基于自适应增强回归的钢筋混凝土柱塑性铰长度计算方法与流程
本发明涉及钢筋混凝土柱塑性铰长度计算,具体涉及一种基于自适应增强回归的钢筋混凝土柱塑性铰长度计算方法。
背景技术:
塑性铰是钢筋混凝土材料中一种特殊的构件,钢筋混凝土受弯、偏压等构件的全受力过程中钢筋屈服后,在荷载无明显增加的情况下,截面的变形可以急剧增大,称出现了“塑性铰”。塑性铰是与理想铰相比较而言,是一种特殊的铰,它能承受一定方向的弯矩,这是它区别于一般铰最本质的特征。塑性铰在桥梁抗震设计中是一个重要的概念,因为在塑性铰形成的过程中能吸取大量的地震能量,所以在设计中恰到好处地设计塑性铰形成的位置,可有效降低震害,可以满足抗震设防要求。钢筋混凝土塑性铰长度的测定一般通过试验的方式,对混凝土构件进行在不同情况下的反复加载得到在不同加载水平下的塑性铰长度。然而,这种方式过程繁琐、耗时久、资源消耗大,十分低效,不利于实际工程的应用。
技术实现要素:
发明目的:本发明提供了一种基于自适应增强回归的钢筋混凝土柱塑性铰长度计算方法,解决现有方法过程繁琐,耗时久,效率久,误差大的问题。
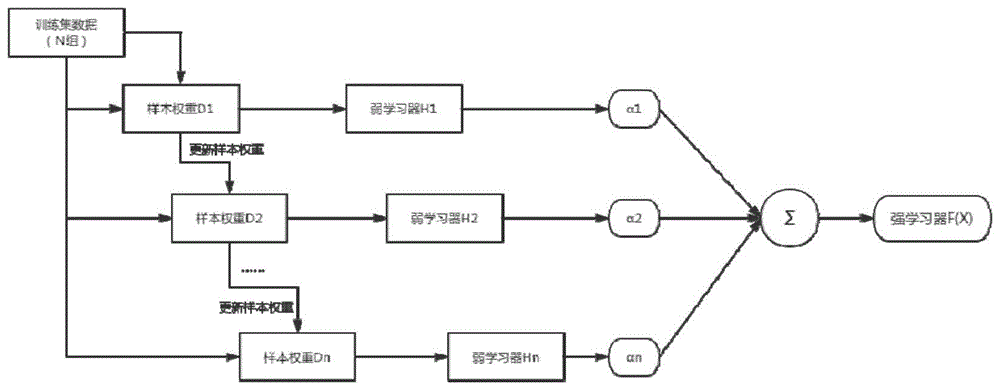
技术方案:本发明所述的基于自适应增强回归的钢筋混凝土柱塑性铰长度计算方法,包括以下步骤:
(1)搜集n组的钢筋混凝土柱塑性铰长度的试验样本,获取每一组试验的塑性铰的加载方式和钢筋自身参数以及最终试验所得的长度信息;
(2)将n组样本中,每组数据的塑性铰的加载方式和自身参数信息作为输入变量x,混合法所得塑性铰长度作为输出变量y;
(3)将n组试验样本作为训练集,并初始化训练集的权重分布;
(4)选择基本弱学习器ht(x),并使用权重分布为dt的训练集对其进行训练,计算该弱学习器在样本分布dt上的误差率et;
(5)计算该弱学习器在最终学习器中所占的权重αt;
(6)更新训练样本的权重;
(7)循环上述步骤(4)-(6)来训练多个弱学习器ht(x),得到对应的权重αt;
(8)按弱学习器的权重来组合各个弱分类器,得到最终的强学习器f(x):
(9)在训练完成的强学习器f(x)中输入待求钢筋混凝土塑性铰加载类型和钢筋自身参数,即输入向量x,得到该钢筋混凝土柱塑性铰长度预测值。
其中,所述步骤(3)中初始化训练集的权重分布为:
d1={w1,w2,…,wn},wi=1/n,i=1,2,…,n
式中,d1为训练集样本的权重分布,训练集中wi为第i个样本的权重,即每个训练样本的权重均为1/n。
所述步骤(4)中弱学习器在样本分布dt上的误差率:
式中,et为本轮弱学习器的误差率,yi为第i组样本的输出值,ht(xi)=yi表示对第i组样本训练正确,ht(xi)≠yi表示对第i组样本训练错误,ht(xi)表示对于第i组样本,使用第t次迭代所得弱学习器训练所得预测值,wi表示第i个样本的权重,i[ht(xi)≠yi]为指示函数,当判定ht(xi)≠yi时,其值为1,否则为0。
所述步骤(5)中计算弱学习器在最终学习器中所占的权重αt为:
所述步骤(6)中更新训练样本的权重:
式中,zt=sum(dt)为归一化因子。
有益效果:本发明可以避免物理试验的过程,可以在非常短的时间内完成分析和预测过程,大幅度提高了计算的效率和精度;可以避免由于参数的不精确而导致的系统误差;使得预测的效果更加贴近实际;具有自适应进化能力,在对于上一轮迭代中预测错误的样本会重点测试,经过多轮迭代之后的样本权重分布具有较高的可信性,由此得到的预测结果也具有较高的精确度。
附图说明
图1是本发明的流程示意图;
图2是adaptiveboosting算法自适应进化过程示意图。
具体实施方式
下面结合附图对本发明进行进一步说明。
如图1-2所示,基于自适应增强回归的钢筋混凝土柱塑性铰长度计算方法,包括以下步骤:
步骤一:机器学习训练集数据库构建
通过文献检索、网络检索等方式搜集n组的钢筋混凝土柱塑性铰长度试验样本数据,构建数据库θ=[θ1,θ2,...,θn],其中θi,i=1,2,...n为第i组数据。
步骤二:算法输入及输出参数设置
数据库θ中每组数据均包含2大类信息:第一类为钢筋混凝土柱塑性铰长度试验加载类型(类别型参数)以及钢筋自身参数(数值型参数);第二类为钢筋混凝土柱塑性铰长度,将第一类信息设为输入变量,记作x;第二类信息设为输出变量,记作y,则每组数据可以写作θi=(xi,yi)。
具体而言,每组数据有13个分量,其中输入参数有12个分量,包括常见的加载类型,截面宽度,截面深度,构件长度,纵向钢筋配筋率和钢筋直径,横向钢筋配筋率和钢筋直径,轴压比等,输出参数有1个分量,则x=(x1,x2,...,x12)为1×12的向量,而y为标量,即如下表1所示:
表1输入变量和输出变量
综上,构建完成的数据库可以表示为:
θ=[θ1,θ2,...,θn]=[(x1,y1),(x2,y2),...,(xn,yn)](1)
步骤三:基于自适应增强回归(adaptiveboosting)算法构建高精度学习器
采用机器学习中的adaptiveboosting算法对已构建的数据库θ进行训练,adaptiveboosting算法包含2个层次的学习器,即弱学习器h(x)和强学习器f(x),其中强学习器为多个弱学习器按一定权重组合而成,具体训练流程如下:
1)对训练集θ中的样本权重进行初始化,定义每个样本θi的权重wi均等,则初始样本权重向量为:
d1={w1,1,w1,2,…,w1,n}w1,i=1/n,i=1,2,…,n(2)
2)进行多轮迭代以确定每轮弱学习器的误差率和权重,设总体迭代t轮,对于第t轮迭代,弱学习器表示为ht(·),则对于每一组样本输入参数xi,弱学习器输出结果为ht(xi),ht(xi)=yi表示对第i组样本预测正确,ht(xi)≠yi表示对第i组样本预测错误;
3)对于n组训练样本,计算第t轮弱学习器的误差率et
该式意义为第t轮弱学习器的误差率et为预测错误的样本的权重wi之和,式中,et为本轮弱学习器的误差率,yi为第i组样本的输出值,ht(xi)=yi表示对第i组样本训练正确,ht(xi)≠yi表示对第i组样本训练错误,ht(xi)表示对于第i组样本,使用第t次迭代所得弱学习器训练所得预测值,wi表示第i个样本的权重,i[ht(xi)≠yi]为指示函数,当判定ht(xi)≠yi时,其值为1,否则为0;
4)根据误差率et计算第t轮弱学习器的权重αt
由上述式子可知,et≤1/2时,αt≥0,且αt随着et的减小而增大,意味着预测误差率越小的弱学习器在最终学习器中的作用越大;
5)更新训练集中每组样本的权重wt+1,i,使得预测正确(ht(xi)=yi)的样本权重降低,预测错误(ht(xi)≠yi)的样本权重增加,以在下一轮训练过程中重点学习预测错误的样本
dt+1={wt+1,1,wt+1,2…,wt+1,n}(5)
6)对于t<t,重复2)-5),获得每一轮训练的弱学习器ht(·)及其权重αt,组合成强学习器
步骤四:训练完成的强学习器的应用
向训练完成后的强学习器f(·)输入待求钢筋混凝土塑性铰加载类型和钢筋自身参数x,学习器输出钢筋混凝土塑性铰长度f(x)。
本发明是对于所有数据进行学习,并经过了多轮的自我修正和进化的,由于算法的运行完全基于黑匣模式,并不存在拟合函数的环节,单纯依靠已知的试验数据进行分析和学习,所以这种预测所得到的结果也完全基于实际,不再需要重复分析各种非理想化状态下的情况,真正避免了繁琐和理想化的模拟计算。
- 还没有人留言评论。精彩留言会获得点赞!