基于碎片化知识下的卷积嵌入表示推理方法与流程
本发明涉及知识图谱下的海量数据存储与推理领域,具体涉及一种基于碎片化知识下的卷积嵌入表示推理方法。
背景技术:
目前,卷积嵌入表示推理算法现有关系图卷积网络r-gcn和二维卷积知识图嵌入conve。前者使用卷积算子来捕获图中的局部信息,它可以在计算每个节点的卷积时采用相同的聚合方案。r-gcn模型主要是对gcns(图神经网络)进行扩展,将其从局部图领域扩展到可以处理大规模知识图,图神经网络可以被理解为简单可微的消息传递框架的特殊情况。conve模型首先对头实体嵌入向量和关系嵌入向量连接并整形成一个矩阵,将这个矩阵视为图片矩阵,然后使用卷积对这个“图片”进行特征图的提取。得到特征图之后,展平并全连接,然后与权重矩阵w相乘得到一个与尾实体维度相同的向量,最后将这个向量与全部尾实体相乘,得到的结果经过logistic-sigmoid函数处理成零到一之间的一系列值作为事实三元组的可信程度。
r-gcn模型只能处理无向图,无法解决现实生活中有向知识图的问题;conve模型效果不错,但它在进入卷积之前需要把头实体嵌入向量和关系嵌入向量进行连接操作,因此模型的效果与两者的二维形状有关,不同的形状的连接方式可能导致不同的效果,并且头实体与关系的交互仅发生在连接处,浪费了两者大量的维度信息。另外,conve模型只考虑了事实三元组本身的信息,忽略了知识库中其他实体对事实三元组的影响。由于知识碎片的到来将使得知识库动态变化,现有嵌入表示推理方法无法解决动态碎片化推理问题。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于碎片化知识下的卷积嵌入表示推理方法,结合碎片化知识动态特点进行模型学习与推理,能够适应动态碎片知识进行模型学习与推理。
为实现上述目的,本发明采用如下技术方案:
一种基于碎片化知识下的卷积嵌入表示推理方法,包括以下步骤:
步骤s1:从百科页面中的词条提取关键字,并使用cypher语法存入neo4j数据库;
步骤s2:从neo4j数据库获取事实三元组;
步骤s3:判断事实三元组中实体和关系是否已经训练,如果已训练则进行步骤s4,否则进行步骤s5;
步骤s4:去掉头实体或者尾实体,使完整的事实三元组破坏并形成缺失事实三元组,并将其放入ce-rcf模型中计算得到评估结果,如果该评估结果大于设定阈值,则将事实三元组标记为已训练事实三元组;
步骤s5:判断未训练事实三元组数量是否大于阈值,如果大于阈值则将全部事实三元组放入ce-rcf模型中进行参数训练,否则将当前事实三元组标记为未训练事实三元组;
步骤s6:判断是否需要开启下一次,如果不需要开启下一次训练则直接将该事实三元组标记为未训练的事实三元组并存储起来,否则将未训练的事实三元组和已训练事实三元组共同取出并合并,输入ce-rcf模型进行训练或重新训练;
步骤s7:将合并后的全部事实三元组标记为已训练事实三元组并存储,得到完善后的事实三元组。
进一步的,所述ce-rcf模型具体为:
1)知识库中有一个事实三元组(hi,rj,tk),将头实体嵌入向量hi视为一张图片,并将每个头实体嵌入向量整形为一个矩阵"image"i如公式所示:
"image"i=res(hi)
2)对关系嵌入向量rj进行处理,生成包含全部实体嵌入向量信息的m个卷积滤波器权重矩阵
3)将头实体图片矩阵"image"i经过所有卷积滤波器权重矩阵
4)将所有特征图fmli,j整形并全连接为向量fvi,j
5)将向量fvi,j经过全连接网络,并使用激活函数转化为d维特征
向量
6)首先将特征向量
根据上述过程,将事实三元组(hi,rj,tk)的得分转化为头实体嵌入表示hi在关系rj下的特征与尾实体tk的契合程度的问题,事实三元组(hi,rj,tk)的得分score(hi,rj,tk)表示为:
进一步的,所述卷积滤波器权重矩阵具体为:
1)将关系嵌入向量rj与全部实体嵌入向量点积,并连接为|e|维向量
2)将向量
3)将卷积滤波器权重向量
对于卷积滤波器权重向量
对于事实三元组(hi,rj,tk),卷积滤波器权重矩阵
根据上述过程,将事实三元组(hi,rj,tk)的得分score(hi,rj,tk)函数由变换为:
进一步的,所述步骤s6具体为:
步骤s61:判断事实三元组数组中头实体、关系与尾实体是否都存在于现有模型中,如果存在则进行有效推理校验,根据校验结果来判断该事实三元组是否能直接使用;只要三元组有一个元素不在现有模型中或有效推理校验结果表明该事实三元组不能直接使用,则检测未训练事实三元组数量是否达到开启下一次训练的标准;
步骤s62:如果校验结果表明该事实三元组能直接使用,则将其标记为已训练事实三元组并存储起来;如果不需要开启下一次则直接将该事实三元组标记为未训练的事实三元组”并存储起来,否则将未训练的事实三元组和已训练事实三元组共同取出并合并,并进行训练或重新训练。
本发明与现有技术相比具有以下有益效果:
1、本发明结合碎片化知识动态特点进行模型学习与推理,能够适应动态碎片知识进行模型学习与推理。
2、本发明法简化了实体与关系的连接操作,设计了可以包含全部实体信息的特定关系的卷积滤波器权重生成方式,并以此来提取头实体的特征。提高了链路预测性能。
附图说明
图1是本发明方法流程图;
图2是本发明一实施例中ce-rcf整体模型图;
图3是本发明一实施例中生成卷积滤波器权重矩阵可视化;
图4是本发明一实施例中卷积滤波器权重矩阵神经网络可视化。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
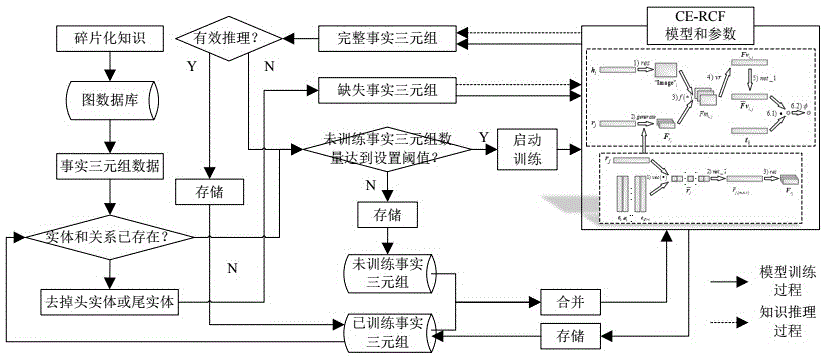
请参照图1,本发明提供一种基于碎片化知识下的卷积嵌入表示推理方法,包括以下步骤:
步骤s1:从百科页面中的词条提取关键字,并使用cypher语法存入neo4j数据库;
步骤s2:从neo4j数据库获取事实三元组;
步骤s3:判断事实三元组中实体和关系是否已经训练,如果已训练则进行步骤s4,否则进行步骤s5;
步骤s4:去掉头实体或者尾实体,使完整的事实三元组破坏并形成缺失事实三元组,并将其放入ce-rcf模型中计算得到评估结果,如果该评估结果大于设定阈值,则将事实三元组标记为已训练事实三元组;
步骤s5:判断未训练事实三元组数量是否大于阈值,如果大于阈值则将全部事实三元组放入ce-rcf模型中进行参数训练,否则将当前事实三元组标记为未训练事实三元组;
步骤s6:判断事实三元组数组中头实体、关系与尾实体是否都存在于现有模型中,如果存在则进行有效推理校验,根据校验结果来判断该事实三元组是否能直接使用;只要三元组有一个元素不在现有模型中或有效推理校验结果表明该事实三元组不能直接使用,则检测未训练事实三元组数量是否达到开启下一次训练的标准;如果校验结果表明该事实三元组能直接使用,则将其标记为已训练事实三元组并存储起来;如果不需要开启下一次则直接将该事实三元组标记为未训练的事实三元组”并存储起来,否则将未训练的事实三元组和已训练事实三元组共同取出并合并,并进行训练或重新训练。
步骤s7:将合并后的全部事实三元组标记为已训练事实三元组并存储,得到完善后的事实三元组。
在本实施例中,预定义如下表:
表1相关名词符号及其含义
表2相关函数符号及其含义
表3相关其他符号及其含义
对于关系的类型有如表4所示4种。
表4相关系类型
其中一对一关系(1-1)为简单关系,多对一关系(n-1)、一对多关系(1-n)、多对多关系(n-n)为复杂关系。
在本实施例中,在conve的基础上提出了一种新的卷积链路预测模型ce-rcf,去掉了其中的头实体嵌入和关系嵌入连接过程,让头实体嵌入向量进行卷积不受二维形状和与关系连接方式的影响,并设计了卷积时使用的滤波器权重矩阵的生成方式,让包含全部实体信息的卷积滤波器权重与头实体嵌入向量交互:关系嵌入向量与实体嵌入向量点积后与权重矩阵相乘,生成卷积滤波器权重矩阵。ce-rcf模型可视化如图2所示,所述ce-rcf模型具体为:
1)知识库中有一个事实三元组(hi,rj,tk),将头实体嵌入向量hi视为一张图片,并将每个头实体嵌入向量整形为一个矩阵"image"i如公式所示:
"image"i=res(hi)
2)对关系嵌入向量rj进行处理,生成包含全部实体嵌入向量信息的m个卷积滤波器权重矩阵
3)将头实体图片矩阵"image"i经过所有卷积滤波器权重矩阵flrj进行卷积后得到该m个特征图fmli,j,其中l∈[0,m),
4)将所有特征图fmli,j整形并全连接为向量fvi,j
5)将向量fvi,j经过全连接网络,并使用激活函数转化为d维特征向量
6)首先将特征向量
根据上述过程,将事实三元组(hi,rj,tk)的得分转化为头实体嵌入表示hi在关系rj下的特征与尾实体tk的契合程度的问题,事实三元组(hi,rj,tk)的得分score(hi,rj,tk)表示为:
在本实施例中,一个事实三元组(hi,rj,tk)的m个卷积滤波器权重矩阵
1)将关系嵌入向量rj与全部实体嵌入向量点积,并连接为|e|维向量
2)将向量
3)将卷积滤波器权重向量
对于卷积滤波器权重向量
对于事实三元组(hi,rj,tk),卷积滤波器权重矩阵
根据上述过程,将事实三元组(hi,rj,tk)的得分score(hi,rj,tk)函数由变换为:
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!