一种基于视觉跟踪的自适应显示器定位方法与流程
本发明涉及人工智能技术,具体涉及一种基于视觉跟踪的自适应显示器定位方法。
背景技术:
目前,在使用电脑时,市场上流行的显示器支架基本都是固定或者人工调节的,而用户如果对适当角度的把控有偏差,容易因为显示器的位置不正确,长时间看显示器时,会因为坐姿不正确引起健康问题,比如驼背,严重者可能导致腰间盘突出等重大问题。
技术实现要素:
本发明的主要目的在于提供一种基于视觉跟踪的自适应显示器定位方法,在日常使用电脑时自动调节显示器,使显示器达到最佳显示位置,同时解决人们因面对显示器坐姿不正确的问题。
本发明采用的技术方案是:一种基于视觉跟踪的自适应显示器定位方法,包括:
安装好相机;
对efficient-net目标检测网络进行更改,构建图人脸位置检测装置;
结合点云分割网络gac-net和point-cnn框架,构建人脸点云语义分割网络;
先建立图像数据库并进行标注,利用labelimg软件标注出人脸x、y、w和h的值,利用labelme标注出人脸中左眼和右眼区域像素的类别为1和2,其余背景类别为0。
进一步地,所述对efficient-net目标检测网络进行更改,构建图人脸位置检测装置还包括:
去除原网络中的分类分支,仅保留回归分支,并且回归分支中仅预测4个值,x、y、w和h,分别对应人脸位置左上角的坐标及其长和宽,其被归一化为[0,1]范围内,其位置结果用于裁剪深度图中的人脸区域。
更进一步地,所述结合点云分割网络gac-net和point-cnn框架,构建人脸点云语义分割网络包括:
所述网络输出分为三类,分别为左眼、右眼和背景,左眼和右眼点云通过pca计算法向量并取平均值v,结合其高度,获得显示器运动预测结果。
更进一步地,所述的基于视觉跟踪的自适应显示器定位方法还包括:
分别建立损失函数,人脸位置检测网络为l1损失,即l1=|x-x'|+|y-y'|+|w-w'|+|h-h'|,其中x、y、w和h为真是标签值,x'、y'、w'和h'为预测值,通过损失函数更新网络模型参数,提高模型的准确率,从而获得预测参数模型。
本发明的优点:
本发明的方法可以应用于现有电动显示器装置上,实现显示器的自适应定位。
本发明是基于深层神经网络在目标检测和语义分割的优异特性,结合人机工程学,从而解决人们日常使用电脑时自动调节显示器。
本发明的方法,在日常使用电脑时自动调节显示器,使显示器达到最佳显示位置,同时解决人们因面对显示器坐姿不正确的问题。
除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照图,对本发明作进一步详细的说明。
附图说明
构成本申请的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
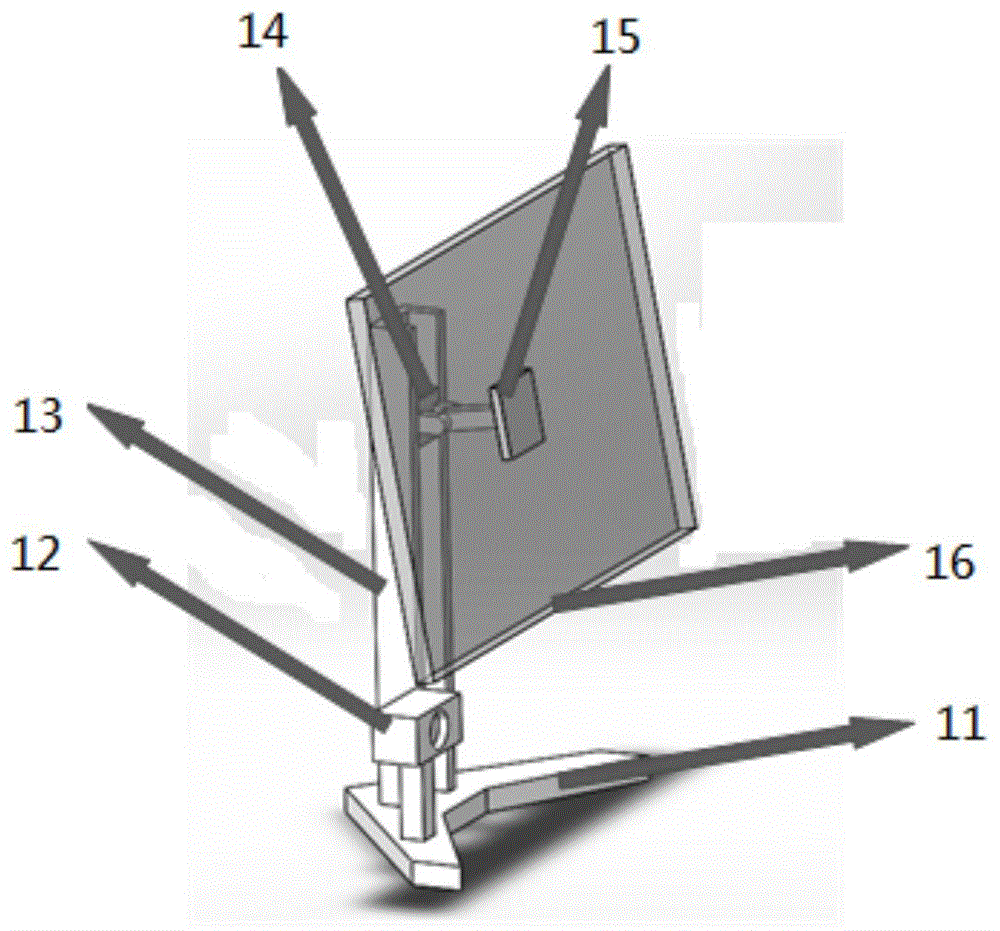
图1是本发明的自适应显示器装置简图;
图2是本发明的自适应显示器运动简图;
图3是本发明的方法原理图;
图4是本发明的基于efficient-det的人脸位置检测网络;
图5是本发明的基于gac-net和point-cnn的人脸点云分割网络;
图6是本发明的神经网络训练流程图;
图7是本发明的自适应显示器运动结果预测流程图;
图8是本发明的预测结果参数。
附图标记:
11为底座、12为相机、13为滑轨、14为滑块、15为连杆、16为屏幕;
21为滑块、22为连杆。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
参考图1至图8,如图1至图8所示,本发明基本组成:包括显示器、rgb-d相机、人脸位置检测网络、人脸点云分割网络和机器视觉处理系统。
所述的机器视觉处理系统由具有计算能力的设备组成,所述的rgb-d相机可以采用微软的kinect等rgb-d相机,所述的显示器可以采用已有方法进行平移和旋转。
该方法利用rgb-d相机采取显示器使用用户的彩色图像和深度图,将所述的彩色图像输入人脸位置检测网络,输出人脸位置。将人脸位置信息输入所述的深度图进行裁剪人脸区域,将人脸区域深度图转换为点云,输入人脸点云分割网络,从而分割出人脸中左眼和右眼的区域。分别计算所述的左眼和右眼的法向量并取其平均值为v,同时结合左右眼的平均高度h,查找已建立好的“显示器位移和旋转角度与人眼法向量v和高度h的映射表格”,获取显示器的最佳位置,从而实现指导显示器进行自适应移动。通过对人眼位置的准确获取,实现对自适应显示器的精密控制。
本发明的主要实现过程:
完成“显示器位移和旋转角度与人眼法向量v和高度h的映射表格”的建立。
完成人脸位置检测网络的建立并对其进行训练。
完成人脸点云分割网络的联机并对其进行训练。
本发明的方法可以应用于现有电动显示器装置上,实现显示器的自适应定位。
本发明是基于深层神经网络在目标检测和语义分割的优异特性,结合人机工程学,从而解决人们日常使用电脑时自动调节显示器。
本发明的方法,在日常使用电脑时自动调节显示器,使显示器达到最佳显示位置,同时解决人们因面对显示器坐姿不正确的问题。
本发明的具体方法如下:
按照如图1中的布局安装rgb-d相机。
按照现有电动显示器实现图2中滑块沿z轴的直线运动和连杆绕x轴的旋转运动。
对efficient-net目标检测网络进行更改,构建图4中的人脸位置检测装置,efficient-net具有速度快、精度高的优点。
由于进行检测的只有一个类别——人脸,故去除原网络中的分类分支,仅保留回归分支,并且回归分支中仅预测4个值,x、y、w和h,分别对应人脸位置左上角的坐标及其长和宽,其被归一化为[0,1]范围内,目的是方便神经网络的训练。
其位置结果用于裁剪深度图中的人脸区域,以便转化人脸点云。
结合点云分割网络gac-net和point-cnn框架,构建图5中的人脸点云语义分割网络,gac是图卷积注意力卷积,可以提高网络的注意力机制,xconv对于点云无序性具有很好地处理效果,通过迭代gac和xconv层,从而的提高网络的语义分割性能。
所述网络输出3个类别,分别为左眼、右眼和背景,左眼和右眼点云通过pca计算法向量并取平均值v,结合其高度,便可获得显示器运动预测结果。
神经网络需要大量数据进行训练,根据图6中流程所述,需先建立图像数据库并进行标注,利用labelimg软件标注出人脸x、y、w和h的值,利用labelme标注出人脸中左眼和右眼区域像素的类别为1和2,其余背景类别为0。
再建立步骤3和4中的模型。分别建立损失函数,人脸位置检测网络为l1损失,即l1=|x-x'|+|y-y'|+|w-w'|+|h-h'|,其中x、y、w和h为真是标签值,x'、y'、w'和h'为预测值,人脸点云分割网络为典型的cross-entropy损失函数,在此不赘述。通过损失函数更新网络模型参数,提高模型的准确率,从而获得预测参数模型。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!