一种基于土压平衡盾构机参数数据驱动反演地质的方法与流程
本发明涉及盾构施工
技术领域:
,尤其是涉及一种基于土压平衡盾构机参数数据驱动反演地质的方法。
背景技术:
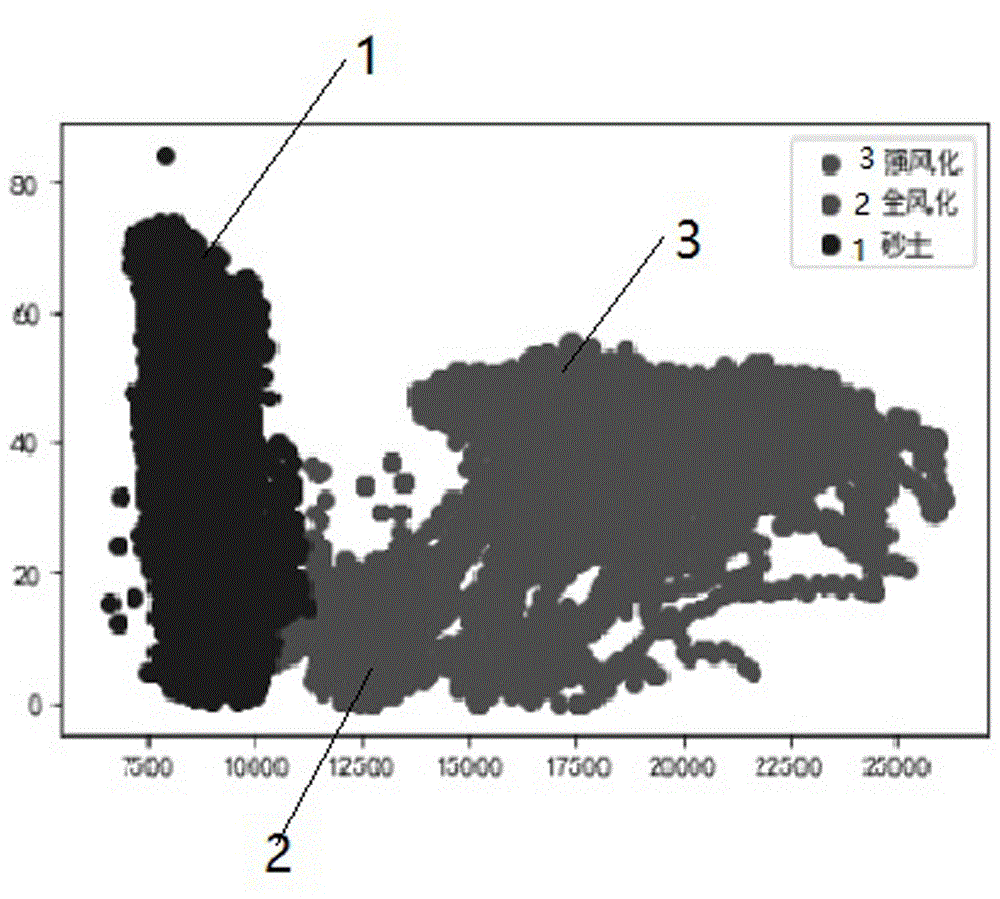
:土压平衡盾构的基本原理是用一件有形的钢质组件沿隧道设计轴线开挖土体而向前推进。土压平衡盾构属封闭式盾构。盾构的另一个作用是能够承受来自地层的压力,防止地下水或流砂的入侵。土压平衡盾构有着很多的优点,比如安全开挖和衬砌,掘进速度快;不影响地面交通与设施,同时不影响地下管线等设施;穿越河道时不影响航运,施工中不受季节、风雨等气候影响,施工中没有噪音和扰动。但是土压平衡盾构机在施工过程中,会碰到断面尺寸多变、地质条件变化的问题,如果不能对地质条件进行预测,则会对施工效率有很大的影响,且会影响施工工程的安全性与可靠性,增加了施工风险,影响工程施工的工期。技术实现要素:本发明为了克服现有技术中地质条件变化,降低施工效率,影响施工工程安全性与可靠性,增加施工风险的问题,提出了种基于土压平衡盾构机参数数据驱动反演地质的方法,可以从施工历史数据中得出参考模型,根据当前土压平衡盾构机的运行数据,预测地质条件,为后续施工提供有效的技术支撑。为了实现上述目的,本发明采用了以下技术方案:一种基于土压平衡盾构机参数数据驱动反演地质的方法,其特征是,包括以下步骤:(1-1)提取土压平衡盾构机的历史运行数据集data,从历史运行数据集data中提取正常掘进段的数据data1,并剔除异常值;(1-2)分别对数据data1中不同地质条件下的数据添加对应的标签,筛选设备运行参数变量,构建新的数据集data2;(1-3)对数据集data2进行归一化处理,形成数据集data3;(1-4)将数据集data3随机划分为训练集和测试集,在训练集上学习随机森林模型,并在测试集上进行验证,确定模型超参数;(1-5)提取土压平衡盾构机的实时正常掘进段数据,根据学习的随机森林模型的输入参数筛选数据,代入学习的随机森林模型,计算地质条件信息。作为优选,步骤(1-5)包括以下步骤:(2-1)提取土压平衡盾构机的实时运行参数;(2-2)判断是否为正常掘进段数据,若是正常掘进段数据,则根据学习的随机森林模型的输入参数筛选数据;若不是正常掘进段数据,则丢弃该数据;(2-3)将筛选的数据代入学习的模型,计算地质条件信息。作为优选,设备运行参数变量包括刀盘扭矩、总推进力、推进速度和贯入度。作为优选,所述正常掘进段数据包括主动参数、被动参数、施工环号和采样时刻。作为步骤(2-2)的替换,将随机森林模型替换为k-means模型,根据k-means模型的输入参数筛选数据。作为优选,剔除异常值采用3σ原则。作为优选,包括土压平衡盾构机、设于土压平衡盾构机上的数据采集装置、设于土压平衡盾构机上的数据服务器和盾构大数据平台,数据采集装置与数据服务器电连接,数据服务器与盾构大数据平台进行数据传输。作为优选,数据采集装置包括若干个测量传感器,各个测量传感器均与数据服务器电连接。土压平衡盾构机施工呈现一定的周期性。土压平衡盾构机在每环的施工过程中,都要经历启动、正常掘进、更换渣车、停机等阶段。在启动阶段,各参数(刀盘扭矩、总推进力、推进速度等)处于上升趋势;而在正常掘进阶段,各参数则几乎平稳,变化不大。因此,依托不同地质下土压平衡盾构机运行的历史数据,借助于机器学习方法,构建土压平衡盾构机运行参数反演地质条件的自动化模型,即可根据正常掘进段土压平衡盾构机运行参数推测当前的地质条件。土压平衡盾构机运行原始数据中含有500多项属性,其中描述土压平衡盾构机的属性有7项,称之为主动参数;而描述盾构机工作状态的属性主要有30项,称之为被动参数。原始数据中其它的属性项与数据分析的关联性不大。因此,从原始数据集中只抽取施工环号、数据采样时刻、主动参数和被动参数等属性项,形成精简的原始数据集。因此,依托于盾构大数据信息采集平台,为保障该自动化模型的准确性,对采集到的多种地质条件下土压平衡盾构机运行数据的需满足如下条件:(a)不同地质条件下的土压平衡盾构机机型应接近;(b)不同地质条件下的土压平衡盾构机刀盘布局、刀盘直径等参数应接近。将从盾构大数据平台的数据库中提取出的历史数据集data剔除突变点、异常值、零值等异常数据,并只提取其中平稳掘进段的数据,记为data1;根据3σ原则再次剔除data1中的异常点,并从中筛选关键变量(刀盘扭矩、总推进力、推进速度、贯入度),并根据地质信息,对不同地质条件添加不同的标签,合并不同地质各环号下提取的掘进段数据,并按主动参数、被动参数变量依次提取,在合并后的数据集后添加新的一列,按数据所属的地质类别添加相应的数值标签(比如:若有3类地质,则将砂土地层的数据标注为‘1’;全风化岩地层的数据标注为‘2’;强风化岩地层的数据标注为‘3’),该地质标签需与地勘报告、施工现场实际地质条件一致,形成带人工标注标签的数据集data2;对数据集data2进行归一化处理形成data3,消除不同变量间量纲的影响。在上述数据处理基础上,将数据集data3按随机方式(p=0.7)随机划分为训练集和测试集;在训练集上构建地质条件反演的随机森林模型,在测试集上采用随机森林模型学习超参数训练分类器。为土压平衡盾构机施工的辅助巡航提供技术支撑。随机森林模型(rf)通过随机选择训练样本与随机选择特征变量的方法生成多棵cart决策树,并将这些树的决策结果组合并投票,得到的最终分类或回归的结果可以较好的克服单颗决策树泛化能力较差的缺点。rf在生成cart树过程中,主要采用bootstrap重抽样方法按每次2/3的比例从原始数据集中抽取k个样本分别作为k棵cart树的训练数据。这k个样本称为袋内(inbag)数据,即每次未被抽中的约1/3的数据称为袋内(outofbag)数据,rf利用oob进行内部误差估计,以提升模型的泛化能力。由于bootstrap采用独立随机重抽样的方式,支持并行运算,运算速度仅由单棵最大深度决策树的计算时间成本,且使用重抽样的方法达到样本空间重构的效果,使得k棵cart树的训练样本不尽相同,减少k棵树之间的相关性。此外,rf还会从所有m个变量特征中按比例随机抽取m个(0<m<m)作为每棵cart树训练的特征变量,进一步减小生成k棵树之间的相关性,从而提高整个集成模型的性能。rf算法可以根据gini不纯度按照式,自动判断特征变量的重要性。其中,在节点z上某属性xj的重要性为:其中,gini(xr1)和gini(xr2)分别标识分枝后两个新节点的gini不纯度。在第i棵树的重要性为:xj在rf中的重要性归一化结果为:rf算法的回归精度还与cart树的数量有关,一般来说树的数量越多,模型的精度越高,但应兼顾模型的泛化能力及计算效率。因此,cart树的数量k需进一步经实验确定,本发明采用交叉验证的方法选定k值。评价指标:以分类的准确率评价隧道全断面地质条件反演自动化模型的性能。准确率(accuracy)计算方式如公式(4)所示:其中,nr是预测正确的样本数,nt是预测的总样本数。因此,本发明具有如下有益效果:本发明针对土压平衡盾构机原始施工数据,根据提取出的平稳掘进段数据,采用机器学习中随机森林模型的方法反演地质条件,准确度高、计算复杂度低,效率较快,为土压平衡盾构机施工的辅助掘进提供技术支撑。附图说明图1是本发明的一种业务流程图;图2为本发明所提供的盾构设备运行关键参数总推进力、推进速度在不同地质下的一种分布规律图;图3为本发明所提供的盾构设备运行关键参数总推进力、推进速度、刀盘扭矩在不同地质下的一种分布规律图;图4为完整掘进过程中刀盘扭矩的一种变化示意图;图5为砂土层、全风岩地层k-means预测的一种混淆矩阵;图6为砂土层、全风岩地层经rf模型预测后的一种混淆矩阵;图7为砂土层、强风岩地层k-means预测的一种混淆矩阵;图8为砂土层、强风岩地层经rf模型预测后的一种混淆矩阵;图9为全风岩地层、强风岩地层k-means预测的一种混淆矩阵;图10为全风岩地层、强风岩地层经rf模型预测后的一种混淆矩阵。图中,砂土1,全风化2,强风化3。具体实施方式下面结合附图与具体实施方式对本发明做进一步描述:如图1所示的实施例是本发明的一种基于土压平衡盾构机参数数据驱动反演地质的方法,包括如下步骤:步骤s1:提取土压平衡盾构机的历史运行数据集data,从历史运行数据集data中提取正常掘进段的数据data1,并采用3σ原则剔除异常值;所述正常掘进段数据包括主动参数、被动参数、施工环号和采样时刻;土压平衡盾构机施工呈现一定的周期性。土压平衡盾构机在每环的施工过程中,都要经历启动、正常掘进、更换渣车、停机等阶段。在启动阶段,各参数(刀盘扭矩、总推进力、推进速度等)处于上升趋势;而在正常掘进阶段,各参数则几乎平稳,变化不大,如图4所示;步骤s2:分别对数据data1中不同地质条件下的数据添加对应的标签,筛选设备运行参数变量,构建新的数据集data2;设备运行参数变量包括刀盘扭矩、总推进力、推进速度和贯入度;步骤s3:对数据集data2进行归一化处理,形成数据集data3;步骤s4:将数据集data3随机划分为训练集和测试集,在训练集上学习随机森林模型,并在测试集上进行验证,确定模型超参数;此处作为替换,将随机森林模型替换为k-means模型,根据k-means模型的输入参数筛选数据。步骤s5:提取土压平衡盾构机的实时正常掘进段数据,根据学习的随机森林模型的输入参数筛选数据,代入学习的随机森林模型,计算地质条件信息。使用本发明所述方法的装置包括土压平衡盾构机、设于土压平衡盾构机上的数据采集装置、设于土压平衡盾构机上的数据服务器和盾构大数据平台,数据采集装置与数据服务器电连接,数据服务器与盾构大数据平台进行数据传输。数据采集装置包括若干个测量传感器,各个测量传感器均与数据服务器电连接。测量传感器将测试所得的数据上传至数据服务器,数据服务器将数据上传至盾构大数据平台。数据采集装置具有体积小的特点,满足现场高温、高湿、多粉尘、噪声大、电磁干扰强的使用环境;具备断电来电后自动重启的能力,具备多级组网能力。该实施例中共收集砂土、强风化岩、全风化岩三种地质下的设备运行数据,分别提取并存储各地质条件下的掘进段数据。图2所示的是在不同地质条件下推进力与推进速度分布情况,其中,坐标横轴为推进速度(m/s),纵轴为总推进力(bar);黄色点为广州段强风化岩;蓝色为广州段全风化岩,红色为郑州段砂质黏土层;图3所示的是不同地质条件下刀盘扭矩、推进力和推进速度的分布情况。花岗岩与砂土地层的总推进力所处区域接近;花岗岩与全风化岩的推进速度所处区域接近;在刀盘扭矩、推进速度、总推进力的三维空间中,全风化岩、强风化岩、砂土分布区域虽然有一定重合,但相比于一维属性空间来说,不同地质条件已能较好地区分。上述不同地质条件下各变量分布规律的可视化图也表明通过历史经验掘进数据,借助于大数据算法理论,能够利用当前掘进数据进行反演地质类别。表1.主动参数表表2.被动参数表名称物理意义数据来源单位刀盘功率实测的驱动电机总功率传感器实测kw总推进力表征土压平衡盾构机机工作能力的主要指标与推进压力的量纲换算kn推进压力测量出的4组推进液压压强加权和传感器实测bar滚动角盾体相对于预先设定水平线的摆动夹角传感器实测deg俯仰角土压平衡盾构机轴线在垂直方向上的倾斜角度传感器实测deg贯入度土压平衡盾构机机刀盘旋转一圈所掘进的长度公式计算mm/r设备桥压力设备桥油缸的压强传感器实测bar铰接压力铰接油缸的压强传感器实测bar螺机前部压力螺机进口土的压强传感器实测bar螺机后部压力螺机出口土的压强传感器实测bar螺机扭矩机器上位机plc自动计算出来的公式计算kn左中土仓压力土仓中分区的压强传感器实测bar左上土仓压力土仓中分区的压强传感器实测bar左下土仓压力土仓中分区的压强传感器实测bar右下土仓压力土仓中分区的压强传感器实测bar右中土仓压力土仓中分区的压强传感器实测bar顶部土仓压力土仓中分区的压强传感器实测bar刀盘扭矩plc自动计算出来的公式计算kn*ma组推进位移a组油箱推进位移传感器实测mmb组推进位移b组油箱推进位移传感器实测mmc组推进位移c组油箱推进位移传感器实测mmd组推进位移d组油箱推进位移传感器实测mm首先,从盾构大数据平台的原始数据中共收集砂土、强风化岩、全风化岩三种地质下的设备运行数据,抽取精简的数据集,主动参数和被动参数如表1和表2所示:然后,删除精简的原始数据集中属性值缺失的记录,并对精简的原始数据集按照环号和时间进行索引排序,分别提取并存储各地质条件下的掘进段数据。其次,分别在对上述提取到的掘进段土压平衡盾构机运行数据按地质信息添加标签列,并以刀盘扭矩、总推进力、推进速度、贯入度等参数为基准变量,依次在数据集中添加新的变量列参与模型的训练过程。最后,分别以k-means无监督模型及有监督随机森林模型对地质类别进行预测,在刀盘扭矩、总推进力、推进速度、贯入度等基准变量上预测结果如下:砂土与全风化岩的预测结果:所用数据为广州段环号8787、8788掘进段全风化岩数据;环号8745、8746、8847、8848掘进段砂土层数据。其中,砂土层558条,全风化岩3154条数据。训练集所占比重为p=0.7。在测试集上的混淆矩阵及准确率如下:k-mean无监督预测结果准确率为100%,如图5所示;随机森林(rf)预测结果准确率为100%,如图6所示。砂土与强风化岩的预测结果:所用数据为广州段环号8752、8753掘进段强风化岩数据;环号8745、8746、8847、8848掘进段砂土层数据。其中,砂土层558条,强风岩1830条数据。训练集所占比重为p=0.7。在测试集上的混淆矩阵及准确率如下:k-mean无监督预测结果准确率为100%,如图7所示;随机森林(rf)预测结果准确率为100%,如图8所示。强风岩与全风岩的预测结果:所用数据为广州段环号8787、8788掘进段全风化岩数据;环号8752、8753掘进段强风岩数据。其中,强风化岩1830条,全风岩3154条数据。训练集所占比重为p=0.7。k-mean无监督预测结果准确率为56%,如图9所示;随机森林(rf)预测结果准确率为95%,如图10所示。从上述混淆矩阵及准确率可以看出:对于差异较大的地层(砂土、岩体),无监督k-means模型及有监督随机森林(rf)模型在土压平衡盾构机运行关键参数(刀盘扭矩、总推进力、推进速度、贯入度)的基础上均能较好的识别出该类地质;但在地质条件接近的岩体层(全风化岩、强风化岩),依靠上述数据经k-means算法识别的准确率较差,随机森林(rf)模型的预测准确率仍在95%。同时注意到无监督k-means算法受初始点影响较大,未给定初始点时,随机预测结果会与上述结果有一定的偏差。应理解,本实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1