基于YOLOv3改进的交通标志检测与识别方法与流程
本发明涉及人工智能机计算机视觉技术领域,尤其涉及一种基于yolov3改进的交通标志检测与识别方法。
背景技术:
近年来自动驾驶技术蓬勃发展,而交通标志作为重要的安全指示标志,事关人民生命安全,其检测与识别更是尤为重要,其中不可避免的需要应用目标检测技术。目标检测技术分为传统目标检测技术与深度学习目标检测技术。
传统目标检测技术采用特征提取加上分类器的方法进行检测识别。该方法通过滑动窗口遍历图像,在对特征进行提取之后,用分类器进行分类。这种方法取得了一定的成果,但不可忽略的是,该方法复杂度高,并且强烈依赖于人工特征的选取、泛化能力差,无法应对复杂的应用场景。此外,分类器的性能也存在着缺陷。而随着深度学习的发展,以卷积神经网络为代表的深度学习目标检测技术逐渐崛起。
深度学习目标检测技术使用卷积神经网络进行特征提取,通过训练学习,实现了更加强大的适应能力和泛化能力。当前,深度学习目标检测主要分为两大类:以rcnn系列为代表的two-stage方法和以yolo、ssd为代表的one-stage方法。
two-stage方法分为两个阶段,首先在图片中产生候选区域,然后对候选区域进行进一步的检测和分类,在准确率上获得了较强的性能。而one-stage方法直接对预测的目标进行回归,拥有速度上的优势。
在交通标志的检测识别应用场景中,对检测算法的速度和性能都提出了较高的需求。
yolov3网络模型是yolo(youonlylookonce)系列目标检测算法中的第三版,采用多个尺度融合的方式进行预测,在保持速度优势的前提下,提升了预测精度,代表了目前目标检测领域的顶尖水平。yolov3是典型的基于回归方法的一阶段深度学习目标检测网络,利用了回归的思想,对于给定的输入图像,直接在图像的多个位置上回归出这个位置的目标边框以及目标类别。传统的yolov3网络在yolov2的基础上进行了一些应用性的改进,不仅借鉴resnet(残差网络)提出了更为强大的darknet53网络来进行特征提取,而且采用多个尺度相融合的方式进行目标检测,具有优异的检测性能,传统的yolov3网络模型在各大目标检测公共数据集上均具有优异的检测性能。
但是,对于交通标志识别任务而言,yolov3网络主体仍较为庞大,因此需要进一步改进。
技术实现要素:
本发明提供了一种基于yolov3改进的交通标志检测与识别方法,对yolov3进行了改进,在保持yolov3算法在交通标志检测识别上的性能,同时对检测算法进行精简。
具体技术方案如下:
一种基于yolov3改进的交通标志检测与识别方法,包括以下步骤:
(1)获取和标注交通标志图像数据集,作为训练集;
(2)构建yolov3改进网络模型;
(3)通过训练集对所述的yolov3改进网络模型进行训练;
(4)通过训练好的yolov3改进网络模型对待测交通标志图像进行检查与识别。
本发明采用ctsd数据集(中国交通标志数据集)作为训练集,将ctsd数据集的格式修改为符合yolo网络的输入格式。
步骤(2)中包括:
将yolo网络模型原有的darknet53网络替换为mobilenetv2网络;从mobilenetv2网络中提取三层特征图,通过invres2netblock对三层特征图进一步提取特征,然后进行上采样与原有特征进行融合,作为新的候选特征;再使用nas-fpn结构对新的候选特征进行进一步的特征融合;
采用giou改进损失函数。
进一步地,步骤(2)中包括:
(2-1)对yolo网络模型原有的darknet53网络进行修改,使用mobilenetv2结构进行替换;
(2-2)增强多尺度特征融合能力;
依次从mobilenetv2结构中提取下采样分别为8、16、32的特征图:route_1、route_2和route_3;使用inv_res2net_block从route_1、route_2和route_3中进一步特征提取,再进行上采样操作,获得融合后的特征c3、c4和c5。
(2-3)对特征c5进行卷积操作后,获得特征c6和c7;
(2-4)将获取的融合特征c3、c4、c5、c6和c7作为输入,通过nas-fpn结构进行更深层次的融合,选取p3、p4和p5作为预测的输出;
nas-fpn是谷歌大脑提出的一种通过自动架构搜索出的金字塔网络结构,其特征融合能力更加优秀,并且可以方便的进行多次融合。
(2-5)采用giou改进yolo网络模型原有的定位损失函数。
iou表达式为:
giou表达式为:
其中:a、b为任意凸形,c为可以包含a、b在内的最小的封闭形状。
giou损失表达式为:
lgiou=1-giou。
步骤(2-4)中,通过nas-fpn结构进行更深层次的融合,选择13×13、26×26、52×52作为三个输出特征图;网络重复次数设置为7。
进一步优选的,步骤(2)还包括:采用k-means++算法对训练集数据的标注信息进行聚类,获得所需的anchor值。采用该技术方案可以实现更好的检测效果,并加快收敛速度。
优选的,步骤(3)中,采用momentum动量算法进行训练,同时采用warmup策略防止梯度爆炸;进一步地,图片输入尺寸设置为416,初始学习率设置为1e-3。
优选的,步骤(3)中,采用多尺度训练策略以及mixup和/或randomcrop数据增强方法进行训练。
与现有技术相比,本发明的有益效果为:
本发明中的yolov3改进网络模型采用mobilenetv2网络结构极大的减少了参数量;同时,通过inv_res2net_block卷积与nas-fpn结构优化了特征融合效果;采用giou改进损失函数;以及在训练中使用多尺度训练和数据增强方法,使得模型检测效果得到了提高。通过上述方法,本发明实现了相较于yolov3原有算法相近的检测性能,同时模型得到了精简。
附图说明
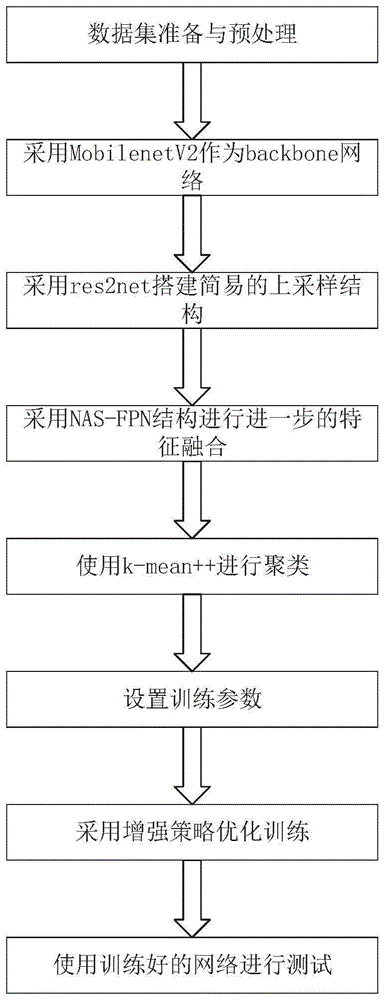
图1为本发明基于yolov3改进的交通标志检测与识别方法的流程图;
图2为本发明改进的模型结构示意图;
图3为inv_res2net_block的结构示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
如图1所示,本发明基于yolov3改进的交通标志检测与识别方法包括以下步骤:
(1)准备数据集
本发明采用ctsd数据集(中国交通标志数据集)进行实验,实验需求数据集格式为yolo网络的输入格式(voc格式),因此需要对原有图片集标注的txt文件进行转化。通过读取标注文件,生成xml文件,存入annotation文件夹中。并将数据分为训练(train)和测试(test)两部分,依次生成两份txt文件,存入main文件夹。生成voc数据集后,运行代码进行相关转化。
(2)对原有yolov3网络进行改进,具体改进措施如下:
对原有的darknet53网络进行修改,使用mobilenetv2结构进行替换。mobilenetv2采用inverted_res_block结构,改变原有mobilenetv1结构先进行扩张,提高通道数,获取更多特征,最后进行压缩。同时采用linearbottlenecks避免了relu对特征的破坏。mobilenetv2网络在缩减计算量的同时,拥有着良好的特征提取能力。
增强多尺度特征融合能力。仿照原有yolov3结构,如图2所示,依次从mobilenetv2结构中提取下采样倍数分别为8、16、32的特征图(featuremap):route_1、route_2和route_3。使用图3所示的inv_res2net_block进行进一步特征提取,然后进行上采样操作,获得简单融合后的特征c3、c4和c5。
inv_res2net_block是在原有的inverted_res_block结构基础上,参考res2net结构进行构建。通过增加小的残差块,增加了每一层的感受野。此外,在其中加入了seblock对通道关系进行建模,并在最后使用通道随机混合(channelshuffle)实现通道间的信息交流。对c5进行卷积操作后,获得特征图输出c6和c7。其后,将获取的融合特征作为输入,通过nas-fpn结构获得更深层次的融合,因交通标志的小目标特性,选取对应着下采样倍数为8、16、32的特征图p3、p4和p5作为预测的输出。图2中的nas-fpn结构是谷歌大脑提出的一种通过自动架构搜索出的金字塔网络结构,其特征融合能力更加优秀,并且可以方便的进行多次融合。
采用giou改进损失函数。iou是目标检测任务中最常用的指标,但是,当两个物体不相交时,两个物体无法回转梯度。同时,其对于目标检测中的尺度是不敏感的。检测任务中采用的回归损失与iou优化并非完全等价的。giou对上述缺点进行了改进,本发明通过引入giou算法对原有损失函数进行修改。使用giou损失替代原有的定位损失函数部分,获得了更加优异的性能。
yolov3原有定位损失为:
lloc=lxy+lwh
式中,k表示网格划分数目;m表示的是每个网格所预测的边框数量;
iou表达式为:
giou表达式为:
上述公式中:a、b为任意凸形,c为可以包含a、b在内的最小的封闭形状。
giou损失表达式为:
lgiou=1-giou
(3)使用k-means++对训练集数据中标注的真实目标边框进行聚类
yolov3的原文中使用k-means算法来进行anchor的聚类,而k-means算法在初始时随机选取k个点作为聚类中心,所以结果会受到初始点选取的影响。而k-means++算法通过随机选取第一个聚类中心,其后通过选取远离已有的聚类中心的点作为新的聚类中心。通过上述方法,k-means++能够有效的改善最终的误差。
(4)使用改进后的模型进行模型训练
图片输入尺寸设置为416,初始学习率设置为1e-3,采用momentum动量算法进行训练,同时采用warmup策略防止梯度爆炸。为了进一步提高检测效果,使用多尺度训练方法及数据增强方法。通过这些训练方法,极大的提高了训练得到的模型的性能及泛化能力。
(5)使用训练好的模型进行最终的检测测验
设置网络状态为测试,可以通过参数设定获取相应下的实验结果,并在测试原图中进行可视化显示。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!