一种数据分发方法及推荐系统与流程
本发明涉及推荐系统中的数据分发技术领域,具体说是一种数据分发方法及推荐系统。
背景技术:
随着互联网技术的发展,推荐系统(个性化推荐系统)的使用非常普遍,推荐系统的任务是联系用户和信息,一方面帮助用户发现对自己有价值的信息,另一方面让信息能够展示在对它感兴趣的用户面前,实现信息消费者和信息生产者的双赢,解决信息过载的问题。
推荐系统可应用在:
音乐、电影的推荐,
电子商务中商品推荐,
个性化阅读(新闻消息),
社交网络好友推荐、朋友圈推荐,
基于位置的服务推荐,等等。
在推荐系统中,第一个环节是分发阶段,合理的分发策略是推荐系统的重点,第二个环节是召回阶段,召回算法是该阶段的关键,第三个环节是排序阶段,将召回阶段得到的候选集进行精准排序,推荐给用户。
所谓召回,可以理解为向用户粗选一批待推荐的信息(商品信息,视频信息等等),相当于粗排序,之后再通过排序模型进行精排序,例如使用ctr(click-throughrate,点阅率)预估的rank模型(排名模型),即:召回=>排序(精排)=>后续其他处理步骤。所以召回的目的在于:从原始数据(一般理解为全量信息集合)中触发尽可能多的正确结果(即召回数据),并将正确结果(即召回数据)返回给排序。
当数据(指原始数据,一般理解为全量信息集合)接入推荐系统时,通常需要通过数据分发器传输给数据召回器,数据召回器负责完成召回阶段的处理,根据召回策略(即召回算法)的不同,数据召回器不唯一,在一个推荐系统中,可能存在多个数据召回器,设计适当的数据分发方法,对于提高数据接入后传输给数据召回器的效率,影响很大,但是,现有技术中,针对数据分发方法的成熟方案鲜有记载,重视程度不够,缺乏成熟度高、有实用价值的数据分发方案。
推荐系统中常用的召回策略(即召回算法)大致如下:
协同过滤模型(主要可以分为基于用户的协同过滤、基于物品的协同过滤)、向量化召回模型和深度树匹配模型,协同过滤模型无法做到全局检索,而向量化召回模型对模型的结构进行了限制。深度树匹配模型解决了上述两个方面的限制,可以做到全局检索+使用先进模型。
技术实现要素:
针对现有技术中存在的缺陷,本发明的目的在于提供一种数据分发方法及推荐系统,统一了分发器架构,可将编写好的策略加载到系统中,容易维护、更新分发策略,业务兼容性好;采用redis缓存进行模块间通信,数据分发响应时间低;分发时通过用户分数的判断,可为老用户推送个性化信息,新老用户推荐不同内容,更符合用户需求。
为达到以上目的,本发明采取的技术方案是:
一种数据分发方法,其特征在于,包括:
调用启动脚本,所述启动脚本用于启动数据分发处理的初始化,
读取配置文件并进行解析,从中获取以下信息:文件名model_file、类名modle_class、策略类型modle_type,
缓存上述解析得到的文件名、类名、策略类型,以参数的形式传递给分发器架构,启动分发策略,将分发策略加载到系统中,
执行分发策略。
在上述技术方案的基础上,所述启动脚本包括:
通过调用start函数开始分发模块的启动,
获取启动分发进程的个数,每个分发进程均执行如下步骤:
获取以参数的形式传递的文件名model_file、类名modle_class、策略类型modle_type,
将参数传递给分发器架构server_deliver.py,
调用record函数记录启动的进程号,以及记录启动的时间。
在上述技术方案的基础上,所述数据分发处理的初始化具体包括以下步骤:
将分发器加载到系统中,
连接热门数据推荐缓存队列popredis,用于分发器向热门推荐pop发送数据,
连接个性化数据推荐缓存队列cfredis,用于分发器向个性化推荐cf发送数据,
连接冷门数据推荐缓存队列coldredis,用于分发器向冷门推荐cold发送数据,
连接其他数据推荐缓存队列otherredis,用于分发器向其他推荐other发送数据,作为后补召回数据策略,
连接数据召回器缓存队列filterredis,用于向数据召回器filter发送通知,通知filter有数据需要从召回器召回,并对召回数据进行整合,
连接分发策略deliver接收请求数据的redis缓存。
在上述技术方案的基础上,所述分发器架构,具体包括:
加载层、架构层、业务层,由这三层构成分发器架构,其中:
加载层,在启动时被调用,用于获取配置文件,从中获取文件名model_file、类名modle_class、策略类型modle_type,通过接口的形式,形成分发实例化对象,
架构层,被所有业务使用,用于从redis缓存中接收原始数据作为待处理数据,将待处理数据发送到业务层,所述待处理数据亦存入redis缓存,
业务层,用于根据加载层传入的分发实例化对象,通过分发策略,对架构层传入的原始数据进行分发处理。
在上述技术方案的基础上,所述执行分发策略具体包括:
步骤1,从redis缓存中读取数据,所述数据为架构层接收到的原始数据,
步骤2,解析读取到的原始数据,依次获取以下信息:
获取用户id,
获取设备id,
获取用户请求资源的个数,默认资源为多媒体资源,所述多媒体资源包括以下任意之一:视频资源,音频资源,
获取写历史标识的标记位,所述写历史标识的标记位用于根据用户请求偏好是否重复推送,
步骤3,判断用户id是否存在,
如果存在,则构建用户唯一标识user_id_key,所述用户唯一标识user_id_key格式如下:
ur:用户id,
如果不存在,则构建用户唯一标识user_id_key,所述用户唯一标识user_id_key格式如下:
dr:设备id
步骤4,将用户唯一标识user_id_key作为参数,查询对应的用户分数信息,
在推荐系统中,用户历史信息模块中存储有用户分数信息,通过将用户唯一标识user_id_key作为参数,发送到用户历史信息模块,可以获得对应的用户分数信息,
步骤5,基于用户分数信息,计算各种召回器召回个数,具体包括:
步骤5.1,设定用户分数阈值,
判断用户分数信息是否大于用户分数阈值,
如果大于,则设定为第一召回比例,
如果小于等于,则设定为第二召回比例,
步骤5.2,将用户请求资源的个数,与第一召回比例或第二召回比例相乘,得到各种召回器召回个数,
步骤6,将数据通过redis缓存发送到不同的召回器,所述不同的召回器至少包括:
个性化数据cf召回器,
冷数据cold召回器,
热门数据pop召回器。
在上述技术方案的基础上,所述设定为第一召回比例,具体包括:
首先,代表个性化召回推荐占比的cf数据占比设定为用户分数/5,
然后,代表热门数据推荐占比的pop数据占比设定为一固定值,
代表冷数据推荐占比cold数据占比设定为一固定值,且与pop数据占比相等,
所述固定值为自定义值或经验值,推荐固定值为12.5%,
再后,计算100%-cold-pop的值,计算结果与用户分数/5比较值的大小,取小值作为代表个性化召回推荐占比,
最后,计算100%-cf-cold的值,计算结果作为pop数据占比。
在上述技术方案的基础上,所述设定为第二召回比例,对应于新用户,因新用户没有相关历史信息,故具体包括:
代表个性化召回推荐占比的cf数据占比设定为0%,
代表热门数据推荐占比的pop数据占比设定为80%,
代表冷数据推荐占比cold数据占比设定为20%。
在上述技术方案的基础上,所述步骤5.2,具体包括:
将用户请求资源的个数rec_num,乘以cf数据占比w_cf,得到个性化数据个数num_cf,
将用户请求资源的个数rec_num,乘以cold数据占比w_cold,得到冷数据个数num_cold,
将用户请求资源的个数rec_num,减去个性化数据个数num_cf和冷数据个数num_cold,得到流行数据个数num_pop。
在上述技术方案的基础上,所述不同的召回器还包括后补数据other召回器,
当个性化数据个数num_cf,冷数据个数num_cold,以及流行数据个数num_pop,相加后总和小于总召回数,
则向后补数据other召回器发送指令,通过后补数据other召回器补齐差值,使差值与个性化数据个数num_cf,冷数据个数num_cold,以及流行数据个数num_pop,相加后总和等于总召回数。
一种推荐系统,其特征在于:包括应用上述任意之一所述数据分发方法的数据分发器,接收数据接入模块发来的原始数据,根据分发策略,将原始数据分发给数据召回模块,数据分发器通知数据融合器有数据推荐请求正在处理,通知数据融合器需要召回哪些召回数据,数据融合器生成推荐内容,推荐内容写入redis缓存,通过redis缓存发送到数据接入模块。
本发明所述的数据分发方法及推荐系统,统一了分发器架构,可将编写好的策略加载到系统中,容易维护、更新分发策略,业务兼容性好;采用redis缓存进行模块间通信,数据分发响应时间低;分发时通过用户分数的判断,可为老用户推送个性化信息,新老用户推荐不同内容,更符合用户需求。
本发明所述的视频推荐系统,可用于酷我音乐app视频推荐系统中,推荐系统的数据分发器,采用本发明所述数据分发方法后,实现了以下功能:
第一、业务兼容性强,该分发器策略及分发架构可以使用在不同的业务(视频、音乐片段、私人电台等)场景中,除分发策略外,该分发器架构只需根据自己的业务编写分发策略,而不需要修分发器架构。
第二、系统容易维护,业务兼容性强。
第三、能够根据用户打分区分新老用户,为新用户提供最新流行视频片段,以及曝光部分冷数据(在推送过程中可以成为流行视频或该用户的个性化视频);为老用户根据播放记录的打分信息推送该用户的个性化信息。
附图说明
本发明有如下附图:
图1调用分发策略的流程图。
图2分发器架构示意图。
图3执行分发策略的流程图。
图4推荐系统结构示意图。
具体实施方式
以下结合附图对本发明作进一步详细说明。
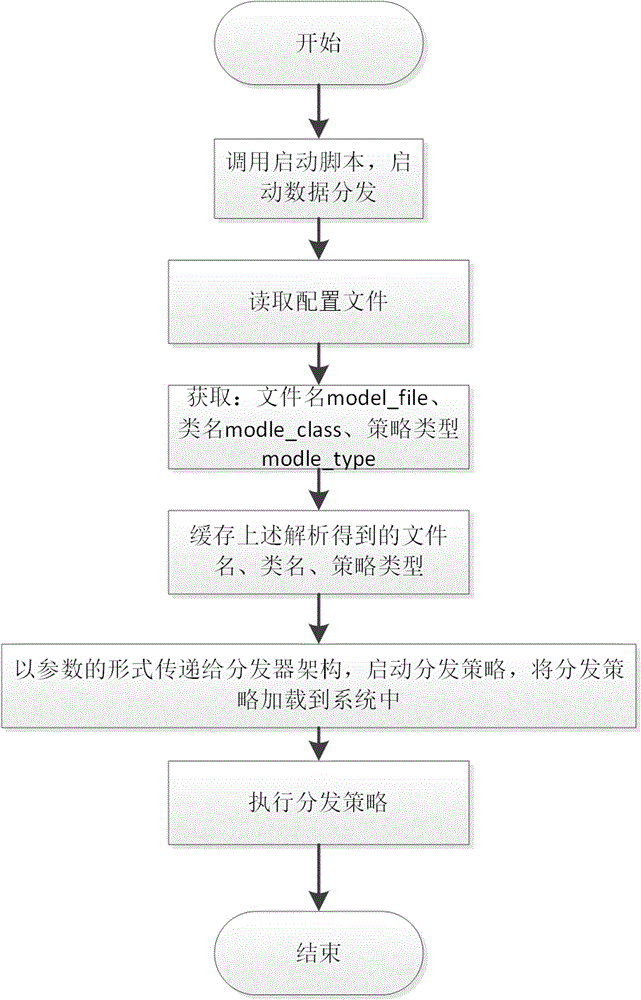
如图1所示,本发明所述的数据分发方法,包括:
调用启动脚本,所述启动脚本用于启动数据分发处理的初始化,
读取配置文件并进行解析,从中获取以下信息:文件名model_file、类名modle_class、策略类型modle_type,
例如:在配置文件feedmv.ini中,设置节[server_deliver],在该节中具体记载:
model_file=deliver_model#分发策略文件名
modle_class=proportion_model#分发策略类名
modle_type=deliver_by_ratio#分发策略类型,这个类型为按照比例分发,
缓存上述解析得到的文件名、类名、策略类型,以参数的形式传递给分发器架构,启动分发策略,将分发策略加载到系统中,
执行分发策略。
在上述技术方案的基础上,所述启动脚本包括:
通过调用start函数开始分发模块的启动,需要说明的是,在开始分发模块的启动时,还可以并行的或顺序的执行其他模块的启动(进程启动),
获取启动分发进程的个数,每个分发进程均执行如下步骤:
获取以参数的形式传递的文件名model_file、类名modle_class、策略类型modle_type,
将参数传递给分发器架构server_deliver.py,
调用record函数记录启动的进程号,以及记录启动的时间。
例如,可采用如下代码实现:
start(){
foriiin$(seq1$num)
do
nohuppython-userver_deliver.pydeliver_modelproportion_modeldeliver>>log/deliver_$ii.log2>&1&
record$!
done
echo$pid>./data/log/startup.pid
echo$pid_time>>./data/log/startup.pidtime
}
其中:
$num:表示启动分发进程的个数,
log/deliver_$ii.log:将部分打印信息或者异常信息输入到该文件,
&:后台运行该进程,
record$!:记录该进程的进程号和启动的时间,
上述实施例中,记录启动的进程号,将启动的进程号存放到文件startup.pid中,同时记录启动的时间,将该进程启动的时间存放到文件startup.pidtime中,
当终止(stop)该进程时,通过读取进程号和动的时间来杀死对应的进程,
record函数可采用如下代码实现:
functionrecord(){
pid=$1
tim=$(ps-eopid,lstart|grep-w$pid|awk'{print$3,$4,$5,$6}'|xargs-i{}date-d{}+%s)
pid_time="$pid_time|||${pid}_${tim}"
pid="$pid|||$pid"
}
record函数用于获取启动的进程号,以及获取启动的时间。
在上述技术方案的基础上,所述数据分发处理的初始化具体包括以下步骤:
将分发器加载到系统中,
连接热门数据推荐缓存队列popredis,用于分发器向热门推荐pop发送数据,
连接个性化数据推荐缓存队列cfredis,用于分发器向个性化推荐cf发送数据,
连接冷门数据推荐缓存队列coldredis,用于分发器向冷门推荐cold发送数据,
连接其他数据推荐缓存队列otherredis,用于分发器向其他推荐other发送数据,作为后补召回数据策略,
连接数据召回器缓存队列filterredis,用于向数据召回器filter发送通知,通知filter有数据需要从召回器召回,并对召回数据进行整合,
连接分发策略deliver接收请求数据的redis缓存。
在上述技术方案的基础上,如图2所示,所述分发器架构,具体包括:
加载层、架构层、业务层,由这三层构成分发器架构,其中:
加载层,在启动时被调用,用于获取配置文件,从中获取文件名model_file、类名modle_class、策略类型modle_type,通过接口的形式,形成分发实例化对象,
架构层,被所有业务使用,用于从redis缓存中接收原始数据作为待处理数据,将待处理数据发送到业务层,所述待处理数据亦存入redis缓存,
业务层,用于根据加载层传入的分发实例化对象,通过分发策略,对架构层传入的原始数据进行分发处理。
采用redis缓存可以获得更低的响应时间,也能提升架构间数据传输的效率,提升处理效率。
前述文件名、类名、策略类型以参数的形式传递给分发器架构,具体说是指传递给架构层,传递这些参数的目的是产生实例化分发策略对象。
在上述技术方案的基础上,如图3所示,所述执行分发策略具体包括:
步骤1,从redis缓存中读取数据,所述数据为架构层接收到的原始数据,
步骤2,解析读取到的原始数据,依次获取以下信息:
获取用户id,
获取设备id,
获取用户请求资源的个数,默认资源为多媒体资源,所述多媒体资源包括以下任意之一:视频资源,音频资源,
获取写历史标识的标记位,所述写历史标识的标记位用于根据用户请求偏好是否重复推送,
步骤3,判断用户id是否存在,
如果存在,则构建用户唯一标识user_id_key,所述用户唯一标识user_id_key格式如下:
ur:用户id,
如果不存在,则构建用户唯一标识user_id_key,所述用户唯一标识user_id_key格式如下:
dr:设备id
步骤4,将用户唯一标识user_id_key作为参数,查询对应的用户分数信息,
在推荐系统中,用户历史信息模块中存储有用户分数信息,通过将用户唯一标识user_id_key作为参数,发送到用户历史信息模块,可以获得对应的用户分数信息,
所述用户分数信息,是根据用户播放记录计算出的分数,具体计算方法不属于本发明内容,可按现有技术实施,例如:
歌曲分数=歌曲的播放总时长除以播放长度,
用户分数=所有歌曲的歌曲分数相加,所有歌曲为该用户播放过的所有歌曲,
步骤5,基于用户分数信息,计算各种召回器召回个数,具体包括:
步骤5.1,设定用户分数阈值,例如0.625,
判断用户分数信息是否大于用户分数阈值,
如果大于,则设定为第一召回比例,
如果小于等于,则设定为第二召回比例,
步骤5.2,将用户请求资源的个数,与第一召回比例或第二召回比例相乘,得到各种召回器召回个数,
步骤6,将数据通过redis缓存发送到不同的召回器,所述不同的召回器至少包括:
个性化数据cf召回器,
冷数据cold召回器,
热门数据pop召回器。
在上述技术方案的基础上,所述设定为第一召回比例,具体包括:
首先,代表个性化召回推荐占比的cf数据占比设定为用户分数/5,
然后,代表热门数据推荐占比的pop数据占比设定为一固定值,
代表冷数据推荐占比cold数据占比设定为一固定值,且与pop数据占比相等,
所述固定值为自定义值或经验值,推荐固定值为12.5%,
再后,计算100%-cold-pop的值,计算结果与用户分数/5比较值的大小,取小值作为代表个性化召回推荐占比,
最后,计算100%-cf-cold的值,计算结果作为pop数据占比。
在上述技术方案的基础上,所述设定为第二召回比例,对应于新用户,因新用户没有相关历史信息,故具体包括:
代表个性化召回推荐占比的cf数据占比设定为0%,
代表热门数据推荐占比的pop数据占比设定为80%,
代表冷数据推荐占比cold数据占比设定为20%。
在上述技术方案的基础上,所述步骤5.2,具体包括:
将用户请求资源的个数rec_num,乘以cf数据占比w_cf,得到个性化数据个数num_cf,
将用户请求资源的个数rec_num,乘以cold数据占比w_cold,得到冷数据个数num_cold,
将用户请求资源的个数rec_num,减去个性化数据个数num_cf和冷数据个数num_cold,得到流行数据个数num_pop。
在上述技术方案的基础上,所述不同的召回器还包括后补数据other召回器,
当个性化数据个数num_cf,冷数据个数num_cold,以及流行数据个数num_pop,相加后总和小于总召回数,
则向后补数据other召回器发送指令,通过后补数据other召回器补齐差值,使差值与个性化数据个数num_cf,冷数据个数num_cold,以及流行数据个数num_pop,相加后总和等于总召回数。
在上述技术方案的基础上,当写历史标识的标记位有效时,向召回器发送指令,所述指令用于控制召回器计算出的召回数据写入数据库作为历史数据。
基于上述数据分发方法,本发明给出了一种推荐系统,包括应用上述数据分发方法的数据分发器,接收数据接入模块发来的原始数据,根据分发策略,将原始数据分发给数据召回模块,数据分发器通知数据融合器有数据推荐请求正在处理,通知数据融合器需要召回哪些召回数据,数据融合器生成推荐内容,推荐内容写入redis缓存,通过redis缓存发送到数据接入模块。如图4所示。
在上述技术方案的基础上,数据接入->数据分发数据格式:
{"query":{"devid":"232398182","cmd":"short_video","cmd_id":"99","num":8,"write_history":"0","uid":"466605798","pid":"99989"},"msg":[]}
其中:
query:为请求所带信息
cmd:业务名称(short_video为短视频,feedmv_rec视频,private_fm私人电台等)
cmd_id:业务编码
num:资源请求数量
write_history:是否写历史
pid:接入模块的进程id
devid:用户设备id
uid:用户id
msg:为应答数据这里为空列表。
在上述技术方案的基础上,数据分发->数据召回数据格式:
{"msg":[],"query":{"pid":"99989","recall_num":3,"cmd":"short_video","cmd_id":"99","user_id":"ur:466605798"}
其中:
query:为请求所带信息
recall_num:召回数据的数量
user_id:用户唯一标识
msg:为应答数据这里为空列表。
在上述技术方案的基础上,数据召回->数据融合数据格式:
{"msg":[{"recall_type":"pop","id":"121107","score":"0.878"},{"recall_type":"pop","id":"109312","score":"0.86"},{"recall_type":"pop","id":"12039","score":"0.20"},"query":{"error":"ok","recall_num":3,"pid":"99989","cmd":"short_video","user_id":"ur:466605798","status":200,"cmd_id":"99"}}
其中:
query:请求信息以及状态信息
error:召回状态描述信息
status:状态码
msg:为应答数据
recall_type:为召回类型(根据召回器类型不同召回数据不同即pop,cold,cf,other)
id:召回的资源id
score:这次召回该资源的打分情况。
在上述技术方案的基础上,数据融合->数据接入数据格式:
{"msg":[
{"recall_type":"cf","id":"121107","score":"1.05"},{"recall_type":"cf","id":"109312","score":"0.81"},{"recall_type":"cf","id":"12039","score":"0.79"},
{"recall_type":"pop","id":"121107","score":"0.878"},{"recall_type":"pop","id":"109312","score":"0.86"},{"recall_type":"pop","id":"12039","score":"0.20"},
{"recall_type":"cold","id":"109312","score":"0.11"},{"recall_type":"other","id":"12039","score":"0.0"},
"query":{"error":"ok","num":8,"pid":"99989","cmd":"short_video","user_id":"ur:466605798","status":200,"cmd_id":"99"}}。
本说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!