一种数据处理方法及相关产品与流程
本申请要求2019年4月18日提交,申请号为201910315962.9,发明名称为“一种数据处理方法及相关产品”的优先权。本申请涉及人工智能处理器
技术领域:
,尤其涉及一种数据处理方法及相关产品。
背景技术:
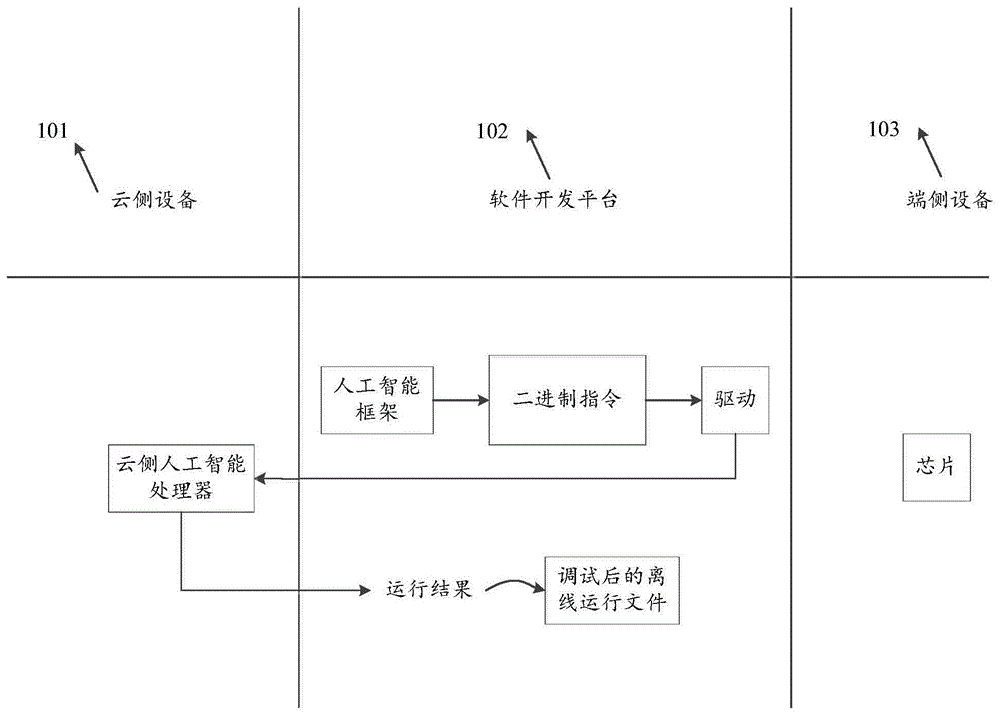
:现有技术中,当人工智能处理器成功流片后,算法应用开发者才能在对应版本的人工智能处理器(硬件实体)上进行开发和测试。从上述描述可以知道,现有技术中,只有在人工智能处理器流片之后,才能得知开发的人工智能算法在对应版本的人工智能处理器上运行的功能结果和性能结果。在实际应用场景下,人工智能处理器通常需要与其他处理器,比如cpu、gpu、dsp等抢占片外存储器的访存带宽;同时,如果人工智能处理器内部多个处理器核之间执行协同任务时相互之间也存在对于片外存储器带宽的抢占。在执行协同任务时,其中一个重要的参数为神经网络中的算子在某种拆分状态下在多核人工智能处理器上并行执行所用时间的估值取决于人工智能处理器的一个处理核可占用的片外存储器的访存带宽。这意味着,当实际带宽发生变化时,多核拆分的策略也将随之改变。那么,如何实现端侧人工智能处理器未流片时算法应用开发者即可展开不同的应用场景下人工智能算法模型与人工智能处理器之间的多核拆分方式的调试工作,是急需解决的问题。技术实现要素:本申请实施例提供一种数据处理方法及相关产品,不管人工智能处理器是否流片,本技术方案都能够提前实现不同的应用场景下人工智能算法模型与人工智能处理器之间的多核拆分方式的调试工作。为实现上述目的,本申请提出一种数据处理方法,所述数据处理方法包括:读取离线运行文件集合;其中,所述离线运行文件集合是根据运行结果满足预设要求时对应的所述端侧人工智能处理器的硬件架构信息、访存带宽和二进制指令确定的离线运行文件构成的。对所述离线运行文件集合进行解析,获得离线运行文件映射表;其中,所述离线运行文件映射表是同一端侧人工智能处理器的硬件架构信息所对应的访存带宽与所述离线运行文件之间的对应关系。根据端侧人工智能处理器工作负荷情况,确定当前访存带宽;基于当前访存带宽从所述离线运行文件映射表中确定需执行的当前离线运行文件。执行当前离线运行文件。优选地,所述离线运行文件映射表的获得步骤包括:所述通用处理器获取端侧人工智能处理器的硬件架构信息以及对应的可配置的访存带宽,根据所述端侧人工智能处理器的硬件架构信息以及对应的访存带宽生成对应的二进制指令;其中,访存带宽为端侧人工智能处理器到片外存储器的访存宽度;所述通用处理器根据所述二进制指令生成对应的人工智能学习任务,将所述人工智能学习任务发送至云侧人工智能处理器上运行;所述云侧人工智能处理器接收人工智能学习任务,执行所述人工智能学习任务,生成运行结果;所述通用处理器接收所述人工智能学习任务对应的运行结果,根据所述运行结果确定所述访存带宽对应的离线运行文件;其中,所述离线运行文件是根据运行结果满足预设要求时的所述端侧人工智能处理器的硬件架构信息以及对应的访存带宽和二进制指令生成的;所述通用处理器根据同一端侧人工智能处理器的不同的访存带宽对应的离线运行文件确定离线运行文件映射表;其中,所述离线运行文件映射表是同一端侧人工智能处理器的硬件架构信息所对应的访存带宽与所述离线运行文件之间的对应关系。为实现上述目的,本申请提出一种数据处理装置,所述装置包括:存储器、通用处理器以及云侧人工智能处理器;所述存储器上存储有可在所述通用处理器和/或所述云侧人工智能处理器上运行上述所述方法的计算机程序。本技术方案的技术效果为:本技术方案提供一软件开发平台,客户可以在该软件开发平台上完成多核拆分方案与人工智能处理器之间的功能、性能、精度调试,调试完成后生成的离线运行文件映射表中不同访存带宽下离线运行文件集合可以在使用兼容架构上的多种soc芯片上部署,带来的好处是客户无需拿到硬件实体就可提前对多核拆分方案与人工智能处理器之间功能、性能、精度调试,大大缩短了产品开发周期。并且,无需为每个soc芯片单独开发或者适配一套开发环境。附图说明为了更清楚地说明本公开实施例的技术方案,下面将对实施例的附图作简单地介绍,显而易见地,下面描述中的附图仅仅涉及本公开的一些实施例,而非对本公开的限制。图1是本技术方案的架构示意图;图2是人工智能处理器的软件栈结构示意图;图3是本技术方案的应用场景示意图之一;图4是本技术方案的应用场景示意图之二;图5是本申请提出的一种数据处理方法流程图之一;图6是人工智能学习库支持的多种类型的基本算子的示意图;图7是本申请提出的一种数据处理方法流程图之二;图8是本申请提出的一种数据处理方法流程图之三;图9是本申请提出的一种数据处理方法流程图之四;图10是本申请提出的一种数据处理装置功能框图;图11是本申请提出的根据所述端侧人工智能处理器的硬件架构信息以及对应的访存带宽生成对应的二进制指令的流程图;图12是本申请提出的本申请实施例提供的一种卷积算子的原始计算图的示意图。图13a是按照输入数据的n维度进行拆分得到的示意图;图13b是按照输出数据的c维度进行拆分的示意图;图13c是按照输入数据c维度进行拆分得到的示意图;图13d是按照输入数据的h维度进行拆分得到的示意图;图13e是按照输入数据的w维度进行拆分得到的示意图;图13f是本申请实施例提供的一种人脸识别神经网络模型的结构示意图;图13g是本申请实施例提供的一种车牌字符识别的神经网络模型的结构示意图;图13h是本申请实施例提供的一种神经网络模型的抽象示意图;图14a是本申请实施例提供的一种串行神经网络模型的抽象示意图;图14b是本申请实施例提供的一种通过胶水算子调整张量数据的拆分方式的示意图;图14c是本申请实施例提供的一种concat算子语义的示意图;图14d是本申请实施例提供的一种split算子语义的示意图;图14e是本申请实施例提供的一种插入胶水算子后的神经网络模型的抽象示意图;图14f是本申请实施例提供的另一种插入胶水算子后的神经网络模型的抽象示意图。具体实施方式下面将结合附图,对本公开实施例中的技术方案进行清楚、完整地描述参考在附图中示出并在以下描述中详述的非限制性示例实施例,更加全面地说明本公开的示例实施例和它们的多种特征及有利细节。应注意的是,图中示出的特征不是必须按照比例绘制。本公开省略了已知材料、组件和工艺技术的描述,从而不使本公开的示例实施例模糊。所给出的示例仅旨在有利于理解本公开示例实施例的实施,以及进一步使本领域技术人员能够实施示例实施例。因而,这些示例不应被理解为对本公开的实施例的范围的限制。除非另外特别定义,本公开使用的技术术语或者科学术语应当为本公开所属领域内具有一般技能的人士所理解的通常意义。本公开中使用的“第一”、“第二”以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的组成部分。此外,在本公开各个实施例中,相同或类似的参考标号表示相同或类似的构件。为了便于更好的理解本技术方案,下面先解释本申请实施例所涉及的技术术语:流片:在集成电路设计领域,流片是指试生产,也即在设计完满足预设功能的集成电路之后,先生产几片或几十片供测试用,如果满足测试需求,则按照当前满足测试需求的集成电路的结构进行大规模生产。人工智能处理器的软件栈:参见图2,该软件栈结构20包括人工智能应用200、人工智能框架202、人工智能学习库204、人工智能运行时库206以及驱动208。接下来对其进行具体阐述:人工智能应用200对应不同的应用场景,提供对应的人工智能算法模型。该算法模型可以直接被人工智能框架202的编程接口解析,在其中一个可能的实现方式中,通过人工智能学习库204将人工智能算法模型转换为二进制指令,调用人工智能运行时库206将二进制指令转换为人工智能学习任务,将该人工智能学习任务放在任务队列中,由驱动208调度任务队列中的人工智能学习任务让底层的人工智能处理器执行。在其中另一个可能的实现方式中,也可以直接调用人工智能运行时库206,运行先前已固化生成的离线运行文件,减少软件架构的中间开销,提高运行效率。二进制指令:是底层的人工智能处理器可以识别的信息。人工智能处理器:也称之为专用处理器,针对特定应用或者领域的处理器。例如:图形处理器(graphicsprocessingunit,缩写:gpu),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上进行图像运算工作的专用处理器。又例如:神经网络处理器(neuralprocessingunit,缩写:npu),是一种在人工智能领域的应用中针对矩阵乘法运算的专用处理器,采用“数据驱动并行计算”的架构,特别擅长处理视频、图像类的海量多媒体数据。可重构体系结构:如果某一人工智能处理器能够利用可重用的硬件资源,根据不同的应用需求,灵活的改变自身的体系结构,以便为每个特定的应用需求提供与之相匹配的体系结构,那么这一人工智能处理器就称为可重构的计算系统,其体系结构称为可重构的体系结构。专用编程语言:基于特定的硬件开发的高级编程语言。例如:cudac。下面结合附图,对本公开实施例提供的一种数据处理方法及相关产品的具体实施方式进行详细说明。现有技术中,算法应用开发者只有在对应版本硬件实体上完成人工智能算法模型与人工智能处理器之间的适配调试工作。可以理解的是,现有技术的实现方案并不能实现未流片的芯片与算法之间的调试过程,这样就需要专门的时间去完成算法模型与芯片之间的适配工作,因而产品问市的期限就要往后拖延,很容易因时间问题错过占领市场的机会。基于此,本申请提出一种技术方案,不管是否流片,根据端侧人工智能处理器的设备信息从云侧中匹配出合适的人工智能处理器来模拟端侧人工智能处理器,本技术方案中的软件开发平台对客户提供的算法模型经过一系列处理,得到对应的人工智能学习任务,该人工智能学习任务在云侧人工智能处理器上运行,得到运行结果。根据运行结果在软件开发平台上对人工智能学习任务进行调整,对于本技术方案来说,不管是否调整人工智能算法模型,通过优化人工智能学习库和/或调整端侧人工智能处理器的设备信息,均可以达到调整人工智能学习任务的目的,实现端侧人工智能处理器与人工智能算法模型之间的适配。在此基础上,获得同一端侧人工智能处理器的不同的访存带宽对应的离线运行文件构成的数据块以及离线运行文件映射表,对于每个独立的任务,在运行时用户根据实时的端侧人工智能处理器工作负荷和状态选择编译时配置的访存带宽,软件开发平台的人工智能运行时库根据配置的访存带宽从离线运行文件映射表中确定对应的离线运行文件,并对确定的离线运行文件进行解析,获得端侧人工智能处理器需执行的二进制指令。参见图1所示,是本技术方案的系统架构图,如图1所示,该系统架构包括:云侧设备101、软件开发平台102、端侧设备103。具体实现中,软件开发平台102提供了一系列工具包,该工具包用于应用开发、性能调优、功能调试等。其中,应用开发工具包括人工智能学习库、人工智能运行时库、编译器和特定领域(如视频分析)的软件开发工具。功能调试工具可以满足编程框架、人工智能学习库等不同层次的调试需求;性能调优工具包括性能剖析工具和系统监控工具等。编译器可以包括c++语言的传统编译器,还可以包括基于类c语言的机器学习编译器,也可以基于其他高级语言或者专门设计的领域专用编程语言(domainspecificlanguage)的机器学习编译器。可选地,该软件开发平台可以在云侧设备101的处理器上运行,也可以运行在本地(host)的计算机设备的处理器上,该本地的计算机设备可以包括通用处理器(如cpu)和显示器等,此处不做具体限定。进一步可选地,上述软件开发平台可以以客户端的形式运行在本地的计算机设备上,或者云端设备上,本申请实施例不作具体限定。如图3所示,该图示意性给出本技术方案的应用场景之一。用户在一台式电脑上登录软件开发平台,在软件开发平台上生成算法模型对应的人工智能学习任务,根据人工智能学习任务在云侧人工智能处理器上运行结果对人工智能学习任务进行调整。如图4所示,该图示意性给出本技术方案的应用场景之二。在云端设备101上设置有人工智能软件开发客户端。具体地,云侧设备是完整的计算机系统,可以包括通用处理器和至少一个人工智能处理器。例如:人工智能处理器可以包括8个集群(cluster),每个cluster中包括4个人工智能处理器核。在实际中,软件开发平台102维护一份用户记录,该用户记录通过数据块等工具保存,记录内容包括用户个人信息(账户信息等)、用户所需要的服务信息。其中,服务信息包括但不限于调试需求,端侧人工智能处理器的设备信息。该调试需求包括但不限于功能调试和性能调试。设备信息包括硬件架构信息和运行环境参数。运行环境参数包括但不限于端侧人工智能处理器的运行主频率、片外存储器到端侧人工智能处理器之间的访存带宽、片上存储大小、端侧人工智能处理器的核数、端侧人工智能处理器的运算器类型。具体实现中,云侧设备101上设置有人工智能处理器,该人工智能处理器称为云侧人工智能处理器。云侧人工智能处理器包括但不限于人工智能处理器芯片、现场可编程门阵列、模拟器。其中,人工智能处理器芯片可以是可重构型芯片,也可以是非重构型芯片。云侧设备101是服务器板卡或服务器板卡集群。具体实现中,端侧设备103上设置有人工智能处理器,该人工智能处理器称为端侧人工智能处理器。端侧设备可以是终端设备,比如:平板电脑、移动电话。端侧设备也可以是边缘端设备,比如:摄像头。需要说明的是,在本申请实施例中,端侧设备103可以是未流片状态的设备,也可以是已流片的设备。本技术方案的工作原理为:在软件开发平台102上,驱动程序根据端侧人工智能处理器的设备信息从云侧设备101中筛选与端侧设备103相适配的人工智能处理器。筛选出的云侧人工智能处理器的硬件架构信息兼容对应的端侧人工智能处理器的硬件架构信息,且云侧人工智能处理器的指令集兼容对应的端侧人工智能处理器的指令集。这里,云侧人工智能处理器的硬件架构信息兼容对应的端侧人工智能处理器的硬件架构信息可以包括:云侧人工智能处理器的计算能力大于或等于端侧人工智能处理器的计算能力。在软件开发平台102上,根据端侧人工智能处理器的设备信息设置人工智能学习库的编译接口对应的软件参数,结合编程框架获得的算法模型,调用已设置好的人工智能学习库的编译接口来编译,获得对应的端侧人工智能处理器的二进制指令。该二进制指令经运行时库处理生成人工智能学习任务。将人工智能学习任务放入任务队列,最终由驱动器调度任务队列中的人工智能学习任务让云侧人工智能处理器执行。根据云侧人工智能处理器执行的人工智能学习任务,反馈运行结果至软件开发平台102上。可选地,软件开发平台102可以显示运行结果。根据运行结果,软件开发平台102接收用户的操作指令,软件开发平台102根据操作指令执行三种方式中的至少其中一种方式来调整二进制指令。这三种方式分为:调整所述端侧人工智能处理器的硬件架构信息、调整所述端侧人工智能处理器的运行环境参数、优化人工智能学习任务。将调整后的二进制指令转换为对应的人工智能学习任务,放入任务队列中,由驱动器调度任务队列中的人工智能学习任务让云侧人工智能处理器执行。直至云侧人工智能处理器反馈的运行结果符合预期。进一步地,软件开发平台102支持一种功能,针对同一端侧人工智能处理器,根据实际情况,设置不同的访存带宽,根据多核拆分策略获得对应的离线运行文件。根据同一端侧人工智能处理器的不同的运行环境参数对应的离线运行文件确定离线运行文件映射表;其中,所述离线运行文件映射表是同一端侧人工智能处理器的硬件架构信息所对应的运行环境参数与所述离线运行文件之间的对应关系。对于每个独立的任务,在运行时用户根据实时的硬件工作负荷和状态选择编译时配置的访存带宽,软件开发平台的人工智能运行时库根据配置的访存带宽从离线运行文件映射表中确定对应的离线运行文件,并对确定的离线运行文件进行解析,获得端侧人工智能处理器需执行的二进制指令。在本技术方案中,端侧人工智能处理器的设备信息与人工智能学习库的编译接口的软件参数相对应,该软件参数包含更多信息,比如:ramsize、cache大小、是否通过cache缓存等。这些信息关系到生成二进制指令时分配的操作域,因此,在人工智能算法模型不改变的情况下,更改端侧人工智能处理器的设备信息,就可以调整二进制指令,从而调整人工智能学习任务。不管端侧人工智能处理器是否流片,根据端侧人工智能处理器的设备信息从云侧设备101中适配出的云测人工智能处理器可以模拟端侧人工智能处理器,在云侧人工智能处理器上执行对应的人工智能学习任务。根据运行结果,在该软件开发平台上完成算法模型与人工智能处理器之间的功能、性能、精度调试,调试完成后生成的离线运行文件可以在使用兼容架构上的多种端侧的soc芯片上部署,带来的好处是客户无需拿到硬件实体就可提前对算法模型与人工智能处理器之间功能、性能、精度调试,大大缩短了产品开发周期。并且,无需为每个端侧的soc芯片单独开发或者适配一套开发环境。更进一步地,本技术方案中,云侧人工智能处理器的设备信息对应的当前运行环境参数可以与其实际运行环境参数相同,也可以与其实际运行参数不同。根据云侧人工智能处理器对特定人工智能学习任务的执行结果,确定端侧人工智能处理器的设备信息是否符合预期条件。当端侧人工智能处理器的设备信息不符合预期条件时,可以进一步调整端侧人工智能处理器的设备信息,直至该端侧人工智能处理器的设备信息符合预期条件。因此,对于本技术方案来说,端侧人工智能处理器的架构在设计阶段时,还可以基于应用来评定端侧的soc芯片设计规格。基于上述描述,如图5所示,为本申请提出的一种数据处理方法流程图之一。所述方法应用于通用处理器,对应图1中的软件开发平台。正如前文所述,该通用处理器可以是云侧设备101的通用处理器,也可以是本地(host)的计算机设备的通用处理器。包括:步骤501):所述通用处理器获取端侧人工智能处理器的硬件架构信息以及对应的可配置的访存带宽,根据所述端侧人工智能处理器的硬件架构信息以及对应的访存带宽生成对应的二进制指令;其中,访存带宽为端侧人工智能处理器到片外存储器的访存宽度。在本技术方案中,软件开发平台102中集成了多种编程框架,例如,谷歌张量流图人工智能学习系统tensorflow、深度学习框架caffe、caffe2、mxnet等等。以caffe为例,caffe的核心模块有三个,分别是blobs、layers和nets。其中,blobs用来进行数据存储、数据交互和处理,通过blobs,统一制定了数据内存的接口。layers是神经网络的核心,定义了许多层级结构,它将blobs视为输入输出。nets是一系列layers的集合,并且这些层结构通过连接形成一个网图。对于本步骤来说,根据端侧人工智能处理器的硬件架构信息设置人工智能学习库的编译接口对应的软件参数,结合编程框架获得的算法模型,调用已设置好的人工智能学习库的编译接口来编译,获得对应的端侧人工智能处理器的二进制指令。该二进制指令经运行时库处理生成人工智能学习任务。将人工智能学习任务放入任务队列,最终由驱动器调度任务队列中的人工智能学习任务让云侧人工智能处理器执行。在实际应用中,人工智能学习库用于在人工智能处理器上加速各种人工智能学习算法。这里,人工智能学习算法包括但不限于深度学习算法,例如,卷积神经网络算法、循环神经网络算法等。具体地,人工智能学习库主要包括以下几个特性:(1)支持多种类型的基本算子具体实现中,通过基本算子的组合,可以实现多样的机器学习算法,从而满足通用性、灵活性、可扩展性需求。具体地,这里所涉及的多种类型的基本算子可以包括:常见的神经网络算子1、矩阵、向量、标量算子2、循环神经网络算子3。参见图6,是本申请实施例提供的一种人工智能学习库支持的多种类型的基本算子的示意图,如图6所示,人工智能学习库支持的多种类型的基本算子包括常见的神经网络算子1,该神经网络算子1包括卷积/反卷积算子11,池化算子12,激活算子13、局部响应归一化lrn(lrn,localresponsenormalization)/批规范化算子14,分类器(softmax)算子15,全连接算子16。其中,激活算子13可以包括但不限于relu、sigmoid、tanh以及其他可以用插值方式实现的算子。矩阵、向量、标量算子2包括矩阵乘算子21、张量加、减算子22、张量逻辑运算算子23、张量(tensor)变换算子24、roipooling算子25、proposal算子26。其中,tensor变换算子24可以包括但不限于crop、张量重塑reshape、张量拆分slice、张量拼接concat等;循环神经网络算子3包括长短期记忆网络lstm(lstm,longshort-termmemory)算子31、基本循环神经网络rnn(recurrentneuralnetwork,rnn)、循环神经网络rnn算子32、svdf算子33。在实际应用中,用户还可以根据自身需求自由在人工智能学习库中添加新算子或更改不同版本的人工智能学习库,这里不再详述,会在调试人工智能学习任务时详细描述在软件开发平台上如何基于人工智能学习库优化人工智能学习任务。(2)支持对基本算子进行融合具体实现中,融合后的算子在编译期间会采用内存复用、访存优化、指令流水、数据类型优化(例如,针对可以适用的不同的数据类型进行选择)等编译优化手段,从而显著提升融合算子的整体性能。(3)支持生成离线运行文件这里,生成离线运行文件可以包含人工智能算法模型中各个计算节点的网络权值以及指令等必要的网络结构信息,指令可以用于表明该计算节点用于执行何种计算功能,其具体可以包括人工智能学习模型中各个计算节点的计算属性以及各个计算节点之间的连接关系等信息。具体实现中,离线运行文件可以脱离人工智能学习库,基于人工智能运行时库单独运行。在实际应用中,由于离线运行文件脱离了上层软件栈,使得离线运行文件的执行具有更好的性能和通用性。步骤502):所述通用处理器根据所述二进制指令生成对应的人工智能学习任务,将所述人工智能学习任务发送至云侧人工智能处理器上运行。对于本技术方案来说,根据端侧人工智能处理器的硬件架构信息从云侧设备101中适配出的云测人工智能处理器可以模拟端侧人工智能处理器。那么,在软件开发平台102上生成的人工智能学习任务发送至云侧人工智能处理器上运行。步骤503):所述通用处理器接收所述人工智能学习任务对应的运行结果,根据所述运行结果确定所述访存带宽对应的离线运行文件;其中,所述离线运行文件是根据运行结果满足预设要求时的所述端侧人工智能处理器的硬件架构信息以及对应的访存带宽和二进制指令生成的。云侧人工智能处理器在执行人工智能学习任务时,生成运行结果,该运行结果反馈至软件开发平台102上显示。对于本技术方案来说,运行结果可以包括但不限于以下一种或多种信息:所述人工智能学习任务在云侧人工智能处理器上的运行时间是否符合预期要求、执行所述人工智能学习任务时占用云侧人工智能处理系统的负载信息是否符合预期要求、执行人工智能学习任务的结果是否符合预期要求。在本技术方案中,云侧人工智能处理系统包括通用处理器和云侧人工智能处理器。在执行所述人工智能学习任务时,不仅需要获知执行所述人工智能学习任务时占用云侧人工智能处理器的负载信息,还要获知执行过程中占用内存信息以及通用处理器占用率等。运行结果中包含负载信息的原因在于:如果一个人工智能学习任务在通用处理器上所需的资源过多,很有可能在端侧设备上运行时会效果很差或者运行不起来。步骤504):所述通用处理器根据同一端侧人工智能处理器的不同的访存带宽对应的离线运行文件确定离线运行文件映射表;其中,所述离线运行文件映射表是同一端侧人工智能处理器的硬件架构信息所对应的访存带宽与所述离线运行文件之间的对应关系。应该清楚地,离线运行文件包括:离线运行文件版本信息、人工智能处理器版本信息、二进制指令、常数表、输入/输出数据规模、数据布局描述信息和参数信息。具体来说,离线运行文件的版本信息是表征离线运行文件的不同版本;人工智能处理器版本信息是指端侧人工智能处理器的硬件架构信息。比如:可以通过芯片架构版本号来表示硬件架构信息,也可以通过功能描述来表示架构信息。数据布局描述信息是指基于硬件特性对输入/输出数据布局及类型等进行预处理;常数表、输入/输出数据规模和参数信息基于开发好的人工智能算法模型确定。其中,参数信息可以为人工智能算法模型中的权值数据。在常数表中,存储有执行二进制指令运算过程中需要使用的数据。端侧人工智能处理器的硬件架构信息包括所述端侧人工智能处理器的运行主频率、片上存储大小,端侧人工智能处理器的核数以及端侧人工智能处理器的运算器类型中的至少其中之一。对于本技术方案来说,所述通用处理器根据同一端侧人工智能处理器的不同的访存带宽对应的离线运行文件确定离线运行文件映射表,包括:将同一端侧人工智能处理器的不同的访存带宽对应的离线运行文件进行拼接,获得第一数据块;对所述第一数据块进行优化处理,获得离线运行文件映射表。实际中,离线运行文件映射表中每个离线运行文件是软件开发平台上设置的不同的参数对应其中,所述优化处理的步骤包括:根据不同离线运行文件中对应权值和二进制指令的使用行为,对离线运行文件中权值和二进制指令进行复用操作处理。在本技术方案中,若所述运行结果满足预设要求,则根据满足所述预设要求的二进制指令生成对应的离线运行文件。若所述运行结果不满足预设要求,通过功能调试工具和/或性能调优工具执行如下过程中的至少一种优化方式,直至运行结果满足所述预设要求,并根据满足所述预设要求的二进制指令生成对应的离线运行文件;其中,所述优化方式包括:调整所述端侧人工智能处理器的硬件架构信息;优化人工智能学习任务。具体来说,云侧人工智能处理器反馈的运行结果若符合预设要求,当前执行人工智能学习任务对应的二进制指令通过离线方式固化成离线运行文件。云侧人工智能处理器反馈的运行结果若不符合预设要求,调试人工智能学习任务分为两种应用场景。第一种应用场景为:在芯片设计阶段,基于应用,利用本技术方案来评定芯片设计规格。这种情况下,芯片的硬件架构信息可以更改。那么,在软件开发平台上,执行包括:调整所述端侧人工智能处理器的硬件架构信息;优化人工智能学习任务这两种优化方式中的至少一种优化方式,均可相应调整人工智能学习任务对应的二进制指令。每一次调整后,由驱动调度任务队列中调整后的人工智能学习任务,让对应的云侧人工智能处理器执行,获得新的运行结果。如果新的运行结果还是不符合预期,用户可以重复上述步骤,直至运行结果符合预期。最终调试获得的二进制指令通过离线方式固化成离线运行文件。第二种应用场景为:不管端侧人工智能处理器是否流片,客户基于软件开发平台就可以展开设计开发,实现端侧人工智能处理器与人工智能算法模型之间的适配。这种情况下,在实际中,除非重新购买其他架构版本的芯片使用权,否则,芯片的硬件架构信息不会轻易发生变化。假设芯片的硬件架构信息不发生变化,那么,在软件开发平台上,执行包括:在当前硬件架构信息对应的芯片所支持的运行环境参数范围内调整运行环境参数、优化人工智能学习任务这两种优化方式中的至少一种优化方式,均可相应调整人工智能学习任务对应的二进制指令。每一次调整后,由驱动调度任务队列中调整后的人工智能学习任务,让对应的云侧人工智能处理器执行,获得新的运行结果。如果新的运行结果还是不符合预期,用户可以重复上述步骤,直至运行结果符合预期。最终调试获得的二进制指令通过离线方式固化成离线运行文件。关键地,为了能够实现离线运行文件既可以运行在云侧人工智能处理器上,也可以运行在端侧人工智能处理器上,且人工智能学习任务在云侧人工智能处理器上执行时生成的运行结果与在端侧人工智能处理器上执行时生成的运行结果完全一致或在一定的允许误差范围之内,在本技术方案中,根据端侧人工智能处理器的设备信息从云侧人工智能处理器集合中筛选出能够模拟对应端侧人工智能处理器的云侧人工智能处理器,筛选出的云侧人工智能处理器的硬件架构信息兼容对应端侧人工智能处理器的硬件架构信息,云侧人工智能处理器的指令集兼容对应端侧人工智能处理器的指令集,从而可以实现离线运行文件的无缝迁移。在本技术方案中,可以在软件开发平台102上预先存储不同类型的端侧人工智能处理器的硬件架构信息。根据实际需要,从预选存储的硬件架构信息中选取目标信息,依据目标信息从云侧设备101中确定模拟端侧人工智能处理器的云侧人工智能处理器。对于本技术方案来说,另一种可行的方案是,根据实际需要,每一次调整需设置的信息时,用户在软件开发平台102设置不同的硬件架构信息,软件开发平台102接收端侧人工智能处理器的硬件架构信息,依据当前接收到的端侧人工智能处理器的硬件架构信息,从云侧设备101中选出云侧人工智能处理器来模拟端侧人工智能处理器的人工智能处理器。需要说明的是,上述获取端侧人工智能处理器的硬件架构信息的方式仅仅是例举的部分情况,而不是穷举,本领域技术人员在理解本申请技术方案的精髓的情况下,可能会在本申请技术方案的基础上产生其它的变形或者变换,比如:端侧设备103发送请求信息至软件开发平台102,软件开发平台102对请求信息进行解析,获得端侧人工智能处理器的硬件架构信息。但只要其实现的功能以及达到的技术效果与本申请类似,那么均应当属于本申请的保护范围。在实际应用中,从云侧设备101中选出云侧人工智能处理器来模拟端侧人工智能处理器时,将当前启用的端侧设备信息写入驱动程序中,以根据驱动程序中的设备信息适配云侧人工智能处理器。其中,适配云侧人工智能处理器的过程包括:根据端侧人工智能处理器的硬件架构信息筛选出云侧人工智能处理器;其中,筛选出的云侧人工智能处理器的硬件架构信息兼容对应端侧人工智能处理器的硬件架构信息,云侧人工智能处理器的指令集兼容对应端侧人工智能处理器的指令集;根据端侧人工智能处理器的运行环境参数对筛选出的云侧人工智能处理器进行调频调带。另外,针对优化人工智能学习任务来说,可以有四种方式。第一种方式:用户可以在软件开发平台上基于编程语言实现文件编译成动态链接库,在框架中调用该动态链接库。第二种方式:用户可以在软件开发平台上基于编程语言开发新的算子,结合本地已拥有的人工智能学习库,以得到新的离线运行文件。比如:以proposal算子为例。我们将faster-r-cnn中proposal算子,替换为pluginop算子,调用专用编程语言编写的proposal_kernel.mlu算子,cambricon-caffe框架中的proposal算子就通过pluginop替换成了专用编程语言实现的proposalkernel,从而将专用编程语言与现有的人工智能学习库联系到一起,支持了人工智能学习库中的各种特性及在线、离线、逐层、融合等运行模式。由第一种方式和第二种方式可知,在框架中已经支持了大量层和算子,一般的模型都可以全部放到云的服务器板卡上运行。但算法更新变化快,个人或组织可能也积累了一些自定义的算子、算法,一来不希望暴露自定义的算法,二来通过底层库直接对实际应用进行支持效率不能满足需求,所以提供了专用编程语言来帮助开发者进行自主的算法开发,满足之前的开发模式中不够灵活的痛点。第三种方式:用户可以在软件开发平台上从当前本地已拥有人工智能学习库的版本中选择其中之一,并匹配对应的人工智能运行时库,如果当前本地已拥有的人工智能学习库无法满足需求,通过软件开发平台发送请求,以达到升级本地人工智能学习库的版本的目的。软件开发平台运营方根据请求给软件开发平台提供相应的新版本的人工智能学习库以及对应的人工智能运行时库,用户在软件开发平台上选用最新版本的人工智能学习库以及对应的人工智能运行时库,基于最新版本的人工智能学习库获得调试后的二进制指令。第四种方式:用户可以调整人工智能算法模型来达到优化人工智能学习任务的目的。在实际应用中,上述四种优化人工智能学习任务的方式中采用至少其中一种方式均达到优化人工智能学习任务的目的。不管是否调整人工智能算法模型,通过优化人工智能学习库和/或调整端侧人工智能处理器的设备信息,均可以达到调整人工智能学习任务的目的,实现端侧人工智能处理器与人工智能算法模型之间的适配。图5所示的方案提供一软件开发平台,客户可以在该软件开发平台上完成算法与人工智能处理器之间的功能、性能、精度调试,调试完成后生成的离线运行文件可以在使用兼容架构上的多种端侧的soc芯片上部署,带来的好处是客户无需拿到硬件实体就可提前对算法与人工智能处理器之间功能、性能、精度调试,大大缩短了产品开发周期。并且,无需为每个端侧的soc芯片单独开发或者适配一套开发环境。对于多核拆分策略来说,现有技术中,数据并行的问题在于,其扩展性依赖于处理的数据批量的大小。尽管在训练阶段这通常不会是一个问题,但是对于推理阶段这个前提则难以保证。一般来说,用于实时服务领域(包括视频监控,自动驾驶等)的神经网络模型,处理的数据通常是以流的方式串行输入,导致了每次处理的数据规模很小甚至往往是单张图片。在这种情况下,数据并行不能提供任何并行度,所有的工作任务会集中在单个核上,这使得多核带来的计算资源不能转化成处理任务的速度。当在线下使用数据集完成了神经网络模型的训练后,就会把模型部署到云端的服务器上来处理外界发来的数据,此时的应用场景就由离线训练变成了在线推理。在在线推理阶段,一个非常重要的指标是时延,也就是从服务器收到待处理数据到返回处理后的结果的时间,进一步来说,是使用神经网络模型处理数据的时间。低时延保证云端服务器能够对客户端发来的数据在最短的时间内做出响应,在一些更加敏感的场景下,直接决定了方案是否可用。因此,在线推理阶段对于人工智能处理器的要求就由处理大批量数据、高吞吐量转变为处理小批量数据、低时延。在这种情况下,传统的数据并行或者模型并行难以有效降低推理任务的时延。对于数据并行来说,大批量数据是前提,这本身与在线推理小批量数据的特点矛盾。对于模型并行来说,它通常是为了解决一个规模很大的神经网络模型超过了单个设备的内存限制而采用的方法,把算子分配到不同的核上并不能降低网络的时延。为了真正能够在多核人工智能处理器上降低推理任务的时延,必须寻找一种方法,能够把对小批量数据甚至单个数据的推理计算任务合理地分配到多核架构的各个核上,保证每一时刻都有尽可能多的核参与计算,才能充分利用多核架构的资源。一种方法是把神经网络中的每个算子的计算任务都拆分到多个核上计算,这种方法即使在处理单张图片的推理任务时也能保证每一时刻都有多个核参与计算,从而达到了利用多核资源降低时延的目的。但是,对于多核人工智能处理器来说,还有很多要解决的问题。首先,深度学习人工智能处理器通过定制化自身的硬件设计来适配深度学习算法本身的数据并行特征,提高计算吞吐量,人工智能处理器往往需要足够的数据规模才能达到较高的计算效率,而算子内的进一步拆分会减小每个核上的计算规模。当拆分达到一定粒度,每个核上计算效率的损失会超过拆分增加并行度所带来的收益。因此,必须在拆分并行和计算效率之间,在保证足够计算效率的同时提供足够的并行度。另一方面,神经网络模型可以看作是一个由通常数以百计甚至千记的算子所构成的复杂计算图。不同种类的算子内的算法逻辑各不相同,这就导致对这些算子进行拆分的方法也不一样。每个算子的拆分,除了平衡自身的计算效率和并行度,还要考虑和前后算子的搭配,甚至于对全局的影响。深度学习的快速发展带来的是越来越多的大规模复杂网络,通过手动方式寻找一种好的并行方法是不现实的,因此需要一种自动化的方法来保证来对于不同的网络都能够给出一种较好的拆分并行策略。此外,还需要考虑的是对于底层人工智能处理器的可移植性。对于没有足够良好的可编程性的人工智能处理器来说,由单核扩展到多核,并且实现算子内部的拆分并行所带来的修改软件栈的工作量是非常大的。传统的数据并行和模型并行的实现仍然是基于一个处理核完成一个算子的计算任务,所以并不会带来很多额外的工作,而单个算子的跨核并行需要对算子本身实现进行修改,这种修改的难易程度依赖于人工智能处理器的可编程性和原有算子实现逻辑的复杂程度。如何减小在多核架构上实现低时延推理过程中的额外开销,缓解实现过程中工作量对于人工智能处理器本身可编程性的依赖,使得方法能够在未来对于不同的多核人工智能处理器都有一定的通用性也是一个需要考虑的问题。基于上述分析描述,在本申请实施例中,把一个算子拆分成多个规模更小的子算子,这样可以直接调用单核架构下的计算库,避免了重新实现的额外工作量。比如:一个激活算子在经过拆分后可以得到许多更小的激活算子,这意味着只需要在多个核上调用原有的单核激活函数完成每个子任务,而不需要修改或者重新实现一个多核版本的激活函数。在这个过程中,既需要兼顾每个算子本身的拆分后的计算效率和并行度,也要考虑上下文算子彼此之间在拆分上的相互配合。最终目标是得到一个能够有效降低整个神经网络模型端到端的推理时延的拆分并行方案。此外,需要说明的是,本申请实施例所提供的神经网络处理方法能够尽量避免对单核处理器计算库进行修改,同时也能够实现神经网络模型在多核处理器上的并行执行。具体地,上层框架通过把神经网络模型中的算子拆分成若干个可以并行执行子算子,对每个子算子,深度学习框架调用计算库生成所述子算子在单个核上执行的机器指令,通过把所述子算子的机器指令加载到不同核上,实现算子在多核处理器上的并行计算。具体地,因为深度学习框架可以使用单核处理器计算库生成子算子的计算指令,神经网络模型中所述算子的输入和输出张量数据随着所述算子被拆分成子算子同样被拆分成相应的子张量数据。下面结合图11所示的根据所述端侧人工智能处理器的硬件架构信息以及对应的访存带宽生成对应的二进制指令的流程图。具体说明在本申请实施例中是如何对目标算子进行拆分,进而达到优化人工处理器核运算过程的目的。下面以caffe为例进行详细描述,可以包括但不限于如下步骤:步骤a):所述通用处理器根据人工智能算法模型对应计算图中的目标算子,确定与所述目标算子相关联的张量数据的拆分状态集合;其中,所述张量数据包括输入张量数据和输出张量数据。在caffe框架下,所述目标算子可以是神经网络模型中的对应目标层(layer),该目标层为所述神经网络模型中的至少一层,所述张量数据包括输入张量数据和输出张量数据。在本申请实施例中,神经网络模型可以接收输入数据,并根据接收的输入数据和当前的模型参数生成预测输出。在实际应用中,该神经网络模型可以是回归模型、深度神经网络(deepneuralnetwork,dnn)、卷积神经网络模型(convolutionalneuralnetworks,cnn)、循环神经网络模型(recurrentneuralnetworks,rnn)等,本申请实施例不作具体限定。在计算机设备执行神经网络计算任务时,如果该神经网络计算任务具有多层运算,多层运算的输入神经元和输出神经元并非是指整个神经网络模型的输入层中神经元和输出层中神经元,而是对于网络中任意相邻的两层,处于网络正向运算下层中的神经元即为输入神经元,处于网络正向运算上层中的神经元即为输出神经元。以卷积神经网络为例,设一个卷积神经网络模型有l层,k=1,2,...,l-1,对于第k层和第k+1层来说,我们将第k层称为输入层,其中的神经元为所述输入神经元,第k+1层称为输出层,其中的神经元为所述输出神经元。即除最顶层外,每一层都可以作为输入层,其下一层为对应的输出层。在本申请实施例中,算子是指,实现某种特定功能的函数。例如,以reshape算子为例,该算子用于对张量数据的形状进行重新诠释。又例如,以transpose算子为例,该算子用于调整张量数据的维度顺序。在本申请实施例中,有向无环图是指,在有向图的基础上加入了无环的限制。在本申请实施例中,有向边可以用于表征算子与算子之间的连接关系,也可以用于表征人工智能处理器执行神经网络模型时的执行顺序。在本申请实施例中,所述目标算子的输入张量数据的拆分状态集合中的拆分状态根据所述目标算子的运算逻辑和对应输出张量数据的拆分状态集合中的拆分状态确定。在本申请实施例中,所述目标算子的输出张量数据的拆分状态集合中的拆分状态根据所述算子的运算逻辑和对应输入张量数据的拆分状态集合中的拆分状态确定。具体来说,神经网络模型通常可以看作是一个由算子和多维张量数据所构成的有向无环图(dag,directedacyclicgraph),算子和张量数据彼此之间通过有向边相互连接,有向边的指向表明了数据是算子的输入或者是输出。为了便于阐述,在本申请实施例中,我们使用op表示算子,tensor表示张量数据。同时,为了统一不同算子的拆分方式的表达,深度学习框架统一选择使用与算子相关联的张量数据的拆分方式来说明不同算子的拆分方式。在本申请实施例中,认为神经网络中所有张量数据都是4维的,对于图像分类网络最后的全连接层和归一化指数回归层的输入数据或输出数据来说,实际维度不到4,仍然将其表示为4维张量。用符号n,c,h,w分别表示这4个维度。其中,n表示批量的大小,c表示特征图像的个数,h表示特征图像的高,w表示特征图像的宽。这种假设是仅仅是出于说明的便捷性,对于框架本身来说,可以支持含有任意维度数量的张量数据的神经网络模型的处理。尽管如此,4维对于相当大一部分的神经网络结构都足够使用。在本申请实施例中,当计算机设备对神经网络模型中的算子进行拆分时,考虑到算子的种类不同,该算子支持的计算逻辑也不相同,同样有不同的拆分策略。为了能够统一地表达不同算子的拆分策略,我们采用算子的输入张量数据、输出张量数据的拆分状态来表示算子本身计算逻辑的拆分。在本申请实施例中,考虑到不同的算子具有不同的特性,为了避免不合理的拆分方式带来的负面影响,在对算子进行拆分时,计算机设备可以根据算子的类型确定算子的拆分方式,从而可以得到拆分状态集合中的拆分状态。具体地,请参见表1:表1operation允许拆分的输入维度卷积算子(convolution)n,c,h,w(h和w不应小于卷积核)全连接(fc)算子n,c激活算子(relu)n,c,h,wscalen,c,h,w批标准化层(batchnorm)n,c,h,w分类器算子(softmax)无法拆分要规范化的维度池化算子(pooling)n,c,h,w(h和w不应小于卷积核)如表1所示,不同类型的算子支持的拆分方式是不同的。通过这一实现方式,可以结合算子的特性对算子进行有针对性地拆分,从而可以避免不合理的拆分方式带来的负面影响,例如,加大了计算机设备的资源消耗、导致因拆分后的子算子的规模不均衡而带来的耗时问题等等。具体来说,以卷积算子为例,在本申请实施例中,卷积算子的不同拆分方式可以描述为以下5种,这5种情况可以相互交叉,同时存在,可以保证足够的拆分度:(1)当卷积算子输入数据的n维度超过1时,在n维度上进行拆分;(2)在卷积算子的输入数据的c维度上进行拆分;(3)在卷积算子的输出数据的c维度上进行拆分;(4)在卷积算子的输入数据的h维度上进行拆分;(5)在卷积算子的输入数据的w维度上进行拆分。可以知道的是,上述五种拆分方式都是把原始的卷积算子拆分成更小的卷积。为了便于理解,下面结合具体的实例进行阐述。在caffe框架下,神经网络模型具有层级结构,如图12所示,是本申请实施例提供的一种卷积算子的原始计算图的示意图。对于卷积算子conv来说,其包含4个维度上的输入数据(input),并在权值矩阵的作用下,可以得到输出数据(output)。如图13a-13e所示,为本申请实施例提供的计算图上卷积算子在并行度为2的条件下的多种拆分方式。具体地,图13a为按照输入数据的n维度进行拆分得到的示意图;图13b为按照输出数据的c维度进行拆分的示意图;图13c为按照输入数据c维度进行拆分得到的示意图;图13d为按照输入数据的h维度进行拆分得到的示意图;图13e为按照输入数据的w维度进行拆分得到的示意图。需要说明的是,图中每个张量数据给出了各个维度的起点和终点,用来明确拆分后的子张量数据与原始张量数据之间的关系。图中n表示输入数据批量大小、ic表示输入数据特征图像数量、ih表示输入数据特征图像的长度、iw表示输入数据特征图像的宽度、oc表示输出数据特征图像数量、oh表示输出数据特征图像的长度、ow表示输出数据特征图像的宽度、kh表示卷积核窗口的长度、kw表示卷积核窗口宽度。在实际应用中,这些拆分方式执行在不同的维度上,同时彼此之间可以通过相互组合形成更多的拆分方式,从而可以提供足够的并行度来利用多核处理器的资源,同时在一定程度上可以避免单个维度的过度拆分影响计算机设备的计算效率。又例如,以分类器(softmax)算子为例,计算机设备可以在softmax算子概率归一化的维度之外的任意一个或几个维度上对softmax算子进行拆分,拆分后将得到若干个可以并行执行的softmax算子。又例如,以激活算子为例,计算机设备可以允许其输入数据和输出数据在任意维度上进行拆分。在实际应用中,当一个激活算子的输入数据被分成了若干个子块(从一致性的角度来考虑,输出数据也会进行同样的划分),不妨表示为input0、input1、input2、......、inputm-1和output0、output1、output2、......、outputm-1,则在计算阶段,整个激活算子实际上被拆分成了m个更小的激活算子,这些激活算子彼此之间没有依赖关系,可以运行在多个核上。这里,需要说明的是,选择在何种维度上对算子进行拆分对于拆分方式特别敏感的算子是非常有意义的。例如,如上描述的分类器(softmax)算子。在本申请实施例中,在确定与目标算子关联的张量数据的拆分状态集合时,拆分状态集合可以包括如下几种表现形态:(1)在一种可能的实现方式中,神经网络模型中包含多种不同类型的算子,且这些算子可以允许在任意维度上进行拆分,在这种情况下,计算机设备可以根据多种不同算子中的每个算子各自对应的拆分方式确定拆分状态集合中的拆分状态。为了便于理解,下面结合具体的实例进行阐述,在caffe框架下,神经网络模型具有层级结构,例如,如图13f所示,人脸识别神经网络模型中包含多种不同类型的算子(卷积算子、池化算子、全连接算子),其中,各算子之间的连接关系为:卷积层1-池化层1-卷积层2-池化层2-全连接层1-全连接层2。由于这些算子可以允许在任意维度上进行拆分,那么,在这种情况下,计算机设备可以根据每个算子各自对应的拆分方式确定拆分状态集合中的拆分状态。(2)在一种可能的实现方式中,神经网络模型中包含多种不同类型的算子,其中,一些算子可以允许在任意维度上进行拆分,一些算子只支持在有限维度上进行拆分,那么,在这种情况下,计算机设备可以分别确定这多个不同算子各自对应的拆分方式,然后,将这多个不同算子各自对应的拆分方式确定为拆分状态集合中的拆分状态。(3)在一种可能的实现方式中,神经网络模型中包含多种不同类型的算子,其中,一些算子可以允许在任意维度上进行拆分,一些算子只支持在有限维度上进行拆分,那么,在这种情况下,计算机设备可以分别确定这多个不同算子各自对应的拆分方式,然后,将多个算子中的每个算子均支持的拆分方式的交集确定为拆分状态集合中的拆分状态。为了便于理解,下面结合具体的实例进行阐述,在caffe框架下,神经网络模型具有层级结构,例如,如图13g所示,车牌字符识别神经网络模型中包含多种不同类型的算子(卷积算子、池化算子、激活算子、softmax算子等),其中,各算子之间的连接关系为:卷积层1-激活函数relu-最大池化层1-卷积层2-激活函数relu-最大池化层2-卷积层3-激活函数relu-最大池化层3-卷积层4-激活函数-最大池化层4-卷积层5-激活函数-最大池化层5-全连接层1-softmax层-输出层。由于卷积算子、池化算子、激活算子可以允许在任意维度上进行拆分,而softmax算子只支持在有限维度上进行拆分,那么,在这种情况下,计算机设备将这多个算子中的每个算子均支持的拆分方式的交集确定为拆分状态集合中的拆分状态。(4)在一种可能的实现方式中,神经网络模型中包含多种不同类型的算子,其中,一些算子完全不支持任何形式的拆分,而神经网络模型中的其他算子为了在数据的拆分格式上保持一致,在这种情况下,不对神经网络模型进行拆分。我们将这一状态认为是不拆分状态。通过这一实现方式,可以避免不合理的拆分方式带来的负面影响,例如,加大了计算机设备的资源消耗、导致因拆分后的子算子的规模不均衡而带来的耗时问题等等。这里,在确定拆分状态集合中的状态时,对于本申请所描述的技术方案来说,可以对整个神经网络模型中的所有算子进行拆分,也可以对神经网络模型中的部分算子进行拆分,本申请实施例不做具体限定。另外,考虑到目前深度学习领域出现的网络结构和算法已经逐渐模糊各个数据维度的物理意义和彼此之间的界限,本技术方案可以扩展应用到更多维度下的算子拆分。在本申请实施例中,我们将张量数据的任意一种拆分称为该张量数据的一种拆分状态s,计算机设备对张量数据拆分后,获得子张量数据集合。拆分状态s通过对应的子张量数据集合进行表征。所有可能的拆分{s0,s1,s2,…}组成了该张量数据的拆分状态集合s,一般来说,这是一个非常大的状态空间,这意味着由张量数据的拆分状态所表示的算子的可能的拆分方式的空间也非常巨大。在本申请实施例中,计算机设备可以在满足设置好的至少一种剪枝条件下,对张量数据的状态空间进行剪枝,以缩小状态空间。例如,剪枝条件可以包括但不限于:(1)在对神经网络模型进行拆分时,应该保证拆分后的子算子的规模是均衡的。通过这一实现方式,可以从张量的状态空间s中去除那些拆分上不均衡的拆分状态。在本申请实施例中,保证拆分后的子算子的规模是均衡的原因在于:首先,多核处理器完成一个算子的计算的时延取决于执行子任务耗时最长的那个核的时间,而多核架构中各个核在硬件结构上彼此是相互对等的,因此每个核的时间耗费的长短取决于分配给该核的任务负载的多少。在满足拆分后的子算子的规模是均衡的情况下,可以保证多核结构中的每个核的时间消耗是相等的,从而可以提高计算机设备的执行效率。(2)在对神经网络模型进行拆分时,应该保证拆分后的子算子的数量是2的整数次幂。通过这一实现方式,可以从张量的状态空间s中去除那些拆分数量上不均衡的拆分状态。在本申请实施例中,保证拆分后的子算子的数量是2的整数次幂的原因在于:多核处理器的架构中的核数通常是2的整数次幂,如1,2,4,8,16等等。在实际应用中,一个并行度不是2的整数次幂的任务往往会导致核的调度上产生“碎片”,因此拆分后的子算子数量应当保证是2的整数次幂。可以理解的是,当计算机设备在满足如上至少一种剪枝条件时,计算机可以对状态空间s中的拆分状态进行调整,以去除一些不合理的拆分状态,可以在实现缩小算子拆分策略的搜索空间的同时,避免不合理的拆分方式带来的负面影响,例如,加大了计算机设备的资源消耗、导致因拆分后的子算子的规模不均衡而带来的耗时问题等等。在本申请实施例中,并非选择任意与算子关联的张量数据的拆分状态都能表示该算子的一种有效的拆分方式。张量数据的拆分的维度应该被算子所支持,例如归一化指数回归算子(softmax)的输入数据不应该在待归一化的维度上存在拆分。此外,算子的输入张量和输出张量的拆分应该满足算子的计算逻辑,例如,卷积算子的输出数据在h/w维度上拆分的每一个子块的起止点都应该确实是其对应的输入数据在h/w维度上拆分的子块根据卷积算子的卷积核和位移步长计算出来的;卷积算子的输入数据在c维度上的拆分应该和权值数据在c维度上的拆分完全一致,输出数据在c维度上的拆分应该和权值数据在n维度上的拆分完全一致。在深度学习框架中,使用输出状态根据每个算子的具体逻辑来反向推出算子的输入状态,或者使用输入状态根据每个算子的具体逻辑来正向推出算子的输出状态。这保证了相关数据的拆分状态始终能够表示一个有效的算子拆分方式。步骤b):所述通用处理器遍历所述拆分状态集合,确定相邻拆分状态集合之间所述算子的张量数据的拆分路径以及所述拆分路径的权重;其中,所述拆分路径的权值基于所述访存带宽确定。在本申请实施例中,如图13h所示,整个神经网络模型的拆分方案p可以看作是由每个算子的输入张量数据的拆分状态集合中的一种拆分状态向输出张量中的一种拆分状态的跳转。前一个算子的输出张量的拆分状态即是后一个算子输入张量的拆分状态。经过算子的每一种可能的跳转对应了在该算子上的一种有效的拆分方式。因此,拆分路径可以表示算子的拆分方式。在本申请实施例中,经所述拆分路径对应的拆分方式对算子的计算逻辑进行拆分,获得对应的子算子集合。输入张量数据的状态和对应输出张量数据的状态通过拆分路径连接,表示该输入张量数据的一拆分状态的子张量数据集合经过子算子集合中的子算子处理,得到该输出张量数据的对应拆分状态的子张量数据集合。这里,路径用于表示算子的输入到输出的中间过程。在本申请实施例中,可以将算子在某种拆分状态下在多核处理器上并行执行时所用的时间表征为权重。这里,需要说明的是,多核处理器完成一个算子的计算时间取决于执行拆分后的子计算任务耗时最长的那个核的时间。在本申请实施例中,可以通过如下步骤a1-a4确定每种拆分路径的权重值:a1、确定拆分后的n个子算子的计算负载c1,c2,…,cn。其中,ci根据拆分后第i个子算子的类型和规模计算得到;a2、确定n个子算子的访存数据量d1,d2,…,dn。其中,di根据拆分后第i个子算子的类型和规模计算得到;a3、确定每个人工智能处理器核的计算吞吐速率α。α由人工智能处理器本身的性能参数所决定;a4、确定每个人工智能处理器核的访存带宽β。通常来说,人工智能处理器的多个核共享有限的访存带宽,因此β=b/n。其中,b是多核人工智能处理器的总带宽。基于上述确定好的参数,计算机设备可以根据如下计算公式(1)来计算每种拆分策略对应的权重值:t=maxi=1,...,n(max(ci/α,di/β))(1)其中,计算公式中内侧的取最大值操作是基于算子实现的计算部分和访存部分之间能够相互隐藏,即计算和访存可以做到尽量并发执行。对于一些人工智能处理器来说,当子算子的规模过小时会导致每个核的计算吞吐量降低,可以对α进行进一步修正使估值更加准确。计算公式中外侧的取最大值操作就是多核人工智能处理器完成一个算子的计算的时间取决于执行子计算任务耗时最长的那个核的时间。需要说明的是,上述获取拆分路径的权重的方式仅仅是例举的部分情况,而不是穷举,本领域技术人员在理解本申请技术方案的精髓的情况下,可能会在本申请技术方案的基础上产生其它的变形或者变换,比如:衡量拆分路径的权重不仅仅可以是执行子任务的所花费的时间,也可以是执行子任务的吞吐量。或也可以通过实际测量在多核处理器上执行所述拆分路径对应的算子拆分方式下的所有子任务的时间来确定拆分路径的权重。但只要其实现的功能以及达到的技术效果与本申请类似,那么均应当属于本申请的保护范围。步骤c):所述通用处理器根据所述拆分路径的权重,确定所述目标算子的张量数据的目标拆分路径,根据所述目标拆分路径对所述计算图中的目标算子进行拆分。在本申请实施例中,在确定目标算子的张量数据的目标拆分路径时,可以包括两种不同的实现方式。在一种可能的实现方式中,可以通过正向遍历的方式来确定目标拆分路径。在另一种可能的实现方式中,可以通过反向遍历的方式来确定目标优化路径。下面对其进行具体阐述:在本申请实施例中,通过正向遍历的方式来确定目标优化路径,可以包括:遍历所述目标算子的张量数据的所有拆分状态集合,对当前拆分状态集合,遍历每一拆分状态,获得所有指向当前拆分状态的有向边以及所述有向边的起点对应的拆分状态到所述目标算子的输入张量数据的拆分状态之间的拆分路径;根据所述有向边的权重和所述有向边对应的起始拆分状态到所述目标算子的输入张量数据的拆分状态之间的拆分路径的权重确定所述当前拆分状态到所述目标算子的输入张量数据的拆分状态之间的拆分路径;其中,所述拆分路径的权重根据所述拆分路径对应的所有有向边的权重确定;遍历完所述目标算子的所有拆分状态集合后,获得所述目标算子的输入张量数据的拆分状态集合与所述目标算子的输出张量数据的拆分状态集合之间的目标拆分路径。在本申请实施例中,通过反向遍历的方式来确定目标优化路径,可以包括:遍历所述目标算子的所有拆分状态集合,对当前拆分状态集合,遍历每一拆分状态,获得所有以当前拆分状态为起点的有向边以及所述有向边的终点对应的拆分状态到所述目标算子的输出张量数据的拆分状态之间的拆分路径;根据所述有向边的权重和所述有向边的终点对应的拆分状态到所述目标算子的输出张量数据的拆分状态之间的拆分路径的权重确定所述当前拆分状态到所述目标算子的输出张量数据的拆分状态之间的拆分路径;其中,所述拆分路径的权重根据所述拆分路径对应的所有有向边的权重确定;遍历完所述目标算子的所有拆分状态集合后,获得所述目标算子的输入张量数据的拆分状态集合与所述目标算子的输出张量数据的拆分状态集合之间的目标拆分路径。在本申请实施例中,当计算机设备确定好了神经网络模型的多种不同的拆分方案各自对应的权重值之后,计算机设备可以将权重值最小的拆分方案确定为神经网络模型的目标拆分路径。在本申请实施例中,计算机设备通过正向遍历(或反向遍历)获取到的目标拆分路径的数量可以为1个,也可以为多个,本申请实施例不作具体限定。本领域的技术人员应当理解,目标拆分路径的数量往往需要结合具体的神经网络模型(亦或是目标算子)来确定。这里,进一步需要说明的是,在目标优化路径的数量为多个的情况下,本申请实施例可以采用多个目标优化路径中的任意一个目标优化路径对神经网络模型进行拆分,也可以采用在多个目标优化路径中选择一个最优的目标优化路径对神经网络模型进行拆分,以使多核处理器在对应的核上运行拆分好的神经网络模型。在本申请实施例中,计算机设备可以结合viterbi算法从图13h中获取目标优化路径。这里,目标优化路径为权重和最小的路径。具体来说,viterbi算法是一种动态规划算法,用于寻找最有可能产生观测时间序列的隐含状态序列。在本申请实施例中,将张量数据拆分状态集合中的状态看作是viterbi算法中的隐含状态,将拆分状态集合之间的有向边看作是隐含状态之间的转移关系,而有向边的权重对应着隐含状态之间的转移概率的对数值。具体实现中,计算机设备可以由前往后遍历网络计算图中的所有算子,当访问第i个算子时,计算机设备根据当前算子对应的所有有向边及其权重(具体地,如公式5)确定神经网络模型中的输入张量数据的拆分状态集合中的拆分状态到当前算子的输出张量数据的拆分状态集合中的每个拆分状态的最短路径当计算机设备完成所有算子的遍历后,可以得到由神经网络的输入张量数据的拆分状态集合中的拆分状态到输出张量数据的拆分状态集合中的每个拆分状态的最短路径;之后,计算机设备在这些最短路径中确定全局范围内的最短路径,也即目标优化路径。这里,需要说明的是,上述例举的采用类似于viterbi算法来获取目标优化路径的实现方式,只是作为一种示例,而不是穷举,本领域技术人员在理解本申请技术方案的精髓的情况下,可能会在本申请技术方案的基础上产生其它的变形或者变换,比如:神经网络模型的输入张量数据的拆分状态集合到神经网络模型的输出张量数据的拆分状态集合之间的每一条拆分路径的权重由对应的状态路径的权重之和确定。根据经验设置一阈值,拆分路径的权重小于设定的阈值,就可以作为目标拆分路径对神经网络模型进行拆分。但只要其实现的功能以及达到的技术效果与本申请类似,那么均应当属于本申请的保护范围。为了便于理解,下面结合具体的实例阐述在本申请实施例中是如何在遍历了目标算子的所有拆分状态集合后获得目标拆分路径的。如图14a所示,该神经网络模型为串行结构,且整个神经网络模型的输入张量数据和输出张量数据均为不拆分状态。这里,整个神经网络模型的输入张量数据为不拆分状态是指:在当前的拆分状态集合中有且只有一个输入状态。那么,相应的,整个神经网络模型的输出张量数据为不拆分状态是指:在当前的拆分状态集合中有且只有一个输出状态。我们把一个包含n个算子的串行神经网络模型描述为一个算子序列(op0,op1,op2,...,opn),假设每个算子只有一个输入和一个输出,前一个算子的输入是后一个算子的输出,那么包括整个神经网络的输入张量数据和输出张量数据以及所有的算子之间的中间结果张量在内,所有的张量数据构成集合(tensor0,tensor1,...,tensorn),opi的输入是tensori-1,输出是tensori。对每个数据张量tensori,有与之对应的状态集合si,搜索策略的目标是寻找一种张量本身和其状态集合的某个状态之间的映射关系tensori→si,通过给神经网络模型中每个张量数据确定一个具体的拆分状态,从而可以确定所有算子的拆分方式,因此,把一个神经网络模型中所有张量数据到其拆分状态的一种映射关系称为该网络模型的一种拆分方案p。在计算阶段,第i个算子opi以处于拆分状态s的输入数据计算出处于拆分状态r的输出张量数据,具体的并行计算方式由输入张量数据和输出张量数据的状态所决定,同时,该算子的计算时间记为ts→r,其值的大小取决于相应的拆分方式和底层加速器的硬件特性,则整个网络的时延t的计算公式为:其中,si-1∈si-1,si∈si。由于整个网络的拆分方案p可以看作是由每个算子的输入张量的状态集合中的一种状态向输出张量中的一种状态的跳转。这里,经过算子的每一种可能的跳转对应了在该算子上的一种有效的拆分方式,同样与之对应的还有使用该拆分方式在多核处理器上并行执行该算子所适用的时间ti,因此ti可以看作是由算子的输入张量的状态指向输出张量的状态的有向边的权重。同时,作为整个网络的输入张量和输出张量,他们对应的状态空间中只有一种不拆分的保持整个数据块连续完整的状态,这使得神经网络模型的拆分方案p由完整的输入数据开始,到完整的输出数据结束,外部的用户始终看到一个完整的输入和输出。此时,对于给定的神经网络模型搜索一个好的拆分方案p,即是寻找一条由输入张量数据的不拆分状态到输出张量数据的不拆分状态的最短路径,该路径在每个中间结果张量的有效状态空间中都要选择一个状态经过。这里,式3、式4给出了这种抽象的公式表示。p={s0,s1,...,sn}=argmin(t(s0,s1,...,sn))(3)具体地,计算机设备将整个神经网络模型的输入张量数据的不拆分状态为起始状态sroot,在初始阶段,神经网络模型的输入张量数据的不拆分状态为起始状态sroot对应的拆分路径的权重为0,其余所有张量数据的所有状态的对应的拆分路径的权重为∞。神经网络模型中任一张量数据的任一状态s都有与之对应的由sroot开始到s的拆分路径权重为ls。由前往后访问每一个拆分状态集合,在每个拆分状态集合中,依次遍历其中的每一个状态s。对每个状态s,有指向后一拆分状态集合中若干拆分状态的有向边e1,…,eks。以后一拆分状态集合中的拆分状态v为例,使用式(1)获得状态s到状态v之间的权重tsv,利用式(5)来更新该状态路径指向的下一拆分状态集合中的状态v对应的由sroot开始到状态v的拆分路径的权重lv。lv=min(lv,ls+tsv)(5)在计算机设备依据神经网络模型的有向边正向遍历完成所有拆分状态集合的访问后,可以获得整个神经网络模型的输入张量数据的不拆分状态sroot到神经网络模型的输出张量数据的不拆状态send的目标拆分路径。上述描述一条由不拆分状态sroot到不拆分状态send经过每个拆分状态集合中的一个状态的路径,该路径即为神经网络模型的拆分路径。计算机设备可以从神经网络模型的拆分路径中选取权重最小的作为神经网络模型的目标拆分路径。需要说明的是,图14a所示的神经网络模型为串行神经网络模型,且为了便于说明本技术方案,神经网络模型的输入张量数据和输出张量数据对应的拆分状态集合均为不拆分状态。在神经网络模型的输出张量数据的拆分状态集合不是不拆分状态send,而是多个拆分状态构成的集合时,神经网络模型的输出张量数据的拆分状态集合中的每个拆分状态的拆分路径的权重中选出最小值作为整个神经网络模型的输入张量数据的拆分状态集合到神经网络模型的输出张量数据的拆分状态集合之间的目标拆分路径。另外,需要说明的是,计算机设备可以搜索由不拆分状态send到不拆分状态sroot的拆分路径,二者是等价的。同理,在神经网络模型的输入张量数据的拆分状态集合不是不拆分状态send,而是多个拆分状态构成的集合时,神经网络模型的输入张量数据的拆分状态集合中的每个拆分状态的拆分路径的权重中选出最小值作为整个神经网络模型的输入张量数据的拆分状态集合到神经网络模型的输出张量数据的拆分状态集合之间的目标拆分路径。在本申请实施例中,多核人工智能处理器的核数可以为8,也可以为16,本申请实施例不作具体限定。在本申请实施例中,在确定了目标优化路径之后,计算机设备可以根据确定好的目标优化路径对目标算子进行拆分。考虑到神经网络模型用于执行某个特定的神经网络计算任务,例如,人脸识别;又例如,边缘检测;又例如,语义分析等等。当计算机设备根据目标拆分路径对神经网络进行拆分,也即将神经网络计算任务拆分成若干个子计算任务,在这种情况下,计算机设备可以通过调用多核人工智能处理器来运行拆分后的若干个子计算任务,从而可以得到运行结果。这里,运行结果是指,计算机设备执行特定神经网络计算任务时的结果,可以包括但不限于:神经网络模型的精度、神经网络模型的运行时间等等。在实际应用中,计算机设备可以输出该运行结果,例如,计算机设备通过显示屏显示该运行结果。实施本申请实施例,计算机设备通过将神经网络计算任务拆分成若干个规模更小的子计算任务,这样多核处理器可以直接调用单核架构下的计算库,充分利用了多核处理器的硬件资源,从而可以避免重现实现的额外工作量。在本申请实施例中,可以在目标算子与关联的拆分状态之间插入胶水算子,以调整拆分状态集合中的拆分状态,接下来具体介绍在本申请实施例中是如何引入胶水算子,基于更新后的拆分状态集合来确定目标优化路径的,可以包括但不限于如下步骤:步骤s400、根据所述神经网络模型中目标算子,确定与所述目标算子的算子关联的张量数据的拆分状态集合。在本申请实施例中,关于步骤s400的具体实现请参考前述步骤s300,此处不多加赘述。步骤s402、在所述目标算子与关联的拆分状态集合之间插入胶水算子,调整所述拆分状态集合中的拆分状态,得到调整后的拆分状态集合;其中,所述胶水算子用于将所述张量数据按照一种拆分方式得到的拆分状态转换成按照任一种拆分方式得到的拆分状态。在本申请实施例中,为了便于区分引入胶水算子前的拆分状态集合和引入胶水算子后调整得到的拆分状态集合,我们将引入胶水算子前的拆分状态集合定义为第一拆分状态集合,将引入胶水算子后调整得到的拆分状态集合定义为第二拆分状态集合。在本申请实施例中,当对单个算子进行拆分时,根据选择的拆分方式的不同,与算子关联的张量数据也会按照不同的方式被拆分成若干子张量数据。由于在实际网络中,张量数据往往与多个算子存在关联关系,使得每个计算图中的每个算子选择怎样的拆分方式不是一个孤立的问题,会对相邻算子甚至网络中的所有算子都会产生影响。例如,最简单的情况下,某张量数据tensor1既是算子op0的输出数据,也是算子op1的输出数据。当op0确定按照某种方式进行拆分后,tensor1作为op0的输出,同样也确定了按照某种方式拆分成了一些列子张量数据,那么op1在选择拆分方式时,必须保证选择的方式与其输入数据tensor1已经确定的拆分方式相兼容,这使得op0的选择范围受到了约束。那么,可以理解的是,op1在这种约束下所选择的拆分方式又会通过与其关联的张量数据约束其他相邻算子的拆分选择。这种算子间关于拆分方式选择的相互影响会带来很多问题,首先,会带来性能方面的问题。在实际应用中,当计算机设备在多核处理器上调用不同的拆分方式下对应子计算任务时,性能间有差异。那么,可以理解的是,如果相邻的两算子最佳的算子拆分方案在其共同关联的张量数据上的拆分方式上不一致的情况下,为了避免冲突,必然有一方要屈就于另一方的选择。其次,算子之间的拆分方式的相互影响会影响整个网络的可执行性。如前所述,不同算子所能够支持的拆分方式取决于算子自身的类型以及数据规模。有些算子,譬如激活算子relu,卷积算子conv,所支持的拆分方式允许其输入数据在nchw中的任意维度上进行拆分;有些算子,譬如softmax算子,所支持的拆分方式只允许其输入数据在某个特定的维度上进行拆分;而最后一些算子,往往是实现上非常复杂的算子,譬如nms(non-maximumsuppression)算子,难以通过算子拆分的方式把计算负载分配到多个核上并行,因此,这类算子最终只能在单个核上执行,相应的输入数据应该保持完整不拆分的状态。那么,可以理解的是,如果一个神经网络模型中存在上述提及的最后一类算子,则必须保证该算子的输入数据处于完整不拆分的状态,否则网络在该算子处无法继续执行。如果这种约束随着网络结构扩散,就会使得难以通过算子拆分的方式在神经网络计算中挖掘出足够数量的并行度。在本申请实施例中,为了解决算子拆分彼此之间相互影响的问题,在目标算子与关联的第一拆分状态集合之间插入胶水算子,该胶水算子可以实现让神经网络模型对应的计算图中的每个算子可以灵活不受限地选择作用于自身的拆分方式。具体来说,胶水算子(transform)用于将张量数据由按照一种拆分方式得到的若干个子张量数据的状态调整为按照另一种方式拆分得到的若干个子张量数据。如图14b所示,当当前张量数据的拆分方式不被其后的算子的任何一种拆分方式所允许,又或者其后的算子在兼容当前张量数据的拆分方式的前提下可选择的方案所带来的性能提升很差,在这种情况下,计算机设备可以通过在计算图中插入胶水算子把当前数据调整成另一种更优的拆分方式。在本申请实施例中,胶水算子的语义可以通过神经网络模型中的concat算子和/或split算子得到。下面对其进行具体阐述:在本申请实施例中,concat算子,也即,拼接算子,用于将多个张量数据沿着指定的维度拼接成一个张量。除了在指定维度外,输入张量的其他维度应该保持一致。通过concat算子,神经网络将代表来自上游不同位置的特征的多个张量拼接成一个,从而可以在下游计算中对这些特征共同进行处理。具体地,可以参见图14c所示的concat算子语义的示意图。在本申请实施例中,split算子,也即拆分算子,用于将一个张量在指定维度上拆分成多个张量。拆分后的多个张量除了指定维度之外,在其他维度上保持一致。通过split算子,可以把属于同一张量数据的特征拆成多份,从而在后续计算中分别进行针对性处理。具体地,可以参见图14d所示的split算子语义的示意图。在本申请实施例中,胶水算子内部采用拆分-拼接、拼接-拆分、拼接、拆分这四种方式中的其中之一种实现方式,在拼接阶段可以把在任意维度上相邻的子数据块拼接成一个新的子张量数据,在拆分阶段,可以把任意一个子张量数据拆分成几个更小的子张量数据。这样,张量数据按照任意一种拆分方式得到的子张量数据可以转换成按照另一种方式拆分得到的子张量数据。为了说明这一点,不妨假设数据本身是一维的,调整前的拆分形式表示为{(0,p1),(p1,p2),…,(pn-1,end)},每一段代表一维数据拆分后的一个子段,通过胶水算子调整后的拆分形式是{(0,q1),(q1,q2),…,(qm-1,end)},如果调整前的某相邻两段(pi-1,pi),(pi,pi+1)是调整后的某一段(qj,qj+1),即pi-1=qj,pi+1=qj+1,在调整这一部分时只需要在拼接阶段把(pi-1,pi),(pi,pi+1)拼接在一起,跳过拆分阶段。同样另一种情况下,如果调整前的某一子段是调整后的若干子段的集合,则跳过拼接阶段,在拆分阶段执行相应的拆分。最坏情况下,可以把拼接阶段把所有数据组合成一个完整一维数据,在拼接阶段在进行对应的拆分。在本申请实施例中,所述在所述目标算子与关联的第一拆分状态集合之间插入胶水算子,调整所述算子的输入张量数据的拆分状态集合中的拆分状态,得到第二拆分状态集合,包括:在所述目标算子与关联的第一拆分状态集合之间插入胶水算子,通过所述胶水算子将所述第一拆分状态集合中的拆分状态更新为所述第二拆分状态集合。如前所述,我们把数据按照任意一种方式拆分得到的所有子张量数据称为该张量数据的一种拆分状态s,张量数据所有可能的状态构成了该张量数据的状态空间s。假设网络中有算子op按照某一拆分方式进行拆分,则其输入数据tensor0和输出数据tensor1分别有状态s和t,二者分属于tensor0和tensor1的状态空间s、t。在此基础上,op自身的拆分方式可以视作是一条由s指向t的有向边。在本申请实施例中,基于上述对张量数据的状态的抽象描述,整个神经网络可以被抽象成如图13h所示。图中,虚线框代表每个张量数据的拆分状态集合,集合中包含了若干个拆分状态,这些拆分状态来自于该张量数据的拆分状态空间。算子的输入张量数据的拆分状态集合中的状态和输出张量的拆分状态集合中的状态之间的有向边表示该算子本身的一种拆分方式,使用该拆分方式下的并行时间作为有向边的权重。其中,tensor0是整个神经网络的输入张量数据,tensor3是整个神经网络的输出张量数据,任意一条由tensor0的拆分状态集合中的任一状态出发,到tensor3的拆分状态集合中的任一状态结束的路径,都对应了一种该神经网络的有效拆分方案,例如,可以记为p。在本申请实施例中,以图13h所示的tensor1的拆分状态集合为例,在op0关联的拆分状态集合中拆入胶水算子,通过胶水算子将该拆分状态集合中的状态进行调整,可以得到更新后的拆分状态集合。具体地,可以如图14e所示。在图14e中,更新后的拆分状态集合中的拆分状态包括:statem’1、statem’2、statem’k。这里,statem’1、statem’2、statem’k为第一拆分状态集合中的状态经过胶水算子后产生的新的状态。在本申请实施例中,所述在所述目标算子与关联的第一拆分状态集合之间插入胶水算子,调整所述算子的输入张量数据的拆分状态集合中的拆分状态,得到第二拆分状态集合,包括:在所述目标算子与关联的第一拆分状态集合之间插入胶水算子,通过所述胶水算子将所述第一拆分状态集合中的拆分状态更新为第三拆分状态集合;根据所述第一拆分状态集合和所述第三拆分状态集合生成所述第二拆分状态集合。在本申请实施例中,以图13h所示的tensor1的拆分状态集合(也即第一拆分状态集合)为例,在op0关联的拆分状态集合中拆入胶水算子,通过胶水算子将该拆分状态集合中的拆分状态进行调整,将第一拆分状态集合中的拆分状态更新为第三拆分状态集合,之后,根据第一拆分状态集合和第三拆分状态集合生成第二拆分状态集合。具体地,可以如图14f所示。在图14f中,第二拆分状态集合中的拆分状态包括:state1、state2、...、statem’。这里,state1、state2、...statem为第一拆分状态集合中的拆分状态,而statem’为第一拆分状态集合中的状态经过胶水算子后产生的新的拆分状态。通过这一实现方式,可以保证第二拆分状态集合中尽可能的包含多种不同的拆分状态,这有利于接下来获取整个神经网络模型的目标优化路径。在本申请实施例中,通过胶水算子来表示调整张量数据的拆分状态的行为方式,神经网络模型的每一层的计算规模随着网络的延申不断变化,随着神经网络模型拆分趋势的变化,需要对算子的拆分方式做出相应的调整,也就是对中间结果的状态进行调整。如图14e所示,在op0和其输入tensor1之间加入了胶水算子,可以把张量数据的任意一种拆分状态转换成另一种拆分状态。对胶水算子而言,其输入张量数据和输出张量数据有着相同的形状和相同的状态空间,由输入张量数据的任一拆分状态,存在指向输出张量数据所有拆分状态的有向边,因此在输入张量数据的拆分状态集合和输出张量数据的拆分状态集合之间形成了全连接的网状结构。这使得任意一种输入张量数据的拆分状态可以在算子op0前转换成另一种拆分状态,给拆分方案的搜索空间中引入了在每个算子计算开始前调整其输入张量数据的拆分状态,也即是调整算子本身拆分方式的可能性。需要说明的是,图14e或图14f示出了算子与对应的输入张量数据之间插入胶水算子,也可以在算子与对应的输出张量数据之间插入胶水算子,更可以在算子与对应的输入张量数据、输出张量数据之间均插入胶水算子,此次仅仅是例举的部分情况,而不是穷举,本领域技术人员在理解本申请技术方案的精髓的情况下,可能会在本申请技术方案的基础上产生其它的变形或者变换,但只要其实现的功能以及达到的技术效果与本申请类似,那么均应当属于本申请的保护范围。步骤s404、遍历所述调整后的拆分状态集合,确定相邻拆分状态集合之间所述目标算子的张量数据的拆分路径。如前所述,这里,调整后的拆分状态集合也即第二拆分状态集合。步骤s406、根据所述拆分路径的权重,确定所述目标算子的张量数据的目标拆分路径。步骤s408、根据所述目标拆分路径对所述目标算子进行拆分,以分配到所述多核人工智能处理器的对应核进行处理。在本申请实施例中,关于步骤s404-步骤s408的具体实现请参考前述步骤s302-步骤s306,此处不多加赘述。实施本申请实施例,在目标算子与关联的拆分状态集合之间插入胶水算子,该胶水算子可以实现让神经网络模型对应的计算图中的每个算子可以灵活不受限地选择作用于自身的拆分方式,从而可以解决算子拆分彼此之间相互影响的问题。在本申请实施例中,通过引入胶水算子使得每个算子都可以根据实际情况选择适当的拆分方式,然而,在计算机设备在运行包含有胶水算子的神经网络模型时,由于胶水算子本身会带来额外的开销,这无疑加大了计算机设备的资源消耗。以胶水算子采用拆分-拼接或拼接-拆分为例,假设待调整张量数据的总大小为m,且两个阶段均不能跳过,且每个阶段都要针对4个维度进行拼接或者拆分。为了便于移植,拼接和拆分通常会使用神经网络算法中自带的拼接算子(concat)和拆分算子(split)实现,由于这两个算子每次只能处理一个维度,整个胶水在最差情况下会带来8m的存储读写开销。所以,必须在调整拆分状态和引入的额外开销之间寻找一个最佳的平衡点,再引入尽量少的胶水算子的情况下又能符合网络结构的规律再合理的地方对算子的拆分方式进行调整。这也是本申请描述的技术方案旨在解决的技术问题。基于此,在本申请实施例中,在上述步骤s406之后,在步骤s408之前,还可以包括步骤s4010,下面对其进行具体阐述:步骤s4010、在满足所述目标拆分路径中包含的同一胶水算子的输入张量数据的状态和输出张量数据的状态相同的情况下,将插入的对应胶水算子删除,得到优化后的目标拆分路径。在本申请实施例中,计算机设备根据拆分路径的权重确定好目标拆分路径之后,计算机设备判断目标拆分路径中包含的同一胶水算子的输入张量数据的状态和输出张量数据的状态是否相同,在满足同一胶水算子的输入张量数据的状态和输出张量数据的状态相同的情况下,移除该胶水算子。这里,当同一胶水算子的输入张量数据的状态和输出张量数据的状态相同表示在该位置使用胶水算子并没有对张量数据的拆分状态进行任何调整。如前所述,当计算机设备在运行包含有胶水算子的神经网络模型时,因胶水算子本身会带来额外的开销,这无疑加大了计算机设备的资源消耗。当计算机设备在满足同一胶水算子的输入张量数据的状态和输出张量数据的状态相同的情况下,移除该胶水算子的实现方式,可以减少计算机设备的资源消耗。进一步地,这一实现方式可以把引入胶水算子所带来的额外开销和算子本身不同拆分方式的并行效率放在一起进行决策,从而可以得到一个基于整个神经网络的最优拆分方案p。那么,相应地,计算机设备在执行上述步骤s304根据拆分路径的权重确定好目标拆分路径之后,计算机设备判断目标拆分路径中包含的同一胶水算子的输入张量数据的状态和输出张量数据的状态是否相同,在满足同一胶水算子的输入张量数据的状态和输出张量数据的状态不相同的情况下,保留该胶水算子。在这种情况下,这里引入的胶水算子可以使得每个算子的拆分方式兼容了与其直接关联的张量数据的拆分方式,通过这一实现方式,可以把引入胶水算子所带来的额外开销和算子本身不同拆分方式的并行效率放在一起进行决策,从而可以得到一个基于整个神经网络的最优拆分方案p。那么,相应地,在本申请实施例中,当计算机设备执行上述步骤s306时,根据所述优化后的目标拆分路径对目标算子进行拆分。这里,对目标算子的拆分的具体实现请参考前述描述,此处不多加赘述。实施本申请实施例,删除目标优化路径中输入张量数据的状态和输出张量数据的状态相同的胶水算子,可以在调整拆分状态和引入的额外开销之间寻找一个最佳的平衡点。当计算机设备执行根据优化后的目标优化路径进行拆分的神经网络模型时,可以减少计算机设备的资源消耗。在本申请实施例中,考虑到神经网络模型中具有多分支结构,在这种情况下,需要解决多分神经网络模型中不同分支拆分方式一致性的问题。位于分支交汇处的算子具有1个以上的输入张量数据,例如对位加法算子(add),对位乘法算子(mult),拼接算子(concat)。对一个有2个输入的算子a,在计算机设备访问该算子,即根据输入张量数据的拆分状态集合确定输出张量数据的拆分状态集合结束后,两个输入张量数据tensorleft、tensorright分别有对应的拆分状态集合sleft和sright。分别沿tensorleft、tensorright开始的两条之路继续向前遍历,一种情况下,两条支路会直接延伸直至遍历结束,代表整个网络有不止一个输入数据,这通常在推理任务中并不常见,另一种情况下,两条支路在某算子处合到一起。无论哪种情况,当确定拆分方案p时,在算子a的两个输入张量数据tensorleft、tensorright上,可能会选中相互不匹配的拆分状态。具体来说,假设算子a是二元对位加法算子,回溯过程在tensorleft的拆分状态集合中选中的可能是一个仅在c维度上有拆分的状态,而在tensorright的拆分状态集合中选中的可能是一个仅在h维度上有拆分的状态,这两个拆分状态所表示的加法算子本身的拆分方式是不一致的,因此会导致整个拆分方案p无效。在本申请实施例中,回溯是指上一个实现过程的逆过程。例如,当对神经网络模型进行正向遍历时,回溯是指对神经网络模型进行反向遍历。回溯过程的目的在于避免计算机设备在确定目标优化路径时出现误判,从而导致根据计算机设备在调用拆分后的神经网络模型时的时间消耗增大等负面影响。为了解决这个问题,在遍历算子a结束前保证tensorleft、tensorright对应的拆分状态集合中都只含有一个拆分状态,这确保回溯过程中在两状态集合中选择的状态的确定性。在一种情形下,在正向遍历阶段,当前算子的输出张量数据被至少两个算子作为输入张量数据,或当前算子具有至少两个输出张量数据时,当前算子的输出张量数据的拆分状态集合中保留一个拆分状态,且保留的拆分状态经由当前算子的同一有向边确定。下面具体描述在本申请实施例中,是如何确保回溯过程中在两状态集合中选择的状态的确定性,该方法可以包括但不限于如下步骤:步骤700:根据所述神经网络模型对应的计算图中目标算子,确定与所述目标算子关联的张量数据的拆分状态集合;步骤702:遍历所述拆分状态集合,确定相邻拆分状态集合之间所述算子的张量数据的拆分路径;步骤704:根据所述拆分路径的权重,确定所述目标算子的张量数据的目标拆分路径。具体实现中,所述确定所述目标算子的张量数据的目标拆分路径,包括:遍历所述目标算子的张量数据的所有拆分状态集合,对当前拆分状态集合,遍历每一拆分状态,获得所有指向当前拆分状态的有向边以及所述有向边的起点对应的拆分状态到所述目标算子的输入张量数据的拆分状态之间的拆分路径;根据所述有向边的权重和所述有向边对应的起始拆分状态到所述目标算子的输入张量数据的拆分状态之间的拆分路径的权重确定所述当前拆分状态到所述目标算子的输入张量数据的拆分状态之间的拆分路径;其中,所述拆分路径的权重根据所述拆分路径对应的所有有向边的权重确定;遍历完所述目标算子的所有拆分状态集合后,获得所述目标算子的输入张量数据的拆分状态集合与所述目标算子的输出张量数据的拆分状态集合之间的目标拆分路径。这里,这一实现方式为通过正向遍历的方式来获取目标优化路径。步骤706:根据所述目标拆分路径对所述目标算子进行拆分,以分配到所述多核人工智能处理器的对应核进行处理。在本申请实施例中,为了确保回溯过程中在两状态集合中选择的状态的确定性,在正向遍历阶段,当前算子的输出张量数据被至少两个算子作为输入张量数据,或当前算子具有至少两个输出张量数据时,当前算子的输出张量数据的拆分状态集合中保留一个拆分状态,且保留的拆分状态经由当前算子的同一有向边确定。这样,在遍历分支算子结束前,将从多个输入数据的拆分状态集合中选择出对应累计权重最小的状态保留下来,移除拆分状态集合中其他的拆分状态。在本申请实施例中,关于步骤s700-步骤s706的具体实现请参考前述步骤s300-步骤s306的相关描述,此处不多加赘述。在一种可能的实现方式中,结合引入胶水算子来调整拆分状态集合中的拆分状态以及对目标优化路径中输入张量数据的状态和输出张量数据的状态相同的胶水算子进行删除,可以得到对上述步骤s700-步骤s706描述的方法的变形,可以包括但不限于如下步骤:步骤700’、根据所述神经网络模型对应的计算图中目标算子,确定与所述目标算子关联的张量数据的拆分状态集合;步骤702’、在所述目标算子与关联的第一拆分状态集合之间插入胶水算子,调整所述目标算子的输入张量数据的拆分状态集合中的拆分状态,得到第二拆分状态集合;其中,所述胶水算子用于将所述张量数据按照一种拆分方式得到的拆分状态转换成按照任一种拆分方式得到的拆分状态;步骤704’、遍历所述第二拆分状态集合,确定相邻拆分状态集合之间所述目标算子的张量数据的拆分路径;步骤706’、根据所述拆分路径的权重,确定所述目标算子的张量数据的目标拆分路径。具体实现中,所述确定所述目标算子的张量数据的目标拆分路径,包括:遍历所述目标算子的张量数据的所有拆分状态集合,对当前拆分状态集合,遍历每一拆分状态,获得所有指向当前拆分状态的有向边以及所述有向边的起点对应的拆分状态到所述目标算子的输入张量数据的拆分状态之间的拆分路径;根据所述有向边的权重和所述有向边对应的起始拆分状态到所述目标算子的输入张量数据的拆分状态之间的拆分路径的权重确定所述当前拆分状态到所述目标算子的输入张量数据的拆分状态之间的拆分路径;其中,所述拆分路径的权重根据所述拆分路径对应的所有有向边的权重确定;遍历完所述目标算子的所有拆分状态集合后,获得所述目标算子的输入张量数据的拆分状态集合与所述目标算子的输出张量数据的拆分状态集合之间的目标拆分路径。这里,这一实现方式为通过正向遍历的方式来获取目标优化路径。在本申请实施例中,为了确保回溯过程中在两状态集合中选择的状态的确定性,在正向遍历阶段,当前算子的输出张量数据被至少两个算子作为输入张量数据,或当前算子具有至少两个输出张量数据时,当前算子的输出张量数据的拆分状态集合中保留一个拆分状态,且保留的拆分状态经由当前算子的同一有向边确定。这样,在遍历分支算子结束前,将从多个输入数据的拆分状态集合中选择出对应累计权重最小的状态保留下来,移除拆分状态集合中其他的拆分状态。步骤s708’、在满足所述目标拆分路径中包含的同一胶水算子的输入张量数据的状态和输出张量数据的状态相同的情况下,删除所述胶水算子,得到优化后的目标拆分路径;步骤s7010’、根据所述优化后的目标拆分路径对所述目标算子进行拆分,以分配到所述多核人工智能处理器的对应核进行处理。在本申请实施例中,关于步骤s700’-步骤s7010’具体实现请参考前述实施例中的相关描述,此处不多加赘述。实施本申请实施例,在正向遍历阶段,对于位于分支点的算子或输出张量,计算机设备仅保留唯一一个到目前为止对应的路径的最短的状态,删除其他所有的状态。通过这一实现方式,可以避免回溯阶段可能出现的不一致,可以提高计算机设备确定目标优化路径的效率和精确度。在另一种情形下,在反向遍历阶段,当所述算子具有至少两个输入张量数据时,所述算子的输入张量数据的拆分状态集合中保留一个拆分状态,且所述拆分状态经由所述算子的同一状态路径确定。下面具体描述在本申请实施例中,是如何确保回溯过程中在两状态集合中选择的状态的确定性,该方法可以包括但不限于如下步骤:步骤800:根据所述神经网络模型对应的计算图中目标算子,确定与所述目标算子关联的张量数据的拆分状态集合;步骤802:遍历所述拆分状态集合,确定相邻拆分状态集合之间所述算子的张量数据的拆分路径;步骤804:根据所述拆分路径的权重,确定所述目标算子的张量数据的目标拆分路径。具体实现中,所述确定所述目标算子的张量数据的目标拆分路径,包括:遍历所述目标算子的所有拆分状态集合,对当前拆分状态集合,遍历每一拆分状态,获得所有以当前拆分状态为起点的有向边以及所述有向边的终点对应的拆分状态到所述目标算子的输出张量数据的拆分状态之间的拆分路径;根据所述有向边的权重和所述有向边的终点对应的拆分状态到所述目标算子的输出张量数据的拆分状态之间的拆分路径的权重确定所述当前拆分状态到所述目标算子的输出张量数据的拆分状态之间的拆分路径;其中,所述拆分路径的权重根据所述拆分路径对应的所有有向边的权重确定;遍历完所述目标算子的所有拆分状态集合后,获得所述目标算子的输入张量数据的拆分状态集合与所述目标算子的输出张量数据的拆分状态集合之间的目标拆分路径。这里,这一实现方式为通过反向遍历的方式来获取目标优化路径。步骤806、根据所述目标拆分路径对所述目标算子进行拆分,以分配到所述多核人工智能处理器的对应核进行处理。在本申请实施例中,为了确保回溯过程中在两状态集合中选择的状态的确定性,在反向遍历阶段,当前算子具有至少两个输入张量数据时,当前算子的输入张量数据的拆分状态集合中保留一个拆分状态,且所述拆分状态经由所述算子的同一有向边确定。这样,在遍历分支算子结束前,将从多个输入数据的拆分状态集合中选择出对应累计权重最小的状态保留下来,移除拆分状态集合中其他的拆分状态。在一种可能的实现方式中,结合引入胶水算子来调整拆分状态集合中的拆分状态以及对目标优化路径中输入张量数据的状态和输出张量数据的状态相同的胶水算子进行删除,可以得到对上述步骤s800-步骤s806描述的方法的变形,可以包括但不限于如下步骤:步骤800’、根据所述神经网络模型对应的计算图中目标算子,确定与所述目标算子关联的张量数据的拆分状态集合;步骤802’、在所述目标算子与关联的第一拆分状态集合之间插入胶水算子,调整所述目标算子的输入张量数据的拆分状态集合中的拆分状态,得到第二拆分状态集合;其中,述张量数据按照一种拆分方式得到的拆分状态转换成按照任一种拆分方式得到的拆分状态;步骤804’、遍历所述第二拆分状态集合,确定相邻拆分状态集合之间所述目标算子的张量数据的拆分路径。步骤806’、根据所述拆分路径的权重,确定所述目标算子的张量数据的目标拆分路径。具体实现中,所述确定所述目标算子的张量数据的目标拆分路径,包括:遍历所述目标算子的所有拆分状态集合,对当前拆分状态集合,遍历每一拆分状态,获得所有以当前拆分状态为起点的有向边以及所述有向边的终点对应的拆分状态到所述目标算子的输出张量数据的拆分状态之间的拆分路径;根据所述有向边的权重和所述有向边的终点对应的拆分状态到所述目标算子的输出张量数据的拆分状态之间的拆分路径的权重确定所述当前拆分状态到所述目标算子的输出张量数据的拆分状态之间的拆分路径;其中,所述拆分路径的权重根据所述拆分路径对应的所有有向边的权重确定;遍历完所述目标算子的所有拆分状态集合后,获得所述目标算子的输入张量数据的拆分状态集合与所述目标算子的输出张量数据的拆分状态集合之间的目标拆分路径。这里,这一实现方式为通过反向遍历的方式来获取目标优化路径。在本申请实施例中,为了确保回溯过程中在两状态集合中选择的状态的确定性,在反向遍历阶段,当前算子具有至少两个输入张量数据时,当前算子的输入张量数据的拆分状态集合中保留一个拆分状态,且所述拆分状态经由所述算子的同一有向边确定。这样,在遍历分支算子结束前,将从多个输入数据的拆分状态集合中选择出对应累计权重最小的状态保留下来,移除拆分状态集合中其他的拆分状态。步骤s808’、在满足所述目标拆分路径中包含的同一胶水算子的输入张量数据的状态和输出张量数据的状态相同的情况下,删除所述胶水算子,得到优化后的目标拆分路径;步骤s8010’、根据所述优化后的目标拆分路径对所述目标算子进行拆分,以分配到所述多核人工智能处理器的对应核进行处理。在本申请实施例中,关于步骤s800’-步骤s8010’具体实现请参考前述实施例中的相关描述,此处不多加赘述。实施本申请实施例,在反向遍历阶段,对于位于分支点的算子或输出张量,计算机设备仅保留唯一一个到目前为止对应的路径的最短的状态,删除其他所有的状态。通过这一实现方式,可以避免回溯阶段可能出现的不一致,可以提高计算机设备确定目标优化路径的效率和精确度。为了便于理解,下面示例性地描述本申请可以适用的应用场景:以自动驾驶应用为例,车辆在自动行驶过程中需要对车载传感器采集到的图像、视频、语音等外部信息进行分析处理。为了保证安全性,车辆必须在最短的时间内得到上述多种外部信息的分析结果,从而做出科学、有效地决策。由于车辆的硬件系统中配置了多核处理器结构的处理芯片,车辆的硬件系统可以通过本申请描述的技术方案对神经网络模型处理小批量外部信息的计算任务进行拆分,得到拆分后的多个子计算任务,并通过将拆分后的子计算任务均衡地分配给多个处理器核上,从而可以实现在多个处理器核上并行执行多个子计算任务。这一实现方式可以高效的完成外部信息的处理,并将处理结果返回,车辆的智能驾驶系统可以根据返回结果辅助车辆自动驾驶。可以理解的是,本技术方案可以把一个算子拆分成多个规模更小的子算子,这样可以直接调用单核架构下的计算库,充分利用了多核处理器的硬件资源,从而可以避免重现实现的额外工作量。在上述应用场景中,多核处理器结构芯片设置在车辆上。实际中,多核处理器结构芯片可以设置在云端服务器上,车辆可以通过3g/4g、wifi等网络将车载传感器传来的图像、视频、语音等外部信息发生至云端服务器。云端服务器使用本方案把神经网络模型处理小批量外部信息的计算负载均衡地分配到多个处理核上。在车辆行驶规定的响应时间内,云端服务器将处理结果通过3g/4g、wifi等网络反馈至车辆。在实际中,车载传感器采集到的外部信息的规模不同。在应用之前,根据不同规模的外部信息,车载处理器利用本方案确定相应的算子拆分路径。将不同规模的外部信息对应的算子拆分方案存储对应区域,多核处理器结构芯片获取外部信息后调出对应的算子拆分路径来对神经网络模型中的算子进行拆分,把外部信息的计算负载均衡地分配到多个处理器核上。需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本披露并不受所描述的动作顺序的限制,因为依据本披露,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于可选实施例,所涉及的动作和模块并不一定是本披露所必须的。进一步需要说明的是,虽然图11的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图11中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。步骤d):所述通用处理器根据所述端侧人工智能处理器的硬件架构信息对拆分后的神经网络模型进行编译,获得对应的二进制指令。如图7所示,为本申请提供的一种数据处理方法流程图之二。所述方法应用于云侧人工智能处理器上。包括:步骤701a):接收人工智能学习任务;其中,所述人工智能学习任务是根据端侧人工智能处理器的设备信息生成的二进制指令确定的;步骤702b):执行所述人工智能学习任务,生成运行结果。在本步骤中,所述运行结果包括但不限于以下一种或多种信息:所述人工智能学习任务在云侧人工智能处理器上的运行时间是否符合预期要求、执行所述人工智能学习任务时占用云侧人工智能处理系统的负载信息是否符合预期要求、执行人工智能学习任务的结果是否符合预期要求。需要强调的是,图5所示的所有相关技术方案内容均适用于图7所示的技术方案,这里不再赘述。这里需要明确的是,对云侧设备101来说,一种应用场景是:在云侧人工智能处理器集合中,尽可能涵盖端侧人工智能处理器的所有版本的硬件架构信息。例如:型号与硬件架构信息的版本对应,端侧人工智能处理器的型号有a、b、c等。在云侧人工智能处理器集合中,均包含型号为a的人工智能处理器、型号为b的人工智能处理器、型号为c的人工智能处理器。另一种应用场景是:在云侧人工智能处理器集合中,人工智能处理器的硬件架构能够实现高配置功能、中配置功能或低配置功能。例如:针对不同的应用场景和实际需求,将人工智能处理器的部分功能屏蔽,转换为低配置功能的人工智能处理器或中配置功能的人工智能处理器来满足不同客户的需求。这种情况下,本技术方案中的软件开发平台102在生成二进制指令时是基于端侧人工智能处理器的设备信息,并且,通过驱动程序更改筛选出的云侧人工智能处理器所支持的不同的运行环境参数,使得高配置版本的人工智能处理器中的部分功能被屏蔽,仅仅在实现的功能上与对应的端侧人工智能处理器的功能相适配。因此,高配置版本的人工智能处理器的运行环境参数的取值范围包含端侧人工智能处理器所支持的所有运行环境参数。比如:云侧人工智能处理器的片上内存大小为100m,端侧人工智能处理器的片上内存大小为小于100m的某个值均可。进一步地,利用分时复用的方法,通过虚拟机技术,根据用户使用云侧设备101的人工智能处理器的资源的时间段,合理分配云侧设备101的人工智能处理器,可以将资源分配给不同时间段的人工智能学习任务,减少需要部署的云侧人工智能处理器的开发环境数量。更进一步地,在云侧设备101的人工智能处理器集合中,并不一定必须都是硬件实体,可以是fpga。参考现代ic设计验证的技术主流,以硬件描述语言(verilog或vhdl)所完成的电路设计,可以经过简单的综合与布局,快速的烧录至fpga上。对于本技术方案来说,若在云侧人工智能处理器中不存在适配的硬件实体,可以使用fpga来为用户提供服务。根据端侧人工智能处理器的设备信息筛选出符合需求的fpga,该fpga具有与端侧人工智能处理器的硬件架构信息所对应的镜像文件。若不存在符合需求的fpga,软件开发平台102可以将端侧人工智能处理器的硬件架构信息对应的镜像文件烧录至一空闲的fpga上,该fpga去执行软件开发平台发送过来的人工智能学习任务。对于云侧人工智能处理器来说,可以提供更细粒度的资源配置。如用户a在软件开发平台102上基于m个core构成端侧人工智能处理器生成人工智能学习任务,而适配出的云侧人工智能处理器具有core的总数为n,且n个core中的p个core已经被用户b发起的人工智能学习任务所使用。若满足m+p<=n,且用户a对应的端侧人工智能处理器的设备信息与用户b对应的端侧人工智能处理器的设备信息必须相同,软件开发平台102中的人工智能运行时库将不同用户发起的人工智能学习任务分配在不同的core上,每个core上执行不同的人工智能学习任务,达到对云侧人工智能处理器的资源更细粒度的分配。还有,针对云侧人工智能处理器来说,可以是常规的非可重构体系结构的人工智能处理器,也可以是可重构体系结构的人工智能处理器。对于可重构体系结构的人工智能处理器来说,利用驱动程序中的设备信息去调整可重构型芯片内部的环境运行参数,并根据软件开发平台102发送过来的人工智能学习任务来调用重构型芯片内部对应的功能模块。也就是说,根据实际应用的不同,去调整可重构型芯片内部的功能模块,使得重构后的芯片来替换端侧人工智能处理器。基于上述关于云侧人工智能处理器的描述,对于本技术方案来说,软件开发平台102统计一段时间内各个时间段使用不同硬件架构信息的云侧人工智能处理器的用户量,估计得到能够满足用户需求的最小值v,该数字v是云侧人工智能处理器的数量配置的最小值。在此基础上添加少量w个冗余的人工智能处理器来进行容错或防止用户量突增的情况,则(v+w)为云侧设备101需要配置的人工智能处理器的数量。同时,软件开发平台102会定期统计用户量的变化情况,改变云侧设备101中部署的人工智能处理器的数量来满足用户的需求且降低云端开销。综上,由上述描述可知,采用实时部署的方式,根据软件开发平台发送过来的人工智能学习任务,动态调整云侧设备101中部署的人工智能处理器资源,达到在用户不感知的情况下,利用分时复用的方法,根据用户使用云侧设备101的人工智能处理器的资源的时间段,通过配置不同的开发环境,可以将同一云侧人工智能处理器资源分配给不同时间段的人工智能学习任务,减少需要部署的云侧人工智能处理器的开发环境数量。如图8所示,为本申请提出的一种数据处理方法流程图之三。所述方法应用于端侧人工智能处理器上;包括:步骤801a):读取离线运行文件集合;其中,所述离线运行文件集合是根据运行结果满足预设要求时对应的所述端侧人工智能处理器的硬件架构信息、访存带宽和二进制指令确定的离线运行文件构成的。步骤802b):对所述离线运行文件集合进行解析,获得离线运行文件映射表;其中,所述离线运行文件映射表是同一端侧人工智能处理器的硬件架构信息所对应的访存带宽与所述离线运行文件之间的对应关系。步骤803c):根据端侧人工智能处理器工作负荷情况,确定当前访存带宽;基于当前访存带宽从所述离线运行文件映射表中确定需执行的当前离线运行文件。步骤804d):执行当前离线运行文件。需要强调的是,图5、图7所示的所有相关技术方案内容均适用于图8所示的技术方案,这里不再赘述。针对端侧人工智能处理器生成的人工智能学习任务,在软件开发平台102上根据云侧人工智能处理器反馈的运行结果对人工智能学习任务进行优化调试,在运行结果达到预期要求后,调试后的人工智能学习任务的二进制指令经固化处理转换为离线运行文件,实现之前的调试和性能成果的固化。之后需要编写离线的应用程序,脱离编程框架保证实际应用场景下精度正常,就可以交叉编译到端侧设备103上进行实地部署了。如图9所示,为本申请提出的一种数据处理流程图之四。所述系统包括通用处理器和云侧人工智能处理器;包括:步骤a:所述通用处理器获取端侧人工智能处理器的硬件架构信息以及对应的可配置的访存带宽,根据所述端侧人工智能处理器的硬件架构信息以及对应的访存带宽生成对应的二进制指令;其中,访存带宽为端侧人工智能处理器到片外存储器的访存宽度;步骤b:所述通用处理器根据所述二进制指令生成对应的人工智能学习任务,将所述人工智能学习任务发送至云侧人工智能处理器上运行;步骤c:所述云侧人工智能处理器接收人工智能学习任务,执行所述人工智能学习任务,生成运行结果;步骤d:所述通用处理器接收所述人工智能学习任务对应的运行结果,根据所述运行结果确定所述访存带宽对应的离线运行文件;其中,所述离线运行文件是根据运行结果满足预设要求时的所述端侧人工智能处理器的硬件架构信息以及对应的访存带宽和二进制指令生成的;步骤e:所述通用处理器根据同一端侧人工智能处理器的不同的访存带宽对应的离线运行文件确定离线运行文件映射表;其中,所述离线运行文件映射表是同一端侧人工智能处理器的硬件架构信息所对应的访存带宽与所述离线运行文件之间的对应关系。需要强调的是,图5、图7所示的所有相关技术方案内容均适用于图9所示的技术方案,这里不再赘述。如图10所示,为一种数据处理装置功能框图之一。所述装置包括:存储器、通用处理器以及云侧人工智能处理器;所述存储器上存储有可在所述通用处理器和/或所述云侧人工智能处理器上运行如图5、图7、图8、图9所示方法的计算机程序。在本实施例中,本申请实施例还提供一种可读存储介质,其上存储有计算机程序,执行计算机程序的流程体现了的上述图5、图7、图8、图9所示的数据处理方法。由上可见,本申请实施例提供一种数据处理方法及相关产品,不管人工智能处理器是否流片,本技术方案就能够提前实现人工智能算法模型与人工智能处理器之间的调试工作。本领域技术人员也知道,除了可以以纯计算机可读程序代码方式在客户端和服务器上实现本技术方案,完全可以将技术方案的步骤在客户端和服务器上以逻辑门、开关、专用集成电路、可编程逻辑控制器和嵌入微控制器等的形式来实现。因此这种客户端和服务器可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置也可以视为硬件部件内的结构。或者甚至,可以将用于实现各种功能的装置视为既可以是实现方法的软件模块又可以是硬件部件内的结构。通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到本申请可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如rom/ram、磁碟、光盘等,存储介质中包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施方式或者实施方式的某些部分所述的方法。本说明书中的各个实施方式均采用递进的方式描述,各个实施方式之间相同相似的部分互相参见即可,每个实施方式重点说明的都是与其他实施方式的不同之处。尤其,针对客户端和服务器的实施方式来说,均可以参照前述方法的实施方式的介绍对照解释。本申请可以在由计算机执行的计算机可执行指令的一般上下文中描述,例如程序模块。一般地,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等等。也可以在分布式计算环境中实践本申请,在这些分布式计算环境中,由通过通信网络而被连接的远程处理设备来执行任务。在分布式计算环境中,程序模块可以位于包括存储设备在内的本地和远程计算机存储介质中。虽然通过实施方式描绘了本申请,本领域普通技术人员知道,本申请有许多变形和变化而不脱离本申请的精神,希望所附的权利要求包括这些变形和变化而不脱离本申请的精神。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1