基于多源辅助信息的协同过滤推荐系统及方法与流程
本发明属于推荐系统技术领域,具体涉及基于多源辅助信息的协同过滤推荐系统及方法。
背景技术:
传统的协同过滤推荐方法基于用户显式交互行为的相似性,找出邻域用户并进行推荐。在推荐过程中,协同过滤方法只依赖用户的评分等显式交互信息,无需物品的描述性信息,因此,对于某些专业性较强的领域,协同过滤方法比基于内容的推荐方法拥有更好的适应性。由于协同过滤方法需要用到用户的显式交互信息,显式交互数据的稀疏性问题是协同过滤推荐的一大难题,现有的关于协同过滤推荐系统中数据稀疏性问题的研究大致有两个方向:一个方向是在协同过滤方法上进行创新,如矩阵分解等,这些新方法依旧需要用户评分等显式交互信息;另一个方向是借助辅助信息,这些研究通常是在评分信息的基础上引入辅助信息,来缓解稀疏性问题并提升推荐效果。vasile等使用物品的源信息作为辅助信息,即物品的类别信息,对物品序列和源信息序列同时进行嵌入,进而预测用户未来可能感兴趣的物品。刘卫东等研究电影评分及高考成绩的预测问题,将电影类型以及考生个人信息等辅助信息加入变分自编码器,并引入评分行为的负反馈信息,提高了预测的准确度。在各种辅助信息中,文本类辅助信息使用最为频繁,尤其是用户评论文本,因为其经常伴随着评分信息一起出现,且主观情感较强,从中能直接挖掘出用户的喜好。李琳等对潜在主题因素模型(hft:hiddenfactorsastopics)进行了改进,将用户评论集和商品评论集各自的潜在主题向量与传统矩阵分解的用户潜在因子向量和商品潜在因子向量建立正向的映射关系,并添加潜在主题作为评分预测的引导项。almahairi等从词袋模型和循环神经网络模型两方面对评论文本进行建模,构造凸函数来同时优化矩阵分解和文本建模的结果,使得推荐效果优于以lda模型进行建模的方法。karamanolakis等把变分自编码器运用到基于评论辅助信息的协同过滤推荐中,通过将用户相关的先验分布信息加入到编码器的潜在空间中,对评论文本中的用户偏好信息进行编码,使得潜在空间同时考虑了评论和评分两方面的信息。wu等构建了两个学习模块来分别学习用户评论文本中的特征和用户-物品交互数据中的特征,其中评论文本特征的学习模块使用卷积操作和注意力机制,最后将两个模块学到的特征进行动态的线性融合来预测最终评分。然而,当显式交互信息缺失时,完全利用辅助信息挖掘用户潜在偏好并进行协同过滤推荐的研究相对较少。
技术实现要素:
本发明解决的问题是,当显式交互信息缺失时,完全利用辅助信息挖掘用户潜在偏好并进行协同过滤推荐;为解决所述问问题,本发明提供一种基于多源辅助信息的协同过滤推荐系统及方法。
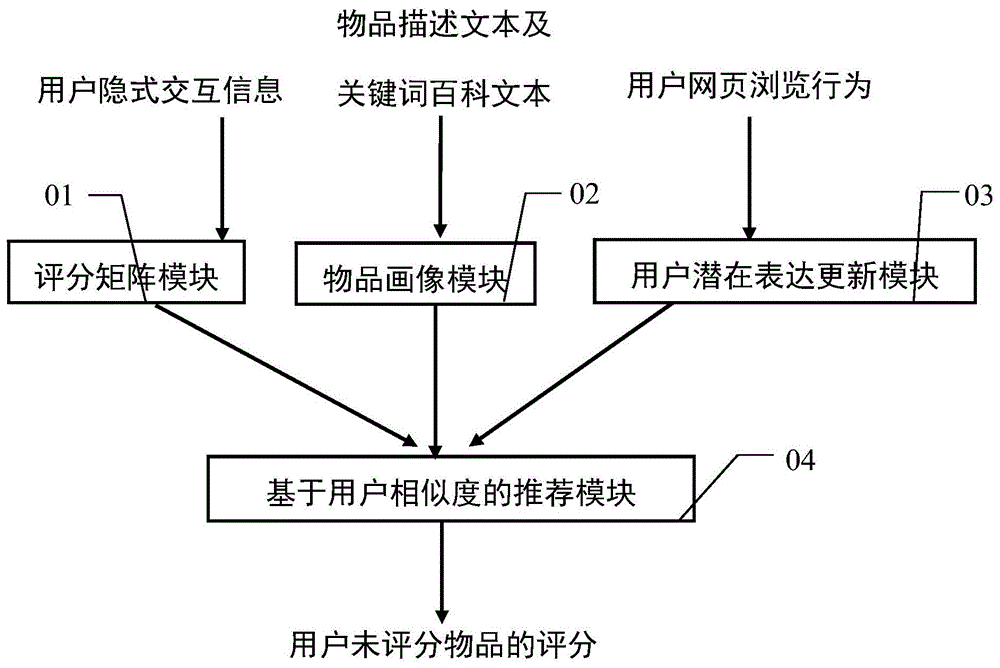
本发明提供的基于多源辅助信息的协同过滤推荐系统包括:评分矩阵模块、物品画像模块、用户潜在表达更新模块、基于用户相似度的推荐模块;所述评分矩阵模块基于预先定义的评分指标及用户偏好函数,从用户隐式交互信息中挖掘潜在偏好,向基于用户相似度的推荐模块输出用户评分矩阵;所述物品画像模块获取领域相关的物品描述文本及关键词百科文本,提取文本特征,向基于用户相似度的推荐模块输出物品特征向量;所述用户潜在表达更新模块获取用户网页浏览行为信息,根据网页文本内容,向基于用户相似度的推荐模块输出用户潜在表达的更新权重;所述基于用户相似度的推荐模块根据所述评分矩阵、物品特征向量和用户潜在表达的更新权重,计算用户相似度,输出用户未评分物品的预测评分。
进一步,所述评分矩阵模块包含评分指标子模块和偏好函数子模块,所述评分指标子模块包括用户个人兴趣度、物品公共影响力以及用户忠实度三个评分指标;用户u对物品i的个人兴趣度
进一步,所述物品画像模块包括物品-关键词向量子模块和物品-主题向量子模块,所述物品-关键词向量子模块从物品表述文本中提取领域关键词,根据关键词词频,将物品向量化表示:vi1=(k1,k2,...km),其中,vi1是物品i的关键词词频向量,(k1,k2,...km)为各领域关键词在物品i的描述文本中出现的次数,m为领域数;所述物品-主题向量子模块将物品描述文本与关键词百科文本组合,构建物品的领域相关文本,采用主题模型进行文本建模,将物品向量化表示:vi2=(t1,t2,...tn),其中,vi2是物品i的主题向量,(t1,t2,...tn)为各主题在物品i的领域相关文本中的分布值,n为主题数;将物品-关键词向量vi1与物品-主题向量vi2合并,得到物品i的画像pitem(i),物品i的特征向量形式为:vi=(k1,k2,...km,...t1,t2,...tn)。
进一步,所述用户潜在表达更新模块包含跨领域词向量训练子模块和更新权重计算子模块,所述跨领域词向量训练子模块以用户浏览的网页文本内容为源领域语料库ds,以所有物品的领域相关文本为目标领域语料库dt;先采用word2vec方法分别训练源领域词向量ws和目标领域词向量wt,再采用跨领域词嵌入方法,根据跨领域词的重要性,训练跨领域词向量w′t;设定β为词数阈值,vu为用户的潜在表达;若跨领域关键词词数c≥β,采用独立更新规则,包括:对于每个领域关键词k∈pitem∩{ω|ω∈dt∩ds},计算跨领域词向量w′t(k)与目标领域词向量wt(k)的余弦相似度sim(wt(k),w′t(k))作为每个领域关键词各自的更新权重,采用独立更新规则更新用户潜在表达的对应维度v′u,k=vu,k*(1+sim(wt(k),w′t(k)));若跨领域关键词词数c<β,采用整体更新规则,包括:对于每个跨领域词ω∈dt∩ds,计算跨领域词向量w′t与目标领域词向量wt的余弦相似度sim(wt,w′t),对所有跨领域词的相似度取平均值作为所有跨领域关键词共享的更新权重:
进一步,所述基于用户相似度的推荐模块首先采用niu等人提出的用户ctri值方法,考虑用户评分信息的并集以及物品画像,计算融合多源辅助信息后的用户潜在表达(latentrepresentation):
本发明的优点包括:本发明实施例提供的基于多源辅助信息的协同过滤推荐系统及方法,首先,利用用户隐式交互行为信息来挖掘偏好并生成评分,使得缺少用户显式交互信息的领域也能采用协同过滤方法进行推荐任务。其次,本发明基于跨领域词向量来挖掘用户的网页浏览行为,使得用户偏好信息尽可能全面。最后,本发明采用了能够缓解稀疏性问题的相似度计算方法来计算用户相似度并进行协同过滤推荐。
附图说明
图1是本发明实施例提供的基于多源辅助信息的协同过滤推荐系统的框架图。
具体实施方式
下面结合附图和实施例,对本发明提供基于多源辅助信息的协同过滤推荐系统及方法做进一步阐述。
如图1所示,本发明提供的基于多源辅助信息的协同过滤推荐系统,包括:评分矩阵模块01、物品画像模块02、用户潜在表达更新模块03、基于用户相似度的推荐模块04。
结合图1,所述评分矩阵模块01基于预先定义的评分指标及用户偏好函数,从用户隐式交互信息中挖掘潜在偏好,向基于用户相似度的推荐模块输出用户评分矩阵。所述评分矩阵模块01包含评分指标子模块和偏好函数子模块,所述评分指标子模块包括用户个人兴趣度、物品公共影响力以及用户忠实度三个评分指标;用户u对物品i的个人兴趣度
继续结合图1,所述物品画像模块02获取领域相关的物品描述文本及关键词百科文本,提取文本特征,向基于用户相似度的推荐模块输出物品特征向量;所述物品画像模块包括物品-关键词向量子模块和物品-主题向量子模块,所述物品-关键词向量子模块从物品表述文本中提取领域关键词,将物品向量化表示:vi1=(k1,k2,...km),其中,vi1是物品i的关键词词频向量,(k1,k2,...km)为各领域关键词在物品i的描述文本中出现的次数,m为领域数;所述物品-主题向量子模块将物品描述文本与关键词百科文本组合,构建物品的领域相关文本,采用主题模型进行文本建模,将物品向量化表示:vi2=(t1,t2,...tn),其中,vi2是物品i的主题向量,(t1,t2,...tn)为各主题在物品i的领域相关文本中的分布值,n为主题数;物品i的特征向量为:vi=(k1,k2,...km,...t1,t2,...tn)。
继续结合图1,所述用户潜在表达更新模块03获取用户网页浏览行为信息,根据网页文本内容,向基于用户相似度的推荐模块的输出用户潜在表达的更新权重及采用的更新规则;所述用户潜在表达更新模块包含跨领域词向量训练子模块和更新权重计算子模块,所述跨领域词向量训练子模块以用户浏览的网页文本内容为源领域语料库ds,以所有物品的领域相关文本为目标领域语料库dt;先采用word2vec方法分别训练源领域词向量ws和目标领域词向量wt,再采用yang等人提出的跨领域词嵌入方法,根据跨领域词的重要性,训练跨领域词向量w′t;设定β为词数阈值,vu为用户的潜在表达。若跨领域关键词词数c≥β,采用独立更新规则,包括:对于每个领域关键词k∈pitem∩{ω|ω∈dt∩ds},计算跨领域词向量w′t(k)与目标领域词向量wt(k)的余弦相似度sim(wt(k),w′t(k))作为每个领域关键词各自的更新权重,采用独立更新规则更新用户潜在表达的对应维度v′u,k=vu,k*(1+sim(wt(k),w′t(k)));若跨领域关键词词数c<β,采用整体更新规则,包括:对于每个跨领域词ω∈dt∩ds,计算跨领域词向量w′t与目标领域词向量wt的余弦相似度sim(wt,w′t),对所有跨领域词的相似度取平均值作为所有跨领域关键词共享的更新权重:
继续结合图1,所述基于用户相似度的推荐模块04根据所述评分矩阵、物品特征向量和用户潜在表达的更新权重,计算用户相似度,输出用户未评分物品的预测评分。所述基于用户相似度的推荐模块04首先采用niu等人提出的用户ctri值方法,根据用户评分信息的并集以及物品画像,计算融合多源辅助信息后的用户潜在表达(latentrepresentation):
本发明还提供采用本发明所提供的基于多源辅助信息的协同过滤推荐系统的基于多源辅助信息的协同过滤推荐方法。
在本发明的一个实施例中,所述基于多源辅助信息的协同过滤推荐系统及方法被用于交响乐领域,用户隐式交互数据是某大型剧院两年问的会员用户购票记录,主要字段包括用户编号、节目编号、节目名称、购票时间、节目票价、购买张数以及用户截至该时间段之前的累计消费额和累计购买张数。经过筛选后,得到396个用户在205场节目上的9123条购票记录,由于用户在同一个节目上会出现多次购买,按照用户编号和节目编号分组累计后,一共有7985条购票记录,数据稀疏度为1-7985/(396×205)≈0.9016。
物品描述文本为该剧院节目的介绍文本。从这些节目介绍文本中提取到的关键词主要以交响乐领域的作家名、演出者名字、曲名以及演奏乐器和演奏形式等专有名词组成。关键词的百科文本则是从百度百科中爬取对应词条的部分文本获得。
用户浏览的网页文本的浏览时间段与购票数据所属的时间段相同。实验过程中,先对网页文本的网站来源进行了分类,主要分为“音乐相关网页”和“普通网页”。其中,“音乐相关网页”为用户在指定的多个音乐相关域名的浏览记录,总共有2406个不同的网页,而“普通网页”则没有对域名进行筛选,是用户在互联网上的浏览记录。之后,在处理用户网页文本的过程中,就直接根据不同的网页文本类型来更新用户的潜在表达,而没有设置跨领域关键词词数的阈值β。由于“音乐相关网页”与“交响乐”同属于“音乐”这一大领域,它们之间的相关性可能较大,采取独立更新规则,而“普通网页”相关性较小,采取整体更新规则。
本实施例在实验过程中使用评分排名前k的物品的召回率recall@k以及平均绝对误差(mae:meanabsoluteerror)这两个指标来评价本算法的性能。
recall@k反映了用户实际评分的物品中被推荐的物品的比例,其中k为用户推荐列表中的物品个数。其计算公式如下:
在实验过程中,使用所有用户的recall@k均值来评价推荐效果。
对于预测评分的推荐系统,平均绝对误差是使用最频繁的一种评价指标。平均绝对误差是最终预测评分与真实评分之间的误差绝对值的均值,对于任意一组预测评分pi和真实评分ri,平均绝对误差mae的计算公式如下:
整体实验过程中,选择70%的评分数据作为训练集进行训练,30%的评分数据作为测试集,来验证最后的推荐效果。对于每一项对比实验,都进行5次验证。在使用用户浏览的网页文本以及所有节目文本训练词向量时,词向量维度设置为100维,最小词频设置为3,其他参数与yang等人的词嵌入方法中使用的默认参数相同。最终生成评分排名前k的推荐列表的参数k设置为10。
为验证基于评分信息进行预测并生成推荐列表的有效性,实验对比使用偏好函数计算评分与只使用购票张数替代评分的推荐效果,并使用随机选取推荐方法作为基准,使用recall@k作为评价指标。选取评分排名前10的物品作为推荐列表,整体推荐效果用所有用户的recall@10的均值来衡量。为了保证随机选取结果的稳定性,对于每个用户,均进行10次随机选取,再求均值作为最终结果。两种评分生成方法与随机选取方法的对比结果如下:
表1评分生成方法的recall@10比较(无网页文本辅助信息)
表2评分生成方法的recall@10比较(有网页文本辅助信息)
从实验结果中可以看出,使用偏好函数和购票张数来生成评分均比随机选取的推荐结果好很多,且使用偏好函数比仅仅使用购票张数的效果更好,这也说明了从用户-物品交互辅助信息中挖掘多角度信息来生成初始评分的方法,比仅仅考虑其中一种信息的效果更合理。
为验证使用关键词词频与lda主题建模构建物品画像的有效性,实验中固定邻域用户个数以及用户浏览的网页文本辅助信息这两个变量,比较单独使用关键词词频以及单独使用lda主题文本建模,与同时使用这两种方法构造物品画像,对评分预测结果的影响,得到的实验结果如图所示:
表3各物品表示方法的平均绝对误差(无网页文本辅助信息)
表4各物品表示方法的平均绝对误差(有网页文本辅助信息)
从实验结果中可以看出,不加入用户浏览的网页文本辅助信息时,将关键词词频和lda主题建模这两种方法相结合能使评分预测更为准确,且较为稳定。加入网页文本辅助信息后,单独使用关键词词频表示物品也能得到较好的结果。因此,使用关键词与lda主题建模相结合的方法,来构建物品画像,能够对推荐结果产生一定的正向作用。
为评估基于多源辅助信息的协同过滤推荐框架的有效性,与传统的推荐方法进行对比,如:基于knn的推荐方法,以及矩阵分解方法svd、svd++和nmf等,其中矩阵分解方法的潜在因素个数均设置为20。对比实验的输入数据与之前相同,使用用户购票辅助信息生成的用户-节目评分矩阵中的训练集,选用平均绝对误差作为评价指标。为验证方法的稳定性,选择五次实验的平均值、最大值和最小值进行比较。使用本发明的推荐方法时,选择邻域用户个数n=20,并加入用户的网页浏览信息,对比结果如下:
表5推荐方法比较
在其他推荐方法中,在该数据集上表现最好的是nmf算法,平均绝对误差在0.19左右。使用本发明提出的推荐框架的预测效果比这些传统的推荐方法都好,相较于nmf,平均绝对误差能够有0.01左右的提升。
本发明虽然已以较佳实施例公开如上,但其并不是用来限定本发明。任何本领域技术人员在不脱离发明的精神和范围内,都可以利用上述揭示方法和技术内容对本发明方案做出可能的变动和修改,因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化及修饰,均属于本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!