性和多样性,并且在召回率、覆盖率方面均具有良好的表现。推荐系统算法的构造者在构造算法的时候,可以根据本专利提出的解决推荐系统中数据稀疏问题的方法,根据实际应用场景,调整上述方案参数,提升推荐性能。
- 还没有人留言评论。精彩留言会获得点赞!