对非饱和信息进行迭代建模的方法与流程
本发明涉及根据信息样本的类型进行建模方法,具体讲是对非饱和信息进行迭代建模的方法。
背景技术:
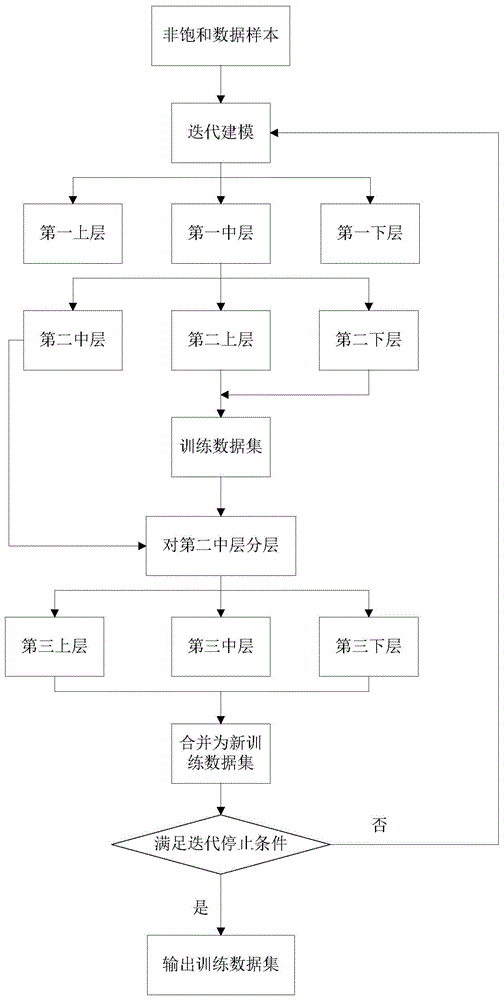
:在数据挖掘领域,通常样本标签需要一段时间的观察期才能得到,因此当时间窗口不足,数据较少的情况下,样本标签会存在比实际情况少或者置信度不够的情况。这种情况会导致在实际建模过程中出现部分样本难分(在预测过程中没有足够的置信度证明是正样本还是负样本),从而使得模型整体的auc(areaundercurve),ks(在模型中用于区分预测正负样本分隔程度的评价指标)等指标较低,模型效果无法达到理想值。而模型的好坏与样本分类的好坏是成正比的,也就是和auc的大小成正比。对于数据不足或者标签不置信导致的难分样本情况,目前主流的解决方案有以下两种:1:数据扩充,将相似领域的数据引入,例如需要对领域a进行建模,但是缺乏足够的数据,将表现相似的b领域的数据引入一部分加入建模样本。2:迁移学习,在有充分数据样本的领域建模得到一个基准模型,然后用目标样本数据对模型参数进行微调从而应用到目标领域中。例如在图片分类中,需要建立一个对狼群的识别模型,但是由于狼的图片样本较少,可以先用家犬图片做预训练,提取到犬科动物的共有基础特征后,在用狼的图片进行再训练,对模型进行修正,最终得到能够识别狼的模型。以上两种方法的缺点分别有:1:做数据扩充虽然解决了数据不足的问题,但同时引入了噪声和偏差。新样本和原来的样本的分布式是不完全一致的,因此形成的训练样本与模型用于预测的目标领域样本分布也是有区别的,样本分布不一致会导致模型有偏,在预测过程中,得到预测结果误差会更大。2:迁移学习要求目标样本和原有训练样本的主要特征有相似性,目前主要应用于深度学习,而于一般的机器学习方法不适用。技术实现要素:本发明提供了一种对非饱和信息进行迭代建模的方法,通过建立一种通用的模型对各种场合下应用的非饱和信息进行尽可能准确的分类。本发明对非饱和信息进行迭代建模的方法,包括:a.通过现有的建模方式(例如gbdt算法)对非饱和信息的数据样本进行训练得到数据模型和表示数据样本为正样本或负样本概率的概率值pi,其中i为概率值的个数,i的最大值与数据样本的数量相同;b.根据设定的置信度步长得到包含第一置信度上界和第一置信度下界的列表,根据各数据样本对应的概率值pi与所述列表中第一置信度上界和第一置信度下界之间的关系,对数据样本进行分层,将计算得到的auc(areaundercurve)最大值对应的最终置信度上界和最终置信度下界;c.根据所述的最终置信度上界和最终置信度下界对数据样本再次分层,得到包含正样本和负样本的训练数据集,通过对训练数据集进行训练,得到分类器;d.通过分类器的预测得到训练数据集以外的数据样本的概率值pi,并根据所述的最终置信度上界和最终置信度下界对训练数据集以外的数据样本进行分层,并将本次分层结果与所述的正样本和负样本进行对应合并,形成新训练数据集;e.迭代步骤b~步骤d,直到所述训练数据集以外的数据样本无法再分层,得到最终形成的新训练数据集。待分类的数据样本要视具体应用场景,通过本发明的方法将原始非饱和的数据样本进行优化后得到新训练数据的模型,例如在信贷领域通过本发明的模型对数据样本分类,得到的就是好坏客户的分类。再如,在文本分类领域的分类对象就是文本数据。同时,本发明得到所得模型的适用场景是普遍通用的,只要存在训练数据的标签置信度不够或不准确的情况,都可以用这种本发明建模的方式对数据进行优化。具体的,步骤b所述的对数据样本进行分层,是先定义第一置信度上界和第一置信度下界分别在0~1之间,且第一置信度上界>第一置信度下界,再根据设定的置信度步长得到包含第一置信度上界和第一置信度下界的列表,将所有的概率值pi与列表中每组的第一置信度上界和第一置信度下界进行数值大小的比较:概率值pi>第一置信度上界的数据样本为第一上层;概率值pi<第一置信度下界的数据样本为第一下层;第一置信度下界<概率值pi<第一置信度上界的数据样本为第一中层。进一步的,步骤b中将分层后的数据样本以auc为指标进行交叉验证训练,得到auc最大值对应的最终置信度上界和最终置信度下界。其中交叉验证和auc指标的获得采用已有的标准方法,在此不做详述。具体的,步骤c所述的对数据样本再次分层,是将所有数据样本的概率值pi与步骤b得到的最终置信度上界和最终置信度下界进行数值大小的比较:概率值pi>最终置信度上界的数据样本为第二上层;概率值pi<最终置信度下界的数据样本为第二下层;最终置信度下界<概率值pi<最终置信度上界的数据样本为第二中层。进一步的,步骤c所述的训练数据集中,以第二上层的数据样本为正样本,第二下层的数据样本为负样本。具体的,步骤d所述的对训练数据集以外的数据样本进行分层,是将训练数据集以外的数据样本的概率值pi与所述的最终置信度上界和最终置信度下界进行比较:概率值pi>最终置信度上界的数据样本为第三上层;概率值pi<最终置信度下界的数据样本为第三下层;最终置信度下界<概率值pi<最终置信度上界的数据样本为第三中层。具体的,步骤d所述的合并形成新训练数据集,是将所述的第三上层的数据样本和第二上层的数据样本合并为新训练数据集中的正样本,第三下层的数据样本和第二下层的数据样本合并为新训练数据集中的负样本。本发明实现了一种通用的模型,能够对各种场合下应用的非饱和信息进行的分类,具有较高的准确性和效率。以下结合实施例的具体实施方式,对本发明的上述内容再作进一步的详细说明。但不应将此理解为本发明上述主题的范围仅限于以下的实例。在不脱离本发明上述技术思想情况下,根据本领域普通技术知识和惯用手段做出的各种替换或变更,均应包括在本发明的范围内。附图说明图1为本发明对非饱和信息进行迭代建模的方法的流程图。具体实施方式如图1所示本发明对非饱和信息进行迭代建模的方法,包括:a.通过现有的gbdt算法建模方式对非饱和信息的数据样本进行训练得到数据模型和表示数据样本为正样本或负样本概率的概率值pi,其中i为概率值的个数,i的最大值与数据样本的数量相同。b.根据设定的置信度步长得到包含第一置信度上界和第一置信度下界的列表。其中第一置信度上界和第一置信度下界分别在0~1之间,且第一置信度上界>第一置信度下界。例如设置置信度步长=0.05,得到的列表如表1所示:表1:根据各数据样本对应的概率值pi与所述列表中第一置信度上界和第一置信度下界之间的关系,对数据样本进行分层:将所有的概率值pi与列表中每组的第一置信度上界和第一置信度下界进行数值大小的比较:概率值pi>第一置信度上界的数据样本为第一上层;概率值pi<第一置信度下界的数据样本为第一下层;第一置信度下界<概率值pi<第一置信度上界的数据样本为第一中层。将分层后的数据样本以auc为指标进行交叉验证训练,得到auc最大值对应的最终置信度上界和最终置信度下界。其中交叉验证和auc指标的获得采用已有的标准方法。比如(0.1,0.5)这一组,pi<0.1的数据样本为第一下层,0.1<pi<0.5的数据样本在第一中层,pi>0.5的数据样本在第一上层,而(0.1,0.5)这组的auc是所有组里最大的,则最终置信度上界=0.5,最终置信度下界=0.1。c.根据所述的最终置信度上界和最终置信度下界对数据样本再次分层:将所有数据样本的概率值pi与步骤b得到的最终置信度上界和最终置信度下界进行数值大小的比较:概率值pi>最终置信度上界的数据样本为第二上层;概率值pi<最终置信度下界的数据样本为第二下层;最终置信度下界<概率值pi<最终置信度上界的数据样本为第二中层。得到包含正样本和负样本的训练数据集,其中第二上层的数据样本为正样本,第二下层的数据样本为负样本。通过对训练数据集进行训练,得到分类器。d.通过分类器的预测得到训练数据集以外的数据样本(第二中层)的概率值pi,并根据所述的最终置信度上界和最终置信度下界对第二中层的数据样本进行分层:将第二中层的数据样本的概率值pi与所述的最终置信度上界和最终置信度下界进行比较:概率值pi>最终置信度上界的数据样本为第三上层;概率值pi<最终置信度下界的数据样本为第三下层;最终置信度下界<概率值pi<最终置信度上界的数据样本为第三中层。最后将第三上层的数据样本和第二上层的数据样本合并为新训练数据集中的正样本,第三下层的数据样本和第二下层的数据样本合并为新训练数据集中的负样本,由此得到新训练数据集。e.迭代步骤b~步骤d,直到所述第二中层的数据样本无法再分层,得到最终形成的新训练数据集。实施例1:(1)原始非饱和数据样本:正样本:1187负样本:35060通过现有的gbdt算法建模方式对非饱和信息的数据样本进行训练得到数据模型和数据样本标签的概率值pi,如表2所示:表2:序号pi分类10.013020.058130.030040.062050.004060.223170.151180.0370………(2)根据步骤b计算第一置信度上界和第一置信度下界,如表3所示:表3:取auc最大值对应的第一置信度上界和第一置信度下界组为最终置信度上界和最终置信度下界。(3)根据最终置信度上界和最终置信度下界,对所有数据样本再次分层得到训练数据集:最终置信度上界:0.15最终置信度下界:0.05正样本:852负样本:30541(4)通过步骤d得到合并后的新训练数据集:第三上层:450第三中层:3079第三下层:1794(5)迭代步骤b~步骤d后,得到最终修正后的样本:第三上层:798第三中层:1311第三下层:34147对数据样本优化后的效果(该效果是指采用本发明的方法优化后得到的数据样本进行训练和采用现有方法训练得到的模型在测试集上的auc指标,auc是已有的常用评价模型好坏的指标):auc(测试集)现有方法0.76本发明优化后0.83可以看出,通过本发明的方法对非饱和的数据优化有,得到的auc明显高于现有的方法,由此说明本发明得到的模型也明显优于现有的模型,能够对非饱和数据进行更准确的分类。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1