企业运营数据的处理方法与流程
本发明实施例涉及数据处理技术领域,特别涉及企业运营数据的处理方法。
背景技术:
强化运营管理商业智能,已经成为全世界、各行业普遍关注、亟待提升的命题。世界领先的制造企业均通过集约化运营管理、加强运营监控、提高运营管理的商业智能等手段来提升企业核心竞争力。自1996年“商业智能”这一概念被gartner机构提出,伴随erp等企业事务处理过程系统在世界各大企业的深入融合应用以及大数据、数据挖掘、数据仓库、ai等先进技术日益发展成熟,运营管理商业智能在世界范围内,尤其是制造业及流通企业展现了前所未有的市场前景。包括微软、ibm、oracle、sap在内的著名it厂商纷纷致力于该领域内解决方案的研究。
近年来,我国多项政策均有涉及到推进ai技术在商业领域实现落地的内容。国内各行业大型企业已经建设完备并深化推广应用erp、crm、plm等核心业务系统及综合协同办公系统,以支撑企业日常生产运营工作。随着运营管理数据的爆炸式增长,市场竞争日益加剧,为发掘数据背后的价值以获得快速决策和市场反应能力,各企业纷纷投入研发力量并规划建设企业一体化运营监控体系。
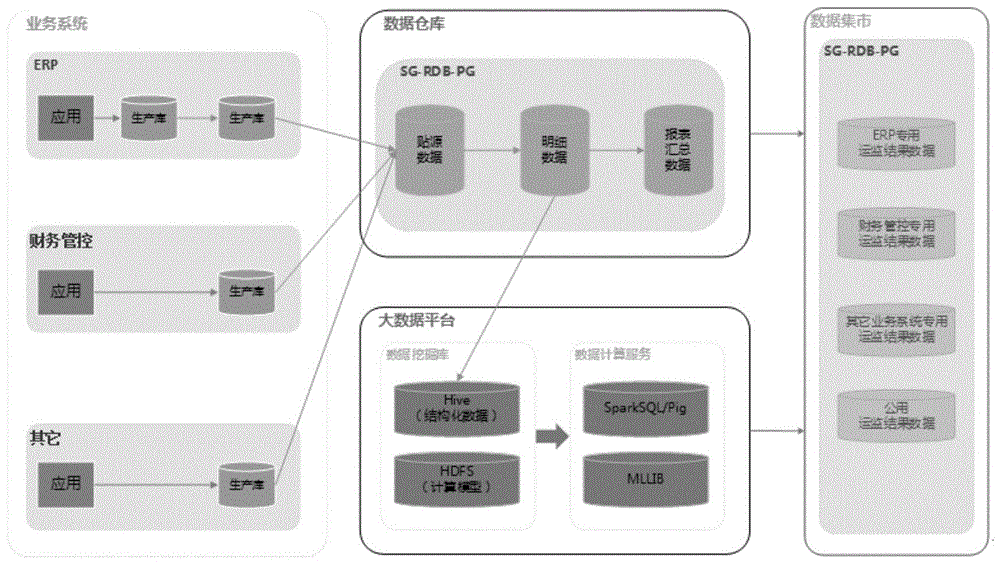
由于企业运营监控系统立足于企业以往建立的erp、财务管控、crm、plm、人力资源系统、生产制造系统、综合管理系统,甚至线下手工台账流程等系统之上,需要与既建多种系统进行集成以抽取各类业务数据,并对所得数据进行统一管理与应用。将面临数据来源系统接口多样、数据类型不统一、数据冗余、数据体量庞大、同步及管理困难等问题。但是现有技术中,对于此类运营数据还没有一种很好的数据处理方案。
技术实现要素:
针对现有技术中的缺少对海量企业运营数据进行处理方法的问题,本发明实施例提出了一种企业运营数据的处理方法,能够对海量的企业运营数据进行有效和快速的处理。
为了解决上述问题,本发明实施例提出了一种自主可控数据库分布式集群的流式数据处理方法,包括:
数据抽取步骤,用于从多种不同系统中抽取数据;
数据存储与处理步骤,用于将抽取到的数据存储到分布式存储架构搭建数据仓库中;
数据挖掘与数据计算,用于对运营数据进行数据挖掘与数据计算,以获取可满足单业务分析及多业务分析需要的数据。
其中,所述数据抽取步骤包括:
通过smarthub从不同的企业运营系统中抽取数据;其中所述smarthub为支持db、日志、api类型的数据中进行数据采集的插件,且能够对数据采集的过程进行实时的一致性检测,并对采集过程中出现的异常进行及时告警。
其中,所述企业运营系统包括以下的至少一种:erp、财务管控、crm、plm、人力资源、生产制造数据系统;其中所述数据抽取步骤用于从所述企业营业系统的数据接口或中间库进行历史数据与实时数据的抽取;还用于从没有数据接口或中间库的企业运营系统中的数据通过excel表的形式进行数据导入。
其中,所述数据存储与处理步骤包括:通过基于sg-rdb-pg数据库的分布式存储架构搭建数据仓库,在数据仓库内进行企业运营数据的存储、清洗转换以及加载。
其中,所述数据存储与处理步骤包括:
从数据源获取的分散、零乱、标准不统一的原始企业运营数据初步存放在贴源库中,贴源库用于数据溯源,当数据应用出现偏差或不符时能够通过贴源数据追踪到原数据、原系统,同时为后续清洗转换、统计分析提供原始数据支撑;
采用etl软件对贴源库中的不符合要求的数据进行清洗,主要包括不完整的数据、错误的数据、重复的数据三大类。同时对清洗后的数据进行不一致数据转换与整合,将不同业务系统的相同类型的数据统一;处理后的数据通过etl工具加载到明细库;
对明细库中业务系统数据根据业务需求进行深度处理,如数据粒度转换、商务规则计算,所得数据存放在汇总库;
为满足数据挖掘与应用的需要,针对数据仓库使用webservice开发数据流通接口。
其中,所述数据存储与处理步骤包括:
数据挖掘与数据计算,通过基于hadoop架构、spark计算引擎搭建的运监大数据平台,对企业运营数据进行分析和计算;其中所述运监大数据平台至少搭载了snappydata、hdfs、elasticsearch、druid组件。
其中,所述数据存储与处理步骤包括:
所述运监大数据平台通过etl与sql方式相结合对数据仓库中的数据进行抽取;
根据预设的数据分析预测模型,针对所得运营数据进行数据挖掘与数据计算。
本发明的上述技术方案的有益效果如下:本发明实施例的上述方案是一种企业运营监控(测)数据处理方法,应用smarthub对接企业不同业务源系统,抽取原始数据存放在sg-rdb-pg数据仓库的贴源库中。采用etl工具对贴源库中数据进行数据清洗、初步数据转换、并将结果数据资产加载到数据仓库的明细库中。根据业务需求使用kettle工具对明细库中数据进行商务规则计算等深度处理,然后加载至汇总库。针对数据仓库开发webservice接口,实现权限内数据从数据仓库抽取至大数据平台进行数据计算与挖掘,形成企业运营数据资产。数据集市从数据仓库与大数据平台抽取健全的数据资产,结合主数据模型支撑上层应用开发。
附图说明
图1为本发明实施例的系统原理图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
数据抽取步骤,用于从多种不同系统中抽取数据;
具体的,可以通过smarthub从不同的系统中抽取数据;其中该smarthub为支持db、日志、api等多种类型的数据中进行数据采集的插件,且能够对数据采集的过程进行实时的一致性检测,并对采集过程中出现的异常进行及时告警。在一些实施例中,可以通过smarthub技术实现从erp、财务管控、crm、plm、人力资源、生产制造等系统的数据接口或中间库进行历史数据与实时数据的抽取。同时,对不能提供接口或中间库企业运营数据数据支持通过excel表的形式进行数据导入。
数据存储与处理,本方案采用基于sg-rdb-pg数据库的分布式存储架构搭建数据仓库,在数据仓库内进行企业运营数据的存储、清洗转换以及加载。1)从数据源获取的分散、零乱、标准不统一的原始企业运营数据初步存放在贴源库中,贴源库用于数据溯源,当数据应用出现偏差或不符时能够通过贴源数据追踪到原数据、原系统,同时为后续清洗转换、统计分析提供原始数据支撑;2)本方法采用kettle等成熟etl软件对贴源库中的不符合要求的数据进行清洗,主要包括不完整的数据、错误的数据、重复的数据三大类。同时对清洗后的数据进行不一致数据转换与整合,将不同业务系统的相同类型的数据统一。处理后的数据通过etl工具加载到明细库;3)对明细库中业务系统数据根据业务需求进行深度处理,如数据粒度转换、商务规则计算,所得数据存放在汇总库;4)为满足数据挖掘与应用的需要,本方法针对数据仓库使用webservice开发数据流通接口。
数据挖掘与数据计算,本方法包括基于hadoop先进架构、spark计算引擎搭建的运监大数据平台,平台搭载了snappydata、hdfs、elasticsearch、druid等组件,可对企业运营数据进行灵活高效的内存级分析和运算。平台采用etl与sql方式相结合对数据仓库中的数据进行抽取,结合多种数据分析、预测分析模型,针对所得运营数据进行数据挖掘与数据计算,可满足单业务分析及多业务分析需要,使数据成为标准统一、质量可靠、安全有效的数据资产。
数据服务,对企业运营数据进行上述一系列处理,可形成健全的数据资产支撑上层应用开发。本方法针对企业运营业务及运营监控(测)需要搭建数据集市,接收来自大数据平台及数据仓库的数据。本方法基于sg-rdb-pg架构搭建数据集市,可实现主数据模型构造;存储内存计算结果数据,并结合主数据模型,对业务应用提供更通用的oltp支撑;存储面向各类报表、统计分析类前台应用程序功能需要访问的重度汇总类数据。
本发明实施例的上述方案是一种企业运营监控(测)数据处理方法,应用smarthub对接企业不同业务源系统,抽取原始数据存放在sg-rdb-pg数据仓库的贴源库中。采用etl工具对贴源库中数据进行数据清洗、初步数据转换、并将结果数据资产加载到数据仓库的明细库中。根据业务需求使用kettle工具对明细库中数据进行商务规则计算等深度处理,然后加载至汇总库。针对数据仓库开发webservice接口,实现权限内数据从数据仓库抽取至大数据平台进行数据计算与挖掘,形成企业运营数据资产。数据集市从数据仓库与大数据平台抽取健全的数据资产,结合主数据模型支撑上层应用开发。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!