核电厂热工水力安全分析最佳估算加不确定性方法与流程
本发明属于核电厂安全分析技术领域,具体涉及一种核电厂热工水力安全分析最佳估算加不确定性方法。
背景技术:
核电厂的安全运行一直是核能发展中备受关注的一个事项,针对核电厂的事故安全分析方法也得到了长久的发展。目前国际上核电发达国家用于核电厂事故安全分析的方法为最佳估算加不确定性分析方法,这类方法能够考虑电厂模拟中的各类不确定性,使得模拟结果更加真实和可靠。最佳估算加不确定性分析方法在我国依旧处于发展阶段,开发先进的最佳估算加不确定性分析方法对于我国的核电自主化具有重要意义。
目前国际主流的传统最佳估算加不确定性分析方法已经得到了广泛的应用和验证,其发展已相对成熟,且分析步骤也相对固定。但是依旧存在一些问题亟待解决和优化。
首先,由于核电厂事故分析中涉及到的输入参数数目巨大,同时考虑所有参数的不确定性是不真实的,因此需确定对目标重要输出影响最大的输入参数。在该过程中,基于专家经验和判断建立现象识别排序表是通用的常规做法。但是,基于现象识别排序表的参数识别存在误识别不重要参数和遗漏重要参数的问题,国际上鲜有解决该问题的相关研究。
其次,最佳估算加不确定性分析方法需对所有输入参数的不确定性进行量化,这些不确定的输入包含状态参数,材料物性,初始/边界条件以及程序的本构模型。其中程序本构模型的不确定性很难进行量化,这是因为其不确定性评价依赖于模型相关的实验数据,而这些数据往往由于难以直接测量、年代久远或者数据非公开的原因而不可用。传统的方法中大多将本构模型的不确定性使用保守假设进行处理,这样处理会导致部分热工水力现象的模拟失真,无法得到真实的模拟结果。
最后,最佳估算加不确定性分析方法中要求量化输入参数对目标输出的影响大小,并对输入参数的重要度进行排序。考虑到计算成本,现有方法大多使用局部敏感性分析方法执行相关计算,但是对于模拟核电厂这种大型非线性,且参数间存在高阶相互作用的复杂系统而言,局部方法会获得错误的敏感性结果。因此需发展和使用全局敏感性分析方法,然而全局敏感性分析方法由于其所需的程序运行次数十分巨大,因此在核电厂事故分析中难以被直接使用。
以上存在的这些问题,会导致核电厂安全分析的结果不够准确和真实,因此需要进行相关的优化和补充研究。
技术实现要素:
本发明中开展了相关研究以解决现有最佳估算加不确定性分析方法中存在的问题。首先提出了一个结构化的本构模型不确定性评价方法,基于该结构化方法,本构模型会被按照其特征进行分类,并对不同的模型采用适当的方法评估其不确定性。而后,开发了一种优化的矩独立全局敏感性分析方法,该方法能够以十分小的计算成本获得可靠度较高的敏感性分析结果。随后提出了一个适用于最佳估算加不确定性方法的新敏感性分析框架,使得能够基于敏感性分析结果对现象识别排序表进行迭代修正。最后,基于上述方法调整现有方法的基本框架,得到了本发明一种核电厂热工水力安全分析最佳估算加不确定性方法。
本发明采用如下技术方案:
一种核电厂热工水力安全分析最佳估算加不确定性方法,其特征在于,包括如下步骤:
第一步:指定分析核电厂及工况;
第二步:确定对应工况的目标重要输出及其安全接受限值;
第三步:建立现象识别排序表:基于目标重要输出,结合专家经验和判断,建立现象识别排序表并初步识别对目标输出影响大的重要现象,过程或参数;
第四步:确定重要输入参数的不确定性分布:使用带有不确定性的参数表征所有的不确定性源,并对不确定性源中的状态参数、材料物性以及初始或边界条件对应的表征参数进行不确定性量化;
第五步:重要本构模型的不确定性量化:使用适用于本构模型不确定性量化的结构化方法对重要的重要本构模型进行不确定性量化,基于实验数据的可用性、模型是否存在可选选项以及模型的特征分类三个方面确定适合于目标本构模型的不确定性评估方法;对于缺少模型相关实验数据的情况,选择覆盖率校准方法;对于存在可选模型用于描述同一热工水力现象或过程的情况,基于贝叶斯框架确定适用于当前工况的最佳本构模型;
基于贝叶斯框架确定最佳本构模型后,基于特征将最佳本构模型分为独立模型和非独立模型,其中独立模型是指该模型在程序计算中能够被直接调用而无需涉及其他模型,使用不确定性因子方法对此类模型进行不确定性量化;
而非独立模型则是指在模型计算中会涉及多个子模型的模型,采用贝叶斯校准方法对此类模型进行不确定性量化;
基于该结构化方法,程序中本构模型的不确定性能够给被评估量化;
第六步:确定相关安全系统:基于目标核电厂的设计,并结合分析的工况,确定事故分析中会投入使用的相关安全系统;
第七步:确定安全系统可用性假设:基于上一步中确定的相关安全系统,进一步确定安全系统中涉及的组件,并确定组件的可用性;
第八步:确定核电厂的最佳节点化建模方案:基于整体核电厂及各功能系统或组件的设计参数确定核电厂的最佳节点化建模方案,并使用最佳估算程序完成对核电厂最佳估算模型的建模;核电厂的建模方案使用分离效应试验或者整体效应试验的实验数据进行评估和修正,以期能够真实地模拟事故工况中的现象或者过程;
第九步:执行基准工况计算:使用最佳估算程序完成对目标核电厂的建模以及分析工况的模拟后,使用所有参数的名义值执行一次程序计算,这一步的主要目的是评估电厂的初始稳态值是否为设计值,并且直观地分析程序模拟的瞬态工况是否可靠;
第十步:补充未被现象识别排序表识别的参数,并根据电厂设计及相关实验数据给定其不确定性分布,该步骤的目的是为了防止某些对目标输出具有重要影响的输入参数未被现象识别排序表识别;
第十一步:初始被现象识别排序表识别的输入参数的不确定性分布在第四步中给定,第十步中额外补充了部分现象识别排序表之外的输入参数及其不确定性分布;根据所有这些参数的不确定性分布类型及其不确定性区间,通过查表确定这些参数的五个高斯点;
第十二步:使用优化的矩独立全局敏感性分析方法计算各个输入参数的敏感性指标;优化的矩独立全局敏感性分析方法原理如下:
矩独立全局敏感性分析方法旨在评估输入参数对目标输出概率密度函数的影响;假设函数y=g(x)存在k个输入参数,即x=(x1,x2,...,xk)t,每个输入参数服从概率分布fxi(xi),输入参数的不确定性可通过函数计算传播至输出y;将y的无条件概率密度函数和无条件累积分布函数表示为fy(y)和fy(y),将第i个输入参数xi取某一固定值时得到的y的条件概率密度函数和条件累积分布函数表示为fy|xi(y)和fy|xi(y);根据定义,将第i个输入参数的矩独立敏感性指标表示为:
其中s(xi)为固定第i个输入参数情况下输出概率密度函数的偏移量:
将求解输出的概率密度函数转换为求解其累积分布函数能够在一定程度上优化计算结果;假设输出的fy(y)和fy|xi(y)存在m个交点,表示为a1,a2,...am,则s(xi)表示为(m+1)个子面积之和,即:
s(xi)=s1+s2+...+sj+...+sm+sm+1(j=1,2,...,m+1)(11)
其中,fy(y)和fy|xi(y)的交点根据下式进行求解:
而每个子面积sj根据如下关系式进行计算:
由此可知,如果能快速计算得到输出的fy(y)和fy|xi(y),则根据式(9~13)计算得到各个输入参数的矩独立全局敏感性指标δi;
为了能以低的计算成本且又相对精确地计算输入参数的敏感性指标,使用了多种方法进行优化计算;首先,为了降低积分计算的计算量,使用五点高斯求积方案替代积分计算:
式中,ωi,j表示第i个输入参数按照其分布类型确定的五个高斯权重值中的第j个值,同理xi,j表示第i个输入参数的第j个高斯点取值;ωi,j和xi,j的取值与参数的分布类型及不确定性区间有关;
求解s(xi,j)的关键在于求解输出的条件和无条件累积分布函数,即fy(y)和fy|xi(y);根据累积分布函数的定义,将其表示为:
fy(y)=p{g(x)≤y}=p{g(x)-y≤0}=p{z(x,y)≤0}=pf{z(x,y)}(15)
其中,z(x,y)=g(x)-y为定义的新函数,pf为失效概率;因此,将求解函数g(x)的累积分布函数转换为求解函数z(x,y)的失效概率,而高阶矩估计方法能被用于求解函数的失效概率;
使用四阶矩估计方法和皮尔森系统以求解函数的失效概率,根据皮尔森系统,将函数输出的累积分布函数表示为:
其中,βsm=μz/σz,即函数z(x,y)输出的均值和标准差之比,基于函数z(x,y)输出的前四阶中心矩,根据皮尔森系统确定f(z)的表达式;因此,求解函数z(x,y)输出的前四阶中心矩即能够求解得到函数g(x)输出的累积分布函数,而函数z(x,y)与函数g(x)输出的前四阶中心矩存在以下关系:
其中α1z表示函数z(x,y)的一阶中心矩,α1g表示函数g(x)的一阶中心矩,以此类推,为了快速计算函数g(x)输出的前四阶中心矩,使用高维模型表示的降维技术将函数的输出表示为:
其中c为参考点,即所有输入参数取名义值时的输入参数向量;g0为参考点对应的函数输出;g(xi,c)表示其他参数均取名义值,仅改变第i个输入参数时函数的输出值,k为输入参数的数目;
基于函数g(x)输出的降维表达式,将其前四阶中心矩表示为:
其中αmg表示g(x)输出的第m阶矩,m=1,2,3,4;根据五点高斯求积方案,将上式中的积分计算简化,得到:
由此可见,如果能求解得到每个输入参数xi在5个高斯点处的函数g(xi,j,c)的输出值,即能够计算得到函数g(x)输出的无条件累积分布函数,即fy(y);同理,将输入参数xi的取值依次固定于其5个高斯点,使用其余的k-1个输入参数执行相同的计算即能够计算得到函数g(x)输出的条件累积分布函数,即fy|xi,j(y),进而计算得到每个输入参数的矩独立全局敏感性指标δi;
第十三步:基于新敏感性分析框架迭代修正现象识别排序表:
最佳估算加不确定性分析方法的敏感性分析中,首先基于现象识别排序表识别对目标输出有较大影响的参数或者模型,而后建立对应的评估矩阵,进而确定核电厂的最佳节点化建模方案;基于核电厂的最佳估算模型,使用第十二步中开发的优化矩独立全局敏感性分析方法执行参数的筛选和重要度排序计算;由于提出的优化矩独立全局敏感性分析方法计算量十分小,因此能够在执行敏感性分析计算中额外考虑部分未被现象识别排序表识别的输入参数,以防止部分重要参数被现象识别排序表遗漏而导致不确定性传播计算结果不充分的问题;计算得到参数的敏感性排序后,如存在重要参数没有被现象识别排序表包含,则需对现象识别排序表进行补充或者修正,并重新评估是否需要改变核电厂的节点建模方案,以此形成一个循环修正现象识别排序表的过程;最后,若所有的重要参数均包含于现象识别排序表中,则根据最后一次迭代计算得到的矩独立全局敏感性指标对参数进行重要度排序,对目标输出没有影响的输入参数计算得到的敏感性指标为0;
第十四步:确定所有对目标输出有影响的重要输入参数:在敏感性分析过程中,能够计算获得所有输入对目标输出的全局敏感性指标,基于该计算结果,能够去除对目标输出影响较小或者没有影响的输入参数,使用剩下的参数执行后续不确定性传播计算;剩下的参数中既包含现象识别排序表参数,还可能包含部分第十步中补充的未被现象识别排序表识别的参数;
第十五步:确定不确定性传播计算所需的样本数量:采用高阶非参数阶数统计的方法确定不确定性传播计算所需的程序运行次数;
第十六步:随机抽样生成输入样本并执行对应的程序计算;
第十七步:量化目标输出的不确定性并确定目标输出的容忍限值:由于通过程序计算获得了目标输出的多个计算样本值,因此根据第十五步中使用的高阶非参数阶数统计方法的阶数直接在计算值中确定目标输出的容忍限值;同时,使用输出的各计算样本估算输出的置信限值,比较容忍限值和置信限值以确保容忍限值的保守性;
第十八步:比较目标输出的容忍限值与第二步确定的安全接受限值,判断核电厂在事故工况下是否安全。
和现有技术相比较,本发明具备如下优点:
对于难以直接评估不确定性的最佳估算程序本构模型,本发明开发了一个结构化方法用于对其进行不确定性量化。该结构化方法能基于实验数据的可用性,模型是否存在可选选项,以及模型的特征分类三个方面确定适合于目标本构模型的不确定性评估方法。对于缺少模型相关实验数据的情况,选择覆盖率校准方法。对于存在可选模型用于描述同一热工水力现象或过程的情况,基于贝叶斯框架确定适用于当前工况的最佳本构模型。而后基于特征将模型分为独立模型和非独立模型,其中独立模型是指该模型在程序计算中可以被直接调用而无需涉及其他模型,使用不确定性因子方法对此类模型进行不确定性量化。而非独立模型则是指在模型计算中会涉及多个子模型的模型,采用贝叶斯校准方法对此类模型进行不确定性量化。基于该结构化方法,最佳估算程序中的本构模型不确定性可以被评估量化。
(2)由于核电厂事故安全分析计算十分耗时,导致传统最佳估算加不确定性方法中的敏感性分析方法存在计算成本过大或者计算结果不可靠的缺点。本发明中使用了优化的矩独立全局敏感性分析方法,该方法中使用了高维模型表示的降维技术,结合高斯求积方案,皮尔森系统以及高阶矩估计的方法对矩独立全局敏感性分析方法进行优化以减小其计算成本,能够使用输入参数数目4至5倍的程序计算次数获取十分准确的敏感性分析结果,因此该方法可在大大减小了敏感性分析计算成本的基础上提高了敏感性分析结果的准确性和可靠性。
(3)传统方法中的现象识别排序表的建立主要取决于专家经验和判断,其存在误识别不重要输入参数或者遗漏重要参数的问题。本发明中提出了一个能够基于全局敏感性分析结果对现象识别排序表进行迭代修正的框架。基于该框架,可以补充未被现象识别排序表识别的输入参数用于执行定量全局敏感性分析。基于敏感性分析结果排除误识别的不重要输入参数,并判断是否存在重要参数被原始现象识别排序表遗漏,若存在则需补充修正原始现象识别排序表,并重新执行敏感性分析计算。整个过程形成了一个迭代修正现象识别排序表的框架,以此确保通过现象识别排序表识别的参数包含核电厂事故安全分析的所有重要参数。
附图说明
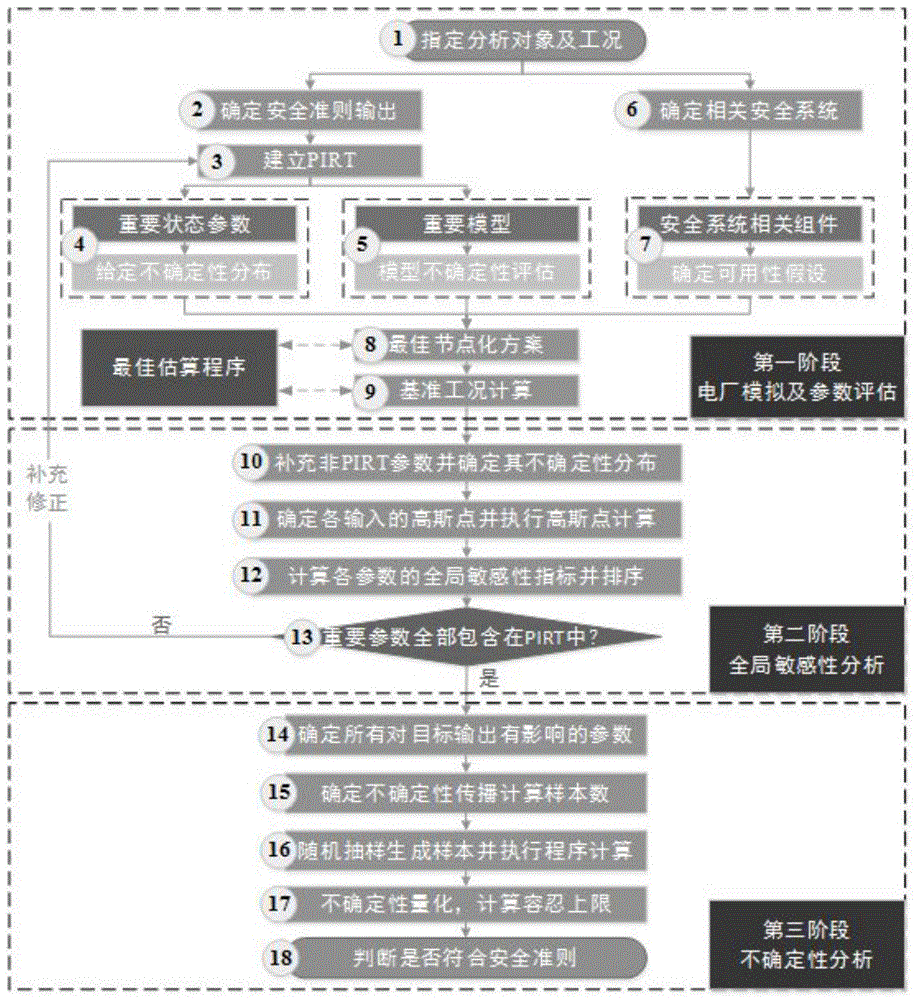
图1为本发明提出的适用于核电厂热工水力安全分析最佳估算加不确定性方法的流程示意图。
图2为适用于最佳估算程序本构模型不确定性量化的结构化方法示意图。
图3为迭代现象识别排序表修正的最佳估算加不确定性新敏感性分析框架示意图。
具体实施方式
下面结合图1对本发明中提出的核电厂热工水力安全分析最佳估算加不确定性方法的实现步骤进行详细说明。
第一步:指定分析核电厂及工况。
第二步:确定对应工况的目标重要输出及其安全接受限值。
第三步:建立现象识别排序表:基于目标重要输出,结合专家经验和判断,建立现象识别排序表并初步识别对目标输出影响大的重要现象,过程或参数。
第四步:确定重要输入参数的不确定性分布:使用带有不确定性的参数表征所有的不确定性源,并对不确定性源中的状态参数、材料物性以及初始或边界条件对应的表征参数进行不确定性量化。由于这些参数的不确定性能根据电厂设计或者实验直接测量得到,因此其不确定性量化较为容易。
第五步:重要本构模型的不确定性量化:
使用适用于本构模型不确定性量化的结构化方法对重要的重要本构模型进行不确定性量化。该结构化方法示意图如图2所示,其能基于实验数据的可用性、模型是否存在可选选项以及模型的特征分类三个方面确定适合于目标本构模型的不确定性评估方法。对于缺少模型相关实验数据的情况,选择覆盖率校准方法。对于存在可选模型用于描述同一热工水力现象或过程的情况,基于贝叶斯框架确定适用于当前工况的最佳本构模型。
贝叶斯框架的原理如下:
贝叶斯框架是由贝叶斯提出的一种使用先验信息和样本信息推断后验信息的统计学理论,其基础为贝叶斯公式。假设最佳估算程序中描述某一现象的本构模型存在n个,分别是m1,m2,...,mn,经由实验或采样的方式得到的观测数据表示为s,则贝叶斯公式可以表示为如式(1)所示:
其中p(mi)称为模型mi的先验概率,其表示基于已有历史资料或经验认知为模型mi分配的可信程度。若关于模型的先验信息较少,则可基于贝叶斯假设选取均匀分布,即p(mi)=1/n。p(s|mi)代表似然函数,其表示观测数据s是来自于模型mi的概率。而p(mi|s)则被称为后验概率,其表示在给定观测数据s的情况下模型mi的条件概率。后验概率的值可被用于筛选最佳模型,在给定相同的观测数据s的前提下后验概率值最大的模型为最佳模型。
在实际应用中,先验概率的值一般基于历史数据或者专家经验,因此均为固定的值,故求解模型mi后验概率的关键在于求解每个可选模型的似然函数。
假设存在由k个实验数据组成的向量
rc=rexp-rcal(2)
式中,
使用式(3)计算获得所有可选模型的似然函数后即可使用式(1)计算各模型的后验概率,选取后验概率最大的模型作为最佳本构模型。
基于贝叶斯框架确定最佳本构模型后,基于特征将最佳本构模型分为独立模型和非独立模型,其中独立模型是指该模型在程序计算中能够被直接调用而无需涉及其他模型,使用不确定性因子方法对此类模型进行不确定性量化;不确定性因子方法的实现依赖于模型相关的实验数据,其基本原理是通过模拟实验条件获取与实验测量值相对应的程序模拟计算值,而后将实验值与计算值的比值定义为不确定性因子,通过使用统计学方法评估不确定性因子的分布特征,从而确定该因子的不确定性分布。
而非独立模型则是指在模型计算中会涉及多个子模型的模型,采用贝叶斯校准方法对此类模型进行不确定性量化。贝叶斯校准方法的核心亦为贝叶斯公式,式(1)所示的贝叶斯公式在该方法中可表示为如下形式:
式中,x表示n个模型参数的不确定性组成的向量,rc的定义见式(2),其表示k个观测实验数据与计算值差值的向量。式(4)中,由于p(rc)不为x的函数,因此可将其视为一个归一化乘子,故有:
p(x|rc)∝p(x)p(rc|x)(5)
其中,p(x)表示重要参数或者子模型不确定性的先验概率,其分布服从正态分布,即xi服从n(μi,σi2),因此可以将p(x)表示为:
又因为rc服从n(0,σtot2),因此似然函数可表示为:
综合式(5),(6)和(7),可将后验概率表示为:
上式中σtot2表示实验值和计算值差值的方差,μi和σi2为未知待求解量,使用基于马尔科夫链的蒙特卡罗抽样算法执行式(8)的计算。
基于该结构化方法,程序中本构模型的不确定性可以被评估量化。
第六步:确定相关安全系统:基于目标核电厂的设计,并结合分析的工况,确定事故分析中会投入使用的相关安全系统。
第七步:确定安全系统可用性假设:基于上一步中确定的相关安全系统,进一步确定安全系统中涉及的组件,并确定组件的可用性。现有的最佳估算加不确定性分析方法中的系统组件功能可用性均是基于保守假设。
第八步:确定核电厂的最佳节点化建模方案:基于整体核电厂及各功能系统或组件的设计参数确定核电厂的最佳节点化建模方案,并使用最佳估算程序完成对核电厂最佳估算模型的建模。核电厂的建模方案可使用分离效应试验或者整体效应试验的实验数据进行评估和修正,以期能够真实地模拟事故工况中的现象或者过程。
第九步:执行基准工况计算:使用最佳估算程序完成对目标核电厂的建模以及分析工况的模拟后,使用所有参数的名义值执行一次程序计算,这一步的主要目的是评估电厂的初始稳态值是否为设计值,并且直观地分析程序模拟的瞬态工况是否可靠。
第十步:补充未被现象识别排序表识别的参数,并根据电厂设计及相关实验数据给定其不确定性分布,该步骤的目的是为了防止某些对目标输出具有重要影响的输入参数未被现象识别排序表识别。
第十一步:初始被现象识别排序表识别的输入参数的不确定性分布于第四步中给定,第十步中额外补充了部分现象识别排序表之外的输入参数及其不确定性分布。根据所有这些参数的不确定性分布类型及其不确定性区间,可以通过查表确定这些参数的五个高斯点。
第十二步:使用优化的矩独立全局敏感性分析方法计算各个输入参数的敏感性指标。优化的矩独立全局敏感性分析方法原理如下:
矩独立全局敏感性分析方法旨在评估输入参数对目标输出概率密度函数的影响。假设函数y=g(x)存在k个输入参数,即x=(x1,x2,...,xk)t,每个输入参数服从概率分布fxi(xi),输入参数的不确定性可通过函数计算传播至输出y。将y的无条件概率密度函数和无条件累积分布函数表示为fy(y)和fy(y),将第i个输入参数xi取某一固定值时得到的y的条件概率密度函数和条件累积分布函数表示为fy|xi(y)和fy|xi(y)。根据定义,将第i个输入参数的矩独立敏感性指标表示为:
其中s(xi)为固定第i个输入参数情况下输出概率密度函数的偏移量:
将求解输出的概率密度函数转换为求解其累积分布函数可以在一定程度上优化计算结果。假设输出的fy(y)和fy|xi(y)存在m个交点,表示为a1,a2,...am,则s(xi)可以表示为(m+1)个子面积之和,即:
s(xi)=s1+s2+...+sj+...+sm+sm+1(j=1,2,...,m+1)(11)
其中,fy(y)和fy|xi(y)的交点可根据下式进行求解:
而每个子面积sj可根据如下关系式进行计算:
由此可知,如果能快速计算得到输出的fy(y)和fy|xi(y),则可根据式(9~13)计算得到各个输入参数的矩独立全局敏感性指标δi。
为了能以十分小的计算成本且又相对精确地计算输入参数的敏感性指标,使用了多种方法进行优化计算。首先,为了降低积分计算的计算量,使用五点高斯求积方案替代积分计算:
式中,ωi,j表示第i个输入参数按照其分布类型确定的五个高斯权重值中的第j个值,同理xi,j表示第i个输入参数的第j个高斯点取值。ωi,j和xi,j的取值与参数的分布类型及不确定性区间有关。
求解s(xi,j)的关键在于求解输出的条件和无条件累积分布函数,即fy(y)和fy|xi(y)。根据累积分布函数的定义,可将其表示为:
fy(y)=p{g(x)≤y}=p{g(x)-y≤0}=p{z(x,y)≤0}=pf{z(x,y)}(15)
其中,z(x,y)=g(x)-y为定义的新函数,pf为失效概率。因此,可将求解函数g(x)的累积分布函数转换为求解函数z(x,y)的失效概率,而高阶矩估计方法能被用于求解函数的失效概率。
本发明中使用四阶矩估计方法和皮尔森系统以求解函数的失效概率。根据皮尔森系统,可将函数输出的累积分布函数表示为:
其中,βsm=μz/sz,即函数z(x,y)输出的均值和标准差之比,基于函数z(x,y)输出的前四阶中心矩,可根据皮尔森系统确定f(z)的表达式。因此,求解函数z(x,y)输出的前四阶中心矩即可求解得到函数g(x)输出的累积分布函数,而函数z(x,y)与函数g(x)输出的前四阶中心矩存在以下关系:
其中α1z表示函数z(x,y)的一阶中心矩,α1g表示函数g(x)的一阶中心矩,以此类推。为了快速计算函数g(x)输出的前四阶中心矩,使用高维模型表示的降维技术将函数的输出表示为:
其中c为参考点,即所有输入参数取名义值时的输入参数向量;g0为参考点对应的函数输出;g(xi,c)表示其他参数均取名义值,仅改变第i个输入参数时函数的输出值,k为输入参数的数目。
基于函数g(x)输出的降维表达式,可将其前四阶中心矩表示为:
其中αmg表示g(x)输出的第m阶矩,m=1,2,3,4。根据五点高斯求积方案,将上式中的积分计算简化,可以得到:
由此可见,如果能求解得到每个输入参数xi在5个高斯点处的函数g(xi,j,c)的输出值,即可计算得到函数g(x)输出的无条件累积分布函数,即fy(y)。同理,将输入参数xi的取值依次固定于其5个高斯点,使用其余的(k-1)个输入参数执行相同的计算即可计算得到函数g(x)输出的条件累积分布函数,即fy|xi,j(y),进而可以计算得到每个输入参数的矩独立全局敏感性指标δi。
第十三步:基于本发明提出的新敏感性分析框架迭代修正现象识别排序表。
提出的新敏感性分析框架示意图如图3所示。最佳估算加不确定性分析方法的敏感性分析中,首先基于现象识别排序表识别对目标输出有较大影响的参数或者模型,而后建立对应的评估矩阵,进而确定核电厂的最佳节点化建模方案。基于核电厂的最佳估算模型,使用第十二步中开发的优化矩独立全局敏感性分析方法执行参数的筛选和重要度排序计算。需要说明的是,由于提出的优化矩独立全局敏感性分析方法计算量十分小,因此可以在执行敏感性分析计算中额外考虑部分未被现象识别排序表识别的输入参数,以防止部分重要参数被现象识别排序表遗漏而导致不确定性传播计算结果不充分的问题。计算得到参数的敏感性排序后,如存在重要参数没有被现象识别排序表包含,则需对现象识别排序表进行补充或者修正,并重新评估是否需要改变核电厂的节点建模方案,以此形成一个循环修正现象识别排序表的过程。最后,若所有的重要参数均包含于现象识别排序表中,则可根据最后一次迭代计算得到的矩独立全局敏感性指标对参数进行重要度排序,对目标输出没有影响的输入参数计算得到的敏感性指标为0。
第十四步:确定所有对目标输出有影响的重要输入参数:在敏感性分析过程中,能够计算获得所有输入对目标输出的全局敏感性指标,基于该计算结果,可以去除对目标输出影响较小或者没有影响的输入参数,使用剩下的参数执行后续不确定性传播计算。剩下的参数中既包含现象识别排序表参数,还可能包含部分第十步中补充的未被现象识别排序表识别的参数。
第十五步:确定不确定性传播计算所需的样本数量:采用高阶非参数阶数统计的方法确定不确定性传播计算所需的程序运行次数,该方法可以通过公式计算直接确定指定置信度下包络目标输出数据指定份额的最小程序计算次数。
第十六步:随机抽样生成输入样本并执行对应的程序计算。
第十七步:量化目标输出的不确定性并确定目标输出的容忍限值:由于通过程序计算获得了目标输出的多个计算样本值,因此可以根据第十五步中使用的高阶非参数阶数统计方法的阶数直接在计算值中确定目标输出的容忍限值。同时,可以使用输出的各计算样本估算输出的置信限值,比较容忍限值和置信限值以确保容忍限值的保守性。
第十八步:比较目标输出的容忍限值与第二步确定的安全接受限值,判断核电厂在事故工况下是否安全。
- 还没有人留言评论。精彩留言会获得点赞!