一种基于百科词条自动构建影视综知识图谱的方法与流程
本发明涉及知识图谱技术领域,具体地说,涉及一种基于百科词条自动构建影视综知识图谱的方法。
背景技术:
知识图谱被称为下一代ai系统的基石,越来越多的人们已经逐渐意识到知识图谱的重要性。知识图谱最早是由google公司在2012年提出来的一个概念。从学术的角度,可以对知识图谱给一个这样的定义:“知识图谱本质上是语义网络的知识库”。从实际应用的角度出发可以简单地把知识图谱理解成多关系图(multi-relationalgraph)。其中节点和边是构成知识图谱的重要部分,创建知识图谱必须要创建节点和连接节点对应的边。现有知识图谱构建流程大都是开放领域的,影视综领域相关的知识图谱少之又少。目前大多数知识图谱构建流程使用了多个数据源且数据获取难度大,致使各个数据源的融合和数据的获取成为图谱自动化建设的一大难点。影视综图谱以明星、电影、电视剧等为核心,可以挖掘明星之间的隐含关系,也可以针对影视综做一些问答系统和电影推荐等。
技术实现要素:
本发明的目的在于提供一种基于百科词条自动构建影视综知识图谱的方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供一种基于百科词条自动构建影视综知识图谱的方法,其方法包括如下步骤:
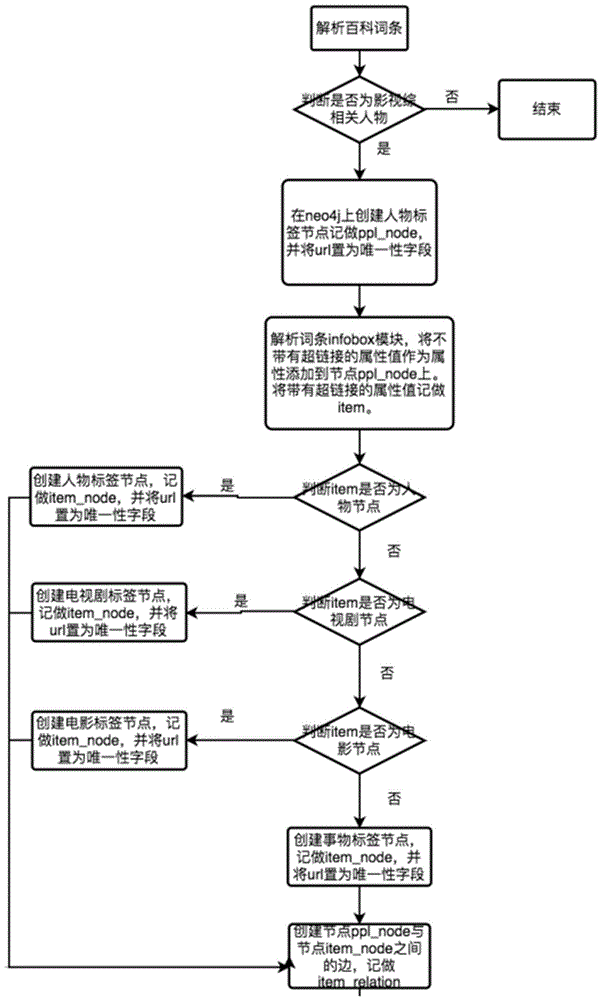
步骤一:解析百科词条;
步骤二:将词条名称、词条简介、词条infobox和词条标签传入分类模型判断是否为影视综相关人物,如果是,则继续执行步骤三,如果否,则结束;
步骤三:在neo4j上创建人物标签节点,记做ppl_node,并将url置为唯一性字段;
步骤四:解析词条infobox模块;
步骤五:将item对应的词条名称、词条简介、词条infobox和词条标签传入分类模型判断item是否为人物节点,如果是,则根据item创建人物标签节点,记做item_node,并将url置为唯一性字段,执行步骤九,如果否,则执行步骤六;
步骤六:将item对应的词条名称、词条简介、词条infobox和词条标签传入分类模型判断item是否为电视剧节点,如果是,则根据item创建电视剧标签节点,记做item_node,并将url置为唯一性字段,执行步骤九,如果否,则执行步骤七;
步骤七:将item对应的词条名称、词条简介、词条infobox和词条标签传入分类模型判断item是否为电影节点,如果是,则根据item创建电影标签节点,记做item_node,并将url置为唯一性字段,执行步骤九,如果否,则执行步骤八;
步骤八:根据item创建事物节点,记做item_node,并将url置为唯一性字段;
步骤九:创建节点ppl_node和节点item_node之间的边;
步骤十:解析参演电影模块,创建电影标签节点记做movie_node,并将url置为唯一性字段;
步骤十一:创建ppl_node与节点movie_node之间的边;
步骤十二:根据饰演字段创建角色节点记做role_node1,并将url置为唯一性字段;
步骤十三:创建ppl_node与节点role_node1之间的边;
步骤十四:解析参演电视剧模块,创建电视剧标签节点记做tv_series_node,并将url置为唯一性字段;
步骤十五:创建ppl_node与节点tv_series_node之间的边;
步骤十六:根据饰演字段创建角色标签节点记做role_node2,并将url置为唯一性字段;
步骤十七:创建ppl_node与节点role_node2之间的边。
作为优选,所述步骤四中,解析词条infobox模块具体为:将不带有超链接的属性值作为属性添加到节点ppl_node上,将带有超链接的属性值和对应的链接记做item。
作为优选,所述步骤九中,节点ppl_node和节点item_node之间的边,记做item_relation。
作为优选,所述步骤十一中,ppl_node与节点movie_node之间的边,记做starred_relation1。
作为优选,所述步骤十三中,ppl_node与节点role_node1之间的边,记做act_relation1。
作为优选,所述步骤十五中,ppl_node与节点tv_series_node之间的边,记做starred_relation1。
作为优选,所述步骤十七中,ppl_node与节点role_node2之间的边,记做act_relation2。
与现有技术相比,本发明的有益效果:
1、该基于百科词条自动构建影视综知识图谱的方法中,采用百科词条作为数据源,数据源易获得,容易复现,同时,数据源单一,不存在数据融合的问题。
2、该基于百科词条自动构建影视综知识图谱的方法中,将百科词条infobox、参演电影、参演电视剧模块转化为创建图谱节点和边的解析,根据百科词条判断是否为影视综相关人物,实现影视综领域图谱自动化建设。
附图说明
图1为本发明的整体流程局部图之一;
图2为本发明的整体流程局部图之二;
图3为本发明的整体流程局部图之三;
图4为本发明的效果图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-图4所示,本发明提供一种技术方案:
本发明提供一种基于百科词条自动构建影视综知识图谱的方法,其方法包括如下
步骤一:解析百科词条;
步骤二:将词条名称、词条简介、词条infobox和词条标签传入分类模型判断是否为影视综相关人物,如果是,则继续执行步骤三,如果否,则结束;
步骤三:在neo4j上创建人物标签节点,记做ppl_node,并将url置为唯一性字段;
步骤四:解析词条infobox模块,将不带有超链接的属性值作为属性添加到节点ppl_node上,将带有超链接的属性值和对应的链接记做item;
步骤五:将item对应的词条名称、词条简介、词条infobox和词条标签传入分类模型判断item是否为人物节点,如果是,则根据item创建人物标签节点,记做item_node,并将url置为唯一性字段,执行步骤九,如果否,则执行步骤六;
步骤六:将item对应的词条名称、词条简介、词条infobox和词条标签传入分类模型判断item是否为电视剧节点,如果是,则根据item创建电视剧标签节点,记做item_node,并将url置为唯一性字段,执行步骤九,如果否,则执行步骤七;
步骤七:将item对应的词条名称、词条简介、词条infobox和词条标签传入分类模型判断item是否为电影节点,如果是,则根据item创建电影标签节点,记做item_node,并将url置为唯一性字段,执行步骤九,如果否,则执行步骤八;
步骤八:根据item创建事物节点,记做item_node,并将url置为唯一性字段;
步骤九:创建节点ppl_node和节点item_node之间的边,记做item_relation;
步骤十:解析参演电影模块,创建电影标签节点记做movie_node,并将url置为唯一性字段;
步骤十一:创建ppl_node与节点movie_node之间的边,记做starred_relation1;
步骤十二:根据饰演字段创建角色节点记做role_node1,并将url置为唯一性字段;
步骤十三:创建ppl_node与节点role_node1之间的边,记做act_relation1;
步骤十四:解析参演电视剧模块,创建电视剧标签节点记做tv_series_node,并将url置为唯一性字段;
步骤十五:创建ppl_node与节点tv_series_node之间的边,记做starred_relation1;
步骤十六:根据饰演字段创建角色标签节点记做role_node2,并将url置为唯一性字段;
步骤十七:创建ppl_node与节点role_node2之间的边,记做act_relation2。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的仅为本发明的优选例,并不用来限制本发明,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!