一种激光雷达场景三维姿态点法向量估计修正方法与流程
本发明属于激光雷达三维目标姿态估计技术领域,特别是涉及一种激光雷达场景三维姿态点法向量估计修正方法。
背景技术:
现有的姿态估计方法主要有主成分分析法(pca)、矩形包围盒法、模型匹配法和基于深度学习的方法。pca方法应用较为广泛,但其对目标点云分布的完备性要求较高,由于激光雷达得到的是单个视角下的距离像数据,因此pca方法并不适用。矩形包围盒法是基于汽车、坦克等目标具有类似矩形结构的特征,这种方法对遮挡较为敏感,会直接影响到姿态估计的结果。模型匹配法要求目标已知且具有完整的姿态模型库,目标点云特征和模型点云特征匹配度最高的姿态模型为目标点云姿态,在实际应用中较难实现。基于深度学习的姿态估计方法,一般针对二维图像,通过卷积神经网络获取姿态角数据。该方法需要大量的样本数据供训练使用,且对图像分辨率的要求较高。已提出的基于点法向量的姿态估计算法(pdva),这种方法对激光雷达仿真系统得到的无噪距离像具有较好的姿态估计效果,但对于真实激光雷达场景距离像,求得的代表法向量会产生较大的偏移,导致姿态估计与真实值存在一定的偏差。
技术实现要素:
本发明目的是为了解决现有技术中的问题,提出了一种激光雷达场景三维姿态点法向量估计修正方法。本发明应用于获取的真实场景距离像,通过ransac的平面模型,得到最优代表法向量,减小三维姿态估计误差。本发明针对真实场景距离像,通过随机抽样一致算法对聚类中的点法向量进行筛选,修正了代表法向量的偏差,获取最优代表法向量,三维姿态估计更精确。
本发明是通过以下技术方案实现的,本发明提出一种激光雷达场景三维姿态点法向量估计修正方法,根据场景目标代表法向量估计得出场景坐标系scs的xs、ys和zs轴,将scs转换为大地坐标系gcs的过程中,场景目标绕scs的坐标轴xs、ys和zs轴转换的角度即为三维姿态角偏航角ψ、俯仰角θ和滚转角φ;所述方法包括以下步骤:
步骤一:利用局部平面拟合的方法求得点云中各点的点法向量ni,计算出点法向量的质心
步骤二:根据点云中点法向量与质心向量之间夹角的分布,在夹角直方图中选出频次f大于阈值λ的夹角区间,选定区间的数量即为聚簇数量k;
步骤三:初步选取代表法向量;
在分类后的每个聚类δi,i=1,...,k中,对聚类δi中每个点法向量与聚类δi中的其他所有点法向量所成的夹角进行计算,并对所成的夹角进行求和,选取聚类δi中与其他点法向量夹角和最小的点法向量为代表法向量,记为npi;
对每个聚簇中的点加以计数,记为counti,选取counti最大的聚簇的代表点法向量为目标坐标系的一个方向向量记为n,依次选取按counti降序排列的聚簇代表点法向量计算其与n所成的角度,选取所成角度在[90°-δ,90°+δ]范围内的代表法向量为目标坐标系的另一个方向向量;其中δ是一个度数阈值,其大小根据实际情况进行相应调整;
步骤四:选取待拟合的点集对代表法向量进行修正;
计算聚类δi中所有点gi∈δi与代表法向量npi对应点的欧氏距离ρi,求得距离平均值
计算聚类δi中所有点法向量ni与代表法向量npi的夹角值θpi,选取夹角值小于45°的点,得到点集g2:
其中,代表法向量npi对应点坐标表示为(xp,yp,zp),点法向量ni对应点坐标表示为(xi,yi,zi),最后求得待拟合的点集为gd=g1∩g2;
步骤五:采用随机抽样一致算法得到最优拟合平面,计算最终代表法向量。
进一步地,所述步骤五具体为:
在迭代次数k范围内,每次随机抽取gd中的3个点得到拟合平面,求得点到拟合平面距离d,根据设定迭代次数k和距离阈值d,对gd中的点进行筛选,直至找到最佳拟合平面,求得最终代表法向量。
进一步地,所述点到拟合平面的距离求解如式(3)所示,式中[a,b-1,c]为随机选取3个点构建平面的参数;
附图说明
图1为本发明所述激光雷达场景三维姿态点法向量估计修正方法流程图;
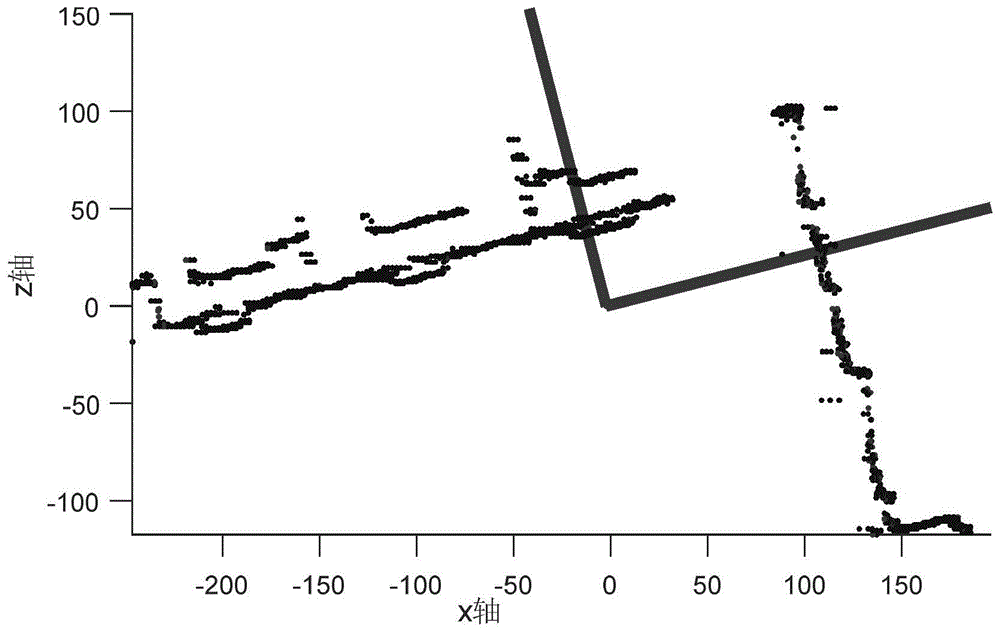
图2为场景代表法向量俯视示意图。
具体实施方式
下面将结合本发明实施例中的附图对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
结合图1,本发明提出一种激光雷达场景三维姿态点法向量估计修正方法,根据场景目标代表法向量估计得出场景坐标系scs的xs、ys和zs轴,将scs转换为大地坐标系gcs(geodeticcoordinatesystem)的过程中,场景目标绕scs的坐标轴xs、ys和zs轴转换的角度即为三维姿态角偏航角ψ、俯仰角θ和滚转角φ;所述方法包括以下步骤:
步骤一:利用局部平面拟合的方法求得点云中各点的点法向量ni,计算出点法向量的质心
步骤二:根据点云中点法向量与质心向量之间夹角的分布,在夹角直方图中选出频次f大于阈值λ的夹角区间,选定区间的数量即为聚簇数量k;
步骤三:初步选取代表法向量;
在分类后的每个聚类δi,i=1,...,k中,对聚类δi中每个点法向量与聚类δi中的其他所有点法向量所成的夹角进行计算,并对所成的夹角进行求和,选取聚类δi中与其他点法向量夹角和最小的点法向量为代表法向量,记为npi;
对每个聚簇中的点加以计数,记为counti,选取counti最大的聚簇的代表点法向量为目标坐标系的一个方向向量记为n,依次选取按counti降序排列的聚簇代表点法向量计算其与n所成的角度,选取所成角度在[90°-δ,90°+δ]范围内的代表法向量为目标坐标系的另一个方向向量;其中δ是一个度数阈值,其大小根据实际情况进行相应调整;
步骤四:选取待拟合的点集对代表法向量进行修正;
计算聚类δi中所有点gi∈δi与代表法向量npi对应点的欧氏距离ρi,求得距离平均值
计算聚类δi中所有点法向量ni与代表法向量npi的夹角值θpi,选取夹角值小于45°的点,得到点集g2:
其中,代表法向量npi对应点坐标表示为(xp,yp,zp),点法向量ni对应点坐标表示为(xi,yi,zi),最后求得待拟合的点集为gd=g1∩g2;
步骤五:采用随机抽样一致算法得到最优拟合平面,计算最终代表法向量,场景代表法向量俯视图如图2所示。
所述步骤五具体为:
在迭代次数k范围内,每次随机抽取gd中的3个点得到拟合平面,求得点到拟合平面距离d,根据设定迭代次数k和距离阈值d,对gd中的点进行筛选,直至找到最佳拟合平面,求得最终代表法向量。
所述随机抽样一致算法参数的选取主要涉及到两个参数,距离阈值d和迭代次数k的选取。
场景目标中,建筑存在窗户,阳台等细节,激光雷达实际距离像测距精度为0.1875米。因此,距离阈值选取d为1.5,即为激光雷达三倍的测距精度。所述点到拟合平面的距离求解如式(3)所示,式中[a,b-1,c]为随机选取3个点构建平面的参数;
设随机选定3个点估计平面,3个点均为正确数据的概率为w3,3个点中至少有1个为异常数据的概率为1-w3,则有:
1-p=(1-w3)k(4)
k在不大于最大迭代次数的情况下,是在不断更新而不是固定的,则有:
其中,p为置信度,一般取0.995;w为内点的比例,w=内点的数目/数据集的数目;m为计算模型所需要的最少样本数,m=3。
本发明针对场景点云存在大面积近似平面区域的特点,根据局部平面拟合和聚类算法实现对场景点云代表法向量的求取。通过设定聚类中各点与代表法向量的距离关系和各点法向量与代表法向量的夹角关系,对进行修正代表法向量的点集进行最优筛选。采用随机抽样一致算法对点集进行最优拟合平面选取,实现获得最优代表法向量。本发明通过该激光雷达场景三维姿态点法向量估计修正方法可估计场景目标最优代表法向量,获得场景目标精确的三维姿态。
以上对本发明所提出的一种激光雷达场景三维姿态点法向量估计修正方法,进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!