一种基于深度学习的盐体语义分割方法及语义分割模型与流程
本发明属于图像语义分割和深度学习领域,具体涉及一种基于深度学习的盐体语义分割方法及语义分割模型。
背景技术:
地球上有大量石油和天然气聚集的地区也会在地表下面形成巨大的盐沉积物,此外,盐体边界解析对于理解盐层构造和地震迁移速度的模型建设具有重要意义。目前专业的地震成像仍然需要专业人士解析盐体。手工设计的属性是根据专业知识设计的;但是这些属性可能尚未完全描述复杂的噪声污染的现实地震数据。这导致非常主观的,高度可变的结果。更令人担忧的是,这会给石油和天然气公司的钻探人员带来潜在的危险情况。近来的一些工作表明,深度学习能够应用于地质数据的分析,并且效果优于传统的方法。盐体的分类可以看作语义分割的范畴,本文提出利用深度学习算法对地质数据中的盐体进行语义分割。
目前,因为深度卷积神经网络的强大特征表征能力,基于深度卷积神经网络的方法在图像分类,目标检测和图像语义分割获得了巨大的进步。语义分割的目的就是给一个给定图像的每一个像素赋一个语义标签。
近年来,绝大多数当前最佳的图像语义分割方法都是基于全卷积神经网络的。全卷积神经网络结构是一个典型的编码器解码器结构,语义信息经过编码器被嵌入到特征图当中,然后解码器负责产生语义分割结果。通常解码器就是预训练好的卷积神经网络分类模型用于提取图像特征,而解码器则含有多种上采样操作,用于恢复图像分辨率。尽管编码器前端的特征图含有更多的语义但是在重建细节时会受限于低分辨率。为了解决它,我们需要更好的将高级别特征与低级别特征进行融合,避免高低级别的特征融合不充分,造成的语义分割结果的精度较低。
技术实现要素:
本发明的目的在于:现有的图像语义分割方法高低级别的特征融合不充分,因此受限于低分辨率令重建细节时造成语义分割结果精度较低,应用在盐体语义分割上时,影响得到的盐体数据准确性的问题,提出了一种基于深度学习的盐体语义分割方法。
本发明采用的技术方案如下:
一种基于深度学习的盐体语义分割方法,方法为:
构建基于深度学习的盐体语义分割模型,盐体语义分割模型包括:预处理模型、分类监督模块、特征重校正模块、特征融合模块、盐体分割分支模块、整体分割分支模块、边缘预测模块、上采样层,在语义分割模型中:预处理模型对图像进行预处理得到不同尺度的特征图,不同尺度的特征图分别依次经过特征重校正模块,然后分别输入对应的上采样层,再输入特征融合模块将每级尺度对应上采样的特征图与上一级尺度对应上采样的特征图级联,最后再分别输入特征重校正模块,将得到结果中最末一级尺度的特征图分别输入盐体分割分支模块、整体分割分支模块、边缘预测模块,其中分类监督模块对整个过程中每个模块输出特征图进行监督预测是否有盐;
选择盐体图像的训练数据集,输入构建的盐体语义分割模型,并对盐体语义分割模型进行训练,模型训练过程中将盐体分割分支模块、整体分割分支模块、边缘预测模块和分类监督模块的损失进行混合作为总损失,根据总损失进行模型参数更新;
输入待分析盐体图像到训练好的盐体语义分割模型,端到端地输出预测的语义分割结果。
进一步,所述预处理模型为resnet34,包括1个convolution层、一个maxpool层、4个残差连接块,其中第一个残差连接块包含3个残差块,有6个3×3的卷积层,第二个残差连接块包含4个残差块,有8个3×3的卷积层,第三个残差连接块包含6个残差块,有12个3×3的卷积层,第四个残差连接块包含3个残差块,有6个3×3的卷积层,每个残差连接块都采用残差连接,预处理模型输出的特征图分别为特征图dn_1、特征图dn_2、特征图dn_3和特征图dn_4。
进一步,所述分类监督模块包括:1个1×1的卷积、1个全局池化层和1个全连接层,分类监督模块对图片进行判别为有盐还是无盐。
进一步,所述特征重校正模块为结合空间特征重校正模块与通道特征重校正模块的网络模块。
进一步,所述盐体分割分支模块包括1个3×3卷积层和一个1×1卷积层,输出为含盐的特征图。
进一步,所述整体分割分支模块包括1个3×3卷积层和一个1×1卷积层,输出为整体的特征图。
进一步,所述边缘预测模块包括拉普拉斯算子卷积层、tanh激活层以及relu激活层,输出为边缘预测特征图,公式为δf=relu(tanh(conv(f,klaplace)),其中,δf表示边缘预测特征图,f表示特征图,klaplace表示拉普拉斯算子的卷积核,conv()表示拉普拉斯算子卷积层去卷积特征图,tanh()表示tanh激活层处理得到的特征图,relu()表示relu激活层处理得到的特征图。
进一步,所述对语义分割模型进行模型训练的具体步骤为:
对训练数据集中的图像进行数据预处理,将图像剪裁为固定尺寸;
对预处理后的训练数据集数据通过上下翻转、缩放和旋转的方式进行扩增,并加载预训练好的imagenet图像分类模型,对整个盐体语义分割模型进行初始化;
将扩增后的训练数据集输入盐体语义分割模型,记训练过程中模型整体分割分支预测的语义分割结果与标注图像的lovasz_hingeloss为lossfinal,盐体分割分支预测的语义分割结果与标注图像的lovasz_hingeloss为lossno_empty,分类监督模块预测的图片结果与图片标签的交叉熵损失为lossclass,边缘预测模块预测的边缘结果与标注图像提取的边缘的交叉熵损失为lossb,则训练过程中的总损失误差记为losstotal=lossfinal+0.5*lossno_empty+0.05*lossclass1+0.5*lossb,根据总损失误差losstotal使用随机梯度下降算法进行误差反向传播,用循环学习率策略,更新模型参数,得到训练好的语义分割模型。
一种基于深度学习的语义分割模型,语义分割模型包括:预处理模型、分类监督模块、特征重校正模块、特征融合模块、目标分割分支模块、整体分割分支模块、边缘预测模块、上采样层和卷积层,在语义分割模型中:预处理模型对待分割图像进行预处理得到不同尺度的特征图,不同尺度的特征图输入后分别依次经过特征重校正模块,然后分别输入对应的上采样层,再输入特征融合模块将每级尺度对应上采样的特征图与上一级尺度对应上采样的特征图级联,最后再分别输入特征重校正模块,将得到结果中最末一级尺度的特征图分别输入目标分割分支模块、整体分割分支模块、边缘预测模块,其中分类监督模块对整个过程中每个模块输出特征图进行监督预测是否含有目标。
进一步,
所述预处理模型为resnet34,包括1个convolution层、一个maxpool层、4个残差连接块,其中第一个残差连接块包含3个残差块,有6个3×3的卷积层,第二个残差连接块包含4个残差块,有8个3×3的卷积层,第三个残差连接块包含6个残差块,有12个3×3的卷积层,第四个残差连接块包含3个残差块,有6个3×3的卷积层,每个残差连接块都采用残差连接;
所述分类监督模块包括:1个1×1的卷积、1个全局池化层和1个全连接层;
所述特征重校正模块为结合空间特征重校正模块与通道特征重校正模块的网络模块;
所述目标分割分支模块包括1个3×3卷积层和一个1×1卷积层,输出为含目标的特征图;
所述整体分割分支模块包括1个3×3卷积层和一个1×1卷积层,输出为整体的特征图;
所述边缘预测模块包括拉普拉斯算子卷积层、tanh激活层以及relu激活层,输出为边缘预测特征图,公式为δf=relu(tanh(conv(f,klaplace)),其中,δf表示边缘预测特征图,f表示特征图,klaplace表示拉普拉斯算子的卷积核,conv()表示拉普拉斯算子卷积层去卷积特征图,tanh()表示tanh激活层处理得到的特征图,relu()表示relu激活层处理得到的特征图。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
1、本发明中,所述基于深度学习的盐体语义分割方法采用预处理模型做基础模型进行特征提取,得到的特征图经过分类监督模块预测图片有盐与否作为辅助监督加速收敛,同时监督盐体分割分支模块输出的含盐图片分割结果和整体分割分支模块输出的所有图片分割结果,边缘预测模块输出边缘预测结果,组成混合损失有效提高盐体分割精度,最终得到较好的语义分割结果。并且其中每级上采样的特征图经过特征融合模块,将每级上采样的特征图与上一级上采样特征图级联,这样逐级加强特征通道信息的密集获取,更好的利用每级上采样的特征图信息,更好的融合高层的语义信息和底层的空间信息。
2、本发明中,预处理模型中的中每个残差连接块(residualblock)都采用残差连接,即每个残差块的输出都包含输入的特征图,它的输出被传递至每个后续层,而且每个残差块的特征图都是通过深度加和在一起。这种跳跃连接结构加强了特征图的传递,更加有效地利用特征,便于后续的精准处理。
3、本发明中,特征重校正模块包括空间特征重矫正模块与通道特征重矫正模块,通过给不同尺度的特征图均直接分配一个特征重校正模块,能够实现空间特征重矫正与通道特征重矫正,自适应的学习与当前任务更有利的空间信息和通道信息。具体地,空间特征重校正能够更好的将空间中所有同一位置像素的重要性得到重新校正,并赋以相应的权值,提高语义分割的准确率,通道特征重校正能够将重要的通道赋以高权值,突出重要性。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
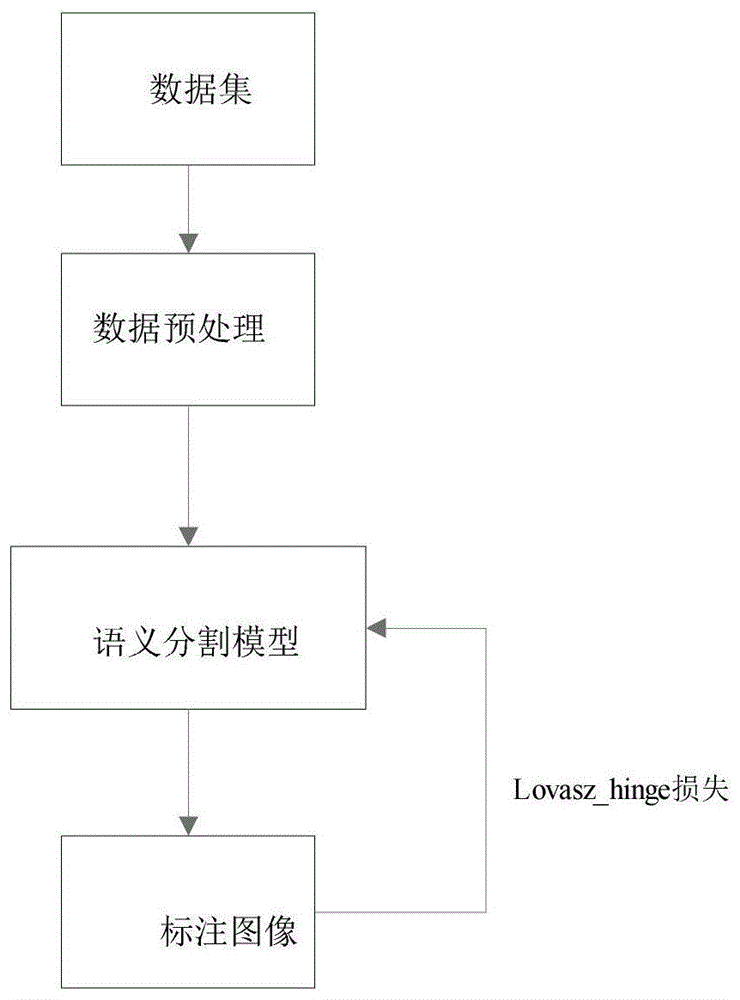
图1为本发明盐体语义分割模型训练的流程示意图;
图2为本发明盐体语义分割模型结构示意图;
图3为本发明分类监督模块结构示意图;
图4为本发明特征融合模块结构示意图;
图5为本发明特征重校正模块结构示意图;
图6为本发明空间特征重校正模块结构示意图:
图7为本发明通道特征重校正模块结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明,即所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,术语“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个......”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
一种基于深度学习的语义分割模型,语义分割模型包括:预处理模型、分类监督模块、特征重校正模块、特征融合模块、目标分割分支模块、整体分割分支模块、边缘预测模块、上采样层和卷积层,在语义分割模型中:预处理模型对待分割图像进行预处理得到不同尺度的特征图,不同尺度的特征图输入后分别依次经过特征重校正模块,然后分别输入对应的上采样层,再输入特征融合模块将每级尺度对应上采样的特征图与上一级尺度对应上采样的特征图级联,最后再分别输入特征重校正模块,将得到结果中最末一级尺度的特征图分别输入目标分割分支模块、整体分割分支模块、边缘预测模块,其中分类监督模块对整个过程中每个模块输出特征图进行监督预测是否含有目标。
所述预处理模型为resnet34,包括1个convolution层、一个maxpool层、4个残差连接块,其中第一个残差连接块包含3个残差块,有6个3×3的卷积层,第二个残差连接块包含4个残差块,有8个3×3的卷积层,第三个残差连接块包含6个残差块,有12个3×3的卷积层,第四个残差连接块包含3个残差块,有6个3×3的卷积层,每个残差连接块都采用残差连接;
所述分类监督模块包括:1个1×1的卷积、1个全局池化层和1个全连接层;
所述特征重校正模块为结合空间特征重校正模块与通道特征重校正模块的网络模块;
所述目标分割分支模块包括1个3×3卷积层和一个1×1卷积层,输出为含目标的特征图;
所述整体分割分支模块包括1个3×3卷积层和一个1×1卷积层,输出为整体的特征图;
所述边缘预测模块包括拉普拉斯算子卷积层、tanh激活层以及relu激活层,输出为边缘预测特征图,公式为δf=relu(tanh(conv(f,klaplace)),其中,δf表示边缘预测特征图,f表示特征图,klaplace表示拉普拉斯算子的卷积核,conv()表示拉普拉斯算子卷积层去卷积特征图,tanh()表示tanh激活层处理得到的特征图,relu()表示relu激活层处理得到的特征图。
本模型可以用于对各种图片进行不同的目标语义分割,对不同的目标在本模型基础上相应地进行不同目标数据的变换,例如可以对图片进行某种物品语义分割或者人体语义分割等等,本发明中基于深度学习的盐体语义分割方法采用该模型对图片进行盐体语义分割。本发明中实施例以盐体为目标进行语义分割。
以下结合实施例对本发明的特征和性能作进一步的详细描述。
实施例1
本发明较佳实施例提供的一种基于深度学习的盐体语义分割方法,方法步骤如图1所示方法为:
步骤1:构建基于深度学习的盐体语义分割模型,盐体语义分割模型包括:预处理模型、分类监督模块、特征重校正模块、特征融合模块、盐体分割分支模块、整体分割分支模块、边缘预测模块、上采样层,在语义分割模型中:预处理模型对图像进行预处理得到不同尺度的特征图,不同尺度的特征图分别依次经过特征重校正模块,然后分别输入对应的上采样层,再输入特征融合模块将每级尺度对应上采样的特征图与上一级尺度对应上采样的特征图级联,最后再分别输入特征重校正模块,将得到结果中最末一级尺度的特征图分别输入盐体分割分支模块、整体分割分支模块、边缘预测模块,其中分类监督模块对整个过程中每个模块输出特征图进行监督预测是否有盐。
需要说明的是:得到的不同尺度的特征图,相同大小特征图的网络模块组合在一起称之为[一级],尺度则单纯指大小。预处理器即编码器,「端到端」英文称之为「end-to-end」,表示:输入一张图片,输出一张分割结果,简单一体化。
所述分类监督模块包括:1个1×1的卷积、1个全局池化层和1个全连接层,分类监督模块对图片进行判别为有盐还是无盐。
所述特征重校正模块为结合空间特征重校正模块与通道特征重校正模块的网络模块。
所述盐体分割分支模块包括1个3×3卷积层和一个1×1卷积层,输出为含盐的特征图。
所述整体分割分支模块包括1个3×3卷积层和一个1×1卷积层,输出为整体的特征图。
所述边缘预测模块包括拉普拉斯算子卷积层、tanh激活层以及relu激活层,输出为边缘预测特征图,公式为δf=relu(tanh(conv(f,klaplace)),其中,δf表示边缘预测特征图,f表示特征图,klaplace表示拉普拉斯算子的卷积核,conv()表示拉普拉斯算子卷积层去卷积特征图,tanh()表示tanh激活层处理得到的特征图,relu()表示relu激活层处理得到的特征图。
步骤2、选择盐体图像的训练数据集,本实施例中以kaggle平台举办的竞赛tgssaltidentificationchallenge提供的数据集。
步骤3、对构建的盐体语义分割模型进行模型训练,模型训练过程中将盐体分割分支模块、整体分割分支模块、边缘预测模块和分类监督模块的损失进行混合作为总损失,根据总损失进行模型参数更新。
本实施例中采用训练数据集对盐体语义分割模型进行模型训练的具体步骤如图1所示,具体为:
对训练数据集中的图像进行数据预处理,将图像剪裁为固定尺寸(这里的预处理是对图像简单的归一化,裁剪固定尺寸等等,以适应要求和方便网络训练);
对预处理后训练数据集中的数据通过上下翻转、缩放和旋转的方式进行扩增,并加载预训练好的imagenet图像分类模型,对整个盐体语义分割模型进行初始化(「预训练好的imagenet图像分类模型」是指在imagenet数据集上训练好的分类模型的预训练权重,虽然分类和分割不是同一个任务,但是为了减少训练时间,可以用分类模型的预训练模型权重去初始化分割网络);
将扩增后训练数据集输入盐体语义分割模型,先对训练数据集图像在预处理模型中进行预处理,得到不同尺度的特征图。所述预处理模型为resnet34,包括1个convolution层、一个maxpool层、4个残差连接块,输出的特征图分别为特征图dn_1、特征图dn_2、特征图dn_3和特征图dn_4。具体结构如下表所示:
从上表可以看出,预处理模型中,第一个残差连接块包含3个残差块,有6个3×3的卷积层,第二个残差连接块包含4个残差块,有8个3×3的卷积层,第三个残差连接块包含6个残差块,有12个3×3的卷积层,第四个残差连接块包含3个残差块,有6个3×3的卷积层。预处理模型中的中每个残差连接块(residualblock)都采用残差连接,即每个残差块的输出都包含输入的特征图,它的输出被传递至每个后续层,而且每个残差块的特征图都是通过深度加和在一起。这种跳跃连接结构加强了特征图的传递,更有效地利用特征。取残差块(1)输出的特征图(尺寸为64×64)、残差块(2)输出的特征图(尺寸为32×32)、残差块(3)输出的特征图(尺寸为16×16)、残差块(4)输出的特征图(尺寸为8×8)分别为网络结构中提取特征(编码器)的第一层(记为dn_1)、第二层(记为dn_2)、第三层(记为dn_3)和第四层(记为dn_4)。
将基于上述预处理模型的不同尺度的特征图输入构建好的盐体语义分割模型中的特征重校正模块(scse)中,特征图dn_1、特征图dn_2、特征图dn_3和特征图dn_4经过特征重校正模块后的输出图分别为输出图ss_1、输出图ss_2、输出图ss_3和输出图ss_4,通过给resnet输出的特征图dn_1、特征图dn_2、特征图dn_3、特征图dn_4均直接分配一个特征重校正模块,能够实现空间特征重矫正与通道特征重矫正,自适应的学习与当前任务更有利的空间信息和通道信息。
然后将ss_1,ss_2,ss_3,ss_4分别输入到对应的上采样层,输出的特征图分别记为u_1,u_2,u_3,u_4,然后再分别输入特征融合模块和特征重校正模块(scse),输出的特征图分别记为dss_1,dss_2,dss_3,dss_4,输出图ss_4输入到分类监督模块,分类监督模块如图3所示。盐体语义分割模型结构图如图2所示,图里面对应的过程为:
fs指代特征融合模块(featurefusion),包含上采样,级联的操作;ss-1~4对应预处理模型(即编码器)的每级特征图,尺度从大到小,dss_1~4对应解码器的每级特征图,尺度从小到大;级联后输出进入分割模块的是第4级dss_4,图中对应输出进入分割模块的是1/2尺度特征图。
如图4所示,特征融合模块是一个将高层特征融入到低层特征的模块,主要是将每级上采样的特征图与上一级上采样特征图级联,这样逐级加强特征通道信息的密集获取,更好的利用每级上采样的特征图信息。
如图5所示,本发明的特征重校正模块为结合了空间特征重校正与通道特征重校正的网络模块。下面将分开进行说明:
如图6所示,空间特征重校正模块中过程为:
(1)将原始特征图
(2)再将其经过一个sigmoid层,将mc的每个空间位置m′(i,,j),i∈{1,2,...,h},j∈{1,2,...,w}的重要性重新校正,并赋以每个空间位置一个权值p(i,j),得到的p(i,j)与原始特征图mc进行点乘。
最终,mc经过空间特征重校正得到的特征图为:
空间特征重校正能够更好的将空间中所有同一位置像素的重要性得到重新校正,并赋以相应的权值,提高语义分割的准确率。
如图7所示,通道特征重校正模块中过程为:
(1)将原始特征图
(2)整合后的特征图再经过一个线性修正单元,对特征进行修正。
(3)对修正后的特征图最后再经过一个卷积核大小为h×w,通道数为c的卷积得到一个特征向量
(4)特征图再经过一个sigmoid层,将特征向量z的激活范围限定在[0,1]之间,得到一个通道权值向量
经过通道特征重校正,能够将重要的通道赋以高权值,突出重要性。
将ss_4输入分类监督模块,得到预测的图片类别结果(有盐/无盐),将dss_4(即最末一级尺度的特征图)输入盐体分割分支模块,得到含盐特征图,将dss_4输入整体分割分支模块,得到全部图片特征图,将dss_4输入边缘预测模块得到预测的的边缘预测特征图(即边缘结果)。
训练过程中计算模型整体分割分支模块预测的全部图片特征图与语义分割标注的lovasz_hingeloss(lossfinal),计算盐体分割分支预测的含盐特征图与语义分割标注的lovasz_hingeloss(lossno_empty),计算分类监督模块预测的图片类别结果(有盐/无盐)与图片标签的交叉熵损失lossclass,计算边缘预测模块预测的边缘预测特征图(即边缘结果)与标注图像提取的边缘的交叉熵损失lossb,训练过程中的总损失误差记为losstotal=lossfinal+0.5*lossno_empty+0.05*lossclassl+0.5*lossb,根据总损失误差losstotal使用随机梯度下降算法进行误差反向传播,用循环学习率策略,更新模型参数,得到训练好的语义分割模型。
输入待分析盐体图像到训练好的盐体语义分割模型,进行一次前向传播,端到端地输出预测的语义分割结果。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!