一种基于脉动阵列的矩阵乘法处理器及其数据处理方法与流程
本申请涉及集成电路及通信技术领域,尤其涉及一种基于脉动阵列的矩阵乘法处理器及其数据处理方法。
背景技术:
神经网络模型中通常都包括大量的网络层,每一个网络层都存在权重矩阵与激活矩阵之间的卷积操作,其中权重矩阵中包含大量的权重数据,激活矩阵中包含大量的激活数据。在进行卷积操作时,一般会将卷积操作转化成矩阵乘法,然后使用矩阵乘法处理器进行计算,进而获得卷积操作的结果。
矩阵乘法处理器通常包括多个基本运算单元,这些基本运算单元排布成脉动阵列,多个权重数据和激活数据在时钟信号的控制下广播至脉动阵列中,整个矩阵乘法运算流程通过控制信号控制每一个基本运算单元不断的对接收到的权重数据和激活数据进行乘法累加运算实现。
在脉动阵列中,每行及每列的基本运算单元之间均设置有用于存储及传递中间运算结果的累加寄存器,由于累加寄存器也需要通过控制信号进行控制以执行存储动作,因此矩阵乘法处理器的控制信号包括用来控制累加寄存器的控制信号和控制运算流程的控制信号,由于这些控制信号都是独立分开的,并且每一类控制信号的数量都是比较多且均需单独布线,导致矩阵乘法处理器的布线复杂度高。
技术实现要素:
为了解决矩阵乘法处理器由于控制信号数量较多导致布线复杂度高的技术问题,本申请通过以下实施例公开了一种基于脉动阵列的矩阵乘法处理器及其数据处理方法。
本申请第一方面公开了一种基于脉动阵列的矩阵乘法处理器,包括:
由多个基本运算单元排布而成的脉动阵列,在所述脉动阵列中,每一列的任意两个相邻基本运算单元之间通过d触发器相连,所述d触发器用于根据时钟信号进行数据的的存储及传递;
每一个所述基本运算单元包括一个权重输入接口、一个数据输入接口、一个时钟信号接收接口以及一个控制信号接收接口,所述基本运算单元用于在控制信号的控制下,对接收到的权重数据以及激活数据执行乘法累加运算;
多个权重输入通道,一个所述权重输入通道对应接至所述脉动阵列其中一行所有基本运算单元的权重输入接口,所述权重输入通道用于按照所述时钟信号,将权重数据输入至对应行中的每一个基本运算单元;
多个数据输入通道,用于按照所述时钟信号,将激活数据输入至所述脉动阵列中每一列底端基本运算单元的数据输入接口,所述每一列底端基本运算单元为位于每一列中最后一行的基本运算单元。
可选的,每一个所述基本运算单元还包括一个本级结果输出接口以及一个前级结果输入接口;
其中,所述本级结果输出接口用于输出当前基本运算单元的输出结果,所述前级结果输入接口用于接收前级结果,所述前级结果为位于所述当前基本运算单元同一列前一行的基本运算单元的输出结果;
所述脉动阵列的每一列基本运算单元中,前一行基本运算单元的本级结果输出接口与后一行基本运算单元的前级结果输入接口相连接。
可选的,每一个所述基本运算单元内设置有一个乘法器、一个加法器、一个与门、一个非门、一个累加寄存器以及一个多路选择器;
其中,所述乘法器的输入端分别接至所述权重输入接口以及所述数据输入接口,输出端接至所述加法器的输入端;
所述加法器的输入端还接至所述与门的输出端,输出端接至所述累加寄存器的输入端;
所述非门的输入端接至所述控制信号接收接口,输出端接至所述与门的输入端;
所述累加寄存器的输入端还接至所述时钟信号接收接口,输出端分别接至所述与门的输入端以及所述多路选择器的输入端;
所述多路选择器的输入端还接至所述前级结果输入接口以及所述控制信号接收接口,输出端接至所述本级结果输出接口。
可选的,所述多路选择器为二选一多路选择器;
所述多路选择器用于接收控制信号、所述前级结果以及所述累加寄存器的累加结果,并根据所述控制信号,选择所述前级结果或者所述累加结果作为输出结果,发送至所述本级结果输出接口。
可选的,所述控制信号为1或0;
其中,若所述控制信号为1,则所述多路选择器选择所述累加结果作为所述当前结果;
或者,若所述控制信号为0,则所述多路选择器选择所述前级结果作为所述当前结果。
可选的,所述d触发器通过数据输入接口连接每一列的任意两个相邻基本运算单元。
本申请第二方面公开了一种基于脉动阵列的矩阵乘法处理器的数据处理方法,所述基于脉动阵列的矩阵乘法处理器的数据处理方法应用于本申请第一方面所述的基于脉动阵列的矩阵乘法处理器,所述基于脉动阵列的矩阵乘法处理器的数据处理方法包括:
获取权重矩阵以及激活矩阵,所述权重矩阵包括多个权重数据,所述激活矩阵包括多个激活数据;
根据时钟信号,将所述多个权重数据与所述多个激活数据按照预设规则依次广播至脉动阵列中,同时根据控制信号,控制每个基本运算单元对接收到的权重数据以及激活数据进行乘法累加运算;
根据控制信号,按行输出所述脉动阵列的运算结果。
可选的,所述预设规则包括:
在第一个时钟内,按照行序将所述权重矩阵中每行的第一个权重数据输入至所述脉动阵列对应行的所有基本运算单元中,按照列序将所述激活矩阵中每列的第一个激活数据分别输入至所述脉动阵列最后一行的基本运算单元中;
在第x个时钟内,按照行序将所述权重矩阵中每行的第x个权重数据输入至所述脉动阵列对应行的所有基本运算单元中,通过d触发器将每行基本运算单元中原有的激活数据按照列序传递至前一行基本运算单元中,然后按照列序将所述激活矩阵中每列的第x个激活数据分别输入至所述脉动阵列最后一行的基本运算单元中,其中,x为大于1的自然数。
可选的,所述根据控制信号,按行输出所述脉动阵列的运算结果,包括:
若某一行所有基本运算单元的控制信号皆为1,则输出该行所有基本运算单元的当前结果。
本申请实施例公开了一种基于脉动阵列的矩阵乘法处理器及其数据处理方法,该矩阵乘法处理器包括由多个基本运算单元排布而成脉动阵列、多个权重输入通道以及多个数据输入通道,在所述脉动阵列中,每一列的任意两个相邻基本运算单元之间通过d触发器相连,所述d触发器用于根据时钟信号进行数据的的存储及传递,基本运算单元用于在控制信号的控制下,对接收到的权重数据以及激活数据执行乘法累加运算,所述权重输入通道以及数据输入通道分别用于按照所述时钟信号,将权重数据输入至对应行中的每一个基本运算单元,将激活数据输入至所述脉动阵列中每一列底端基本运算单元的数据输入接口。当权重数据和激活数据在时钟信号的控制下广播至脉动阵列中时,d触发器同时进行数据的存储以及传递,无需额外的控制信号进行控制,有效减少控制信号的数量,降低矩阵乘法处理器的布线复杂度。
附图说明
为了更清楚地说明本申请的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
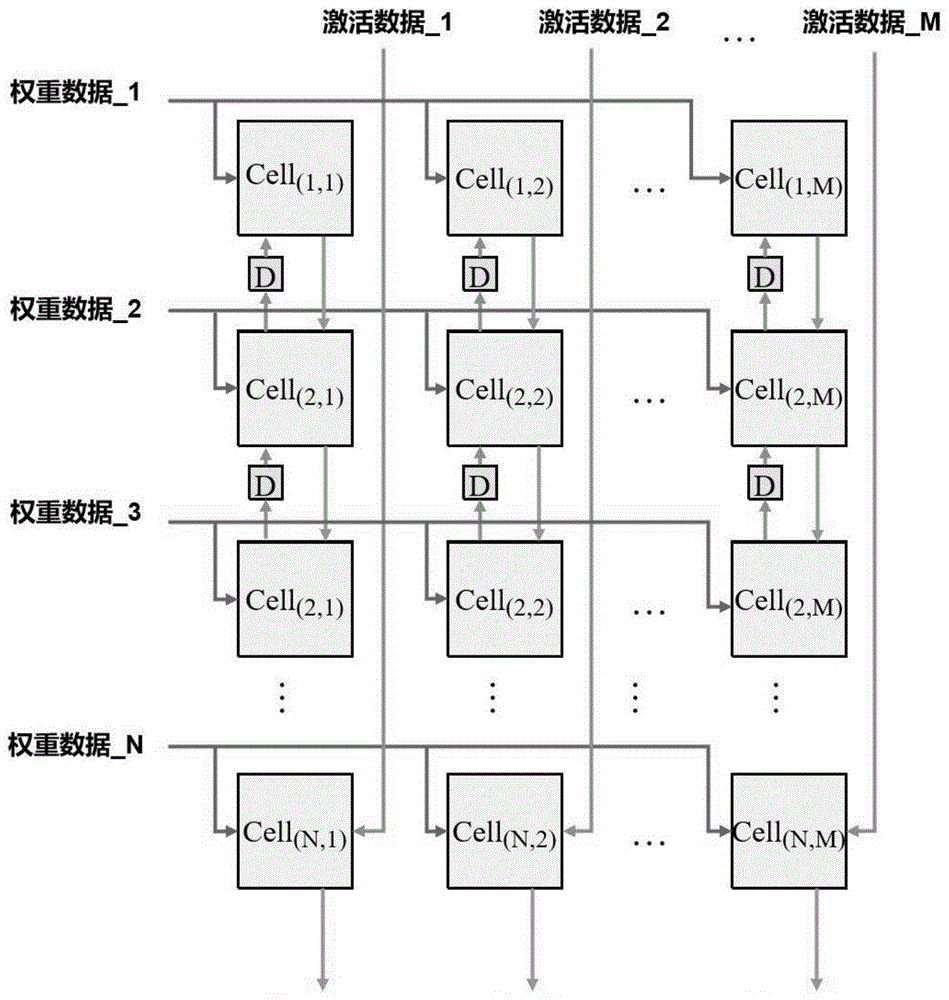
图1为本申请实施例公开的一种基于脉动阵列的矩阵乘法处理器的结构示意图;
图2为本申请实施例公开的一种基于脉动阵列的矩阵乘法处理器中,基本运算单元的结构示意图;
图3为本申请实施例公开的一种基于脉动阵列的矩阵乘法处理器的数据处理方法的工作流程示意图;
图4为本申请实施例公开的一种基于脉动阵列的矩阵乘法处理器在数据处理过程中数据流的示意图。
具体实施方式
为了解决矩阵乘法处理器由于控制信号数量较多导致布线复杂度高的技术问题,本申请通过以下实施例公开了一种基于脉动阵列的矩阵乘法处理器及其数据处理方法。
参见图1,本申请第一实施例公开的一种基于脉动阵列的矩阵乘法处理器,包括:
由多个基本运算单元(cell)排布而成的脉动阵列,脉动阵列由n*m个基本运算单元构成,其中,脉动阵列的维度是可以配置的,其行数n可以大于、小于或者等于列数m。在所述脉动阵列中,每一列的任意两个相邻基本运算单元之间通过d触发器相连,所述d触发器用于根据时钟信号进行数据的的存储及传递。在一种实现方式中,所述d触发器通过数据输入接口连接每一列的任意两个相邻基本运算单元。
多个权重输入通道,一个所述权重输入通道对应接至所述脉动阵列其中一行所有基本运算单元的权重输入接口,所述权重输入通道用于按照所述时钟信号,将权重数据(权重数据_1、权重数据_2、权重数据_3、…、权重数据_n)输入至对应行中的每一个基本运算单元。
多个数据输入通道,用于按照所述时钟信号,将激活数据(激活数据_1、激活数据_2、…、激活数据_m)输入至所述脉动阵列中每一列底端基本运算单元的数据输入接口,所述每一列底端基本运算单元为位于每一列中最后一行的基本运算单元。
所述基本运算单元用于在控制信号的控制下,对接收到的权重数据以及激活数据执行乘法累加运算。参见图2,每一个所述基本运算单元包括一个权重输入接口(weight)、一个数据输入接口(data)、一个时钟信号接收接口(clk)、一个控制信号接收接口(control)、一个本级结果输出接口(output)以及一个前级结果输入接口(resultin)。
其中,权重输入接口(weight)用于接收神经网络每一层中权重矩阵中的权重数据;数据输入接口(data)用于接收神经网络第一层的从外部传感器获得的激活数据,或者神经网络隐藏层中上一层的输出数据;时钟信号接收接口(clk)用于接收固定的时钟信号;控制信号接收接口(control)用于接收控制信号,所述控制信号由权重矩阵所决定,用于控制基本运算单元工作;本级结果输出接口(output)用于输出当前基本运算单元(cell)的运算结果,并将结果输出给同一列下一行的基本运算单元,作为同一列下一行基本运算单元的前级结果输入接口(resultin)的输入;前级结果输入接口(resultin)用于接收前级结果,所述前级结果为位于所述当前基本运算单元同一列前一行的基本运算单元的输出结果,如果基本运算单元的位置处在整个脉动阵列的第一行时,这个基本运算单元的前级结果输入接口(resultin)将直接接地。
所述脉动阵列的每一列基本运算单元中,前一行基本运算单元的本级结果输出接口与后一行基本运算单元的前级结果输入接口相连接。
本申请实施例中,针对矩阵乘法处理器进行布线时,对于任意一行,将一根数据线作为一个权重输入通道从外部连接至这一行的所有基本运算单元上。对于任意一列,将一根数据线作为一个数据输入通道从外部连接至这一列的最底端的基本运算单元上。对于同一列的基本运算单元,通过一个d触发器连接相邻的两个基本运算单元,d触发器分别接至上下两个基本运算单元的数据输入接口(data)。同时,对应于同一列,通过一根数据线将位于上方的基本运算单元的本级结果输出接口(output),连接到相邻下方的基本运算单元的前级结果输出接口(resultin)。
本申请实施例公开了一种基于脉动阵列的矩阵乘法处理器及其数据处理方法,该矩阵乘法处理器包括由多个基本运算单元排布而成脉动阵列、多个权重输入通道以及多个数据输入通道,在所述脉动阵列中,每一列的任意两个相邻基本运算单元之间通过d触发器相连,所述d触发器用于根据时钟信号进行数据的的存储及传递,基本运算单元用于在控制信号的控制下,对接收到的权重数据以及激活数据执行乘法累加运算,所述权重输入通道以及数据输入通道分别用于按照所述时钟信号,将权重数据输入至对应行中的每一个基本运算单元,将激活数据输入至所述脉动阵列中每一列底端基本运算单元的数据输入接口。当权重数据和激活数据在时钟信号的控制下广播至脉动阵列中时,d触发器同时进行数据的存储以及传递,无需额外的控制信号进行控制,有效减少控制信号的数量,降低矩阵乘法处理器的布线复杂度。
进一步的,参见图2,每一个所述基本运算单元内设置有一个乘法器、一个加法器、一个与门、一个非门、一个累加寄存器以及一个多路选择器。
其中,所述乘法器的输入端分别接至所述权重输入接口以及所述数据输入接口,输出端接至所述加法器的输入端。
所述加法器的输入端还接至所述与门的输出端,输出端接至所述累加寄存器的输入端。
所述非门的输入端接至所述控制信号接收接口,输出端接至所述与门的输入端。
所述累加寄存器的输入端还接至所述时钟信号接收接口,输出端分别接至所述与门的输入端以及所述多路选择器的输入端。
所述多路选择器的输入端还接至所述前级结果输入接口以及所述控制信号接收接口,输出端接至所述本级结果输出接口。
其中,乘法器用于在每一个时钟,从数据输入接口(data)接收一个激活数据,以及从权重输入接口(weight)接收一个权重数据,并将接收到的两个数据进行相乘,然后将相乘的结果输出给加法器。
加法器用于将乘法器输出的相乘结果以及与门的输出结果进行累加,并将累加结果输出给累加寄存器。
累加寄存器用于在每一个时钟,从加法器中接收到一个累加结果进行存储,同时将所存储的累加结果作为数据信号分别输出给与门以及多路选择器。其中,累加寄存器的位宽是可以根据乘加结果的位宽进行设定的,本申请实施例中,将其设定为接收32位的数据。
非门用于从控制信号接收接口(control)接收一个提前设置好的控制信号,并将该控制信号进行反向,然后输出给与门。
与门包括两个输入,一个是从非门中获取的经过反向的控制信号,另一个为在每一个时钟从累加寄存器中接收的数据信号。其中,当控制信号为“1”时,与门接收到的信号则为“0”,此时,无论与门从累加寄存器中接收到什么数据信号,与门的输出都为“0”,这种情况下,与门起到清零作用,能够将累加寄存器中的数据清零,以便执行新一次的卷积乘累加操作。当控制信号为“0”时,与门接收到的信号则为“1”,此时,与门将输出从累加寄存器中接收到的数据信号,并把这个数据信号发送给加法器,以执行累加操作,这种情况下,与门起到数据传递作用,能够使一次卷积中的数据能够继续进行累加操作。
本申请实施例中,与门和非门能够将基本运算单元中数据流的控制信号加以合并,使得基本运算单元使用一个控制信号便可执行相乘累加操作,有效减少每个基本运算单元所需要的布线,进而可以减少整个矩阵乘法处理器的布线复杂度。
进一步的,所述多路选择器为二选一多路选择器。
所述多路选择器用于接收控制信号、所述前级结果以及所述累加寄存器的累加结果,并根据所述控制信号,选择所述前级结果或者所述累加结果作为输出结果,发送至所述本级结果输出接口,然后通过本级结果输出接口将输出结果发送至同一列下一行基本运算单元的前级结果输入接口(resultin)。在一种实现方式中,所述控制信号为1或0,其中,若所述控制信号为1,则所述多路选择器选择所述累加结果作为所述当前结果;或者,若所述控制信号为0,则所述多路选择器选择所述前级结果作为所述当前结果。
在一种实现方式中,若基本运算单元位于脉动阵列的第一行,那么接收到的前级结果为0。若基本运算单元位于脉动阵列的最后一行,那么本级结果输出接口的输出将会直接发送给一个缓冲器或者一个存储器。
本申请实施例中,多路选择器能够将一个基本运算单元的运算结果及时的输出,无需在基本运算单元中进行保存,减少了基本运算单元中所需寄存器的数量,因而降低了基本运算单元的结构复杂度。
本申请实施例公开的矩阵乘法处理器中,脉动阵列的行是权重数据的输入方向,其中每一行输入的是一个权重矩阵的权重数据。脉动阵列的列是激活数据的输入方向,其中每一列输入的是一次卷积对应激活矩阵的激活数据。如图1所示,在矩阵乘法处理器工作时,对于不同行,对应不同权重矩阵,即存在n个不同权重矩阵,而在同一行中,同一个权重数据会广播到同一行的所有m个基本运算单元中,且在每一个时钟,一个权重数据都会广播到这一行的所有m个基本运算单元之中。对于不同列,对应不同激活矩阵,即存在m个不同激活矩阵,在每一列中,激活矩阵的第一个激活数据,会在第一个时钟传递给对应列最底端(倒数第一个)的基本运算单元之中;在第二时钟时,激活矩阵的第一个激活数据会沿着d触发器传递到这一列倒数第二个基本运算单元处,而激活矩阵的第二个激活数据则会传递到对应列最底端(倒数第一个)的基本运算单元处;在第三个时钟时,激活矩阵的第一个激活数据会沿着d触发器传递到这一列倒数第三个基本运算单元处,激活矩阵的第二个激活数据会沿着d触发器传递到这一列倒数第二个基本运算单元处,激活矩阵的第三个激活数据会传递到对应列最底端(倒数第一个)的基本运算单元处,依此在每一个时钟不断传递激活数据进行运算。
在矩阵乘法处理器工作期间,对于每一个基本运算单元,在其没有完成一次卷积计算时,其内部的多路选择器会始终选择将前级结果输入接口(resultin)的数据传递到本级结果输出接口(output)。而当每一个基本运算单元完成了一个卷积计算之后,其内部的多路选择器会在其完成卷积运算的那个时钟,选择输出累加寄存器的结果,将完成了卷积计算的运算结果传递到本级结果输出接口(output),同时在下一个时钟到来前,再次选择将前级结果输入接口(resultin)的数据传递到本级结果输出接口(output)。
本申请第二实施例公开了一种基于脉动阵列的矩阵乘法处理器的数据处理方法,所述基于脉动阵列的矩阵乘法处理器的数据处理方法应用于本申请第一实施例所述的基于脉动阵列的矩阵乘法处理器,参见图3,所述基于脉动阵列的矩阵乘法处理器的数据处理方法包括:
步骤s101,获取权重矩阵以及激活矩阵,所述权重矩阵包括多个权重数据,所述激活矩阵包括多个激活数据。
步骤s102,根据时钟信号,将所述多个权重数据与所述多个激活数据按照预设规则依次广播至脉动阵列中,同时根据控制信号,控制每个基本运算单元对接收到的权重数据以及激活数据进行乘法累加运算。
步骤s103,根据控制信号,按行输出所述脉动阵列的运算结果。
进一步的,所述预设规则包括:
在第一个时钟内,按照行序将所述权重矩阵中每行的第一个权重数据输入至所述脉动阵列对应行的所有基本运算单元中,按照列序将所述激活矩阵中每列的第一个激活数据分别输入至所述脉动阵列最后一行的基本运算单元中。
在第x个时钟内,按照行序将所述权重矩阵中每行的第x个权重数据输入至所述脉动阵列对应行的所有基本运算单元中,通过d触发器将每行基本运算单元中原有的激活数据按照列序传递至前一行基本运算单元中,然后按照列序将所述激活矩阵中每列的第x个激活数据分别输入至所述脉动阵列最后一行的基本运算单元中,其中,x为大于1的自然数。
进一步的,所述根据控制信号,按行输出所述脉动阵列的运算结果,包括:
若某一行所有基本运算单元的控制信号皆为1,则输出该行所有基本运算单元的当前结果。
以下结合具体示例,对本申请实施例公开的基于脉动阵列的矩阵乘法处理器的数据处理方法进行说明。
首先,设定脉动阵列的维度为3*3,共有9个基本运算单元,同时设定在卷积运算中只用1*1*3的卷积核,即对于一个基本运算单元,工作三个时钟便得到一个卷积运算的结果,每一个卷积运算的结果由3个权重数据及3个激活数据相乘累加获得。
其次,将脉动阵列中所有的基本运算单元中的多路选择器,均设定为选择前级结果输入接口(resultin)中的信号输出,即将控制信号设置为“0”,这种情况下,不会有结果输出。
参见图4中的第(1)幅图,在输入到矩阵乘法处理器的脉动阵列之前,先对权重矩阵以及激活矩阵进行预处理,将矩阵数据向量化以及对输入数据进行补零。
参见图4中的第(2)幅图,在第一个时钟周期内,对于行,只有脉动阵列的最下面一行得到了有效的权重数据a_1,另外两行得到的是0,对于列,三个激活数据a_1、b_1以及c_1分别输入至最后一行对应列的基本运算单元中,在完成运算之后,运算结果分别存储在最下面一行的累加寄存器中,同时整个脉动阵列中所有的基本运算单元中的多路选择器,均选择基本运算单元中的前级结果输入接口(resultin)中的信号输出,即将控制信号设为“0”,这种情况下,不会有结果输出。
参见图4中的第(3)幅图,在第二个时钟周期,对于行,脉动阵列的第二行得到了有效权重数据b_1,第三行得到了有效数据a_2,对于列,三个激活数据a_1、b_1以及c_1分别通过d触发器传递至第二行中对应列的基本运算单元中,三个激活数据a_2、b_2以及c_2分别输入至最后一行对应列的基本运算单元,在基本运算单元中进行计算之后分别存入各自的累加寄存器中,同时脉动阵列中所有的基本运算单元中的多路选择器,均选择基本运算单元中的前级结果输入接口(resultin)中的信号输出,即将控制信号设为“0”,这种情况下,不会有结果输出。
参见图4中的第(4)幅图,在第三个时钟周期,对于行,第一行得到了有效权重数据c_1,第二行得到了有效权重数据b_2,第三行得到了有效权重数据a_3,对于列,三个激活数据a_1、b_1以及c_1分别通过d触发器传递至第一行中对应列的基本运算单元中,三个激活数据a_2、b_2以及c_2分别通过d触发器传递至第二行中对应列的基本运算单元中,三个激活数据a_3、b_3以及c_3输入至最后一行对应列的基本运算单元,此时,在完成相应的计算之后,脉动阵列第三行已经完成了卷积运算,将第三行的三个基本运算单元的控制信号设置为“1”,使得累加寄存器中的结果从脉动阵列中输出,而第一及第二行基本运算单元的控制信号依旧置为“0”,以继续执行相乘累加操作。
参见图4中的第(5)幅图,在第四个时钟周期,对于行,第一行得到了有效权重数据c_2,第二行得到了有效权重数据b_3,第三行已经没有数据,对于列,不存在数据可以输入至最后一行对应列中的基本运算单元中,三个激活数据a_2、b_2以及c_2分别通过d触发器传递至第一行中对应列的基本运算单元中,三个激活数据a_3、b_3以及c_3分别通过d触发器传递至第二行中对应列的基本运算单元中,在完成相应的计算之后,脉动阵列第二行已经完成了卷积运算,此时第二行的三个基本运算单元的控制信号会置为“1”,将累加寄存器中的结果从脉动阵列中输出,而第一及第三行的控制信号置为“0”,以继续执行相乘累加操作。
参见图4中的第(6)幅图,在第五个时钟周期,对于行,第一行得到了有效权重数据c_3,第二行和第三行已经没有数据。对于列,不存在数据可以输入至最后一行对应列中的基本运算单元中,三个激活数据a_3、b_3以及c_3分别通过d触发器传递至第一行中对应列的基本运算单元中,此时,在完成相应的计算之后,阵列第一行已经完成了卷积运算,第一行的三个基本运算单元的控制信号会置为“1”,将累加寄存器中的结果从脉动阵列中输出,而第二及第三行的控制信号置为“0”。至此,完成了全部的运算,得到9个有效的输出结果。
需要说明的是,在实际运算中,脉动阵列的维度是可以调整的,不仅仅局限于本申请上述实施例中公开的3*3,在此基础上,权重数据和激活数据也不仅局限于3个,本领域技术人员完全可以基于上述公开的实施例,使用任意维度的脉动阵列进行大型的矩阵乘法运算,以实现复杂度更高的卷积运算。
以上结合具体实施方式和范例性实例对本申请进行了详细说明,不过这些说明并不能理解为对本申请的限制。本领域技术人员理解,在不偏离本申请精神和范围的情况下,可以对本申请技术方案及其实施方式进行多种等价替换、修饰或改进,这些均落入本申请的范围内。本申请的保护范围以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!