基于多任务最小二乘支持向量机的股票指数预测方法与流程
本发明属于计算机技术领域,涉及基于多任务最小二乘支持向量机的股票指数预测方法。
背景技术:
股票市场是证券业和金融业必不可少的组成部分,也是对国家经济运行发展的侧面反映,受到广大投资者的普遍关注。在股票交易市场中,股市指数的运行趋势直接决定投资环境的安全性。不论是为了预防股市投资环境的系统结构性风险,还是提前收获股票市场投资的红利,对股市指数的精准预测均能为股票实盘交易提供很多有用信息。由于股票市场容易受到政策、经济、企业运营发展以及投资者心理等诸多复杂因素的影响,因此对股票市场的回归预测成为一大重要难题。
传统的股市预测分析方法主要包括:证券投资分析法、数理统计模型方法、非线性动力学方法以及时间序列挖掘方法。证券投资分析法需要密切关注国际国内动态并具备较强的市场洞察能力;数理统计模型方法以及非线性动力学方法更需要培养极强的数学建模能力,且对数理统计能力要求较高;时间序列挖掘方法同样要求具备较高的计算机技术应用能力。因此,对于普通投资者而言,通过这些传统的方法来预测股市是极为困难的。
目前采用新型支持向量机bp神经网络、深度学习以及数据挖掘技术等方法对股票市场进行预测,其均属于单任务学习方式进行预测,即只考虑一支股票指数,这些技术存在易陷于局部最优解、隐层结构无规律可循、忽略数据间内部关联性等缺陷,导致股票指数预测的精度不高。
技术实现要素:
本发明解决的技术问题在于考虑子任务之间的内在关联性,提供一类提高股票指数预测精度的基于多任务最小二乘支持向量机的股票指数预测方法。
本发明是通过以下技术方案来实现:
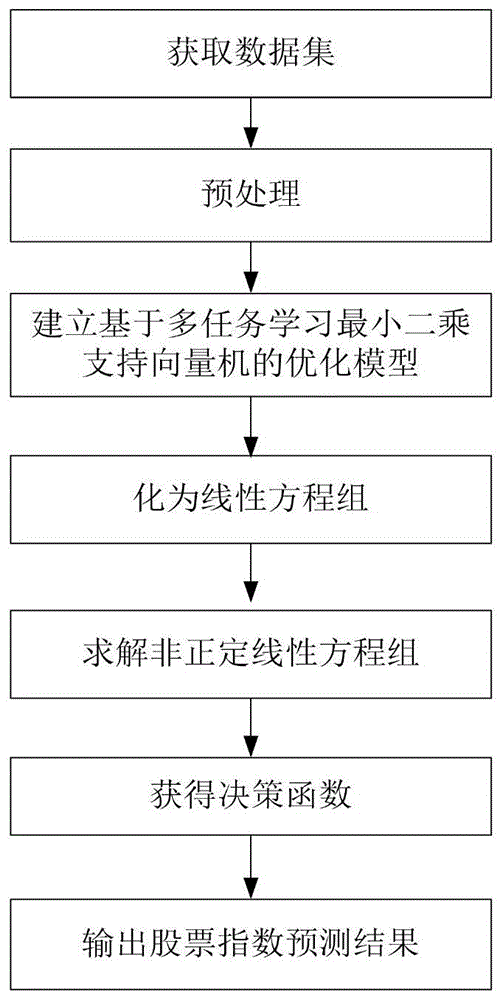
基于多任务最小二乘支持向量机的股票指数预测方法,包括以下步骤:
步骤1:分别下载多支股票指数在预测日之前交易日的行情数据并进行预处理,获取数据集;其中,每个股票指数为一个子任务;
步骤2:根据包含每个子任务的多任务学习假设建立基于多任务学习最小二乘支持向量机的优化模型;
步骤3:通过kkt条件将基于多任务学习最小二乘支持向量机的优化模型转化为非正定线性方程组;
步骤4:通过krylov-cholesky算法求解非正定线性方程组,得优化模型的解;
步骤5:由优化模型的解求得基于多任务学习最小二乘支持向量机的决策函数;
步骤6:将数据集分为训练样本集和测试样本集;通过训练样本集获得股票指数的预测模型,采用测试样本集测试该模型的预测精度和鲁棒性,并与已有方法作对比。
进一步地,步骤1中股票指数包括上证指数、深证成指、创业板指数以及中小板指数;行情数据包括每个交易日的开盘价、收盘价、最高价、最低价、前收盘价、成交量、成交金额、换手率、涨跌额、涨跌幅。
进一步地,步骤2中多任务学习假设为:对于彼此不同却相互关联的子任务,所有子任务内部之间共享一个通用模型ρ0,每个子任务还同时具有独立的子模型ηt,每个子任务的决策函数表示为:
其中ω0和
进一步地,步骤2中多任务学习包括t个彼此不同却相互关联的学习任务,每个任务中包含取自于空间x×y中mt个样本点
进一步地,步骤2中基于多任务学习最小二乘支持向量机优化模型为:
其中
进一步地,步骤3中基于多任务学习最小二乘支持向量机优化模型通过kkt条件,能够转化为非正定线性方程组:
其中,
进一步地,非正定线性方程组通过步骤4中的krylov-cholesky算法转化为:
其中s=htq-1h为正实数,qm×m为正定对称矩阵且
进一步地,步骤5中由最优解求得基于多任务学习最小二乘支持向量机的决策函数为:
其中k0(·,·)对应于通用模型中的映射函数
进一步地,步骤6中选取评价指标,并与已有方法作对比,具体方法为:
定义训练样本集的样本点个数为l,测试样本集的样本点个数为k;xi表示样本属性值,yi和
mae:平均绝对误差,定义为:
rmse:均方根误差,定义为:
sse:误差平方和,定义为:
sst:真实值偏差平方和,定义为:
ssr:预测值偏差平方和,定义为:
sse/sst:归一化均方误差,定义为:
ssr/sst:拟合度,定义为:
当mae、rmse、sse、sst、ssr以及sse/sst的值越小,或者ssr/sst的值越大时,模型的预测精度越高。
与现有技术相比,本发明具有以下有益的技术效果:
本发明提供的基于多任务最小二乘支持向量机的股票指数预测方法,将若干支股票指数作为彼此不同却相互关联的子任务同时学习,通过训练样本集获得股票指数的预测模型,在测试样本集上与单任务学习方法进行对比。本发明的多任务学习方式能够考虑子任务之间的内在关联性,从而提高股票指数的预测精度,同时获得较强的鲁棒性;由于其采用多任务学习方法对股票指数开盘价进行预测,因此能更合理地利用股票指数间的交叉关联性,进而获得精度更高的预测效果;另外,本发明利用最小二乘支持向量机将二次规划问题转化为非正定线性方程组进行求解,有效地降低了计算复杂度,减少了训练时间。
附图说明
图1为本发明流程示意图;
图2为本发明股票指数某一天的日内分时图(用以体现各子任务之间的关联性);
图3为两种单任务学习方法和本专利提供的三种多任务学习方法对上证指数(ssec)400天的预测结果对比图;
图4为图3的局部放大图;
图5为两种单任务学习方法和本专利提供的三种多任务学习方法对深证成指(szi)400天的预测结果对比图;
图6为图5的局部放大图;
图7为两种单任务学习方法和本专利提供的三种多任务学习方法对创业板指(chinextc)400天的预测结果对比图;
图8为图7的局部放大图;
图9为两种单任务学习方法和本专利提供的三种多任务学习方法对中小板指(szsme)400天的预测结果对比图;
图10为图9的局部放大图。
具体实施方式
下面给出具体的实施例。
如图1所示,基于多任务最小二乘支持向量机的股票指数预测方法,包括以下步骤:
如图1所示,基于多任务最小二乘支持向量机的股票指数预测方法,包括以下步骤:
步骤1:本实施例在网易财经官网上下载上证指数ssec、深证成指szi、创业板指chinextc以及中小板指szsme等股票指数的行情数据的历史数据;各股票指数的历史数据包括从2010年7月1日到2019年7月10日的2195个交易日数据。每个交易日数据作为一个样本点,主要包括10个指标:开盘价、收盘价、最高价、最低价、前收盘价、涨跌额、涨跌幅、换手率、成交量、成交额;对行情数据的历史数据进行预处理,首先修正和去除不规则数据,然后修补缺失的数据,具体可以采用均值修补法,调取相邻数据取均值,修补缺失的数据具体可以依据实际情况而定,得数据集;其中,每支股票指数为一个子任务;
步骤2:根据包含每个子任务的多任务学习假设建立基于多任务学习最小二乘支持向量机的优化模型;
其中,多任务学习假设为:对于彼此不同却相互关联的四个子任务,所有子任务内部之间共享一个通用模型ρ0,对于每个子任务同时具有独立的子模型ηt,每个子任务的决策函数可以表示为:
其中ω0和
多任务学习包括t个彼此不同却相互关联的学习任务,每个学习任务中包含取自于空间x×y中mt个样本点
从而得到基于多任务学习最小二乘支持向量机优化模型:
其中
步骤3:通过kkt条件将基于多任务学习最小二乘支持向量机优化模型转化为非正定线性方程组:
其中,
步骤4:通过krylov-cholesky算法将非正定线性方程组转化为;
其中s=htq-1h为正实数,qm×m为正定对称矩阵且
步骤5:由优化模型最优解求得基于多任务学习最小二乘支持向量机的决策函数为:
其中k0(·,·)对应于通用模型中的映射函数
步骤6:从获取的数据集中选取80%作为训练样本集,余下的20%作为测试样本集;然后通过训练样本集获得股票指数的预测模型,输出股票指数预测结果;采用测试样本集测试模型的预测精度和鲁棒性,选取评价指标并与已有方法作对比。
选择具体指标的方法为:
定义训练样本集的样本点个数为l,测试样本集的样本点个数为k。xi表示样本属性值,yi和
mae:平均绝对误差,定义为:
rmse:均方根误差,定义为:
sse:误差平方和,定义为:
sst:真实值偏差平方和,定义为:
ssr:预测值偏差平方和,定义为:
sse/sst:归一化均方误差,定义为:
ssr/sst:拟合度,定义为:
mae、rmse、sse、sst、ssr以及sse/sst的值越小,或者ssr/sst的值越大,模型的预测精度越高。
本实施例中图2为四个股票指数(ssec、szi、chinextc和szsme)在2019年7月19日的日内分时曲线比例图,x轴为该日股票交易的时间(分钟),y轴为各股票指数当日涨跌变化率(以前一日收盘指数为基准,根据指数涨跌变化归一化生成的数据)。从图2中可以明显看出:四大股票的日内指数运行趋势大致相同,且几乎在同一时刻达到日内最高点及最低点,将每个股票指数作为一个子任务,图2体现了子任务之间的密切关联性。本发明提出的基于多任务学习最小二乘支持向量机的股票指数预测方法的决策函数中k0(·,·)和kt(·,·)可以选取不同的核函数组合得到不同的基于多任务学习最小二乘支持向量机的股票指数预测方法。本实施例中选择线性核函数与多项式核函数,线性核函数与径向基核函数,以及多项式核函数与径向基核函数的组合,分别得到emtl-ls-svr(l+p)、emtl-ls-svr(l+r)、emtl-ls-svr(p+r)三种基于多任务学习最小二乘支持向量机的股票指数预测方法。将本发明提出的三种方法与两种单任务学习方法即孪生支持向量机(tsvr)、原始最小二乘孪生支持向量机(plstsvr)作比较,具体的比较结果如表1所示,实验结果为20次实验的平均值。表1实验结果表明:对于mae、rmse、sse/sst三个指标,三种多任务学习最小二乘支持向量机方法在四支股票指数预测中均取得最小值,在ssr/sst指标上三种多任务学习最小二乘支持向量机方法在四支股票指数预测中取得最大值。因此,本发明提供的三种基于多任务学习最小二乘支持向量机的股票指数预测方法对四支股票指数均取得较高的预测精度,且具有较强的鲁棒性。从五种方法的预测结果可以看出plstsvr的预测效果最差。图3-图10表示五种方法分别对四大股票市场指数的预测曲线,针对大数据预测问题,图3、图5、图7、图9仅给出了五种方法从2013年7月25日至2017年7月28日共400个连续交易日对四支股票的预测曲线对比,图4、图6、图8、图10依次为图3、图5、图7、图9存在明显预测差异区域(用虚框标出)的局部放大图。从图4、图6、图8、图10可以明显看出三种基于多任务学习最小二乘支持向量机方法对四支股票指数的预测效果最好,tsvr预测效果次之,plstsvr的预测效果最差。
表1五种算法对四支股票指数开盘价预测结果
- 还没有人留言评论。精彩留言会获得点赞!