一种基于交通违法数据上传质量的车牌信息恢复方法与流程
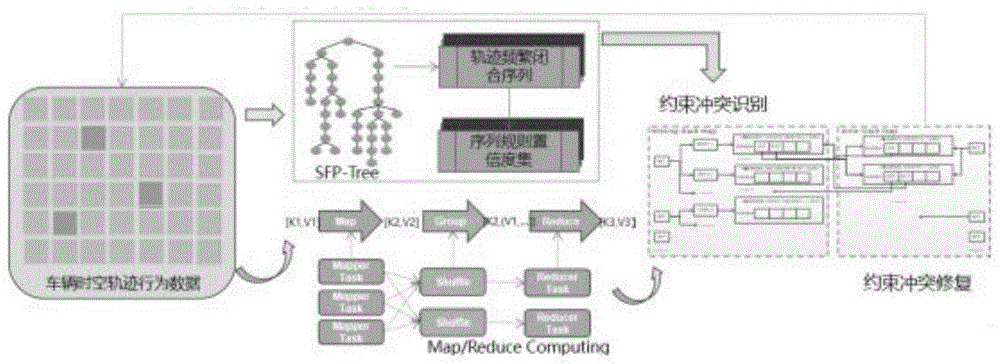
本发明涉及一种交通违法数据的车牌信息恢复方法,尤其是一种基于交通违法数据上传质量的车牌信息恢复方法,属于数据处理
技术领域:
。
背景技术:
:道路交通违法数据来源是通过前端的过车数据采集摄像头,完成了从图像采集、图像处理到图像识别的全部工作,为城市交通的运行情况提供数据上的参考,也为交通执法提供图像证据。对于目前的车辆违法数据有几大属性:其一,数据量大,一个城市一天产生的数据量超过千万,累积数据量超过160亿;其二,数据种类多,一个城市有超过3000台采集设备,采集不同种类数据;再加上根据对来自九个设备厂商收集的超过10万条数据进行人工标注发现,车牌自动识别技术准确率在实际场景中仅为81%,有接近20%的数据识别错误。而导致车牌未能正确识别的原因错综复杂,有光线、拍摄角度遮挡、人为遮挡等原因,急剧增加的交通数据给智能交通中诸如交通拥堵预测、智能交通控制、道路交通安全分析等应用带来更多新的挑战,这些被错误识别的数据会造成研究分析结果偏差较大。技术实现要素:本发明所要解决的技术问题在于提供一种基于交通违法数据上传质量的车牌信息恢复方法,提高车牌信息恢复和准确识别。为解决上述技术问题,本发明的技术方案如下:1、一种基于交通违法数据上传质量的车牌信息恢复方法,包括以下步骤,(1)基于fp-growth算法构建sfp-tree挖掘序列规则:具体步骤为:先对车辆时空轨迹行为数据构建sfp-tree,然后挖掘时空轨迹频繁闭合序列,再计算时空轨迹序列规则置信度;(2)利用约束冲突识别算法(cvr1)和约束冲突修复算法(cvr2)对数据进行冲突识别和冲突修复处理。上述的基于交通违法数据上传质量的车牌信息恢复方法,所述的基于fp-growth算法构建sfp-tree挖掘序列规则,相较于通用的fp-tree构建算法有两点不同:一是基于完整的序列数据库构建sfp-tree每个节点将会保存两个值:叶子节点支持度和根节点支持度,其初始值都为零;二是sfp-tree中会保留序列的原始顺序。前述的基于交通违法数据上传质量的车牌信息恢复方法,所述的对车辆时空轨迹行为数据构建sfp-tree,首先初始化树,接着遍历车辆轨迹,将轨迹元素节点填加到树中,如果该节点为序列的最后一个元素,则将其叶子节点支持度增加,否则增加其根节点支持度;而对于轨迹的第一个元素,如果在根节点下无该元素,则新建一条轨迹,并增加其叶子节点支持度或者根节点支持度。前述的基于交通违法数据上传质量的车牌信息恢复方法,所述的挖掘时空轨迹频繁闭合序列,首先对树采取剪枝处理,遍历树的叶子节点,若其叶子节点支持度不大于阈值min_sup1,则将其剪枝,并修改其父节点;遍历完所有叶子节点剪枝后;接下来进行频繁闭合序列挖掘:遍历剪枝后sfp-tree叶子节点,若叶子节点支持度sl不小于阈值min_sup2,则将其前置序列作为频繁闭合序列,满足频繁闭合序列规则,则其前置序列为频繁闭合序列;同理,可以得到树中所有频繁闭合序列。前述的基于交通违法数据上传质量的车牌信息恢复方法,所述的计算轨迹序列规则置信度集,包括以下步骤:(1)序列规则rules-i的支持度计算:cisthesetofthesupersequenceofsu{i};(2)序列规则rules→1的置信度计算:cisthesetofthesupersequenceofs(3)针对频繁闭合序列<2,4,5,6,7,11,13,15>:前述的基于交通违法数据上传质量的车牌信息恢复方法,根据权利要求1所述的基于交通违法数据上传质量的车牌信息恢复方法,其特征在于:所述的约束冲突识别算法,包括:(1)轨迹点缺失识别:对于目标序列tarseq:{loc1,loc2,......,locn},每次从中取j个轨迹点,并将剩余轨迹点删除,生成新的序列ntarseq,若新序列存在轨迹缺失点或为频繁闭合序列,则可以把删除的轨迹点错误集合;(2)错误轨迹点置信度计算:c={<tp11,.....,tpij>,....<tpq1,.....tpqj>}是所有删除轨迹点组合;对任一元素ci={tpi1,.....,tpij},csi是ci在c中的补集:cfsiisthesetofthesupersequencecsi(3)错误轨迹(e,ttij,locij)置信度:通过以上sfp-tree的构建挖掘到。前述的基于交通违法数据上传质量的车牌信息恢复方法,所述的约束冲突修复算法,包括以下步骤:(1)实体间距离计算(编辑距离)d(vehiclei,vehiclej)=editdistance(licensenumberofvehicleiandvehiclej);(2)missing-track与error-track匹配度计算本发明的有益效果:与现有技术相比,本发明通过建立模型提升了上传的交通违法数据质量,实现车牌信息恢复和准确识别,有利于智能交通的应用和发展。附图说明图1是本发明的算法过程示意图;图2是轨迹点缺失示意图;图3是轨迹点错误示意图;图4是轨迹点混合错误示意图;图5是算法准确率与车辆时空轨迹行为本身质量关系示意图;图6是sfp-growth算法挖掘序列规则时间增长图;图7是闭合频繁项和序列规则项置信度集示意图。下面结合附图和具体实施方式对本发明作进一步的说明。具体实施方式实施例1:如图1所示,本技术方案用于提升道路交通违法数据的质量,通过建立模型对数据质量提升,模型主要包括两个部分,其一是基于fp-growth算法构建sfp-tree挖掘序列规则,对车辆时空轨迹行为数据构建sfp-tree,并挖掘轨迹频繁闭合序列和计算轨迹序列规则置信度集;其二对车辆轨迹数据预处理后,通过约束冲突识别算法对轨迹中缺失、错误及混合错误节点数据进行识别,再利用约束冲突修复算法交叉修复缺失和错误的轨迹点,以提升原始车辆时空轨迹行为数据质量。具体步骤如下:1、构建sfp-tree基于fp-growth算法构建sfp-tree挖掘序列规则,构建sfp-tree算法相较于通用的fp-tree构建算法的主要改变在于两点,一是基于完整的序列数据库构建sfp-tree每个节点将会保存两个值:叶子节点支持度和根节点支持度,其初始值都为零;二是sfp-tree中会保留序列的原始顺序。接下来构建sfp-tree,构建算法的主要思路如下:首先初始化树,接着遍历车辆轨迹,将轨迹元素节点填加到树中,如果该节点为序列的最后一个元素,则将其叶子节点支持度增加,否则增加其根节点支持度;而对于轨迹的第一个元素,如果在根节点下无该元素,则新建一条轨迹,并增加其叶子节点支持度或者根节点支持度。2、挖掘时空轨迹频繁闭合序列为减少无效的轨迹和元素干扰,首先对树采取剪枝处理,遍历树的叶子节点,若其叶子节点支持度不大于阈值min_sup1,则将其剪枝,并修改其父节点;遍历完所有叶子节点剪枝后;接下来进行频繁闭合序列挖掘:遍历剪枝后sfp-tree叶子节点,若叶子节点支持度sl不小于阈值min_sup2,则将其前置序列作为频繁闭合序列,满足频繁闭合序列规则,则其前置序列为频繁闭合序列;同理,可以得到树中所有频繁闭合序列。3、计算时空轨迹序列规则置信度集◆序列规则rules→1的置信度计算:cisthesetofthesupersequenceofs◆针对频繁闭合序列<2,4,5,6,7,11,13,15>:4、约束冲突识别算法(cvr1)和约束冲突修复算法(cvr2)◆约束冲突识别算法cvr1◆轨迹点错误识别对于目标序列tarseq:{loc1,loc2,......,locn},每次从中取j个轨迹点,并将剩余轨迹点删除,生成新的序列ntarseq,若新序列存在轨迹缺失点或为频繁闭合序列,则可以把删除的轨迹点错误集合。◆错误轨迹点置信度计算:c={<tp11,.....,tpij>,....<tpq1,.....tpqj>}是所有删除轨迹点组合◆对任一元素ci={tpi1,.....,tpij},csi是ci在c中的补集:cfsiisthesetofthesupersequencecsi◆错误轨迹(e,ttij,locij)置信度:◆通过以上sfp-tree的构建挖掘到约束冲突修复算法主要是针对约束冲突识别算法中获取的缺失点和错误点进行交叉修复,利用车牌照号码编辑距离计算车辆实体间距离,并采取如下算法计算车辆缺失轨迹点和错误轨迹点匹配度。当车辆实体间距离大于等于阈值时,用缺失轨迹点置信度乘以权重,再加上车辆实体间距离乘以权重;而当小于阈值时,将缺失轨迹点置信度、错误轨迹点置信度以及车辆实体间距离相乘作为匹配度。◆约束冲突修复算法cvr1◆实体间距离计算(编辑距离)d(vehiclei,vehiclej)=editdistance(licensenumberofvehicleiandvehiclej)◆missing-track与error-track匹配度计算5、轨迹中缺失、错误及混合错误节点识别车辆时空轨迹中的频繁闭合序列和序列规则置信度集,接下来使用约束冲突识别算法进行错误数据识别,车辆时空轨迹约束冲突可分为三类,依次为轨迹点缺失,轨迹点错误,以及轨迹点混合错误的情况。如图2、3、4所示6、交叉修复缺失及错误轨迹点为了兼容不同的抓拍摄像机之间存在的时间异步性,引入松弛时间slacktime来处理轨迹点缺失的时间段。达到效果:算法实验结果显示了算法在车辆时空轨迹行为数据质量为81%时的各项评价指标值;约束冲突识别召回率为93.8%,约束冲突识别准确率为93.7,约束冲突修复准确率和约束冲突修复有效准确率分别为85.1%和79.3%。还得出算法准确率与车辆时空轨迹行为本身质量有很大关系,质量越差时,算法的准确率会随之下降和闭合频繁项和序列规则项置信度集在不同训练数据量上并无明显增长,说明算法能够获取车辆轨迹数据中的稳定序列规则集合。实施例2:列举数据进行计算演示:1、基于完整的序列数据库构建的sfp-tree每个节点将会保存两个值:叶子节点支持度(supportasleaf,sl)和根节点支持度(supportasroot,sr),其初始值都为零,在sfp-tree中保留序列原始顺序,见下表:记录id序列元素项11,3,8,9,10,1321,3,8,9,12,1431,3,8,9,10,13,15,1641,3,8,9,10,13,15,16,2151,3,8,9,10,13,15,16,2261,3,8,9,10,13,15,1672,4,5,6,7,11,17,19,2082,4,5,6,7,1592,4,5,6,7,11,13,15,16102,4,5,6,7,11,13,15,16112,4,5,6,7,11,17,19,20122,4,5,6,7,11,13,15,16,21132,4,5,6,1,3,8,9141,2,4,5,62、频繁闭合序列挖掘。剪枝:遍历sfp-tree叶子节点,其叶子节点支持度sl不大于阈值min_sup1,则将其剪枝,并修改其父节点;挖掘:遍历剪枝后sfp-tree叶子节点,若叶子节点支持度sl不小于阈值min_sup2,则将其前置序列作为频繁闭合序列。3、序列规则挖掘对于频繁闭合序列ci,获取其所有子序列s,针对ci中不在子序列s中的元素i,可以形成序列规则rules→i,遍历频繁闭合序列集,可以得到所有序列规则及其置信度。序列规则rules→i的支持度计算:cisthesetofthesupersequenceofsu{i};序列规则rules→1的置信度计算:cisthesetofthesupersequenceofs针对频繁闭合序列<2,4,5,6,7,11,13,15>:4、约束冲突识别算法(cvr1)·时空轨迹约束冲突分类:(1)轨迹点缺失(missing-track)、(2)轨迹点错误(error-track)、(3)轨迹点混合错误。(1)轨迹点缺失(missing-track)对于目标序列tarseq:{loc1,loc2,......,locn},每次从中取j个轨迹点,并将剩余轨迹点删除,生成新的序列ntarseq,若新序列存在轨迹缺失点或为频繁闭合序列,则可以把删除的轨迹点错误集合;(2)错误轨迹点置信度计算:c={<tp11,.....,tpij>,....<tpq1,.....tpqj>}是所有删除轨迹点组合;对任一元素ci={tpi1,.....,tpij},csi是ci在c中的补集:cfsiisthesetofthesupersequencecsi(3)错误轨迹(e,ttij,locij)置信度:5、约束冲突算法所述的约束冲突修复算法,包括以下:实体间距离计算(编辑距离)d(vehiclei,vehiclej)=editdistance(licensenumberofvehicleiandvehiclej);missing-track与error-track匹配度计算6、实验结果(1)数据质量修复评价指标表现评价项evaluation(%)约束冲突识别召回率93.8约束冲突识别准确率93.7约束冲突修复准确率85.1约束冲突修复有效准确率79.3(2)在数据本身质量越高时,算法对数据修复准确度越高。这是算法实验结果,表格展示了算法在车辆时空轨迹行为数据质量为81%时的各项评价指标值;约束冲突识别召回率为93.8%,约束冲突识别准确率为93.7,约束冲突修复准确率和约束冲突修复有效准确率分别为85.1%和79.3%。从图5可以看出,算法准确率与车辆时空轨迹行为本身质量有很大关系,质量越差时,算法的准确率会随之下降。(3)如图6所示,sfp-growth算法挖掘序列规则时间在训练数据上呈线性增长。(4)如图7所示,闭合频繁项和序列规则项置信度集在不同训练数据量上并无明显增长。从图6可以看出,我们分别使用了1至7天的数据进行序列规则挖掘,sfpgrowth算法耗费时间保持线性增长;从图7可以看出,闭合频繁项和序列规则项置信度集在不同训练数据量上并无明显增长,说明算法能够获取车辆轨迹数据中的稳定序列规则集合。本发明的实施方式不限于上述实施例,在不脱离本发明宗旨的前提下做出的各种变化均属于本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1