一种基于执行时间评估的云雾协同计算电网调度方法与流程
【技术领域】
本发明属于电网调度自动化技术领域,具体涉及一种基于执行时间评估的云雾协同计算电网调度方法。
背景技术:
随着物联网、云计算、大数据、人工智能等it新技术的发展,电力信息数据爆炸式增长,使得网络带宽负载急剧增加,造成数据在网路上拥堵,数据无法实时从源端传输至云端,导致无法及时有效地将数据上传到云端服务器,延误了异常事件的最佳处理时机,故单纯的云计算已不能满足一些任务的调度需求,我国电网调度控制技术也需要与时俱进,不断的吸纳新技术,才能巩固和提升电网调度系统信息感知与同步、实时在线分析、调度精益化管理和数据深度应用的支撑能力,完成电网调度运行模式由“分析型调度”逐渐转变为“智能型调度”的任务,云雾协同计算可以很好解决上述提及的问题,实现电力调度自适应调整动态化、协调控制一体化、流程管控高效化、统筹计划精细化等功能。本发明通过融合hadoop技术,云计算和雾计算技术,使智能电网调度系统面对用户提交的任务时先进行调度任务的执行时间进行评估,判断任务属于紧急任务还是非紧急任务,依据判断结果再将其调度到对应的平台执行相应的调度策略,实现最优调度,使得资源的分配更加合理、灵活,保证任务调度的效率,提高资源的使用率,保障电网调度的稳定性和可靠性。
技术实现要素:
为了解决现有技术中的上述问题,本发明提供一种基于执行时间评估的云雾协同计算电网调度方法,所述方法包括如下步骤:
步骤s1:任务执行时间评估;
步骤s2:调度任务类型判断;
步骤s3:基于改进遗传-蚁群算法的任务调度优化方法进行任务调度。
进一步的,所述步骤s1包括:对hadoop平台下数据任务的执行时间进行有效评估。
进一步的,通过任务分割以获取hadoop平台下数据任务需处理数据的分布,并同时考虑平台的网络资源、数据流所需要的计算处理资源完成对调度任务各个环节的刻画描述,从而对调度任务在计算节点上的执行时间进行有效的评估,使得hadoop平台数据任务的执行时间可以在实际调度执行前获悉。
进一步的,所述hadoop平台包括一个或者多个任务调度平台。
进一步的,所述任务分割,具体为:基于数据任务需处理数据的分布进行任务的分割以获取子任务集合及其数据依赖关系。
进一步的,所述对任务的执行时间进行有效的评估,具体为:对子任务集合中的每个子任务所需要的网络资源和计算资源进行评估以获取每个子任务的执行时间。
进一步的,基于子任务集合中每个子任务之间的数据依赖关系、以可用网络资源和可用计算资源为约束条件,进行执行时间优化以获取任务执行时间。
进一步的,在获得调度任务的执行时间后,需要以此时间为依据利用qtsu法则对调度任务的类型进行分类,如果qtsu法则判定该调度任务属于紧急任务,将其调度到离用户较近的雾平台上进行处理,如果qtsu法则判定为非紧急任务则调度到云平台进行处理,以减少迟延。
进一步的,在调度任务类型的判断过程中考虑任务的优先级。
进一步的,通过加权的方式基于优先级对任务类型进行调整。
本发明的有益效果为:通过融合hadoop技术,云计算和雾计算技术,使智能电网调度系统面对用户提交的任务时先进行调度任务的执行时间进行评估,判断任务属于紧急任务还是非紧急任务,依据判断结果再将其调度到对应的平台执行相应的调度策略,实现最优调度,使得资源的分配更加合理、灵活,保证任务调度的效率,提高资源的使用率,保障电网调度的稳定性和可靠性。
【附图说明】
此处所说明的附图是用来提供对本发明的进一步理解,构成本申请的一部分,但并不构成对本发明的不当限定,在附图中:
图1是本发明的基于执行时间评估的云雾协同计算电网调度系统示意图;
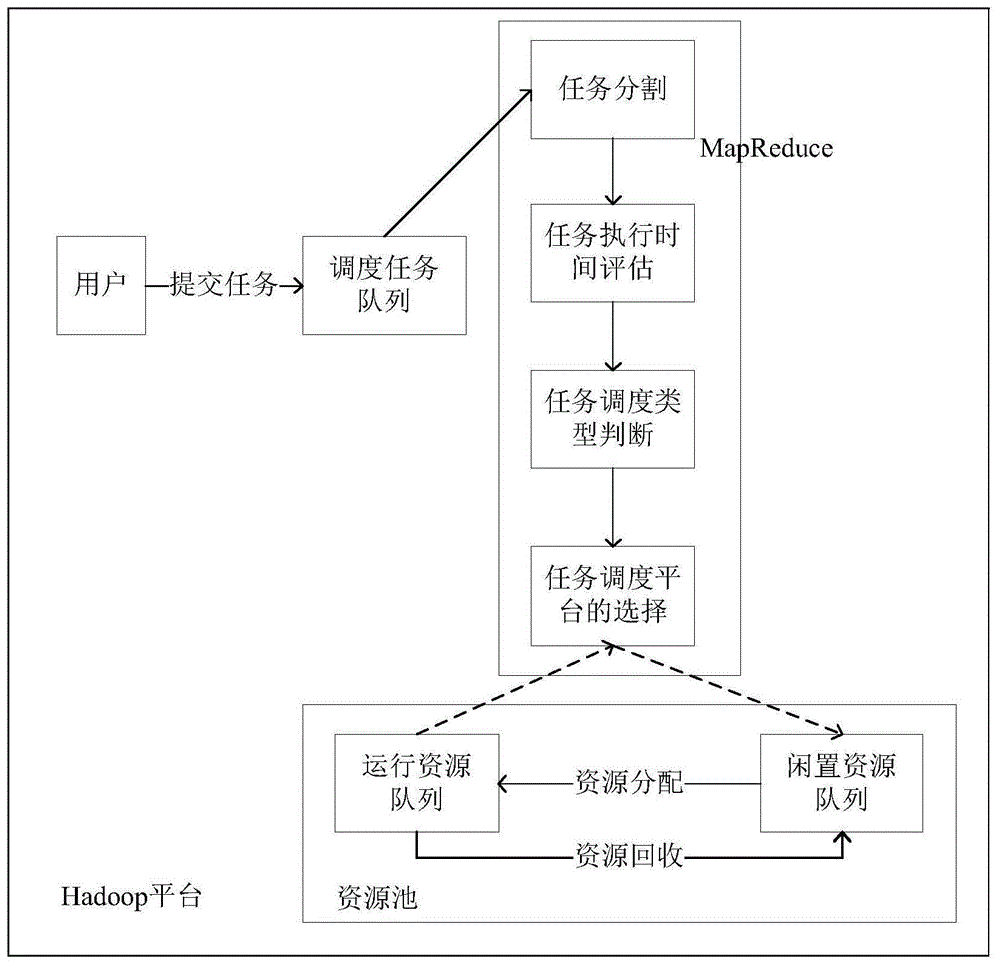
图2是本发明的基于执行时间评估的云雾协同计算电网调度方法示意图;
图3是本发明的改进遗传-蚁群算法的任务调度优化方法的示意图。
【具体实施方式】
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,基于执行时间评估的云雾协同计算电网调度系统包括:任务调度队列、任务调度模块和资源池;
所述任务调度队列用于对用户提交的任务进行排队;例如:按照先到先入的策略进行任务的排队;所述任务调度队列为操作系统中的任务调度队列、或者hadoop平台中的任务调度队列;
所述任务调度模块用于进行任务执行时间评估、调度任务类型判断、调度平台选择;
所述资源池通过闲置资源队列和运行资源队列对调度对象所需要的资源进行管理;在任务执行完毕后进行资源回收,在任务开始执行前进行资源的分配;资源池以调度对象为任务的执行单元对调度任务进行执行;所述调度对象为虚拟机,虚拟机作为资源载体配置有资源并运行于不同的任务调度平台中;资源池在调度平台间共享;
优选的:调度平台对资源池中资源占有优先级相同,能够平等的使用资源池中的资源;可替换的:调度平台不平等的使用资源池中的资源,对于网络资源具有不平等的使用权利;调度平台通过虚拟限定的方式进行资源池中资源组织;例如:不同的调度平台所限定的虚拟范围距离不同网络资源的距离不同从而导致使用权利不同,这实际上适合它们对网络资源的使用开销相关的;类似的情况也存在于计算资源以及存储资源上;
所述任务调度平台包括云计算平台和雾计算平台;
如图2所示,其示出了本发明一种基于执行时间评估的云雾协同计算电网调度方法的示意图,该方法主要包括任务执行时间评估、调度任务类型判断、调度平台选择、执行相应调度策略等几个步骤;在用户提交调度任务后将任务按照任务提交策略放置任务调度队列中;依次获取任务调度队列中的首个任务,并对所述获取任务的执行时间进行有效评估,并以此评估时间为依据通过qtsu法则判断此次执行的任务类型是紧急类型还是非紧急类型,根据不同的类型将其放到对应的平台上进行处理,最后在利用改进的遗传-蚁群算法完成任务调度处理。
所述将任务按照任务提交策略放置任务调度队列中,具体为:按照任务优先级将任务插入任务调度队列中相应的位置,使得任务调度队列中任务的优先级从队首到队尾依次降低;所述任务的优先级为操作系统分配和/或任务所述用户指定的;由于操作系统或者用户指定的任务优先级往往具有一定的主观性且实时性欠佳,传统的仅仅依靠任务调度队列进行任务排队的方式效果不佳,不能考虑电网任务的特殊性,任务调度队列只能够对任务进行大致的排序;可替换的:任务按照达到的先后顺序放入调度任务队列中,这种方式为常见的操作系统任务提交策略;
具体方法步骤如下:
步骤s1:任务执行时间评估;对hadoop平台下数据任务的执行时间进行有效评估。通过任务分割以获取hadoop平台下数据任务需处理数据的分布,并同时考虑平台的网络资源、数据流所需要的计算处理资源完成对调度任务各个环节的刻画描述,从而对调度任务在计算节点上的执行时间进行有效的评估,使得hadoop平台数据任务的执行时间可以在实际调度执行前获悉。
所述hadoop平台包括一个或者多个任务调度平台;
所述任务分割,具体为:基于数据任务需处理数据的分布进行任务的分割以获取子任务集合及其数据依赖关系;
所述对任务的执行时间进行有效的评估,具体为:对子任务集合中的每个子任务所需要的网络资源和计算资源(存储资源)进行评估以获取每个子任务的执行时间;基于子任务集合中每个子任务之间的数据依赖关系、以可用网络资源和可用计算资源(存储资源)为约束条件,进行执行时间优化以获取任务执行时间;由于调度任务在执行前就对任务的执行时间进行有效的评估,可以根据评估的任务执行时间对该阶段的所有任务集合进行较为合理的全局考虑与全局调度,从而更加合理的利用调度资源,缩短任务的执行时间。
步骤s2:调度任务类型判断;在获得调度任务的执行时间后,需要以此时间为依据利用qtsu法则对调度任务的类型进行分类,如果qtsu法则判定该调度任务属于紧急任务,将其调度到离用户较近的雾平台上进行处理,如果qtsu法则判定为非紧急任务则调度到云平台进行处理,以减少迟延,大大的缩短任务处理的时间,从而提升用户满意度。
优选的:在调度任务类型的判断过程中考虑任务的优先级;例如:通过加权的方式基于优先级对任务类型进行调整;
步骤s3:基于改进遗传-蚁群算法的任务调度优化方法进行任务调度;所述基于改进遗传-蚁群算法的任务调度优化方法中,先利用遗传算法的快速搜索到任务调度的可行策略,然后根据所述可行策略确定初始化信息素分布,再采用蚁群算法找到任务调度的最优解,并基于所述最优解进行任务调度。
如图3所示,所述改进遗传-蚁群算法的任务调度优化方法具体包括如下步骤:
步骤s31:对遗传参数进行初始化;
具体的,所采用的遗传算法为基于iga遗传算法;
步骤s32:执行编码操作,利用均匀分布策略初始化种群,并计算出个体的适应度和平均适应度;
步骤s33:采用精英保留策略选择两个适应能力强的个体保留下来,并按照相对的规则进行选择、交叉、变异;
步骤s34采用精英替换策略把步骤s33中的个体替换新一代中的适应度最低的个体,并加速个体进化;
步骤s35:上述步骤完成后进行收敛判定,如果达到最大进化迭代次数或指定的计算精度,则立即停止进化,输出最优解,否则转到步骤s32继续进化;
步骤s36:蚁群初始化;具体为:计算原始信息素,通过分析用户的服务请求,结合任务间的依赖关系及优先级顺序,对信息素进行初始化。
步骤s37:调度对象的选取;具体为:综合考虑任务之间的依赖关系、优先级顺序等多个因素,选取调度对象;所述调度对象为调度任务的执行对象,例如:虚拟机;
步骤s38:信息素的更新。信息素的更新包括虚拟机局部信息素的更新,及时释放避免资源的浪费。在任务执行完毕后,进行资源释放并将释放后的资源放入闲置资源队列中;
步骤s39:任务调度的完成;所有待调度任务全部完成分配后,记录任务的最短完成时间,更新调度对象全局信息素,返回调度对象的任务执行结果;
本发明提出一种基于执行时间评估的云雾协同计算电网调度方法,该方法通过对执行任务的各个环节所需的时间进行有效评估,在任务被执行前就获得了任务的执行时间,可以对整个调度任务集合进行全局把控,从而更好的进行任务调度。利用云雾协同计算平台采用qtsu法则将不同的任务放到不同的计算平台进行任务调度,缓解了单纯的云计算平台处理任务的压力,有效的提高了任务调度效率。缩短了任务处理时间。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!