基于机器学习的小龙虾分级方法与流程
本发明为一种产品的分级算法,具体涉及一种基于机器学习技术的小龙虾分级算法设计,属于人工智能和机器学习技术领域。
背景技术:
随着近年来人工智能领域的飞速发展,模式识别、机器学习、深度学习等相关技术也日益成熟,并且开始被广泛地应用于人们生产生活各个领域、开始逐步影响和改变人类的生产生活方式。
以餐饮行业为例,目前全国的餐饮市场总量约为3万亿元,与小龙虾相关的餐饮项目占据了其中7%~8%的份额、而且呈现出逐年增长的发展态势。由于小龙虾的大小、品质直接决定着小龙虾的价格,因此在小龙虾从养殖厂到餐桌的过程中,对于小龙虾的分级必不可少。在现有的操作中,对小龙虾的分级大多采用人工操作的方式进行,在分级的同时,死虾和空壳虾也会被单独分拣出来。显而易见的是,这样的操作方式不仅工作量巨大而且操作效率低下,一旦出现小龙虾数目庞大的情况,还很容易因为人工操作的不确定性而出现较大的操作误差。
针对上述问题,目前也出现了一些工业化的小龙虾自动检测流水线,这种流水线主要利用机器视觉技术、通过拟合小龙虾虾体特征与重量关系以及对比虾体位姿图像来实现小龙虾自动分级。具体而言,在这一技术方案中,针对图像采集器传回的图像数据,后端服务器通过智能图像处理提取出小龙虾的标志性区域,并通过一系列的图像预处理和模式识别技术对其进行计数,最后通过小龙虾的标志性区域的大小将其进行分级。区别于人工操作的方式,这一技术手段能够有效避免对人力、物力和财力的过度消耗。但是在实际的技术应用过程中,操作人员发现,此类技术存在一定的应用局限性,在后续图像理解及分级性能等方面仍然有所欠缺。
综上所述,如何设计一种全新的、具有优异分级性能且能够克服现有技术中诸多不足的小龙虾分级方法,也就成为了本领域内技术人员所期望解决的一项技术问题。
技术实现要素:
鉴于现有技术存在上述缺陷,本发明的目的是提出一种基于机器学习技术的小龙虾分级算法设计,具体如下。
一种基于机器学习的小龙虾分级方法,包括如下步骤:
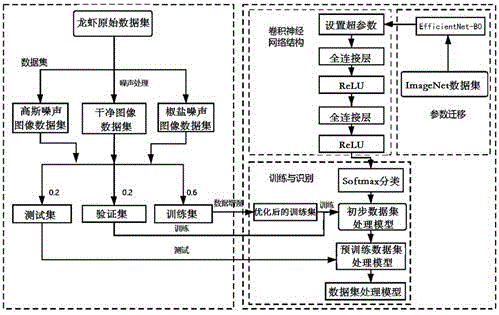
s1、数据集建立步骤,从包含有若干小龙虾图像样本的龙虾原始数据集中提取部分小龙虾图像样本,构建得到干净图像数据集,并将所述干净图像数据集随机划分为训练集、验证集以及测试集;
s2、模型建立步骤,构建初步数据集处理模型,设置所述初步数据集处理模型的超参数并对所述初步数据集处理模型进行特征迁移,随后利用所述训练集、验证集内的数据对所述初步数据集处理模型进行反复训练、验证,得到预训练数据集处理模型,最后利用所述测试集内的数据对所述预训练数据集处理模型进行测试,得到完善的数据集处理模型;
s3、模型使用步骤,使用所述数据集处理模型对所述龙虾原始数据集内的小龙虾图像样本进行逐条处理,最终得到小龙虾分级结果。
优选地,s1所述数据集建立步骤具体包括:
s11、获取若干小龙虾图像样本,按“大”、“中”、“小”三个等级对每个所述小龙虾图像样本进行人工标注等级,将全部样本及其对应等级进行汇总得到龙虾原始数据集,随后从所述龙虾原始数据集选取部分小龙虾图像样本、保证每个等级的样本数量相同,最终构建得到干净图像数据集;
s12、按照划分比例对所述干净图像数据集中的小龙虾图像样本进行随机划分,分别得到训练集、验证集以及测试集、共三个子数据集,在每个子数据集中每个等级的样本数量相同;
s13、利用python中的keras图像预处理模块imagedatagenerator对所述训练集内的小龙虾图像样本进行图像归一化和数据增强处理,对小龙虾图像样本进行旋转操作以增加所述训练集内的数据量,随后通过flow_from_directory()函数将小龙虾图像样本打乱并将所述干净图像数据集转化为二维的one-hot编码标签,实现对所述训练集、验证集以及测试集的优化更新。
优选地,所述划分比例为训练集∶验证集∶测试集=6∶2∶2。
优选地,s2所述模型建立步骤具体包括:
s21、使用imagenet数据集上预训练的efficientnet-b0网络模型作为初步数据集处理模型,设置所述初步数据集处理模型的超参数,通过对所述初步数据集处理模型内的全连接层进行全局平均池化完成特征迁移,再通过线性分类器完成softmax分类;
s22、对经过s21处理后的初步数据集处理模型进行编译处理,随后使用优化更新后的所述训练集、验证集内的数据对所述初步数据集处理模型进行反复训练、验证,得到预训练数据集处理模型;
s24、利用优化更新后的所述测试集内的数据对所述预训练数据集处理模型进行测试,得到完善的数据集处理模型。
优选地,所述初步数据集处理模型采用sequential顺序结构,由一个特征提取层、两个全连接层以及一个线性分类层组成,两个所述全连接层的特征维度分别为512和128,两个所述全连接层内均包含有用于拟合训练数据的relu激活函数。
优选地,所述超参数至少包括要输入的数据集中图像样本的尺寸、batch大小、迭代次数以及类别数。
优选地,所述线性分类器为包含于所述线性分类层内的softmax激活函数。
优选地,s22具体包括:采用编译函数对所述初步数据集处理模型进行编译处理,损失函数选用交叉熵损失函数、优化器选用adam损失函数优化器,冻结efficientnet-b0网络参数、仅训练全连接层和线性分类器内的参数,随后使用fit_generator()函数、结合优化更新后的所述训练集、验证集内的数据对所述初步数据集处理模型进行反复训练、验证,得到预训练数据集处理模型。
优选地,在s22与s24之间,还包括如下步骤:
s23、使用matplotlib.pyplot模块和pandas模块绘制accuracy、loss曲线。
优选地,s24具体包括:利用所述测试集内的数据对所述预训练数据集处理模型进行测试,使用evaluate_generator()函数测试所述预训练数据集处理模型的准确率和loss值,最终得到完善的数据集处理模型。
本发明的优点主要体现在以下几个方面:
本发明所提出的一种基于机器学习技术的小龙虾分级方法,通过将机器视觉与深度学习技术相融合的手段,实现了对于小龙虾大小的自动化分级,大幅减少了使用者的各项成本投入。本发明的方法不仅显著地提升了操作过程中的识别率与准确率,而且有效地弥补了现有方法在后续图像理解及分级性能等方面的缺陷。
此外,本发明的方法也为同领域内的其他相关问题提供了参考,可以以此为依据进行拓展延伸和深入研究,将类似的思路和操作应用于其他的操作平台,应用于对其他产品的分类、分级操作中,具有十分广阔的应用前景和很高的实际应用价值。
以下便结合实施例附图,对本发明的具体实施方式作进一步的详述,以使本发明技术方案更易于理解、掌握。
附图说明
图1为本发明的方法整体流程示意图;
图2为本发明的方法中初步数据集处理模型内全连接层中的处理流程示意图;
图3为本发明的方法在处理干净图像数据集时训练集与验证集的accuracy对比曲线图;
图4为本发明的方法在处理干净图像数据集时训练集与验证集的loss对比曲线图;
图5为本发明的方法在处理高斯噪声图像数据集时训练集与验证集的accuracy对比曲线图;
图6为本发明的方法在处理高斯噪声图像数据集时训练集与验证集的loss对比曲线图;
图7为本发明的方法在处理椒盐噪声图像数据集时训练集与验证集的accuracy对比曲线图;
图8为本发明的方法在处理椒盐噪声图像数据集时训练集与验证集的loss对比曲线图。
具体实施方式
本发明揭示了一种基于机器学习技术的小龙虾分级算法设计,方案细节如下。
如图1~图2所示,一种基于机器学习的小龙虾分级方法,包括如下步骤:
s1、数据集建立步骤,从包含有若干小龙虾图像样本的龙虾原始数据集中提取部分小龙虾图像样本,构建得到干净图像数据集,并将所述干净图像数据集随机划分为训练集、验证集以及测试集。
s2、模型建立步骤,构建初步数据集处理模型,设置所述初步数据集处理模型的超参数并对所述初步数据集处理模型进行特征迁移,随后利用所述训练集、验证集内的数据对所述初步数据集处理模型进行反复训练、验证,得到预训练数据集处理模型,最后利用所述测试集内的数据对所述预训练数据集处理模型进行测试,得到完善的数据集处理模型。
s3、模型使用步骤,使用所述数据集处理模型对所述龙虾原始数据集内的小龙虾图像样本进行逐条处理,最终得到小龙虾分级结果。
s1所述数据集建立步骤具体包括:
s11、获取若干小龙虾图像样本,按“大”、“中”、“小”三个等级对每个所述小龙虾图像样本进行人工标注等级,将全部样本及其对应等级进行汇总得到龙虾原始数据集,随后从所述龙虾原始数据集选取部分小龙虾图像样本、保证每个等级的样本数量相同,最终构建得到干净图像数据集。
s12、按照划分比例对所述干净图像数据集中的小龙虾图像样本进行随机划分,分别得到训练集、验证集以及测试集、共三个子数据集,在每个子数据集中每个等级的样本数量相同。
所述划分比例为训练集∶验证集∶测试集=6∶2∶2。
在本发明的实施例中训练数据是等级为“大”、“中”和“小”的小龙虾图像样本,每类采集565个,共565*3=1695个,并将每一类的样本按照比例6:2:2随机划分成训练集(339个)、验证集(113个)和测试集(113个)。同时通过matlab软件分别对数据集加入方差为0.4的椒盐噪声、加入方差为0.1的高斯噪声模拟实际生产线图像。
s13、利用python中的keras图像预处理模块imagedatagenerator对所述训练集内的小龙虾图像样本进行图像归一化和数据增强处理,对小龙虾图像样本进行旋转操作以增加所述训练集内的数据量,随后通过flow_from_directory()函数将小龙虾图像样本打乱并将所述干净图像数据集转化为二维的one-hot编码标签,实现对所述训练集、验证集以及测试集的优化更新、即完成对所述训练集、验证集以及测试集的生成器部分的补充。
在上述操作中,利用imagedatagenerator图片生成器进行图像预处理,图像归一化处理,将图片像素值归一化为[0,1],图片随机旋转[-40,40]度,采用flow_from_directory(directory),以文件夹路径为参数,生成经过数据归一化处理后的数据,产生batch数据,直到达到设定的迭代次数为止。
s2所述模型建立步骤具体包括:
s21、使用imagenet数据集上预训练的efficientnet-b0网络模型作为初步数据集处理模型,设置所述初步数据集处理模型的超参数,通过对所述初步数据集处理模型内的全连接层进行全局平均池化完成特征迁移,再通过线性分类器完成softmax分类。
所述初步数据集处理模型采用sequential顺序结构,由一个特征提取层、两个全连接层以及一个线性分类层组成。
所述特征提取层主要用于将训练样本输入预训练的efficientnet-b0网络模型中。
所述全连接层用于将将预训练的efficientnet-b0网络模型的特征迁移到小龙虾样本空间。全连接对应矩阵乘积,在实际使用中,全连接层可由卷积操作实现。两个所述全连接层的特征维度分别为512和128,两个所述全连接层内均包含有relu激活函数。所述relu激活函数主要用于修正线性单元、用于隐层神经元输出,其公式为
通过relu激活函数可实现稀疏后的模型能够更好地挖掘相关特征、拟合训练数据。
所述线性分类器为包含于所述线性分类层内的softmax激活函数,其公式为
在构建神经网络中,softmax输出有k个概率值,每个输出都映射到了0到1区间,并且和为1。
所述超参数至少包括要输入的数据集中图像样本的尺寸(input_shape)、batch大小(batch_size)、迭代次数(epochs)以及类别数(num_classes)。在本发明的实施例中,设置要输入的数据集中图像样本的尺寸input_shape=224*224*3;设定batch大小batch_size=8;通常为2^n,如32、64、128...;设定类别数num_classes=3;设定迭代次数epochs=40。
所述迁移学习是指一种机器学习方法,就是把针对数据a训练的模型作为初始点,用于针对数据b的模型的开发和设计过程中。本发明对imagenet数据集上预训练的efficientnet-b0模型进行迁移学习。该模型在imagenet数据集上训练时,其一共包含4049564个参数,其中需要梯度下降来训练的参数有4007548个,不需要训练的参数是batchnormalization层中的均值和方差共42016个。
s22、对经过s21处理后的初步数据集处理模型进行编译处理,随后使用优化更新后的所述训练集、验证集内的数据对所述初步数据集处理模型进行反复训练、验证,得到预训练数据集处理模型。
上述操作可以具体为,采用编译函数(compile)对所述初步数据集处理模型进行编译处理,损失函数选用交叉熵损失函数、优化器选用adam损失函数优化器,冻结efficientnet-b0网络参数、仅训练全连接层和线性分类器内的参数,随后使用fit_generator()函数、结合优化更新后的所述训练集、验证集内的数据对所述初步数据集处理模型进行反复训练、验证,得到预训练数据集处理模型。
所述编译函数的公式为
compile(self,optimizer,loss,metrics=[]),
所述交叉熵损失函数是一个平滑函数,其本质是信息理论中的交叉熵在分类问题中的应用,其公式为
adam损失函数优化器是一种计算能每个参数的自适应学习率的优化方法。即存储了过去梯度的平方
其中,
如果
梯度更新规则为:
超参数设定值为:
fit_generator()函数利用python的生成器,逐个生成数据的batch并进行训练。生成器与模型将并行执行以提高效率。
s23、使用matplotlib.pyplot模块和pandas模块绘制accuracy、loss曲线,结果如图3~图4所示。
s24、利用所述测试集内的数据对所述预训练数据集处理模型进行测试,使用evaluate_generator()函数测试所述预训练数据集处理模型的准确率和loss值,最终得到完善的数据集处理模型。evaluate_generator()函数使用一个生成器作为数据源评估模型,生成器应返回与test_on_batch的输入数据相同类型的数据。该函数的参数与fit_generator同名参数含义相同。
为了进一步验证本发明方法的有效性,研究人员在原始的干净图像数据集的基础上分别合成了高斯噪声图像数据集以及椒盐噪声图像数据集,并按照本发明的方法重复执行了上述流程,其最终的验证结果如图5~图8所示。
本发明所提出的一种基于机器学习技术的小龙虾分级方法,通过将机器视觉与深度学习技术相融合的手段,实现了对于小龙虾大小的自动化分级,大幅减少了使用者的各项成本投入。本发明的方法不仅显著地提升了操作过程中的识别率与准确率,而且有效地弥补了现有方法在后续图像理解及分级性能等方面的缺陷。
具体而言,本发明的方法以预训练的efficientnet-b0网络作为基础框架,通过tensorflow平台实现算法流程,使用两层全连接层及relu激活函数对efficientnet-b0特征进行了迁移,并利用adam优化器对两层全连接层和线性分类层进行了训练。
通过评估本发明的方法在处理干净图像数据集及不同类型的噪声图像数据集时的实际表现可以得知,本发明的方法在不同数据集上均具有较好的泛化性能,在干净图像、高斯噪声图像以及椒盐噪声图像上的识别率分别达到了99.70%、92.07%、88.41%。可以说,本发明的方法为小龙虾的批量化、规模化分级提供了强有力的技术支持。
此外,本发明的方法也为同领域内的其他相关问题提供了参考,可以以此为依据进行拓展延伸和深入研究,将类似的思路和操作应用于其他的操作平台,应用于对其他产品的分类、分级操作中,具有十分广阔的应用前景和很高的实际应用价值。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神和基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。
最后,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!