一种多模态特征融合的文本引导图像修复方法与流程
本发明属于数字图像智能处理技术领域,具体涉及一种图像修复方法,尤其涉及一种多模态特征融合的文本引导图像修复方法。
背景技术:
图像修复是合成图像中缺失或损坏部分的任务。由于其大量的应用,如完成遮挡重建、恢复受损纹理等,已经成为一个热门的研究课题。图像修复的关键是保持图像的全局语义,并恢复缺失区域的真实细节纹理。大多数传统方法选择在缺失区域周围寻找相似的纹理来解决填充孔洞的问题[1]。由于缺乏对高级语义信息的理解,这些方法很难重构出图像中的一些特殊纹理。
近年来,基于深度学习的图像修复方法取得了良好的效果。这些方法利用孔洞周围的信息来预测缺失区域。yu等人提出了一种基于上下文注意力机制的新方法[2],不仅可以合成新的图像结构,而且还可以利用孔洞周围的图像特征作为参考。为了更有效地利用上下文信息,liu等人提出了一种新的连贯语义注意力层(csa)[3],通过模拟孔洞特征之间的语义相关性预测缺失信息。然而,当缺失区域包含图像的主要对象时,这些方法无法做出准确的语义推断。假如一只鸟的躯干被大面积遮挡,这些方法只能通过孔洞周围的信息生成一些类似颜色的补丁,网络并不能准确地推断出待修复区域是一只鸟。然而,在许多情况下,我们需要恢复的恰恰是丢失区域中的物体。
为了产生更合理的修复对象细节纹理,我们研究了画家在修复图像时的行为。当画家看到需要修复的图像中含有一只小鸟的头和尾巴,但是没有小鸟的躯干时,他首先会根据这个现象猜测这幅画的内容,并给出一个大致的文本描述。在绘制缺失区域时,他将以文本描述的内容作为重要参考,以完成更合理的修复结果。这不仅保证了局部像素的连续性,而且保证了图像作为一个整体的语义合理性。
在此过程的启发下,我们认为将文本描述引入图像修复任务是合理且有效的。目前,已有一些深度学习方法,可以通过文本描述直接生成一张图像。zhang等人[4]使用两个gan[5]逐步生成图像:第一阶段生成低分辨率图像,重点是图像的背景、颜色和轮廓;第二阶段使用第一阶段的输出和文本描述作为输入,并生成带有真实细节的高分辨率图像。xu等人提出了attngan[6],在生成过程中添加注意力机制,不仅将文本的句子特征提取为全局约束,而且还将单词嵌入作为局部约束提取到网络中。
虽然文本生成图像的方法可以生成一些合理的结果,但是这种生成是随机的,图像中物体的大小、形状、方向等都不固定,很难直接用于图像修复。因此,如何合理地将图像特征和文本特征进行多模态融合,对于高效的图像修复具有很大的研究价值。
技术实现要素:
为了克服现有技术的不足,本发明的目的在于提供一种能够极大提升物体信息损失严重的图像恢复效果的多模态特征融合的文本引导图像修复方法。
本发明主要针对物体信息损失严重(包括物体被大面积遮挡、缺失主要语义信息等)的图像修复,以图像的文本描述作为先验,构造从粗糙到精细的多阶段深度神经网络作为图像生成器,同时引入判别器来辅助生成器学习图像修复任务,使得生成器可以预测合理的物体信息,在生成自然的图像修复结果的同时,恢复出图像中物体细粒度的纹理。
本发明方法分为两个阶段:粗略修复阶段和精细修复阶段;在粗略修复阶段,网络将文本特征和图像特征映射到统一的特征空间进行融合,利用文本特征的先验知识,网络产生合理的粗糙修复结果;在精细修复阶段,网络为粗糙修复结果生成更多的细粒度纹理;在网络训练中引入重构损失、对抗损失和文本引导的注意力损失来辅助网络生成更加细致、自然的结果。
本发明提供的多模态特征融合的文本引导图像修复方法,具体步骤如下。
(1)从待修复图像中标记出缺损区域
对于一张物体信息缺损严重的图像,首先构建一个与输入图像x大小相同的全零矩阵m,将待修复区域对应像素位置的矩阵点置为1。
(2)将图像对应的文本描述t进行文本特征提取
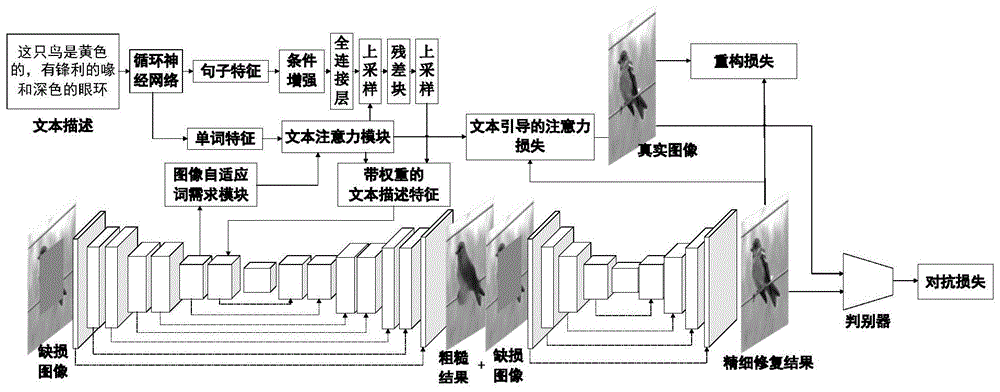
文本描述语句t可以是图像本身包含的外部描述信息,也可以是通过图像中剩余区域的信息,预测出的缺失区域的物体特征表述。将文本描述t送入一个预训练的循环神经网络[7],以当前状态的单词作为输入,通过循环可以使得信息从当前步传递到下一步,帮助网络节点更好地理解文本描述的语义,从而得到初步的句子特征和单词嵌入特征。句子特征经过条件增强[4],将句子向量转换为条件向量。单词特征经过一个注意力模块[6],通过合成一个新的感知层,将单词特征转换到图像特征的公共语义空间,得到一个单词上下文特征ft;根据图像特征,注意力模块关注文本描述中的相关单词,为图像的每个子区域设置一个单词上下文向量,最终得到一张单词注意力图a;对于每一个子区域,其单词上下文向量是与其相关的单词向量的动态表示,指示模型所关注单词的权重。
(3)将输入图像x、缺损区域标记m共同送入编码器
通过编码得到待修复图像的深层特征fi;
具体地,编码器由5个卷积模块组成,包含卷积层和池化层,是粗糙修复网络的第一部分,采用u-net[8]结构,从输入图像中提取特征,将图像压缩成512个16×16的特征向量fi。
(4)将图像特征fi载入图像自适应词需求模块
图像自适应词需求模块以图像修复编码器中间层的特征fi作为输入,经过两个卷积模块和矩阵重塑后分别得到两个特征块g和f。将两个特征块g和f相乘得到一个新的特征图,并对其进行softmax操作,得到一张单词需求注意力图。对应于单词上下文特征向量的每一项,单词需求注意力图的对应项表示需要该向量的概率。图像自适应词需求模块为单词上下文特征ft赋予不同的权重,得到一个带权重的单词特征ftw。为了防止先验信息遗失,将单词上下文特征ft与带权重的单词特征ftw相加,得到最终的图像自适应词特征fti。
这样做的原因是:用文本指导图像修复,文本生成的图像部分必须能和孔洞周围区域的纹理连贯。文本中的描述信息可能包含了缺失区域以外的信息,多余的文本信息经过特征提取可能会造成信息冗余,反而为最终的生成结果增加了一些不需要的纹理。使用图像自适应词需求模块对图像已有特征进行提取,并为文本中的单词特征赋予不同的权重,使得网络可以更有针对性地修复缺失区域中的物体。
(5)将图像自适应词特征fti送入粗糙修复网络中间层,与图像特征fi融合
粗糙修复网络基于u-net结构[8],通过多模态特征融合将文本特征和图像特征映射到统一的多模态向量空间。前半部分是编码器,作用是特征提取,得到图像特征fi;将图像特征fi和相应的图像自适应词特征fti相连接,通过后半部分的解码器,不断上采样得到原始分辨率大小的图像,即粗糙的图像修复结果c。
(6)将粗糙的图像修复结果c、缺损区域标记m共同送入精细修复网络
精细修复网络同样采用u-net结构[8],以粗糙修复结果c和缺损区域标记m为输入,通过不同程度的卷积,学习图像深层次的特征,再经过上采样恢复为原图大小。通过粗糙修复结果c的帮助,精细修复网络可以为图像恢复更加细致的纹理。
(7)通过优化损失函数更新生成器、判别器的参数
生成器g由粗糙修复网络和精细修复网络构成,用于生成一张修复后的图像。在网络的训练中引入判别器[5]来辅助生成器学习图像修复任务,判别器以真实图像和生成图作为输入,任务是判断图像是否真实。判别器输出d(x),代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。训练过程中,生成器g的目标是尽量生成真实的图片去欺骗判别器d。而判别器d的目标就是尽量辨别出g生成的假图像和真实的图像。这样,生成器和判别器就构成了一个动态的博弈,从而促使网络生成更加逼真的图像。同时,网络通过真实图像与修复图像之间的重构损失、文本指导注意力损失来计算生成器参数的梯度,通过真实图像和生成图像计算判别器参数的梯度,通过梯度回传更新网络的参数。
假设定义训练集x={x1,x2,…,xn}。对于训练集中的每个图像xi,它都有相应的文本描述ti;生成器从xi中移除缺损区域,同时使用对应文本描述ti的深层特征,利用深度神经网络产生粗糙的中间结果ci和最终的精细修复结果zi。
为了使生成的粗糙修复结果和最终的精细修复结果都尽可能和原真实图像一致,我们引入像素级的重构损失,定义为:
lrec=||zi-xi||1+||ci-xi||1
将单词注意力图a分别与生成图和真实图相乘,得到带权重的生成图和真实图,并对其进行像素级的l1损失约束,即文本指导注意力损失,定义为
ltga=||a(zi,ti)zi-a(zi,ti)xi||1
这样做的原因是:文本描述包含很多额外的先验信息,例如物体的种类、形状、颜色等等。仅仅将文本特征融入图像修复网络并不能很好的控制网络的学习过程。我们在训练中引入文本指导注意力损失,给网络更多文本相关的约束。单词注意力图a往往更关注文本描述中的实体,即图像缺失区域中的物体。我们希望网络可以对文本关注区域给予更多的考虑,从而生成更真实的细节纹理。
判别器作为二值分类器来区分真实图像和假图像,输出为整个图像的分类结果,使得整个图像尽可能真实,对应的生成对抗损失定义为:
训练时,网络优化更新的整体损失函数定义为:
l=λtgaltga+λreclrec+λganlgan,
其中,ltga为文本指导注意力损失,lrec为重构损失,lgan为生成器和判别器的生成对抗损失,λtga、λrec、λgan为平衡不同损失的权重。
在测试时,网络只需要使用生成器。
对于物体信息损失严重的图像修复问题,本发明提出了一种多模态融合学习方法,并构建了一个文本指导的图像修复对抗生成网络,将文本特征和图像特征映射到一个统一的多模态特征空间。图像自适应词需求模块计算缺损图像需要每个单词的权重,以帮助网络消除冗余文本的不良影响。引入文本指导注意力损失,使网络更多地关注缺失区域的物体特征。本发明的生成图像真实自然,不仅在整体上与文本描述相一致,而且可以恢复出较好的细节纹理。
实验结果表明,本发明可以更好地预测缺失区域中物体的语义信息,并生成细粒度纹理,有效提升图像修复的效果。
附图说明
图1为本发明的网络框架图示。
图2为本发明的图像自适应词需求模块图示。
图3为本发明在鸟类数据集上的图像修复效果图。
图4为本发明在花类数据集上的图像修复效果图。
具体实施方式
对于一张中心区域物体缺损的图像,将缺失区域标记为待修复区域,可以采用图1所示网络进行图像修复。
具体过程如下。
(1)从待修复图像中标记出缺损区域
对于一张物体信息缺损严重的图像,如图1中的小鸟图像缺失中心区域。首先构建一个与输入图像x大小相同的全零矩阵m,将待修复区域对应像素位置的矩阵点置为1,即图1中缺损图像中心灰色区域为1,其余位置为0。
(2)将图像对应的文本描述t进行文本特征提取
文本描述t被送入一个预训练的循环神经网络,得到初步的句子特征和单词嵌入特征。句子特征经过条件增强模块,将句子向量转换为条件向量。单词特征经过一个注意力模块,通过添加一个新的感知层,转换到图像特征的公共语义空间,并得到一个单词上下文特征ft和一个单词注意力图a。如图1中,将图像对应的描述:“这只鸟是黄色的,有锋利的喙和深色的眼环”送入文本特征提取网络,网络将生成一个可以表示该文本描述的句子特征,以及网络关注的单词特征和其对应的注意力权重。
(3)将输入图像x、缺损区域标记m共同送入编码器
编码器通过几个卷积模块,得到待修复图像的深层特征fi。
(4)将图像特征fi载入图像自适应词需求模块
图像自适应词需求模块会根据图像特征fi,为单词上下文特征ft赋予不同的权重,得到一个带权重的单词特征ftw。为了防止先验信息遗失,将单词上下文特征ft与带权重的单词特征ftw相加,得到最终的图像自适应词特征fti。如图1中,缺损图像中小鸟的眼睛是不需要修复的,而小鸟的喙和它身体的颜色是需要修复的。因此,经过此步骤,网络会给“黄色”和“锋利的喙”赋予更高的权重,给“深色的眼环”较少的权重,得到一个带权重的文本描述特征。
(5)将图像自适应词特征fti送入粗糙修复网络,与图像特征fi融合
粗糙修复网络基于u-net结构,通过多模态特征融合将文本特征和图像特征映射到统一的多模态向量空间。将图像特征fi和相应的图像自适应词特征fti相连接,通过解码器生成一个粗糙的图像修复结果c。
(6)将粗糙的图像修复结果c、缺损区域标记m共同送入精细修复网络
精细修复网络结构与粗糙修复网络相同,通过深度学习最终生成纹理更细致的清晰修复结果。
(7)通过优化损失函数更新生成器、判别器的参数
在网络的训练中引入判别器来辅助生成器学习图像修复任务。共使用cub-200-2011数据集和flower数据集进行训练和测试。其中,cub-200-2011数据集包含8855张训练图,2933张测试图,每张图片有10句对应的文本描述;flower数据集包含7034张训练图,1155张测试图,每张图片有7句对应的文本描述。在测试时,网络只需要使用生成器;
所有用于训练和测试的图像大小为256×256像素。我们使用一个大小为128×128的中心矩形掩码覆盖图像,模拟图像缺损区域。循环神经网络是一个预先训练的双向lstm[7],从文本描述中提取语义向量。我们在一台使用nvidiagtx2080tigpu的机器上进行了实验,框架是基于pytorch实现的。网络训练的学习率为2×10-4。参数由adam[9]优化,参数为β1=0.5,β2=0.999,平衡不同损失的权重设置为λtga=1,λrec=1,λgan=0.002。
图3为本发明在鸟类数据集上的图像修复效果图,第1列为待修复图像,第2列为csa的修复效果,第3列为本发明的修复效果,第4列为原始真实图像,第5列为attngan的生成图像,每一行图像上方是其对应的文本描述。相比于csa,本发明的修复结果恢复了鸟的翅膀纹理,并且与文本描述一致。相比于attngan,本发明保留了原始图像的其他区域,并且拥有更好的图像完整性。
图4为本发明在花类数据集上的图像修复效果图,第1列为待修复图像,第2列为csa的修复效果,第3列为本发明的修复效果,第4列为原始真实图像,第5列为attngan的生成图像,每一行图像上方是其对应的文本描述。虽然csa可以从孔洞周围的颜色估计出花中间的近似色块,但本发明可以产生更清晰的花脉、花瓣纹理。
参考文献
[1]barnesc,shechtmane,finkelsteina,etal.patchmatch:arandomizedcorrespondencealgorithmforstructuralimageediting[j].acmtransactionsongraphics,2009,28(3,article24).
[2]jiahuiyu,zhelin,jimeiyang,xiaohuishen,xinlu,andthomasshuang.generativeimageinpaintingwithcontextualattention[j].inproceedingsoftheieeeconferenceoncomputervisionandpatternrecognition,pages5505–5514,2018.
[3]hongyuliu,binjiang,yixiao,andchaoyang.coherentsemanticattentionforimageinpainting[j].iccv,2019.
[4]hanzhang,taoxu,hongshengli,shaotingzhang,xiaogangwang,xiaoleihuang,anddimitrisnmetaxas.stackgan:texttophoto-realisticimagesynthesiswithstackedgenerativeadversarialnetworks[j].inproceedingsoftheieeeinternationalconferenceoncomputervision,pages5907–5915,2017.
[5]iangoodfellow,jeanpougetabadie,mehdimirza,bingxu,davidwarde-farley,sherjilozair,aaroncourville,andyoshuabengio.generativeadversarialnets[j].inadvancesinneuralinformationprocessingsystems,pages2672–2680,2014.
[6]taoxu,pengchuanzhang,qiuyuanhuang,hanzhang,zhegan,xiaoleihuang,andxiaodonghe.attngan:fine-grainedtexttoimagegenerationwithattentionalgenerativeadversarialnetworks[j].inproceedingsoftheieeeconferenceoncomputervisionandpatternrecognition,pages1316–1324,2018.
[7]schusterm,paliwalkk.bidirectionalrecurrentneuralnetworks[j].ieeetransactionsonsignalprocessing,1997,45(11):2673-2681.
[8]ronnebergero,fischerp,broxt.u-net:convolutionalnetworksforbiomedicalimagesegmentation[j].2015.
[9]kingmadp,baj.adam:amethodforstochasticoptimization[j].computerscience,2014.。
- 还没有人留言评论。精彩留言会获得点赞!